# 同時閱讀上百篇文章?漸進閱讀之程序員視角(IRAPP)
> 作者:[葉峻峣](https://www.zhihu.com/people/L.M.Sherlock)
作為一名計算機的學生,漸進閱讀令我非常印象深刻。因為**漸進閱讀**(incremental reading)讓我看到了,在學習上實現**并發**(concurrency)的可能性。
> 注:漸進閱讀是我的翻譯習慣,在其他文本中也被譯作增量閱讀
當然,考慮到本文讀者并非都是計算機專業,也不一定都學過操作系統,筆者盡可能用最通俗的語言來介紹——什么是漸進閱讀。
注:本文**不會**介紹 SuperMemo 的具體操作,留個坑下次填。
> PS:留個彩蛋,猜一下題目中的 IRAPP 是什么的縮寫?
## 目錄
[TOC=2,4]
## 回顧線性閱讀
**漸進閱讀**是從傳統的**線性閱讀**發展而來的,想要介紹漸進閱讀就避不開對線性閱讀的分析。
讓我們從一個例子說起:
小葉是一名計算機專業的學生,想要學習操作系統相關的知識。于是他拿起一本《計算機操作系統》開始閱讀:
~~~text
第三章 處理機調度與死鎖
3.1 處理機調度的層次 ........................................84
3.1.1 高級調度.....................................................84
3.1.2 低級調度.....................................................86
3.1.3 中級調度.....................................................87
3.2 調度隊列模型和調度準則...............................88
3.2.1 調度隊列模型..............................................88
3.2.2 選擇調度方式和調度算法的若干準則..........90
3.3 調度算法 .......................................................91
3.3.1 先來先服務和短作業(進程)優先調度算法....91
3.3.2 高優先權優先調度算法...............................93
3.3.3 基于時間片的輪轉調度算法........................95
3.4 實時調度 ......................................................97
3.4.1 實現實時調度的基本條件...........................97
3.4.2 實時調度算法的分類 .................................99
3.4.3 常用的幾種實時調度算法.........................100
。。。
~~~
小葉今天非常有時間,想要一口氣學完這些內容。于是他開始從 3.3 節讀到了 3.4 節。他遇到了個問題:
~~~text
如選擇太長的時間片,使得每個進程都能在一個時間片內完成, 時間片輪轉算法便退化為 FCFS 算法,無法滿足交互式用戶的需求。
~~~
???FCFS**是啥來著**??
:-: 
好像前面的 3.1.1 有講過,趕緊**回去翻一下**。哦,原來 FCFS 是先來先服務啊,好的我曉得了,繼續看。
~~~text
對于一些小型實時系統,如果能預知任務的開始截止時間,則對實時任務的調度可采用非搶占調度機制,以簡化調度程序和對任務調度時所花費的系統開銷。但在設計這種調度機制時,應使所有的實時任務都比較小,并在執行完關鍵性程序和臨界區后,能及時地 將自己阻塞起來,以便釋放出處理機,供調度程序去調度那種開始截止時間即將到達的 任務。
~~~
嗯?臨界區?
:-: 
好像有印象,不管了,**先記住再說**。
幾個小時后,小葉筋疲力盡地看完了這個章節,卻覺得自己腦中**一團亂麻**,好像沒有學會什么。
。。。
大家在線性閱讀時是不是經常遇到這種問題:
后文要求前文作為**預備知識**,而我們老是**看了后文忘前文**,需要經常回去看前文,浪費不少時間?而且**一直記著**幾個關鍵詞,總會影響自己**深入思考**正在閱讀的文本?
這就是線性閱讀的問題:被動的閱讀讓知識在我們的**工作記憶**中短暫停留,又很快的溜走。一旦忘記了**預備知識**,就會增大**理解**后文的難度。
> 類比
>
> 試著把我們的大腦當做一個計算機,那么閱讀就像進行**I/0 操作**。通過閱讀,我們把信息從書本、網頁上讀入大腦的**工作記憶**。
>
> 而工作記憶,就像**緩存**,**讀寫速度快**,但是**容量**極其**有限**。
>
> 當我們進行線性閱讀時,很快就會達到工作記憶的**瓶頸**。就像 I/O 操作已經用掉了大部分緩存。
>
> 如果我們遇到需要**預備知識**,但是在工作記憶里**找不到**時,我們就需要**返回**前文重新閱讀。就像 CPU 處理發現所需數據**不在**緩存里,需要**重新進行 I/0 操作**。
>
> 顯而易見的是,I/0 操作的速度比讀取緩存慢幾個數量級。
當然,這里我們忘記了一種更為關鍵的記憶——**長期記憶**。如果我們能把前文的知識轉入長期記憶,就可以避免返回前文閱讀,直接把長期記憶調入**工作記憶**即可。
> 類比
>
> 長期記憶可以比作**內存**,從內存中讀寫雖然沒有緩存快,但是要遠比 I/O 操作快得多。
那么我們該怎么把知識裝入**長期記憶**?答案是[**主動回憶**](https://www.yuque.com/supermemo/wiki/active_recall)+[**間隔重復**](https://zhuanlan.zhihu.com/p/305651556)。
唉?這個不是用 Anki 就行了,為啥還要 SuperMemo?
別急,接下來就是 SuperMemo 核心功能的介紹啦!
## 初識漸進閱讀
把知識裝入長期記憶,并不是一件簡單的事情,需要主動回憶和間隔重復。主動回憶,需要我們針對知識提問,明確知識的用途和使用條件。間隔重復,需要我們在日后時不時來回顧知識,讓知識保留的更長久。
所以,知識進入長期記憶需要不少時間,甚至可以說這個時間是**以天為單位**計算的。而我們在線性閱讀中沒有把**預備知識**裝入長期記憶,閱讀后文時必然遇到**理解障礙**。
如果我們不顧**理解障礙**繼續閱讀,會**越來越懵**。如果再把這種不理解的知識強行記住,不僅會很快忘記,還會損害我們的**學習動力**。
> 詳見:[無語義學習](https://zhuanlan.zhihu.com/p/295053968)
而且,其實**知識碎片化**也是理解障礙的一個負面結果。沒有理解的死記硬背,導致知識之間的聯系不能形成[連貫](https://zhuanlan.zhihu.com/p/264327134)的記憶,我們只記住了知識的形式(即字面表述)。
> 詳見:[不要在沒有理解之前就去記憶](https://zhuanlan.zhihu.com/p/281085595)
那么該怎么辦呢?讓我們看看計算機是怎么做的:
> 類比
>
> 把閱讀一篇文章視作一個進程(稱為進程 R),遇到需要前置知識而在記憶中又找不到,就像一個進程請求不到它所需要的資源。
>
> 請求不到資源的進程 R 會占用 CPU,但它又不干活,白白浪費 CPU 的時間。
>
> 為了提高 CPU 的利用率,我們需要將進程 R 阻塞,轉而讓其他進程(比如閱讀另一篇文章)使用 CPU。
>
> 阻塞的進程 R 則需等待請求的資源(預備知識)安排到位,才可繼續執行。
>
> 那么我們可以把形成長期記憶視為另一個進程(稱為進程 M)。形成長期記憶需要睡眠鞏固、主動回憶和間隔重復。睡眠鞏固并不占用白天的時間,所以進程 M 會在間隔重復時和進程 R 在白天交替使用 CPU 來做主動回憶。
>
> 當進程 M 執行后,知識進入了長期記憶,進程 R 就可以準備就緒,等待運行了。
>
> 總結一下,閱讀文章和間隔重復需要互相合作,閱讀文章可以提供所需要記憶的知識,但也需要預備知識的幫助,間隔重復則可以把知識裝入長期記憶,以供后續閱讀使用。
:-: 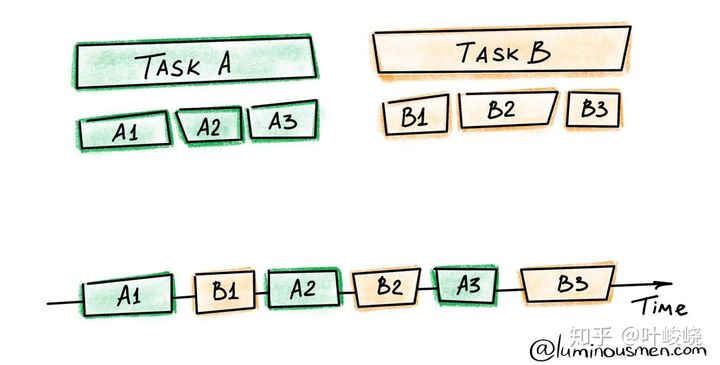
漸進閱讀,其實就是這個思想的體現:閱讀一篇文章,把目前可以理解的內容(即那些已經有預備知識幫助的內容)制作成問答卡片,以供間隔重復和主動回憶來將新的知識裝入長期記憶。當讀到不理解的內容,停止閱讀,開始閱讀其他文章。
等等,閱讀其他文章?那之前的文章怎么辦?
放心,我們只是暫時不繼續閱讀,直到我們做好準備,再進行下一次閱讀。
這就是漸進閱讀的意思——**循序漸進**,保證每一次閱讀都建立在**理解**和**記憶**預備知識的基礎之上。
> 類比
>
> 當我們有很多文章要閱讀時,就像計算機中有大量進程 R 要處理。
>
> 閱讀的過程中,我們需要對每個能夠理解的知識點進行長期記憶。就像計算機中需要對進程 R 中得到的知識調用進程 M 來將知識裝入內存。
>
> 為了避免在閱讀中因為沒有預備知識而卡住,我們需要換一篇文章閱讀。就像計算機將請求資源的進程 R 阻塞,讓其他進程 R 使用 CPU。
>
> 形成長期記憶需要睡眠、主動回憶和間隔重復,就像計算機調用進程 M 將知識寫入并保持在內存。
這么一看,漸進閱讀似乎挺簡單的,但是要明白,并發并不是免費的,并發帶來了極大的收益,也帶來了不少相關的問題:
1. 跳過的文章什么時候閱讀?
2. 該怎么制作易于記憶和使用的問答卡片?
3. 怎么安排問答卡片的間隔重復?
4. 怎么交錯閱讀與記憶?
5. 我想讀和想記的東西太多了,怎么權衡?
現在想來,Anki 本身只能解決問題 3,其他環節只能由使用者自己解決。而 SuperMemo 能解決 1,3,4,5,并且輔助使用者解決問題 2。
## 深入漸進閱讀
關于問題 3,筆者已經翻譯或介紹了很多相關理論和技術,在此處不再贅述,詳情請見:[記憶的雙組分模型](https://zhuanlan.zhihu.com/p/179076885)。
關于問題 1,4,5,SuperMemo 提出了優先級隊列的概念。(是不是很像操作系統里的進程調度?[沃茲尼亞克](https://zhuanlan.zhihu.com/p/303204832) 博士果然是計算機專業出身233)
關于問題 2,SuperMemo 將漸進閱讀劃分為 6 個動作:導入、閱讀、改寫、摘錄、挖空、回憶。這是漸進的重中之重。
### 優先級隊列
在優先級隊列中,所有的問答卡片和文章都會有不同的優先級,根據優先級大小排序。
通過優先級隊列,SuperMemo 會保證高優先級(排名靠前)的內容優先出現。如果我們無法完成每天的所有閱讀和記憶,SuperMemo 可以自動延遲低優先級的內容,幫助我們權衡學習與時間。
:-: 
注:T 表示文章,L 表示問答卡片
詳情請見:[Priority queue 優先級隊列](https://www.yuque.com/supermemo/wiki/priority_queue)
### 漸進的 6 個動作
#### 導入
導入,是我們漸進的第一步。導入什么內容,之后的一系列加工都會以此為基礎。
如果我們把 SuperMemo 視作我們每日的學習工具,我們就必須慎重選擇導入的材料,因為低質的文章只會浪費我們的時間。
同時,這也是我們學習動力的表現。我們的學習動力會驅使我們選擇感興趣的材料,但是我們依然要對學習內容進行一些挑選,這里是幾個我認為比較有用的挑選標準:
1. 基礎先于實用
2. 興趣先于功利
第一條很好理解,知識不僅在一本書中有前后依賴關系,在一個領域中也是如此。打好基礎對學會后續實用的內容有很大幫助,甚至可以說沒有基礎就難以學習后續的知識。舉個例子,就比如只有學習了 C 語言、計算機組成原理、數據結構,我們才有辦法理解操作系統中的知識。
第二條怎么理解呢?這又是一個很大的話題了,這里就簡單說一下真正的興趣該怎么判斷:
三分鐘熱度、動機帶有【功利】因素、來自【外在】的動機、【純感官】的刺激導致的行為、【被動】的行為、始終停留在【心理舒適區】,不是真正的興趣。
動機來自內心、持續時間長達多年、思維高度參與、愿意付出較高的代價、持續的自我提升(走出心理舒適區)存在【心流】(物我兩忘)的現象,才是真正的興趣。
這樣看來,可能我對 Anki 和 SuperMemo 這類學習工具可能有著真正的興趣,2333(當然,寫知乎也很快樂哈哈)
關于學習的樂趣,詳情請見:[6 學習內驅力和獎勵](https://zhuanlan.zhihu.com/p/64571517)
#### 閱讀
導入了文章,自然是要閱讀。關于如何閱讀,大家讀了這么多年書應該都有自己的習慣,我就只講幾個要點:
1. 注意概念和方法
2. 注意論題和結論
第一點很好理解,概念和方法都屬于抽象知識,適用的范圍很廣泛(比如進程的概念被用于理解學習和記憶,進程調度的方法被用于漸進閱讀),這種內容是閱讀中最需要理解的內容。
第二點也很好理解,抓住文章主旨,可以讓我們更好判斷哪些是作者偏題的信息(233,作者也不是完美的),選擇與主題最相關的內容閱讀,并要盡快明白文章的結論,方便后續分析論證。
#### 改寫
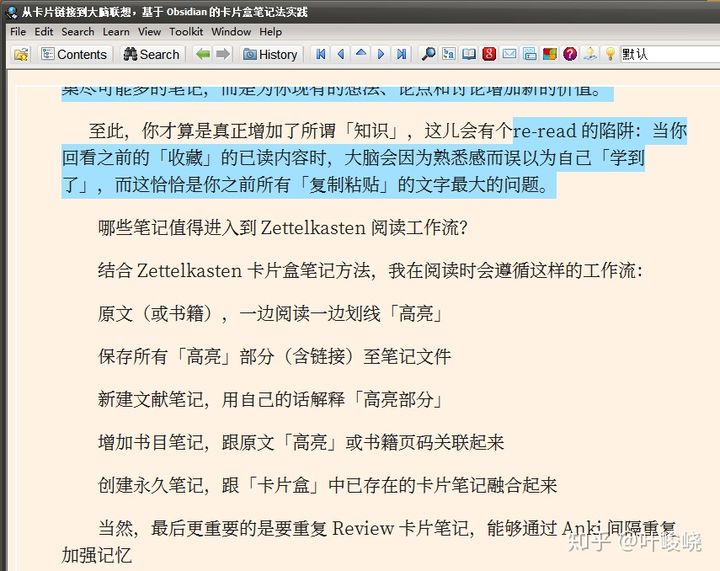
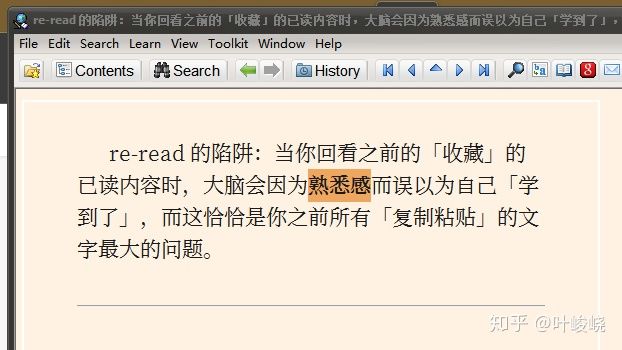
改寫往往是被人忽略的一個關鍵步驟。有時候我們對一段內容十分熟悉,但是真要運用的時候卻發揮不出來。這就是“熟悉感”在欺騙我們,以為我們學會了。
另外,改寫也是為了方便后續處理,比如補充一下文章里的指代。將代詞替換為指代對象,避免之后復習時看到他、它、她,一臉懵逼。
改寫還有一個好處,就是能把句子的組織邏輯拆散,還原為知識本身的邏輯。如何理解?看看這個例子就懂了:
:-: 
改寫還能顯著降低我們的記憶難度,詳情請見:[基于主動回憶的學習中的知識結構與表述](./2454062)
#### 摘錄
漸進里的摘錄就像畫重點:
:-: 
不過與劃重點不同之處在于,漸進閱讀中摘錄的重點會變成一篇新的文章,加入隊列等待閱讀。
:-: 
這樣的好處就是,我們可以不必馬上制作問答卡片,而是讓這些片段再飛一會兒,這些復雜的片段會在不斷的改寫和摘錄中變成表述良好的知識。
#### 挖空
挖空可以說是制作問答卡片最方便的方法:
:-: 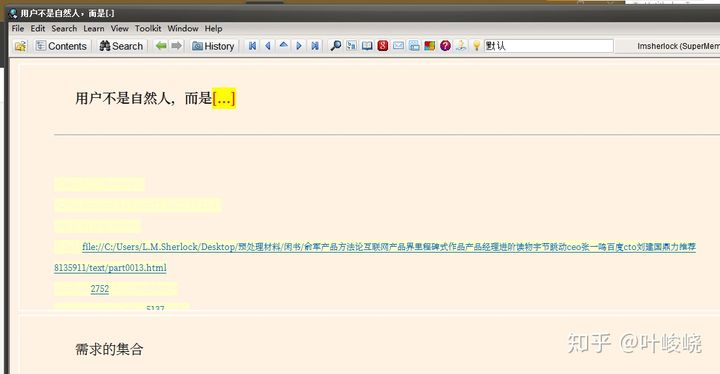
在制作問答卡片時,我們往往要復制很多相同的內容。而通過挖空,我們只需要在原句上一鍵生成。
當然,挖空也有它的問題所在:太多的提示信息、不明的提問指向,等等。這需要我們進一步改寫才能解決。
但是改寫要花的時間可能比低優先級知識的復習時間還長,這顯然是不合算的,所以在漸進中我們還要做出取舍。
詳情請見:[間隔重復中的簡化與冗余](https://zhuanlan.zhihu.com/p/283017134)
#### 回憶
主動回憶、測試效應這些內容說過很多了,他們的效果是有科學證明的,詳情請見:[【理論】測試效應——什么?考試有助于我的學習?](https://zhuanlan.zhihu.com/p/57113246)
我想強調的重點是,知識是自己的,對知識負責,也是對自己負責。根據自己的反饋嚴格打分,對算法和對自己都有好處。
## 結語
漸進學習其實并不是一個復雜的概念,但是在學習上實現并發確實很反直覺。希望本文能夠幫大家理清思路,理解到漸進學習的核心。哪怕不使用 SuperMemo,漸進學習的思想或許也能在大家的學習生活中發揮作用。
祝大家學習順利!
2020 年 11 月 23 日
葉峻峣
> 彩蛋揭曉:
>
> IRAPP 就是 Incremental Reading: A Programmer's Perspective,致敬一下 CSAPP,23333
