
# Ignite 解釋器
原文鏈接 : [http://zeppelin.apache.org/docs/0.7.2/interpreter/ignite.html](http://zeppelin.apache.org/docs/0.7.2/interpreter/ignite.html)
譯文鏈接 : [http://www.apache.wiki/pages/viewpage.action?pageId=10030819](http://www.apache.wiki/pages/viewpage.action?pageId=10030819)
貢獻者 : [片刻](/display/~jiangzhonglian) [ApacheCN](/display/~apachecn) [Apache中文網](/display/~apachechina)
## 概述
[Apache Ignite](https://ignite.apache.org/)內存數據結構是一種高性能,集成和分布式內存平臺,用于實時計算和處理大規模數據集,比傳統的基于磁盤或閃存技術的速度更快。

您可以使用Zeppelin從Ignite SQL解釋器檢索緩存中的分布式數據。此外,Ignite解釋器允許您在SQL不符合您的要求的情況下執行任何Scala代碼。例如,您可以將數據填充到緩存中或執行分布式計算。
## 安裝和運行Ignite示例
為了使用Ignite解釋器,您可以在一些簡單的步驟中安裝Apache Ignite:
1. Ignite僅提供源或二進制版本的示例。下載Ignite?[源版本](https://ignite.apache.org/download.html#sources)或[二進制版本,](https://ignite.apache.org/download.html#binaries)無論你想要什么。但是您必須下載Ignite作為相同版本的Zeppelin的。如果不是,您不能在Zeppelin上使用scala代碼。受支持的Ignite版本在每個Zeppelin?版本的“支持的[解釋器”表中](https://zeppelin.apache.org/supported_interpreters.html#ignite)指定。如果您在使用Zeppelin的主分支,請參閱`ignite.version`在`path/to/your-Zeppelin/ignite/pom.xml`。
2. 示例作為單獨的Maven項目發送,因此要開始運行,您只需將提供的`<dest_dir>/apache-ignite-fabric-{version}-bin/examples/pom.xml`文件導入到您喜歡的IDE(如Eclipse)中。
* 在Eclipse的情況下,Eclipse - > File - > Import - > Existing Maven Projects
* 將示例目錄路徑設置為Eclipse,然后選擇pom.xml。
* 然后啟動`org.apache.ignite.examples.ExampleNodeStartup`(或任何你想要的)運行至少一個或多個點火節點。運行示例代碼時,可能會注意到節點數逐個增加。
> **小費。如果要在cli IDE上運行Ignite示例,則可以從IDE導出可執行Jar文件。然后使用以下命令運行它。**
```
$ nohup java -jar </path/to/your Jar file name>?
```
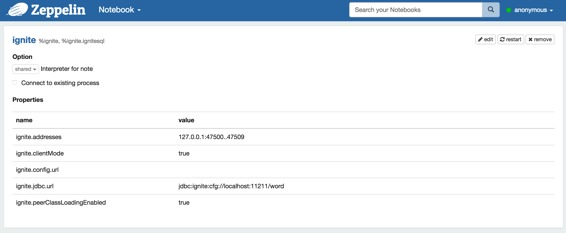
## 配置Ignite解釋器
在“解釋器”菜單中,您可以編輯Ignite解釋器或創建新的。Zeppelin提供了Ignite的這些屬性。
| 物業名稱 | 值 | 描述 |
| --- | --- | --- |
| ignite.addresses | 127.0.0.1:47500..47509 | Ignite集群主機的Coma分離列表。有關詳細信息,請參閱[Ignite Cluster Configuration]([https://apacheignite.readme.io/docs/cluster-config](https://apacheignite.readme.io/docs/cluster-config))部分。 |
| ignite.clientMode | true | 您可以連接到Ignite集群作為客戶端或服務器節點。有關詳細信息,請參閱[Ignite Clients vs. Servers]()部分。使用true或false值分別連接客戶端或服務器模式。 |
| ignite.config.url | ? | 配置URL?覆蓋所有其他設置。 |
| ignite.jdbc.url | jdbc:ignite:cfg://default-ignite-jdbc.xml | 點擊JDBC連接URL。 |
| ignite.peerClassLoadingEnabled | true | 啟用同級加載。有關詳細信息,請參閱[零部署]()部分。使用true或false值來分別啟用或禁用P2P類加載。 |
## 如何使用
?配置Ignite解釋器后,創建自己的筆記本。然后,您可以綁定如下圖像的解釋器。
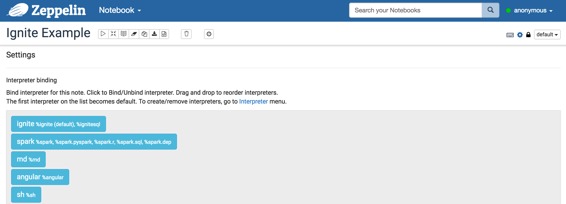
有關更多的解釋器綁定信息,請參閱[此處](http://zeppelin.apache.org/docs/0.7.1/manual/interpreters.html#what-is-interpreter-setting)。
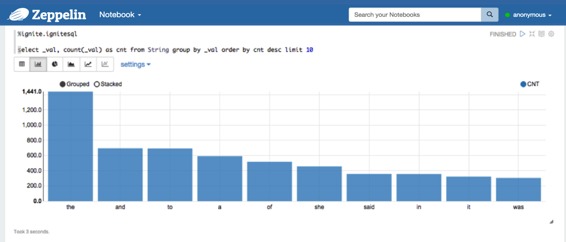
### 點擊SQL解釋器
為了執行SQL查詢,使用`%ignite.ignitesql`前綴。
假設您正在運行`org.apache.ignite.examples.streaming.wordcount.StreamWords`,那么您可以使用“單詞”緩存(當然,您必須將此緩存名稱指定給`ignite.jdbc.url`Zeppelin?的Ignite解釋器設置部分)。例如,您可以使用以下查詢在單詞緩存中選擇前10個單詞
```
%ignite.ignitesql
select _val, count(_val) as cnt from String group by _val order by cnt desc limit 10?
```
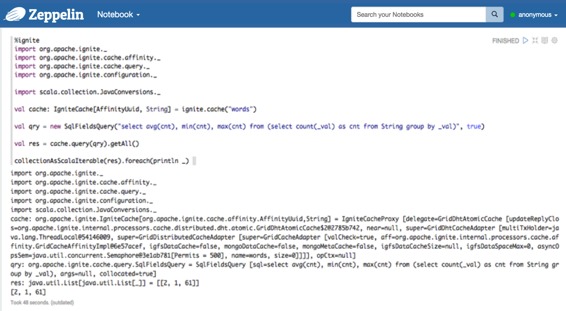
只要您的Ignite版本和Zeppelin Ignite版本相同,您還可以使用scala代碼。在您下載自己的Ignite之前,請檢查Zeppelin Ignite版本。
```
%ignite
import org.apache.ignite._
import org.apache.ignite.cache.affinity._
import org.apache.ignite.cache.query._
import org.apache.ignite.configuration._
import scala.collection.JavaConversions._
val cache: IgniteCache[AffinityUuid, String] = ignite.cache("words")
val qry = new SqlFieldsQuery("select avg(cnt), min(cnt), max(cnt) from (select count(_val) as cnt from String group by _val)", true)
val res = cache.query(qry).getAll()
collectionAsScalaIterable(res).foreach(println _)?
```
``
Apache Ignite還為Zeppelin?[“Ignite with Apache Zeppelin”](https://apacheignite.readme.io/docs/data-analysis-with-apache-zeppelin)提供了指導性文檔。
- 快速入門
- 什么是Apache Zeppelin?
- 安裝
- 配置
- 探索Apache Zeppelin UI
- 教程
- 動態表單
- 發表你的段落
- 自定義Zeppelin主頁
- 升級Zeppelin版本
- 從源碼編譯
- 使用Flink和Spark Clusters安裝Zeppelin教程
- 解釋器
- 概述
- 解釋器安裝
- 解釋器依賴管理
- 解釋器的模擬用戶
- 解釋員執行Hook(實驗)
- Alluxio 解釋器
- Beam 解釋器
- BigQuery 解釋器
- Cassandra CQL 解釋器
- Elasticsearch 解釋器
- Flink 解釋器
- Geode/Gemfire OQL 解釋器
- HBase Shell 解釋器
- HDFS文件系統 解釋器
- Hive 解釋器
- Ignite 解釋器
- JDBC通用 解釋器
- Kylin 解釋器
- Lens 解釋器
- Livy 解釋器
- Markdown 解釋器
- Pig 解釋器
- PostgreSQL, HAWQ 解釋器
- Python 2&3解釋器
- R 解釋器
- Scalding 解釋器
- Scio 解釋器
- Shell 解釋器
- Spark 解釋器
- 系統顯示
- 系統基本顯示
- 后端Angular API
- 前端Angular API
- 更多
- 筆記本存儲
- REST API
- 解釋器 API
- 筆記本 API
- 筆記本資源 API
- 配置 API
- 憑據 API
- Helium API
- Security ( 安全 )
- Shiro 授權
- 筆記本 授權
- 數據源 授權
- Helium 授權
- Advanced ( 高級 )
- Zeppelin on Vagrant VM ( Zeppelin 在 Vagrant 虛擬機上 )
- Zeppelin on Spark Cluster Mode( Spark 集群模式下的 Zeppelin )
- Zeppelin on CDH ( Zeppelin 在 CDH 上 )
- Contibute ( 貢獻 )
- Writing a New Interpreter ( 寫一個新的解釋器 )
- Writing a new Visualization (Experimental) ( 編寫新的可視化(實驗) )
- Writing a new Application (Experimental) ( 寫一個新的應用程序( 實驗 ) )
- Contributing to Apache Zeppelin ( Code ) ( 向 Apache Zeppelin 貢獻( 代碼 ) )
- Contributing to Apache Zeppelin ( Website ) ( 向 Apache Zeppelin 貢獻(website) )