
>[success] # 最壞/最好時間復雜度
[下面內容是通過極客時間整理得到的](https://time.geekbang.org/column/article/40447)
~~~
1.下面的代碼是要做,通過n來控制循環多少項,來找到x所在'array'的位
置,利用之前的分析方法,首先直接看運行次數最多的語句,循環句中
控住'數據的規模的大小'n,則整體的運行時間為:T(n) = O(n),這里要說明
這里沒有break 即使找到了也要循環全部才算完事,且這里考慮的情況n是
數組長度
~~~
~~~
function test(array, n,x){
let i = 0
let pos = -1
for(;i<n;i++){
if(array[i] === x) pos = i
}
return pos
}
~~~
>[danger] ##### 改造上面代碼再分析(最好/最壞)
~~~
1.將代碼中加入了break后整個影響整段代碼運行時間不在單單是'n'這個數據
規模,還有一個就是'x'所在位置,x所在位置最優的肯定是在第一位那么復
雜度O(1),最壞的時間復雜度x在整個數組最后一項O(n)
~~~
~~~
function test(array, n,x){
let i = 0
let pos = -1
for(;i<n;i++){
if(array[i] === x) {
pos = i
break
}
}
return pos
}
~~~
>[success] # 平均時間復雜度
~~~
1.剛才分析了最壞/最好的時間復雜度,但代碼不可能都是這種極端的情況
,即最好最壞因此出來了平均時間復雜度概念
2.來分析數組如果是 array = [1,2], 不考慮'n'為0 則也就是一次都不循環的情
況,如果'x'為1 也就是代碼循環一次即找到位置,'x'為2即代碼循環兩次找到
位置,那么他的平均時間則為 (1+2)/2 = 1.5,即得到下面公式
~~~
* 其中n+1為數組長度(因為數組是從0開始計數,因此長度需要加1),分子為出現的情況總和
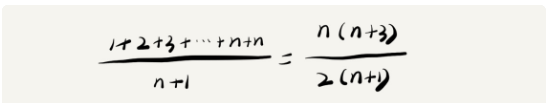
~~~
1.得到上面公式后,再根據之前學的法則,時間復雜度的大 O 標記法中,可
以省略掉系數、低階、常量,所以,咱們把剛剛這個公式簡化之后,得到的
平均時間復雜度就是 O(n)。
~~~
* 考慮概率
~~~
1.實際考慮概率即'x'存在數組和不存在數組這兩種情況,得到的公式如圖
2.則遵循法則得到O(n)
~~~
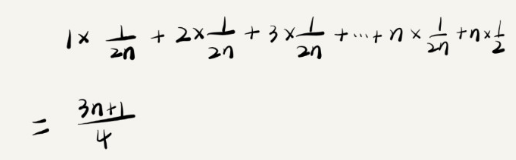
>[success] # 均攤時間復雜度
~~~
1.下面的代碼只有在最特殊的情況下也就是 count 等于array.length時候,他
的復雜度才為O(n),在這之前的復雜度都為O(1)
2.最理想情況下**x!=n**,只執行一次賦值即可推出,所以最好時間復雜度為O(1)。
最壞的情況下**x=n**,要執行一次循環累加和的操作,所以最好時間復雜度為O(n)。
平均的情況下,因為限定條件0<=x<=n,x在0~n中存在的位置可以分為n+1種情況(0到n)。
當**0<=x<n**時,時間復雜度為O(1)。但是**x=n**的時候是一個例外,它的復雜度是O(n)。
而且這n+1種情況發生的概率都是一樣的,為**1n+11n+1。**所以根據加權平均的計算方法,
~~~
* [圖片出處](https://www.cnblogs.com/jonins/p/9956752.html),簡單的說除非當count等于數組長度否則其余復雜度都為1,也正是如此在數組最后一項之前出現的復雜度都為1他們出現的概率為1/n+1,了解清楚后就會得到下面的公式1為復雜度1/n+1 為改復雜度出現的概率當省略系數及常量后,平均時間復雜度為O(1),也就是當把復雜度最高的情況n*(1/n+1)攤還其他 1的情況下最后忽略看成O(1)

~~~
// array 表示一個長度為 n 的數組
// 代碼中的 array.length 就等于 n
int[] array = new int[n];
int count = 0;
void insert(int val) {
if (count == array.length) {
int sum = 0;
for (int i = 0; i < array.length; ++i) {
sum = sum + array[i];
}
array[0] = sum;
count = 1;
}
array[count] = val;
++count;
}
~~~
>[success] # 總結平均和均攤
~~~
1.平均就是在連續沒有規律的情況下使用平均,即可理解當使用find 方法的
時候,是要找的項在每一項不同情況他的運行時間是不一定,即這種情況需要平均即為O(n)
2.均攤當add (js的push)時候只為末尾添加一項,即非要需要的添加項實際無需做處理即為O(1),到達最后一項我們這里是抽象的把push想成到最后
一項去循環所有數組并且添加一項此時為O(n),均攤則為O(1)
~~~
- 接觸數據結構和算法
- 數據結構與算法 -- 大O復雜度表示法
- 數據結構與算法 -- 時間復雜度分析
- 最好、最壞、平均、均攤時間復雜度
- 基礎數據結構和算法
- 線性表和非線性表
- 結構 -- 數組
- JS -- 數組
- 結構 -- 棧
- JS -- 棧
- JS -- 棧有效圓括號
- JS -- 漢諾塔
- 結構 -- 隊列
- JS -- 隊列
- JS -- 雙端隊列
- JS -- 循環隊列
- 結構 -- 鏈表
- JS -- 鏈表
- JS -- 雙向鏈表
- JS -- 循環鏈表
- JS -- 有序鏈表
- 結構 -- JS 字典
- 結構 -- 散列表
- 結構 -- js 散列表
- 結構 -- js分離鏈表
- 結構 -- js開放尋址法
- 結構 -- 遞歸
- 結構 -- js遞歸經典問題
- 結構 -- 樹
- 結構 -- js 二搜索樹
- 結構 -- 紅黑樹
- 結構 -- 堆
- 結構 -- js 堆
- 結構 -- js 堆排序
- 結構 -- 排序
- js -- 冒泡排序
- js -- 選擇排序
- js -- 插入排序
- js -- 歸并排序
- js -- 快速排序
- js -- 計數排序
- js -- 桶排序
- js -- 基數排序
- 結構 -- 算法
- 搜索算法
- 二分搜索
- 內插搜索
- 隨機算法
- 簡單
- 第一題 兩數之和
- 第七題 反轉整數
- 第九題 回文數
- 第十三題 羅馬數字轉整數
- 常見一些需求
- 把原始 list 轉換成樹形結構