
Elasticsearch 使用一種稱為倒排索引的結構,它適用于快速的全文搜索。
<br/>
見其名,知其意,有倒排索引,肯定會對應有正向索引。正向索引(forward index),反向索引(inverted index)更熟悉的名字是倒排索引。
<br/>
所謂的正向索引,就是搜索引擎會將待搜索的文件都對應一個文件 ID,搜索時將這個ID 和搜索關鍵字進行對應,形成 K-V 對,然后對關鍵字進行統計計數。
:-: 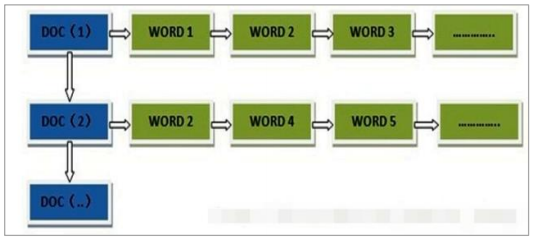
正向索引
但是互聯網上收錄在搜索引擎中的文檔的數目是個天文數字,這樣的索引結構根本無法滿足實時返回排名結果的要求。所以,搜索引擎會將正向索引重新構建為倒排索引,即把文件ID對應到關鍵詞的映射轉換為關鍵詞到文件ID的映射,每個關鍵詞都對應著一系列的文件,這些文件中都出現這個關鍵詞。
:-: 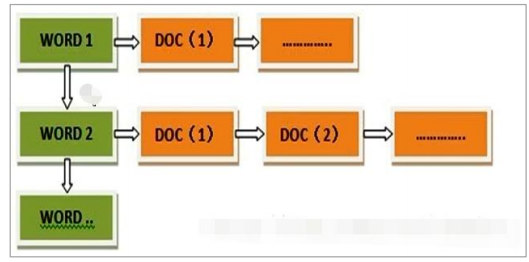
倒排索引
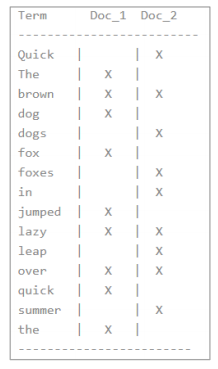
一個倒排索引由文檔中所有不重復詞的列表構成,對于其中每個詞,有一個包含它的文檔列表。例如,假設我們有兩個文檔,每個文檔的 content 域包含如下內容:
* The quick brown fox jumped over the lazy dog
* Quick brown foxes leap over lazy dogs in summer
為了創建倒排索引,我們首先將每個文檔的 content 域拆分成單獨的 詞(我們稱它為 詞條或 tokens ),創建一個包含所有不重復詞條的排序列表,然后列出每個詞條出現在哪個文檔。結果如下所示:
:-: 
現在,如果我們想搜索 quick、brown ,我們只需要查找包含每個詞條的文檔:
:-: 
兩個文檔都匹配,但是第一個文檔比第二個匹配度更高。如果我們使用僅計算匹配詞條數量的簡單相似性算法,那么我們可以說,對于我們查詢的相關性來講,第一個文檔比第二個文檔更佳。
<br/>
但是,我們目前的倒排索引有一些問題:
* Quick 和 quick 以獨立的詞條出現,然而用戶可能認為它們是相同的詞。
* fox 和 foxes 非常相似, 就像 dog 和 dogs ;他們有相同的詞根。
* jumped 和 leap, 盡管沒有相同的詞根,但他們的意思很相近。他們是同義詞。
使用前面的索引搜索 +Quick +fox 不會得到任何匹配文檔。(記住,+ 前綴表明這個詞必須存在。)只有同時出現 Quick 和 fox 的文檔才滿足這個查詢條件,但是第一個文檔包含quick fox ,第二個文檔包含 Quick foxes 。
<br/>
我們的用戶可以合理的期望兩個文檔與查詢匹配。我們可以做的更好。
<br/>
如果我們將詞條規范為標準模式,那么我們可以找到與用戶搜索的詞條不完全一致,但具有足夠相關性的文檔。例如:
* Quick 可以小寫化為 quick 。
* foxes 可以 詞干提取 --變為詞根的格式-- 為 fox 。類似的, dogs 可以為提取為 dog 。
* jumped 和 leap 是同義詞,可以索引為相同的單詞 jump 。
現在索引看上去像這樣:
:-: 
這還遠遠不夠。我們搜索 +Quick +fox 仍然 會失敗,因為在我們的索引中,已經沒有 Quick 了。但是,如果我們對搜索的字符串使用與 content 域相同的標準化規則,會變成查詢+quick +fox,這樣兩個文檔都會匹配!分詞和標準化的過程稱為**分析**。這非常重要。你只能搜索在索引中出現的詞條,所以索引文本和查詢字符串必須標準化為相同的格式。
- Elasticsearch是什么
- 全文搜索引擎
- Elasticsearch與Solr
- 數據結構
- 安裝Elasticsearch
- Linux單機安裝
- Windows單機安裝
- 安裝Kibana
- Linux安裝
- Windows安裝
- es基本語句
- 索引操作
- 文檔操作
- 映射操作
- 高級查詢
- es-JavaAPI
- maven依賴
- 索引操作
- 文檔操作
- 高級查詢
- es集群搭建
- Linux集群搭建
- Windows集群搭建
- 核心概念
- 索引(Index)
- 類型(Type)
- 文檔(Document)
- 字段(Field)
- 映射(Mapping)
- 分片(Shards)
- 副本(Replicas)
- 分配(Allocation)
- 系統架構
- 分布式集群
- 單節點集群
- 故障轉移
- 水平擴容
- 應對故障
- 路由計算
- 分片控制
- 寫流程
- 讀流程
- 更新流程
- 多文檔操作流程
- 分片原理
- 倒排索引
- 文檔搜索
- 動態更新索引
- 近實時搜索
- 持久化變更
- 段合并
- 文檔分析
- 內置分析器
- 分析器使用場景
- 測試分析器
- 指定分析器
- 自定義分析器
- 文檔處理
- 文檔沖突
- 樂觀并發控制
- 外部系統版本控制
- es優化
- 硬件選擇
- 分片策略
- 合理設置分片數
- 推遲分片分配
- 路由選擇
- 寫入速度優化
- 批量數據提交
- 優化存儲設備
- 合理使用合并
- 減少Refresh的次數
- 加大Flush設置
- 減少副本的數量
- 內存設置
- 重要配置
- es常見問題
- 為什么要使用Elasticsearch
- master選舉流程
- 集群腦裂問題
- 索引文檔流程
- 更新和刪除文檔流程
- 搜索流程
- ES部署在Linux時的優化方法
- GC方面ES需要注意的點
- ES對大數據量的聚合實現
- 并發時保證讀寫一致性
- 字典樹
- ES的倒排索引
- Spring Data Elasticsearch
- 環境搭建
- 索引操作
- 文檔操作