
當我們使用 index API 更新文檔 ,可以一次性讀取原始文檔做我們的修改,然后重新索引整個文檔 。 最近的索引請求將獲勝:無論最后哪一個文檔被索引,都將被唯一存儲在 Elasticsearch 中。如果其他人同時更改這個文檔,他們的更改將丟失。
<br/>
很多時候這是沒有問題的。也許我們的主數據存儲是一個關系型數據庫,我們只是將數據復制到 Elasticsearch 中并使其可被搜索。 也許兩個人同時更改相同的文檔的幾率很小。或者對于我們的業務來說偶爾丟失更改并不是很嚴重的問題。
<br/>
但有時丟失了一個**變更**就是非常嚴重的 。試想我們使用 Elasticsearch 存儲我們網上商城商品庫存的數量, 每次我們賣一個商品的時候,我們在 Elasticsearch 中將庫存數量減少。有一天,管理層決定做一次促銷。突然地,我們一秒要賣好幾個商品。 假設有兩個 web 程序并行運行,每一個都同時處理所有商品的銷售。
:-: 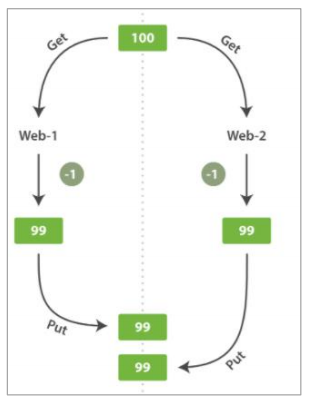
web_1 對 stock_count 所做的更改已經丟失,因為 web_2 不知道它的 stock_count 的拷貝已經過期。 結果我們會認為還有庫存,但實際上已經沒有庫存了,賣給用戶一個已經沒有庫存商品的情況是非常槽糕的。
<br/>
變更越頻繁,讀數據和更新數據的間隙越長,也就越可能丟失變更。
<br/>
在數據庫領域中,有兩種方法通常被用來確保并發更新時變更不會丟失:
(1)悲觀并發控制
這種方法被關系型數據庫廣泛使用,它假定有變更沖突可能發生,因此阻塞訪問資源以防止沖突。 一個典型的例子是讀取一行數據之前先將其鎖住,確保只有放置鎖的線程能夠對這行數據進行修改。
(2)樂觀并發控制
Elasticsearch 中使用的這種方法假定沖突是不可能發生的,并且不會阻塞正在嘗試的操作。 然而,如果源數據在讀寫當中被修改,更新將會失敗。應用程序接下來將決定該如何解決沖突。 例如,可以重試更新、使用新的數據、或者將相關情況報告給用戶。
- Elasticsearch是什么
- 全文搜索引擎
- Elasticsearch與Solr
- 數據結構
- 安裝Elasticsearch
- Linux單機安裝
- Windows單機安裝
- 安裝Kibana
- Linux安裝
- Windows安裝
- es基本語句
- 索引操作
- 文檔操作
- 映射操作
- 高級查詢
- es-JavaAPI
- maven依賴
- 索引操作
- 文檔操作
- 高級查詢
- es集群搭建
- Linux集群搭建
- Windows集群搭建
- 核心概念
- 索引(Index)
- 類型(Type)
- 文檔(Document)
- 字段(Field)
- 映射(Mapping)
- 分片(Shards)
- 副本(Replicas)
- 分配(Allocation)
- 系統架構
- 分布式集群
- 單節點集群
- 故障轉移
- 水平擴容
- 應對故障
- 路由計算
- 分片控制
- 寫流程
- 讀流程
- 更新流程
- 多文檔操作流程
- 分片原理
- 倒排索引
- 文檔搜索
- 動態更新索引
- 近實時搜索
- 持久化變更
- 段合并
- 文檔分析
- 內置分析器
- 分析器使用場景
- 測試分析器
- 指定分析器
- 自定義分析器
- 文檔處理
- 文檔沖突
- 樂觀并發控制
- 外部系統版本控制
- es優化
- 硬件選擇
- 分片策略
- 合理設置分片數
- 推遲分片分配
- 路由選擇
- 寫入速度優化
- 批量數據提交
- 優化存儲設備
- 合理使用合并
- 減少Refresh的次數
- 加大Flush設置
- 減少副本的數量
- 內存設置
- 重要配置
- es常見問題
- 為什么要使用Elasticsearch
- master選舉流程
- 集群腦裂問題
- 索引文檔流程
- 更新和刪除文檔流程
- 搜索流程
- ES部署在Linux時的優化方法
- GC方面ES需要注意的點
- ES對大數據量的聚合實現
- 并發時保證讀寫一致性
- 字典樹
- ES的倒排索引
- Spring Data Elasticsearch
- 環境搭建
- 索引操作
- 文檔操作