# SuperMemo 的三大模塊,解決記憶的三大問題!
> 作者:[葉峻峣](https://www.zhihu.com/people/L.M.Sherlock)
## 目錄
[TOC=2,2]
## 太長不看
* 記憶算法:解決記憶的數量問題
* 漸進閱讀:解決記憶的質量問題
* 優先級隊列:解決記憶的價值問題
## 引言
好久不見,讀者朋友們!挺久沒寫原創了,今天有了靈感,就來寫寫。
這次我們從更抽象的層次來看看 SuperMemo 是怎樣解決記憶問題的。
單看 SuperMemo 如今**浩如煙海的功能**和**上世紀風格的界面**,不少入門者都覺得 SuperMemo 非常復雜,完全搞不明白這些功能**對記憶有什么幫助**。
:-: 
為了更好地剖析 SuperMemo,我發現從**時間順序**來分析是一條不錯的路徑。
以下就是 SuperMemo 主要模塊引入的時間:
* 記憶算法(始于[SuperMemo 1 (1987)](https://zhuanlan.zhihu.com/p/97887756))
* 漸進閱讀(始于[SuperMemo 10 (2000)](https://super-memory.com/articles/soft/sm10.htm))
* 優先級隊列(始于[SuperMemo 13 (2006)](https://super-memory.com/archive/help2006/new2006.htm))
接下來我們就按照這個順序分析一下,這些模塊分別**解決了什么**問題,以及它們是**如何解決**的。
## 記憶算法
> 可能有些讀者朋友不知道 SuperMemo 的記憶算法有多流行,其 1987 年發布的 SM-2 算法正是 Anki 算法的原型。
那么記憶算法究竟解決了什么問題呢?我們先從**兩個直覺**開始說起:
* 如果我們復習兩次,我們就能更好地記住它。這很明顯,不是嗎?如果我們把它復習三遍,我們可能會記得更清楚。
* 如果我們記住一組知識,它們將逐漸從記憶中消失,即不是一次全部消失。這在生活中很容易觀察到。記憶有不同的壽命。
這兩種直覺應該讓每個人都想知道:我們失去了**多少**知識,速度有**多快**?我們下一次應該**什么時候**復習?
當我們問出這些問題之時,人類記憶規律之門便打開了。
記憶與遺忘本質上是一個**隨機過程**。而記憶算法,則是對這個隨機過程的建模與優化,從而計算出最佳的**復習間隔**。
可能有人會問,這還需要建模?還需要算法?我自己安排個 1 3 5 7 天不就行了?
誠然,只要有復習,就會有效果,復習的間隔無非是影響效果的一個變量罷了。
但是這句話就跟「只要有努力,就會有效果,怎樣努力無非是影響學習的一個變量罷了」一樣無用。
事實證明,復習間隔**太長**和**太短**,都會**加重復習**的負擔。
:-: 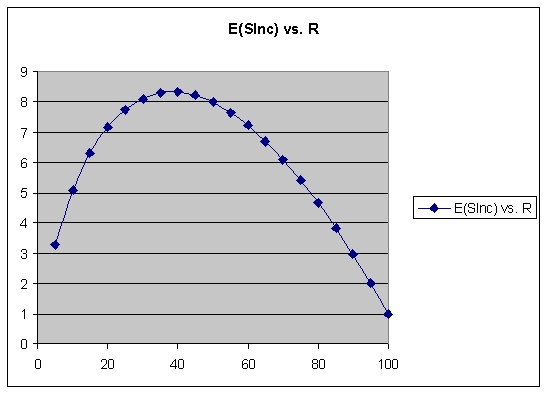
如何理解?間隔短,可以保證自己忘得少,但是這是用時間換的。間隔長,看似可以節省時間,然而其造成的遺忘需要未來更多的復習。
當我們通過算法,在遺忘與復習量之間計算出均衡點,便能最大化地提高復習的效率,也就是**記憶的數量**。
### 小結
**記憶算法**,解決的是記憶的**數量**問題,即如何用**有限**的時間記住**更多**的知識。
**記憶算法**,通過對記憶的**建模**與**優化**,計算出最佳的**復習間隔**,從而解決上述問題。
更多有關記憶算法的內容,請見我的收藏夾:
[Spaced Repetition - 收藏夾](https://www.zhihu.com/collection/644178787)
## 漸進閱讀
漸進閱讀又是解決個啥問題呢?我們先不提它,先講講有了記憶算法后,我們遇到了什么問題:
* 我用「映射法」背單詞,他用「例句法」背單詞,為什么我忘得更快?
* 同九年,汝何秀?為什么我用葉哥的牌組還是記不住?
* 《批量制卡——從入門到刪庫》
* 。。。
從這些問題中,我們可以歸納出一個共同點:**記憶的質量**太差。
即使我們使用相同的記憶算法,不同的記憶內容依然會造成差異;甚至對于相同的內容,是否是自己制作也能產生顯著的不同。
這正是記憶的**質量**問題。知識的表述方式、對知識的理解等等,都會影響我們記憶的**質量**。
有閱讀過這個收藏夾內文章的朋友應該能夠明白,知識表述對記憶質量有很大的影響:
[制卡原則與知識表述 - 收藏夾](https://www.zhihu.com/collection/614280525)
而許多 Anki 用戶在這個問題上有三種因對方式:
* 用別人的牌組
* 批量制卡
* 自己做
前兩種方法就是放棄記憶的質量,節省自己前期的投入,然后在將來還債。
**自己做**固然有助于提高記憶質量,但是由于我們的理解是不斷改進的,制卡經常需要**頻繁改動**,而且用自己的語言表述學到的知識,是一個**巨大的工程**。這使許多同學**望而卻步**。
而**漸進閱讀**,解決正是解決這個問題的一大有力工具。
漸進閱讀將閱讀、改寫、制卡等環節打通,實現學習、理解、記憶的漸進過程,對記憶的質量有顯著的提高。
以我自己為例:
:-: 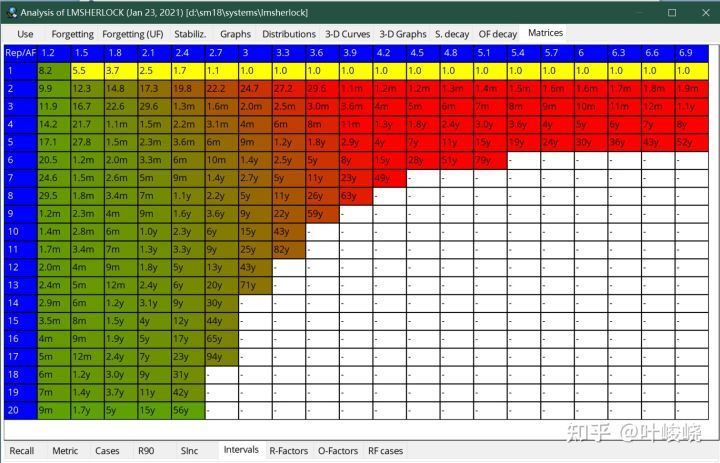
SuperMemo 的算法通過對我個人復習情況的擬合,計算出了不同難度、不同復習次數下對應的最佳復習間隔。可以看到第一個間隔已經有 8 天左右,而如果我的卡片做得非常爛,那么這個間隔可能就只有 1 天。
### 小結
**漸進閱讀**,解決的是記憶的**質量**問題,即如何提高讓自己的記憶**更加穩固**,**更難遺忘**。
**漸進閱讀**,通過打通閱讀到制卡的一系列環節,增進我們對知識的理解,從而解決上述問題。
## 優先級隊列
什么?怎么還有問題?漸進+算法還不夠用嗎?
哈哈,不同階段有不同階段的問題,這是個循序漸進的過程。當記憶算法解決了記憶的數量問題后,自然會有人開始重視記憶的質量問題。而漸進閱讀解決了這一問題后,大量卡片能夠輕松地通過摘錄、挖空產生。漸漸地,有些人發現,哪怕算法效率再高、記憶質量再好,自己也已經復習不過來了。
怎么辦呢?根據我們人類的天性,一個字:**拖**。
別驚訝,[理性拖延](https://zhuanlan.zhihu.com/p/350725699)是現代人的必修課。我們總會把不那么緊急或者重要的事情往后拖。事后來看,有些拖延確實是正確的選擇。
通過拖延,我們把時間、精力投入到更有價值的事情上。在記憶上同樣適用,我們想要解決的是**記憶的價值問題**。
舉個栗子:我喜歡看社科類的書,比如社會心理學、思考快與慢等等,我把它們放入 SuperMemo 中漸進閱讀。同時我是計算機專業的學生,有很多關于操作系統、數據庫的知識也同樣放在 SuperMemo 里。而我每天的復習時間有限,不能把它們都學完。那該怎么辦呢?
:-: 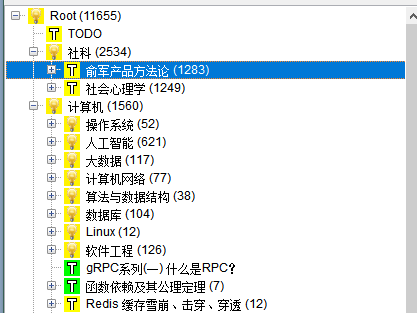
從我個人的角度來看,看社科書主要是業余愛好,而計算機才是主業,所以計算機相關知識的價值更高。
如果我用 Anki,我可能會先學完計算機的牌組,然后再學社科牌組。并且社科牌組經常復習不完,不斷堆積。
如果我用 SuperMemo,我給計算機更高的優先級,那么我在復習時會更頻繁地遇到計算機的卡片,但是也會隨機地遇到一些社科類的卡片,從而更好的 balance 兩者。
更重要的是,即使是業余愛好,社科里也有高價值的知識,即使是專業,計算機里也有低價值的知識。
通過牌組這種形式的組織方式,無法處理上述的情況。那么,優先級隊列便有其不可替代的優勢了。
### 小結
**優先級隊列**,解決的是記憶的**價值**問題,即如何在有限的時間里記憶更多**有價值**的知識。
**優先級隊列**,通過對知識標記優先級,再根據優先級安排**每日復習的順序**,從而解決上述問題。
以下是另外一篇介紹優先級隊列的文章,有興趣不妨看看:
[漸進閱讀:卡片刷不完?擁抱優先級!](./2450604)
## 結語
記憶的數量、質量和價值,正是衡量我們學習效果的三個維度。SuperMemo 的歷史,也是解決這些問題的發展史。任何學習軟件,恐怕都繞不開這些問題。
當然,不同的學習軟件都有自己應對這些問題的解決方案,百花齊放,百家爭鳴,最大的受益者便是我們這些熱愛學習的人。
不知道各位讀者朋友們是否在自己的學習體系中考慮了上述問題,你們又是如何解決的?歡迎在評論區里交流討論。
感謝各位的閱讀!
2021 年 5 月 5 日
葉峻峣
