
# R 解釋器
原文鏈接 : [http://zeppelin.apache.org/docs/0.7.2/interpreter/r.html](http://zeppelin.apache.org/docs/0.7.2/interpreter/r.html)
譯文鏈接 : [http://www.apache.wiki/pages/viewpage.action?pageId=10030900](http://www.apache.wiki/pages/viewpage.action?pageId=10030900)
貢獻者 : [片刻](/display/~jiangzhonglian) [ApacheCN](/display/~apachecn) [Apache中文網](/display/~apachechina)
## 概述
[R](https://www.r-project.org/)是用于統計計算和圖形的免費軟件環境。
要在Apache Zeppelin中運行R代碼和可視化圖形,您將需要在主節點(或您的開發筆記本電腦)上使用R。
* 對于Centos:?`yum install R R-devel libcurl-devel openssl-devel`
* 對于Ubuntu:?`apt-get install r-base`
使用簡單的R命令驗證安裝:
```
R -e "print(1+1)"?
```
要享受plots,請安裝附加庫:
```
+ devtools with `R -e "install.packages('devtools', repos = 'http://cran.us.r-project.org')"`
+ knitr with `R -e "install.packages('knitr', repos = 'http://cran.us.r-project.org')"`
+ ggplot2 with `R -e "install.packages('ggplot2', repos = 'http://cran.us.r-project.org')"`
+ Other vizualisation librairies: `R -e "install.packages(c('devtools','mplot', 'googleVis'), repos = 'http://cran.us.r-project.org'); require(devtools); install_github('ramnathv/rCharts')"`?
```
我們建議您還安裝以下可選的R庫,用于快樂的數據分析:
* glmnet
* PROC
* data.table
* caret
* sqldf
* wordcloud
## 配置
要使用R解釋器運行Zeppelin,`SPARK_HOME`必須設置環境變量。最好的方式是編輯`conf/zeppelin-env.sh`。如果沒有設置,R解釋器將無法與Spark進行接口。
你也應該復制`conf/zeppelin-site.xml.template`到`conf/zeppelin-site.xml`。這將確保齊柏林首次見到R解釋器。
## 使用R解釋器
默認情況下,將R解釋顯示為兩個Zeppelin解釋器,`%r`和`%knitr`。
`%r`將表現得像普通REPL。您可以像CLI中一樣執行命令。

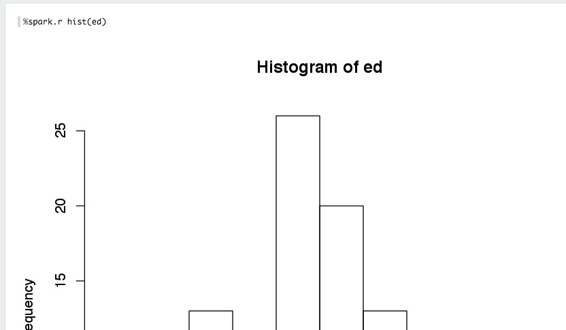
R基本繪圖得到完全支持
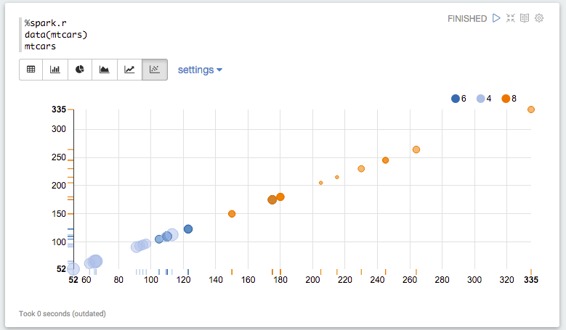
如果您返回一個data.frame,則Zeppelin將嘗試使用Zeppelin的內置可視化進行顯示。
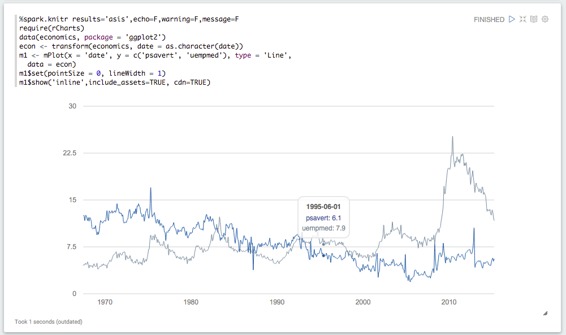
`%knitr`接口直接針對`knitr`第一行的chunk選項:

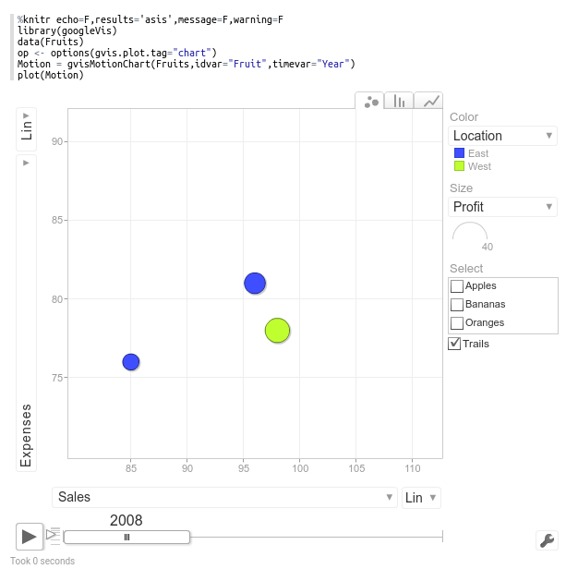
兩位解釋器的環境相同。如果您定義了一個變量`%r`,那么如果您使用一個調用,它將在范圍內`knitr`。
## 使用SparkR&語言間移動
如果`SPARK_HOME`設置,`SparkR`包將自動加載:
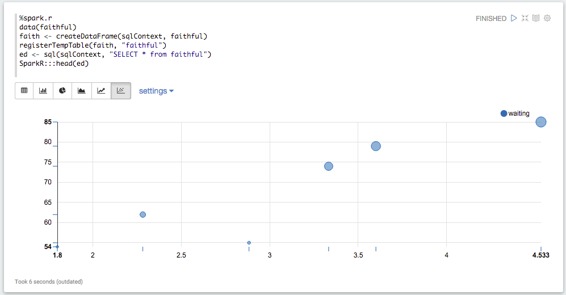
星火上下文和語境SQL創建并注入當地環境自動`sc`和`sql`。
同樣的情況下與共享`%spark`,`%sql`并`%pyspark`解釋:
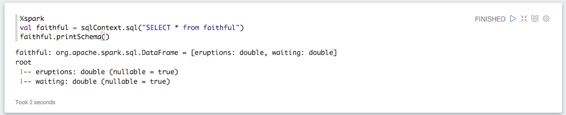
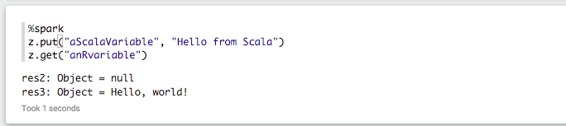
您還可以使普通的R變量在scala和Python中可訪問:

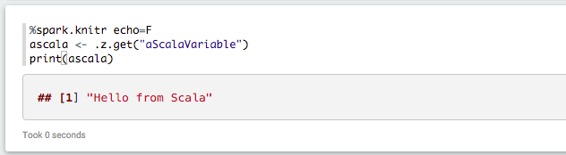
反之亦然:
## 警告和故障排除
* R解釋器幾乎所有的問題都是由于錯誤設置造成的`SPARK_HOME`。R解釋器必須加載`SparkR`與運行版本的Spark匹配的軟件包版本,并通過搜索來實現`SPARK_HOME`。如果Zeppelin未配置為與Spark接口`SPARK_HOME`,則R解釋器將無法連接到Spark。
* 該`knitr`環境是持久的。如果您從Zeppelin運行一個更改變量的塊,則再次運行相同的塊,該變量已被更改。使用不變變量。
* (請注意,`%spark.r`和`%r`是調用同一解釋的兩種不同的方式,因為是`%spark.knitr`和`%knitr`默認情況下,Zeppelin將R解釋器放在`%spark.`翻譯組。
* 使用`%r`解釋器,如果你返回一個data.frame,HTML或一個圖像,它將主導結果。所以如果你執行三個命令,一個是`hist()`,所有你會看到的是直方圖,而不是其他命令的結果。這是一個Zeppelin限制。
* 如果您從解釋器返回data.frame(例如,從調用`head()`)`%spark.r`,則將由Zeppelin的內置數據可視化系統進行解析。
* 為什么`knitr`不是的`rmarkdown`?為什么沒有`htmlwidgets`?為了支持`htmlwidgets`,它具有間接依賴,`rmarkdown`使用`pandoc`,這需要寫入和讀取光盤。這使它比`knitr`RAM完全運行的速度慢許多倍。
* 為什么不`ggvis`和`shiny`?支持`shiny`需要將反向代理集成到Zeppelin中,這是一項任務。
* 最大的OS X和不區分大小寫的文件系統。如果您嘗試安裝在不區分大小寫的文件系統(Mac OS X默認值)上,則maven可能無意中刪除安裝目錄,因為`r`它們`R`成為相同的子目錄。
* 錯誤`unable to start device X11`與REPL解釋。檢查你的shell登錄腳本,看看它們是否在`DISPLAY`調整環境變量。這在某些操作系統上是常見的,作為ssh問題的解決方法,但可能會干擾R繪圖。
* akka庫版本或`TTransport`錯誤。如果您嘗試使用SPARK_HOME運行Zeppelin,該版本的Spark版本與`-Pspark-1.x`編譯Zeppelin時指定的版本不同。
- 快速入門
- 什么是Apache Zeppelin?
- 安裝
- 配置
- 探索Apache Zeppelin UI
- 教程
- 動態表單
- 發表你的段落
- 自定義Zeppelin主頁
- 升級Zeppelin版本
- 從源碼編譯
- 使用Flink和Spark Clusters安裝Zeppelin教程
- 解釋器
- 概述
- 解釋器安裝
- 解釋器依賴管理
- 解釋器的模擬用戶
- 解釋員執行Hook(實驗)
- Alluxio 解釋器
- Beam 解釋器
- BigQuery 解釋器
- Cassandra CQL 解釋器
- Elasticsearch 解釋器
- Flink 解釋器
- Geode/Gemfire OQL 解釋器
- HBase Shell 解釋器
- HDFS文件系統 解釋器
- Hive 解釋器
- Ignite 解釋器
- JDBC通用 解釋器
- Kylin 解釋器
- Lens 解釋器
- Livy 解釋器
- Markdown 解釋器
- Pig 解釋器
- PostgreSQL, HAWQ 解釋器
- Python 2&3解釋器
- R 解釋器
- Scalding 解釋器
- Scio 解釋器
- Shell 解釋器
- Spark 解釋器
- 系統顯示
- 系統基本顯示
- 后端Angular API
- 前端Angular API
- 更多
- 筆記本存儲
- REST API
- 解釋器 API
- 筆記本 API
- 筆記本資源 API
- 配置 API
- 憑據 API
- Helium API
- Security ( 安全 )
- Shiro 授權
- 筆記本 授權
- 數據源 授權
- Helium 授權
- Advanced ( 高級 )
- Zeppelin on Vagrant VM ( Zeppelin 在 Vagrant 虛擬機上 )
- Zeppelin on Spark Cluster Mode( Spark 集群模式下的 Zeppelin )
- Zeppelin on CDH ( Zeppelin 在 CDH 上 )
- Contibute ( 貢獻 )
- Writing a New Interpreter ( 寫一個新的解釋器 )
- Writing a new Visualization (Experimental) ( 編寫新的可視化(實驗) )
- Writing a new Application (Experimental) ( 寫一個新的應用程序( 實驗 ) )
- Contributing to Apache Zeppelin ( Code ) ( 向 Apache Zeppelin 貢獻( 代碼 ) )
- Contributing to Apache Zeppelin ( Website ) ( 向 Apache Zeppelin 貢獻(website) )