
1、SparseArray內部使用雙數組,分別存儲Key和Value,Key是int[],用于查找Value對應的Index,來定位數據在Value中的位置。
2、使用二分查找來定位Key數組中對應值的位置,所以Key數組是有序的。
3、使用數組就面臨刪除數據時數據遷移的問題,所以引入了DELETE標記。
## 雙數組

mValue數組和mKey數組的關系是一一對應的,通過Key的值,可以定位出該Key在mKey數組中的index,進而可以操作MValue數組中對應位置的數據。
## 二分查找
```java
public E get(int key, E valueIfKeyNotFound) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i < 0 || mValues[i] == DELETED) {
return valueIfKeyNotFound;
} else {
return (E) mValues[i];
}
}
```
SparseArray源碼中,所有和Key有關的操作,第一步都是先通過二分查找,定位出該Key的index,再進行后續處理。
二分查找的前提條件,就是必須是針對有序并且支持下標隨機訪問的數據結構,所以它在執行插入操作的時候,必須保證 mKey 數據中的數據有序。
SparseArray的插入代碼如下:
```java
public void put(int key, E value) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i >= 0) {
mValues[i] = value;
} else {
i = ~i;
if (i < mSize && mValues[i] == DELETED) {
mKeys[i] = key;
mValues[i] = value;
return;
}
if (mGarbage && mSize >= mKeys.length) {
gc();
// Search again because indices may have changed.
i = ~ContainerHelpers.binarySearch(mKeys, mSize, key);
}
mKeys = GrowingArrayUtils.insert(mKeys, mSize, i, key);
mValues = GrowingArrayUtils.insert(mValues, mSize, i, value);
mSize++;
}
}
```
同樣會使用二分定位查找Key的index,GrowingArrayUtils的insert方法會完成兩個任務:
1、將數據插入到指定數組對應的位置上。
2、如果發現數組空間不夠,就生成一個更大的新數組,將數組通過復制的方式,動態擴容后搬到新數組中,并返回新數組。
## DELETE標記
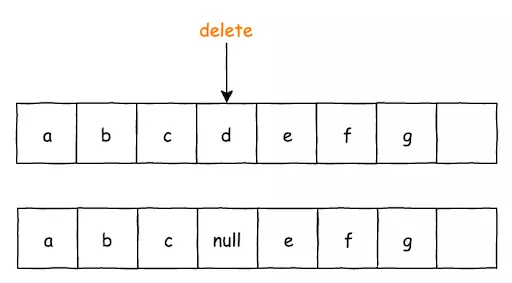
對數組的刪除,如果不做數據遷移,數組中必然存在數據空洞,SparseArray引入DELETE標記,來減少刪除數據時對數據的搬運次數。
在插入時,如遇到DELETE標識,標識當前數據已經刪除掉了,直接進行替換,減少一次插入數據帶來的數據搬運。

DELETE標識是在mValue數組中存儲的,mKey中仍然存儲著它上一次對應數據的Key值。在一些必要條件下,會觸發gc()邏輯,來清理數組中的DELETE標識。在gc()方法中,用了一個布爾類型的mGarbage屬性,來記錄當前 mValue 中,是否存在 DELETE 標識,這是判定是否需要 GC 的依據。SparseArray的**所有和 size 相關的操作**以及**和數組擴容相關的操作**時需要進行gc操作。
## 參考文檔
[https://juejin.im/post/5da1481e6fb9a04de96e8b72](https://juejin.im/post/5da1481e6fb9a04de96e8b72)
- 導讀
- Java知識
- Java基本程序設計結構
- 【基礎知識】Java基礎
- 【源碼分析】Okio
- 【源碼分析】深入理解i++和++i
- 【專題分析】JVM與GC
- 【面試清單】Java基本程序設計結構
- 對象與類
- 【基礎知識】對象與類
- 【專題分析】Java類加載過程
- 【面試清單】對象與類
- 泛型
- 【基礎知識】泛型
- 【面試清單】泛型
- 集合
- 【基礎知識】集合
- 【源碼分析】SparseArray
- 【面試清單】集合
- 多線程
- 【基礎知識】多線程
- 【源碼分析】ThreadPoolExecutor源碼分析
- 【專題分析】volatile關鍵字
- 【面試清單】多線程
- Java新特性
- 【專題分析】Lambda表達式
- 【專題分析】注解
- 【面試清單】Java新特性
- Effective Java筆記
- Android知識
- Activity
- 【基礎知識】Activity
- 【專題分析】運行時權限
- 【專題分析】使用Intent打開三方應用
- 【源碼分析】Activity的工作過程
- 【面試清單】Activity
- 架構組件
- 【專題分析】MVC、MVP與MVVM
- 【專題分析】數據綁定
- 【面試清單】架構組件
- 界面
- 【專題分析】自定義View
- 【專題分析】ImageView的ScaleType屬性
- 【專題分析】ConstraintLayout 使用
- 【專題分析】搞懂點九圖
- 【專題分析】Adapter
- 【源碼分析】LayoutInflater
- 【源碼分析】ViewStub
- 【源碼分析】View三大流程
- 【源碼分析】觸摸事件分發機制
- 【源碼分析】按鍵事件分發機制
- 【源碼分析】Android窗口機制
- 【面試清單】界面
- 動畫和過渡
- 【基礎知識】動畫和過渡
- 【面試清單】動畫和過渡
- 圖片和圖形
- 【專題分析】圖片加載
- 【面試清單】圖片和圖形
- 后臺任務
- 應用數據和文件
- 基于網絡的內容
- 多線程與多進程
- 【基礎知識】多線程與多進程
- 【源碼分析】Handler
- 【源碼分析】AsyncTask
- 【專題分析】Service
- 【源碼分析】Parcelable
- 【專題分析】Binder
- 【源碼分析】Messenger
- 【面試清單】多線程與多進程
- 應用優化
- 【專題分析】布局優化
- 【專題分析】繪制優化
- 【專題分析】內存優化
- 【專題分析】啟動優化
- 【專題分析】電池優化
- 【專題分析】包大小優化
- 【面試清單】應用優化
- Android新特性
- 【專題分析】狀態欄、ActionBar和導航欄
- 【專題分析】應用圖標、通知欄適配
- 【專題分析】Android新版本重要變更
- 【專題分析】唯一標識符的最佳做法
- 開源庫源碼分析
- 【源碼分析】BaseRecyclerViewAdapterHelper
- 【源碼分析】ButterKnife
- 【源碼分析】Dagger2
- 【源碼分析】EventBus3(一)
- 【源碼分析】EventBus3(二)
- 【源碼分析】Glide
- 【源碼分析】OkHttp
- 【源碼分析】Retrofit
- 其他知識
- Flutter
- 原生開發與跨平臺開發
- 整體歸納
- 狀態及狀態管理
- 零碎知識點
- 添加Flutter到現有應用
- Git知識
- Git命令
- .gitignore文件
- 設計模式
- 創建型模式
- 結構型模式
- 行為型模式
- RxJava
- 基礎
- Linux知識
- 環境變量
- Linux命令
- ADB命令
- 算法
- 常見數據結構及實現
- 數組
- 排序算法
- 鏈表
- 二叉樹
- 棧和隊列
- 算法時間復雜度
- 常見算法思想
- 其他技術
- 正則表達式
- 編碼格式
- HTTP與HTTPS
- 【面試清單】其他知識
- 開發歸納
- Android零碎問題
- 其他零碎問題
- 開發思路