
出自
> [Java內存模型](http://www.importnew.com/19612.html)
[TOC=1,2]
譯文出處:?[張坤](http://ifeve.com/java-memory-model-6/)???原文出處:[Jakob Jenkov](http://tutorials.jenkov.com/java-concurrency/java-memory-model.html)
Java內存模型規范了Java虛擬機與計算機內存是如何協同工作的。Java虛擬機是一個完整的計算機的一個模型,因此這個模型自然也包含一個內存模型——又稱為Java內存模型。
如果你想設計表現良好的并發程序,理解Java內存模型是非常重要的。Java內存模型規定了如何和何時可以看到由其他線程修改過后的共享變量的值,以及在必須時如何同步的訪問共享變量。
原始的Java內存模型存在一些不足,因此Java內存模型在Java1.5時被重新修訂。這個版本的Java內存模型在Java8中人在使用。
### Java內存模型內部原理
Java內存模型把Java虛擬機內部劃分為線程棧和堆。這張圖演示了Java內存模型的邏輯視圖。
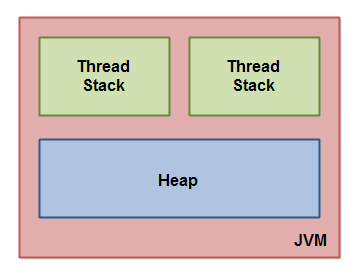
每一個運行在Java虛擬機里的線程都擁有自己的線程棧。這個線程棧包含了這個線程調用的方法當前執行點相關的信息。一個線程僅能訪問自己的線程棧。一個線程創建的本地變量對其它線程不可見,僅自己可見。即使兩個線程執行同樣的代碼,這兩個線程仍然在自己的線程棧中的代碼來創建本地變量。因此,每個線程擁有每個本地變量的獨有版本。
所有原始類型的本地變量都存放在線程棧上,因此對其它線程不可見。一個線程可能向另一個線程傳遞一個原始類型變量的拷貝,但是它不能共享這個原始類型變量自身。
堆上包含在Java程序中創建的所有對象,無論是哪一個對象創建的。這包括原始類型的對象版本。如果一個對象被創建然后賦值給一個局部變量,或者用來作為另一個對象的成員變量,這個對象還是存放在堆上。
下面這張圖演示了調用棧和本地變量存放在線程棧上,對象存放在堆上。
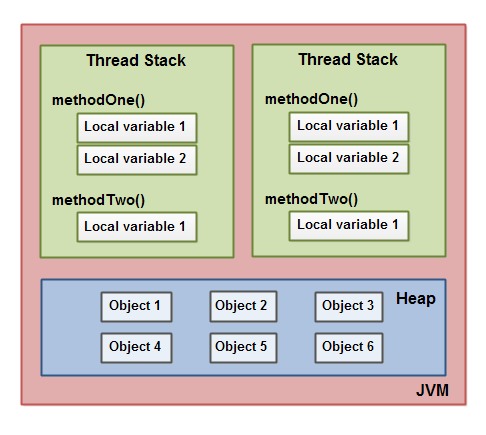
一個本地變量可能是原始類型,在這種情況下,它總是“呆在”線程棧上。
一個本地變量也可能是指向一個對象的一個引用。在這種情況下,引用(這個本地變量)存放在線程棧上,但是對象本身存放在堆上。
一個對象可能包含方法,這些方法可能包含本地變量。這些本地變量還是存放在線程棧上,即使這些方法所屬的對象存放在堆上。
一個對象的成員變量可能隨著這個對象自身存放在堆上。不管這個成員變量是原始類型還是引用類型。
靜態成員變量跟隨著類定義一起也存放在堆上。
存放在堆上的對象可以被所有持有對這個對象引用的線程訪問。當一個線程可以訪問一個對象時,它也可以訪問這個對象的成員變量。如果兩個線程同時調用同一個對象上的同一個方法,它們將會都訪問這個對象的成員變量,但是每一個線程都擁有這個本地變量的私有拷貝。
下圖演示了上面提到的點:

兩個線程擁有一些列的本地變量。其中一個本地變量(Local Variable 2)執行堆上的一個共享對象(Object 3)。這兩個線程分別擁有同一個對象的不同引用。這些引用都是本地變量,因此存放在各自線程的線程棧上。這兩個不同的引用指向堆上同一個對象。
注意,這個共享對象(Object 3)持有Object2和Object4一個引用作為其成員變量(如圖中Object3指向Object2和Object4的箭頭)。通過在Object3中這些成員變量引用,這兩個線程就可以訪問Object2和Object4。
這張圖也展示了指向堆上兩個不同對象的一個本地變量。在這種情況下,指向兩個不同對象的引用不是同一個對象。理論上,兩個線程都可以訪問Object1和Object5,如果兩個線程都擁有兩個對象的引用。但是在上圖中,每一個線程僅有一個引用指向兩個對象其中之一。
因此,什么類型的Java代碼會導致上面的內存圖呢?如下所示:
~~~
public class MyRunnable implements Runnable() {
public void run() {
methodOne();
}
public void methodOne() {
int localVariable1 = 45;
MySharedObject localVariable2 =
MySharedObject.sharedInstance;
//... do more with local variables.
methodTwo();
}
public void methodTwo() {
Integer localVariable1 = new Integer(99);
//... do more with local variable.
}
}
public class MySharedObject {
//static variable pointing to instance of MySharedObject
public static final MySharedObject sharedInstance =
new MySharedObject();
//member variables pointing to two objects on the heap
public Integer object2 = new Integer(22);
public Integer object4 = new Integer(44);
public long member1 = 12345;
public long member1 = 67890;
}
~~~
如果兩個線程同時執行`run()`方法,就會出現上圖所示的情景。`run()`方法調用`methodOne()`方法,`methodOne()`調用`methodTwo()`方法。
`methodOne()`聲明了一個原始類型的本地變量和一個引用類型的本地變量。
每個線程執行`methodOne()`都會在它們對應的線程棧上創建`localVariable1`和`localVariable2`的私有拷貝。`localVariable1`變量彼此完全獨立,僅“生活”在每個線程的線程棧上。一個線程看不到另一個線程對它的`localVariable1`私有拷貝做出的修改。
每個線程執行`methodOne()`時也將會創建它們各自的`localVariable2`拷貝。然而,兩個`localVariable2`的不同拷貝都指向堆上的同一個對象。代碼中通過一個靜態變量設置`localVariable2`指向一個對象引用。僅存在一個靜態變量的一份拷貝,這份拷貝存放在堆上。因此,`localVariable2`的兩份拷貝都指向由`MySharedObject`指向的靜態變量的同一個實例。`MySharedObject`實例也存放在堆上。它對應于上圖中的Object3。
注意,`MySharedObject`類也包含兩個成員變量。這些成員變量隨著這個對象存放在堆上。這兩個成員變量指向另外兩個`Integer`對象。這些`Integer`對象對應于上圖中的Object2和Object4.
注意,`methodTwo()`創建一個名為`localVariable`的本地變量。這個成員變量是一個指向一個`Integer`對象的對象引用。這個方法設置`localVariable1`引用指向一個新的`Integer`實例。在執行`methodTwo`方法時,`localVariable1`引用將會在每個線程中存放一份拷貝。這兩個`Integer`對象實例化將會被存儲堆上,但是每次執行這個方法時,這個方法都會創建一個新的`Integer`對象,兩個線程執行這個方法將會創建兩個不同的`Integer`實例。`methodTwo`方法創建的`Integer`對象對應于上圖中的Object1和Object5。
還有一點,`MySharedObject`類中的兩個`long`類型的成員變量是原始類型的。因為,這些變量是成員變量,所以它們任然隨著該對象存放在堆上,僅有本地變量存放在線程棧上。
### 硬件內存架構
現代硬件內存模型與Java內存模型有一些不同。理解內存模型架構以及Java內存模型如何與它協同工作也是非常重要的。這部分描述了通用的硬件內存架構,下面的部分將會描述Java內存是如何與它“聯手”工作的。
下面是現代計算機硬件架構的簡單圖示:

一個現代計算機通常由兩個或者多個CPU。其中一些CPU還有多核。從這一點可以看出,在一個有兩個或者多個CPU的現代計算機上同時運行多個線程是可能的。每個CPU在某一時刻運行一個線程是沒有問題的。這意味著,如果你的Java程序是多線程的,在你的Java程序中每個CPU上一個線程可能同時(并發)執行。
每個CPU都包含一系列的寄存器,它們是CPU內內存的基礎。CPU在寄存器上執行操作的速度遠大于在主存上執行的速度。這是因為CPU訪問寄存器的速度遠大于主存。
每個CPU可能還有一個CPU緩存層。實際上,絕大多數的現代CPU都有一定大小的緩存層。CPU訪問緩存層的速度快于訪問主存的速度,但通常比訪問內部寄存器的速度還要慢一點。一些CPU還有多層緩存,但這些對理解Java內存模型如何和內存交互不是那么重要。只要知道CPU中可以有一個緩存層就可以了。
一個計算機還包含一個主存。所有的CPU都可以訪問主存。主存通常比CPU中的緩存大得多。
通常情況下,當一個CPU需要讀取主存時,它會將主存的部分讀到CPU緩存中。它甚至可能將緩存中的部分內容讀到它的內部寄存器中,然后在寄存器中執行操作。當CPU需要將結果寫回到主存中去時,它會將內部寄存器的值刷新到緩存中,然后在某個時間點將值刷新回主存。
當CPU需要在緩存層存放一些東西的時候,存放在緩存中的內容通常會被刷新回主存。CPU緩存可以在某一時刻將數據局部寫到它的內存中,和在某一時刻局部刷新它的內存。它不會再某一時刻讀/寫整個緩存。通常,在一個被稱作“cache lines”的更小的內存塊中緩存被更新。一個或者多個緩存行可能被讀到緩存,一個或者多個緩存行可能再被刷新回主存。
### Java內存模型和硬件內存架構之間的橋接
上面已經提到,Java內存模型與硬件內存架構之間存在差異。硬件內存架構沒有區分線程棧和堆。對于硬件,所有的線程棧和堆都分布在主內中。部分線程棧和堆可能有時候會出現在CPU緩存中和CPU內部的寄存器中。如下圖所示:

當對象和變量被存放在計算機中各種不同的內存區域中時,就可能會出現一些具體的問題。主要包括如下兩個方面:
-線程對共享變量修改的可見性
-當讀,寫和檢查共享變量時出現race conditions
下面我們專門來解釋以下這兩個問題。
#### 共享對象可見性
如果兩個或者更多的線程在沒有正確的使用`volatile`聲明或者同步的情況下共享一個對象,一個線程更新這個共享對象可能對其它線程來說是不接見的。
想象一下,共享對象被初始化在主存中。跑在CPU上的一個線程將這個共享對象讀到CPU緩存中。然后修改了這個對象。只要CPU緩存沒有被刷新會主存,對象修改后的版本對跑在其它CPU上的線程都是不可見的。這種方式可能導致每個線程擁有這個共享對象的私有拷貝,每個拷貝停留在不同的CPU緩存中。
下圖示意了這種情形。跑在左邊CPU的線程拷貝這個共享對象到它的CPU緩存中,然后將count變量的值修改為2。這個修改對跑在右邊CPU上的其它線程是不可見的,因為修改后的count的值還沒有被刷新回主存中去。

解決這個問題你可以使用Java中的`volatile`關鍵字。`volatile`關鍵字可以保證直接從主存中讀取一個變量,如果這個變量被修改后,總是會被寫回到主存中去。
#### Race Conditions
如果兩個或者更多的線程共享一個對象,多個線程在這個共享對象上更新變量,就有可能發生[race conditions](http://tutorials.jenkov.com/java-concurrency/race-conditions-and-critical-sections.html)。
想象一下,如果線程A讀一個共享對象的變量count到它的CPU緩存中。再想象一下,線程B也做了同樣的事情,但是往一個不同的CPU緩存中。現在線程A將`count`加1,線程B也做了同樣的事情。現在`count`已經被增在了兩個,每個CPU緩存中一次。
如果這些增加操作被順序的執行,變量`count`應該被增加兩次,然后原值+2被寫回到主存中去。
然而,兩次增加都是在沒有適當的同步下并發執行的。無論是線程A還是線程B將`count`修改后的版本寫回到主存中取,修改后的值僅會被原值大1,盡管增加了兩次。
下圖演示了上面描述的情況:

解決這個問題可以使用[Java同步塊](http://tutorials.jenkov.com/java-concurrency/synchronized.html)。一個同步塊可以保證在同一時刻僅有一個線程可以進入代碼的臨界區。同步塊還可以保證代碼塊中所有被訪問的變量將會從主存中讀入,當線程退出同步代碼塊時,所有被更新的變量都會被刷新回主存中去,不管這個變量是否被聲明為volatile。
- JVM
- 深入理解Java內存模型
- 深入理解Java內存模型(一)——基礎
- 深入理解Java內存模型(二)——重排序
- 深入理解Java內存模型(三)——順序一致性
- 深入理解Java內存模型(四)——volatile
- 深入理解Java內存模型(五)——鎖
- 深入理解Java內存模型(六)——final
- 深入理解Java內存模型(七)——總結
- Java內存模型
- Java內存模型2
- 堆內內存還是堆外內存?
- JVM內存配置詳解
- Java內存分配全面淺析
- 深入Java核心 Java內存分配原理精講
- jvm常量池
- JVM調優總結
- JVM調優總結(一)-- 一些概念
- JVM調優總結(二)-一些概念
- VM調優總結(三)-基本垃圾回收算法
- JVM調優總結(四)-垃圾回收面臨的問題
- JVM調優總結(五)-分代垃圾回收詳述1
- JVM調優總結(六)-分代垃圾回收詳述2
- JVM調優總結(七)-典型配置舉例1
- JVM調優總結(八)-典型配置舉例2
- JVM調優總結(九)-新一代的垃圾回收算法
- JVM調優總結(十)-調優方法
- 基礎
- Java 征途:行者的地圖
- Java程序員應該知道的10個面向對象理論
- Java泛型總結
- 序列化與反序列化
- 通過反編譯深入理解Java String及intern
- android 加固防止反編譯-重新打包
- volatile
- 正確使用 Volatile 變量
- 異常
- 深入理解java異常處理機制
- Java異常處理的10個最佳實踐
- Java異常處理手冊和最佳實踐
- Java提高篇——對象克隆(復制)
- Java中如何克隆集合——ArrayList和HashSet深拷貝
- Java中hashCode的作用
- Java提高篇之hashCode
- 常見正則表達式
- 類
- 理解java類加載器以及ClassLoader類
- 深入探討 Java 類加載器
- 類加載器的工作原理
- java反射
- 集合
- HashMap的工作原理
- ConcurrentHashMap之實現細節
- java.util.concurrent 之ConcurrentHashMap 源碼分析
- HashMap的實現原理和底層數據結構
- 線程
- 關于Java并發編程的總結和思考
- 40個Java多線程問題總結
- Java中的多線程你只要看這一篇就夠了
- Java多線程干貨系列(1):Java多線程基礎
- Java非阻塞算法簡介
- Java并發的四種風味:Thread、Executor、ForkJoin和Actor
- Java中不同的并發實現的性能比較
- JAVA CAS原理深度分析
- 多個線程之間共享數據的方式
- Java并發編程
- Java并發編程(1):可重入內置鎖
- Java并發編程(2):線程中斷(含代碼)
- Java并發編程(3):線程掛起、恢復與終止的正確方法(含代碼)
- Java并發編程(4):守護線程與線程阻塞的四種情況
- Java并發編程(5):volatile變量修飾符—意料之外的問題(含代碼)
- Java并發編程(6):Runnable和Thread實現多線程的區別(含代碼)
- Java并發編程(7):使用synchronized獲取互斥鎖的幾點說明
- Java并發編程(8):多線程環境中安全使用集合API(含代碼)
- Java并發編程(9):死鎖(含代碼)
- Java并發編程(10):使用wait/notify/notifyAll實現線程間通信的幾點重要說明
- java并發編程-II
- Java多線程基礎:進程和線程之由來
- Java并發編程:如何創建線程?
- Java并發編程:Thread類的使用
- Java并發編程:synchronized
- Java并發編程:Lock
- Java并發編程:volatile關鍵字解析
- Java并發編程:深入剖析ThreadLocal
- Java并發編程:CountDownLatch、CyclicBarrier和Semaphore
- Java并發編程:線程間協作的兩種方式:wait、notify、notifyAll和Condition
- Synchronized與Lock
- JVM底層又是如何實現synchronized的
- Java synchronized詳解
- synchronized 與 Lock 的那點事
- 深入研究 Java Synchronize 和 Lock 的區別與用法
- JAVA編程中的鎖機制詳解
- Java中的鎖
- TreadLocal
- 深入JDK源碼之ThreadLocal類
- 聊一聊ThreadLocal
- ThreadLocal
- ThreadLocal的內存泄露
- 多線程設計模式
- Java多線程編程中Future模式的詳解
- 原子操作(CAS)
- [譯]Java中Wait、Sleep和Yield方法的區別
- 線程池
- 如何合理地估算線程池大小?
- JAVA線程池中隊列與池大小的關系
- Java四種線程池的使用
- 深入理解Java之線程池
- java并發編程III
- Java 8并發工具包漫游指南
- 聊聊并發
- 聊聊并發(一)——深入分析Volatile的實現原理
- 聊聊并發(二)——Java SE1.6中的Synchronized
- 文件
- 網絡
- index
- 內存文章索引
- 基礎文章索引
- 線程文章索引
- 網絡文章索引
- IOC
- 設計模式文章索引
- 面試
- Java常量池詳解之一道比較蛋疼的面試題
- 近5年133個Java面試問題列表
- Java工程師成神之路
- Java字符串問題Top10
- 設計模式
- Java:單例模式的七種寫法
- Java 利用枚舉實現單例模式
- 常用jar
- HttpClient和HtmlUnit的比較總結
- IO
- NIO
- NIO入門
- 注解
- Java Annotation認知(包括框架圖、詳細介紹、示例說明)