
**文本向量化**(vectorize)是指將文本轉換為數值張量的過程
* 將文本分割為單詞,并將每個**單詞**轉換為一個向量。
* 將文本分割為字符,并將每個**字符**轉換為一個向量。
* 提取單詞或字符的 n-gram,并將每個 n-gram 轉換為一個向量。
**n-gram**是多個連續單詞或字符的集合(n-gram 之間可重疊)。
**標記**(token):將文本分解而成的單元(單詞、字符或 n-gram)
**分詞** (tokenization):將文本分解成標記的過程
- 基礎
- 張量tensor
- 整數序列(列表)=>張量
- 張量運算
- 張量運算的幾何解釋
- 層:深度學習的基礎組件
- 模型:層構成的網絡
- 訓練循環 (training loop)
- 數據類型與層類型、keras
- Keras
- Keras 開發
- Keras使用本地數據
- fit、predict、evaluate
- K 折 交叉驗證
- 二分類問題-基于梯度的優化-訓練
- relu運算
- Dens
- 損失函數與優化器:配置學習過程的關鍵
- 損失-二分類問題
- 優化器
- 過擬合 (overfit)
- 改進
- 小結
- 多分類問題
- 回歸問題
- 章節小結
- 機械學習
- 訓練集、驗證集和測試集
- 三種經典的評估方法
- 模型評估
- 如何準備輸入數據和目標?
- 過擬合與欠擬合
- 減小網絡大小
- 添加權重正則化
- 添加 dropout 正則化
- 通用工作流程
- 計算機視覺
- 卷積神經網絡
- 卷積運算
- 卷積的工作原理
- 訓練一個卷積神經網絡
- 使用預訓練的卷積神經網絡
- VGG16
- VGG16詳細結構
- 為什么不微調整個卷積基?
- 卷積神經網絡的可視化
- 中間輸出(中間激活)
- 過濾器
- 熱力圖
- 文本和序列
- 處理文本數據
- n-gram
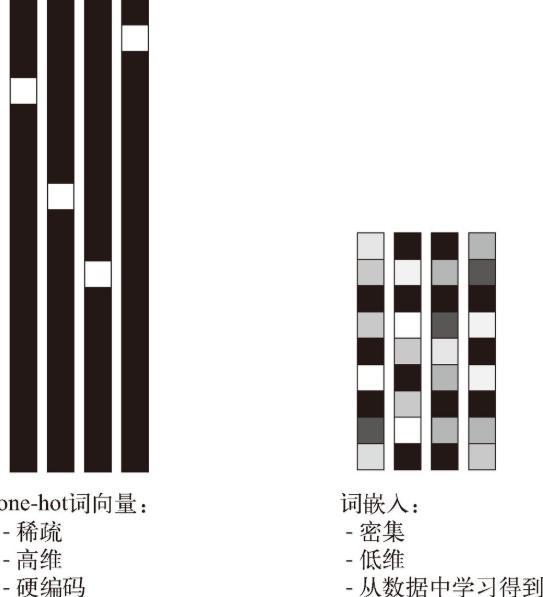
- one-hot 編碼 (one-hot encoding)
- 標記嵌入 (token embedding)
- 利用 Embedding 層學習詞嵌入
- 使用預訓練的詞嵌入
- 循環神經網絡
- 循環神經網絡的高級用法
- 溫度預測問題
- code
- 用卷積神經網絡處理序列
- GRU 層
- LSTM層
- 多輸入模型
- 回調函數
- ModelCheckpoint 與 EarlyStopping
- ReduceLROnPlateau
- 自定義回調函數
- TensorBoard_TensorFlow 的可視化框架
- 高級架構模式
- 殘差連接
- 批標準化
- 批再標準化
- 深度可分離卷積
- 超參數優化
- 模型集成
- LSTM
- DeepDream
- 神經風格遷移
- 變分自編碼器
- 生成式對抗網絡
- 術語表