
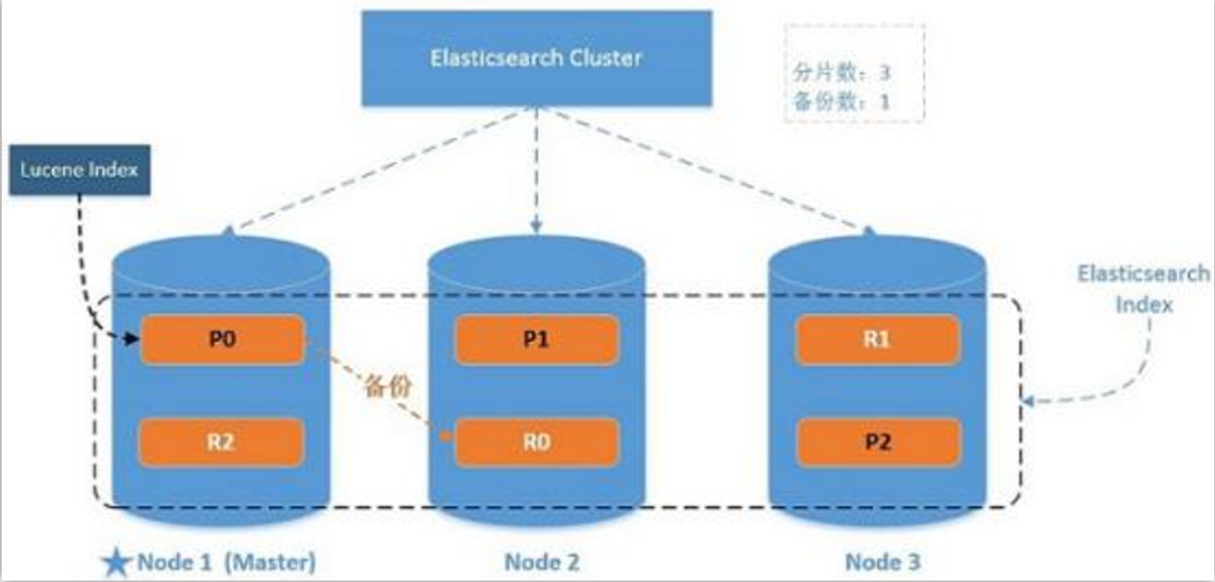
一個運行中的 Elasticsearch 實例稱為一個節點,而集群是由一個或者多個擁有相同 cluster.name 配置的節點組成, 它們共同承擔數據和負載的壓力。當有節點加入集群中或者從集群中移除節點時,集群將會重新平均分布所有的數據。
<br/>
當一個節點被選舉成為主節點時, 它將負責管理集群范圍內的所有變更,例如增加、刪除索引,或者增加、刪除節點等。 而主節點并不需要涉及到文檔級別的變更和搜索等操作,所以當集群只擁有一個主節點的情況下,即使流量的增加它也不會成為瓶頸。 任何節點都可以成為主節點。我們的示例集群就只有一個節點,所以它同時也成為了主節點。
<br/>
作為用戶,我們可以將請求發送到集群中的任何節點 ,包括主節點。 每個節點都知道任意文檔所處的位置,并且能夠將我們的請求直接轉發到存儲我們所需文檔的節點。 無論我們將請求發送到哪個節點,它都能負責從各個包含我們所需文檔的節點收集回數據,并將最終結果返回給客戶端。 Elasticsearch 對這一切的管理都是透明的。
- Elasticsearch是什么
- 全文搜索引擎
- Elasticsearch與Solr
- 數據結構
- 安裝Elasticsearch
- Linux單機安裝
- Windows單機安裝
- 安裝Kibana
- Linux安裝
- Windows安裝
- es基本語句
- 索引操作
- 文檔操作
- 映射操作
- 高級查詢
- es-JavaAPI
- maven依賴
- 索引操作
- 文檔操作
- 高級查詢
- es集群搭建
- Linux集群搭建
- Windows集群搭建
- 核心概念
- 索引(Index)
- 類型(Type)
- 文檔(Document)
- 字段(Field)
- 映射(Mapping)
- 分片(Shards)
- 副本(Replicas)
- 分配(Allocation)
- 系統架構
- 分布式集群
- 單節點集群
- 故障轉移
- 水平擴容
- 應對故障
- 路由計算
- 分片控制
- 寫流程
- 讀流程
- 更新流程
- 多文檔操作流程
- 分片原理
- 倒排索引
- 文檔搜索
- 動態更新索引
- 近實時搜索
- 持久化變更
- 段合并
- 文檔分析
- 內置分析器
- 分析器使用場景
- 測試分析器
- 指定分析器
- 自定義分析器
- 文檔處理
- 文檔沖突
- 樂觀并發控制
- 外部系統版本控制
- es優化
- 硬件選擇
- 分片策略
- 合理設置分片數
- 推遲分片分配
- 路由選擇
- 寫入速度優化
- 批量數據提交
- 優化存儲設備
- 合理使用合并
- 減少Refresh的次數
- 加大Flush設置
- 減少副本的數量
- 內存設置
- 重要配置
- es常見問題
- 為什么要使用Elasticsearch
- master選舉流程
- 集群腦裂問題
- 索引文檔流程
- 更新和刪除文檔流程
- 搜索流程
- ES部署在Linux時的優化方法
- GC方面ES需要注意的點
- ES對大數據量的聚合實現
- 并發時保證讀寫一致性
- 字典樹
- ES的倒排索引
- Spring Data Elasticsearch
- 環境搭建
- 索引操作
- 文檔操作