
隨著按段(per-segment)搜索的發展,一個新的文檔從索引到可被搜索的延遲顯著降低了。新文檔在幾分鐘之內即可被檢索,但這樣還是不夠快。磁盤在這里成為了瓶頸。提交(Commiting)一個新的段到磁盤需要一個 fsync 來確保段被物理性地寫入磁盤,這樣在斷電的時候就不會丟失數據。 但是 fsync 操作代價很大; 如果每次索引一個文檔都去執行一次的話會造成很大的性能問題。
<br/>
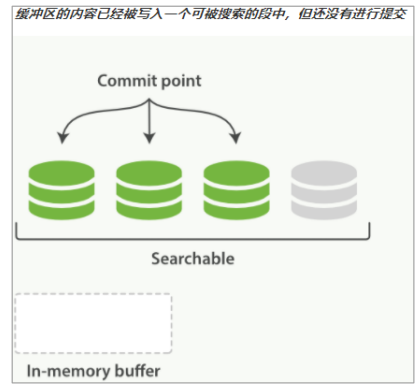
我們需要的是一個更輕量的方式來使一個文檔可被搜索,這意味著 fsync 要從整個過程中被移除。在 Elasticsearch 和磁盤之間是文件系統緩存。 像之前描述的一樣, 在內存索引緩沖區中的文檔會被寫入到一個新的段中。 但是這里新段會被先寫入到文件系統緩存—這一步代價會比較低,稍后再被刷新到磁盤—這一步代價比較高。不過只要文件已經在緩存中,就可以像其它文件一樣被打開和讀取了。
:-: 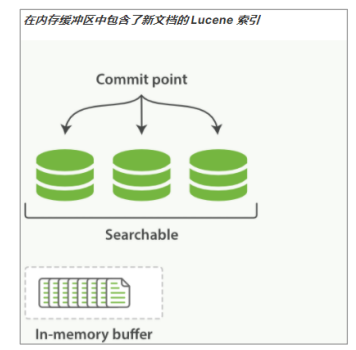
Lucene 允許新段被寫入和打開—使其包含的文檔在未進行一次完整提交時便對搜索可見。這種方式比進行一次提交代價要小得多,并且在不影響性能的前提下可以被頻繁地執行。
:-: 
在 Elasticsearch 中,寫入和打開一個新段的輕量的過程叫做 refresh 。 默認情況下每個分片會每秒自動刷新一次。這就是為什么我們說 Elasticsearch 是 近 實時搜索: 文檔的變化并不是立即對搜索可見,但會在一秒之內變為可見。
<br/>
這些行為可能會對新用戶造成困惑: 他們索引了一個文檔然后嘗試搜索它,但卻沒有搜到。這個問題的解決辦法是用 refresh API 執行一次手動刷新: `/users/_refresh`。
>[info]盡管刷新是比提交輕量很多的操作,它還是會有性能開銷。當寫測試的時候, 手動刷新很有用,但是不要在生產環境下每次索引一個文檔都去手動刷新。 相反,你的應用需要意識到 Elasticsearch 的近實時的性質,并接受它的不足。
并不是所有的情況都需要每秒刷新。可能你正在使用 Elasticsearch 索引大量的日志文件,你可能想優化索引速度而不是近實時搜索, 可以通過設置 `refresh_interval` , 降低每個索引的刷新頻率。
```json
{
"settings": {
"refresh_interval": "30s"
}
}
```
`refresh_interval` 可以在既存索引上進行動態更新。 在生產環境中,當你正在建立一個大的新索引時,可以先關閉自動刷新,待開始使用該索引時,再把它們調回來。
```json
# 關閉自動刷新
PUT /users/_settings
{ "refresh_interval": -1 }
# 每一秒刷新
PUT /users/_settings
{ "refresh_interval": "1s" }
```
- Elasticsearch是什么
- 全文搜索引擎
- Elasticsearch與Solr
- 數據結構
- 安裝Elasticsearch
- Linux單機安裝
- Windows單機安裝
- 安裝Kibana
- Linux安裝
- Windows安裝
- es基本語句
- 索引操作
- 文檔操作
- 映射操作
- 高級查詢
- es-JavaAPI
- maven依賴
- 索引操作
- 文檔操作
- 高級查詢
- es集群搭建
- Linux集群搭建
- Windows集群搭建
- 核心概念
- 索引(Index)
- 類型(Type)
- 文檔(Document)
- 字段(Field)
- 映射(Mapping)
- 分片(Shards)
- 副本(Replicas)
- 分配(Allocation)
- 系統架構
- 分布式集群
- 單節點集群
- 故障轉移
- 水平擴容
- 應對故障
- 路由計算
- 分片控制
- 寫流程
- 讀流程
- 更新流程
- 多文檔操作流程
- 分片原理
- 倒排索引
- 文檔搜索
- 動態更新索引
- 近實時搜索
- 持久化變更
- 段合并
- 文檔分析
- 內置分析器
- 分析器使用場景
- 測試分析器
- 指定分析器
- 自定義分析器
- 文檔處理
- 文檔沖突
- 樂觀并發控制
- 外部系統版本控制
- es優化
- 硬件選擇
- 分片策略
- 合理設置分片數
- 推遲分片分配
- 路由選擇
- 寫入速度優化
- 批量數據提交
- 優化存儲設備
- 合理使用合并
- 減少Refresh的次數
- 加大Flush設置
- 減少副本的數量
- 內存設置
- 重要配置
- es常見問題
- 為什么要使用Elasticsearch
- master選舉流程
- 集群腦裂問題
- 索引文檔流程
- 更新和刪除文檔流程
- 搜索流程
- ES部署在Linux時的優化方法
- GC方面ES需要注意的點
- ES對大數據量的聚合實現
- 并發時保證讀寫一致性
- 字典樹
- ES的倒排索引
- Spring Data Elasticsearch
- 環境搭建
- 索引操作
- 文檔操作