
你好,我是蔡元楠,現在在 Google 主持研發機器學習在生物醫療領域中的產品應用。在此之前,也在 Google 的搜索廣告部門、智能語音助手等部門參與核心系統的研發。

#### Google 洗手間里貼著的 B+ 樹和哈希表
許多來 Google 參觀的人,用完洗手間后,都會驚奇而略帶羞澀地問:“你們馬桶前面的門上,還貼著 B+ 樹和哈希表的對比… 是用來搞笑的嗎?我感覺數據結構只有在面試的時候會問,工作后從來不需要用數據結構的呀”。
這真不是搞笑,在不同的應用場景合理使用對的數據結構,在 Google 等大廠都是非常認真對待的。而事實上很多技術人,包括我遇到不少 Google 招聘的應屆畢業生,對待數據結構還存在以下兩大誤區。
* 不懂底層原理:看了很多書,算法、架構設計等相關的資料,卻始終沒有搞懂底層數據結構的原理,很多開源軟件拿來就用,簡直是盲人摸象。
* 工作中不會用:很多開發者認為數據結構與算法只有在面試的時候用得到,甚至很多課程也僅僅停留在面試刷題的層面上。從而“面試造火箭、工作擰螺絲”成為了很多技術人的自嘲。
這兩個誤區又是緊密相連的,在實際工作中如果用不好數據結構將會給工作帶來很大的影響,比如:
* 如果不知道數據結構背后的原理,就只能堆砌業務邏輯,從而導致的后果往往是把整個代碼庫搞得異常繁瑣復雜且難以維護;
* 錯誤的使用數據結構,也會影響整個核心的用戶體驗,如延時太高、消耗資源過多等;
* 如果對數據結構沒有進行深入的理解,那么也會限制一個技術人的職業成長和技術影響力,因為他的技術廣度與深度無法勝任更關鍵的角色。
存在以上的問題主要是因為:(1)基礎原理沒有融會貫通,(2)實際工作中沒有使用數據結構的場景,無法深入理解其核心原理,慢慢地數據結構原理知識也就忘了。
#### 不懂數據結構引發的血案
清楚記得剛開始工作時,我臨危受命負責解決我們組的一個重大性能 Bug,當時影響了多個核心用戶的體驗。經過深入地排查后才發現,在一個關鍵 RPC 的代碼邏輯中大量使用了一個自定義樹,這個樹的數據結構實現,正是這個系統的瓶頸。

首先這個樹的實現極為繁瑣,為整個系統的維護增加了復雜度;其次他的一些高頻操作的代碼實現都沒有優化。比如,這個樹的節點插入是用數組的插入實現的,這個樹的遍歷實現使用了 C++ 標準庫的 std::vector 等。這個數據結構的改寫把我們 RPC 的 90 分位延時從 800ms 優化到了 200ms 以下。
此時才意識到我之前學的都是“假”的數據結構,曾經對于數據結構的理解是多么浮于紙面。紙上得來終覺淺,只有和真正的應用場景相結合,才能深刻理解數據結構的原理和性能影響。

#### 專欄設計
上面的兩個故事,正是我們設計這個數據結構專欄的初衷,即想要幫助解決很多技術人的兩個誤區:(1)不懂底層原理,(2)工作中不會用。用原理結合真實大廠案例和開源框架的方式,來加深你對于數據結構的理解和應用能力,學完后可以應用到具體的工作中。
現在的開源項目層出不窮,萬變不離其宗的是底層的數據結構實現。可以說,這是一個做底層框架或者做架構設計的架構師非讀不可的專欄,而做應用或業務層的軟件工程師也應該細細品讀,對于以后的代碼邏輯提升有很好的幫助作用。
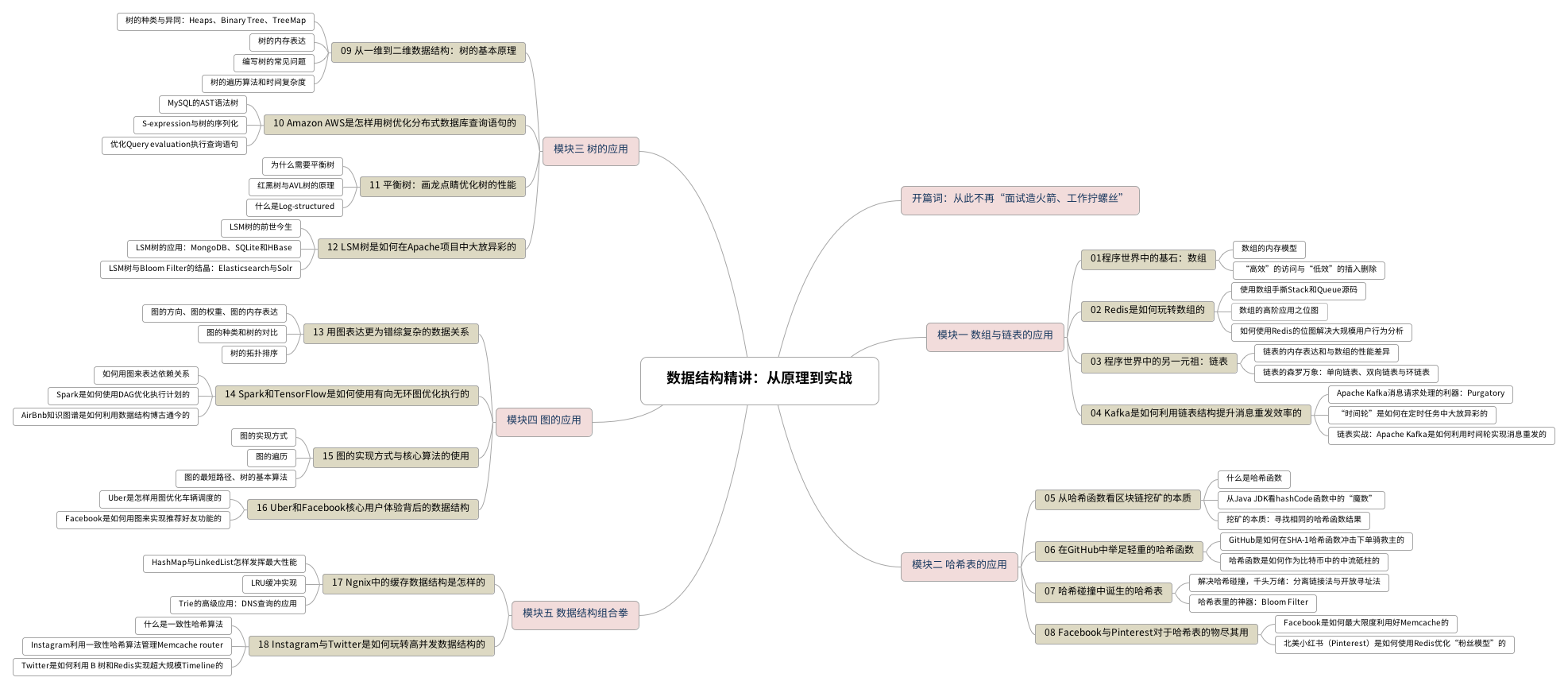
這個專欄共分為 5 大模塊 18 講。
* [ ] 模塊一 數組與鏈表的應用
在模塊一中我們會回顧時間復雜度和空間復雜度、深入數組和鏈表的內存結構,以及如何在 Redis 中使用 Bitmap 來替代常規 SQL 查詢,以作為案例分析探討數組在用戶活躍度分析中的應用;接著也會研究 Kafka 是如何利用鏈表結構來提升消息重發效率的。
* [ ] 模塊二 哈希表的應用
這個模塊將會帶你通過比特幣挖礦的案例,來理解哈希函數和哈希碰撞的本質。緊接著會研究哈希表的各種實現,同時結合之前講解的數組與鏈表,來分析哈希表是如何作為核心數據結構支撐起 Memcached 的,同時帶你領略 Facebook 是如何利用 Memcached 支撐起百億級用戶請求的。
* [ ] 模塊三 樹的應用
在樹的模塊中,會先講解樹的結構化特性,同時比較各種樹,比如堆、二叉樹。接著總結在編寫一個樹的類型時需要注意的常見問題,會以 MySQL 語法樹為例,看看樹是如何在 Amazon AWS 超大型數據庫查詢起到中流砥柱的作用的。在這個模塊的后半部分我們會把重心放在平衡樹上,以及平衡樹是如何成為如 Elastic Search、LevelDB 等眾多存儲系統的基石的。
* [ ] 模塊四 圖的應用
圖也是在大廠應用非常廣泛的數據結構之一。在這一模塊中將會回顧有向圖和無向圖的基本概念、圖的內存表達、比較圖和樹的區別,然后把重心放在應用最廣泛的有向無環圖上。我們以 Apache Spark 和 TensorFlow 為例,來看看有向無環圖是如何優化大規模分布式運算的系統。之后也會以 Uber 的車輛調度算法再加上 Facebook 的 Newsfeed 功能,深入淺出的幫你掌握圖是怎樣實現這些硅谷一線大廠核心功能的。
* [ ] 模塊五 數據結構組合拳
前面的模塊我們主要分析單個數據是如何支撐一個大廠核心應用場景的,或者一個開源框架的核心功能。但是在實戰中會經常需要融合使用多種數據結構去實現業務邏輯。數據結構組合拳這個模塊就是為了幫助你掌握這些應用而設計的。會先詳盡看 Nginx 中的緩存數據結構,如哈希表、鏈表、紅黑樹與 LRU 緩存。相信通過這個案例你能對這些數據結構的理解更進一步;接著會探索 Twitter 的高并發限流機制,涉及到各種并發數據結構,比如并發哈希表、RateLimiter 和消息隊列。在這個模塊結束后,相信以后在面對類似的應用場景時都能信手拈來,打出數據結構組合拳。
#### 講師寄語
數據結構底層原理的速成捷徑:我也曾經讀過枯燥無味的數據結構教材,以及各種味同嚼蠟不得要義的論文,比如數據庫設計論文、分布式系統論文等,當時很痛苦,但硬著頭皮給啃下來了。
為了不讓你再經歷這些,和拉勾教育平臺一起合作,歷時半年精心打磨出了這個專欄,從 5+ 本數據結構教材、20+ 篇技術論文中,提煉出了真正在工程實踐中應用到的關鍵核心原理,同時不乏深度。因為在 Google 億級流量,超大規模技術系統的歷練讓我明白,數據結構的理解不是靠死記硬背的,一定要懂得為什么,不然在工作中很快就會忘掉。這個專欄將會告訴你數據結構為什么這么設計,從而也能根據應用場景來設計合適的數據結構。

真實大廠數據結構實戰案例:將結合 8 個硅谷一線大廠的最佳實踐,以及 15 個頂級開源軟件的應用來解讀數據結構在實戰工程中如何應用,如何通過優化一個核心數據結構來達到優化整個系統的功能。搞清楚這些數據結構原理后,相信你也能擁有造輪子的能力,而不是只能借助其他人的開源框架了。
* 8 個硅谷一線大廠包括 Facebook、Instagram、GitHub、Amazon、Uber、Twitter、Airbnb 和 Pinterest。
* 15 個頂級開源軟件包括 Redis、Kafka、MySQL、SQLite、 MongoDB、Spark、TensorFlow、Nginx、Memcached、LevelDB、RocksDB、HBase、Cassandra、Elastic Search 和 Solr。
馬上就要開始正式內容的學習了,讓我們一起以 Linux 之父 Linus Torvalds 的話共勉吧!Bad programmers worry about the code. Good programmers worry about data structures and their relationships.(低水平的程序員操心代碼,高水平的程序員考慮數據結構和數據結構的聯系。)
- 前言
- 開篇
- 開篇詞:從此不再“面試造火箭、工作擰螺絲”
- 模塊一:數組與鏈表的應用
- 第 01 講:數組內存模型
- 第 02 講:位圖數組在 Redis 中的應用
- 第 03 講:鏈表基礎原理
- 第 04 講:鏈表在 Apache Kafka 中的應用
- 模塊二:哈希表的應用
- 第 05 講:哈希函數的本質及生成方式
- 第 06 講:哈希函數在 GitHub 和比特幣中的應用
- 第 07 講:哈希碰撞的本質及解決方式
- 第 08 講:哈希表在 Facebook 和 Pinterest 中的應用
- 模塊三:樹的應用
- 第 09 講:樹的基本原理
- 第 10 講:樹在 Amazon 中的應用
- 第 11 講:平衡樹的性能優化
- 第 12 講:LSM 樹在 Apache HBase 等存儲系統中的應用
- 模塊四:圖的應用
- 第 13 講:用圖來表達更為復雜的數據關系
- 第 14 講:有向無環圖在 Spark 中的應用
- 第 15 講:圖的實現方式與核心算法
- 第 16 講:圖在 Uber 拼車業務中的應用
- 模塊五:數據結構組合拳
- 第 17 講:緩存數據結構在 Nginx 中的應用
- 第 18講:高并發數據結構在 Instagram 與 Twitter 中的應用