
你好,我是你的數據結構課老師蔡元楠,歡迎進入第 18 課時的“高并發數據結構在 Instagram 與 Twitter 中的應用”學習。
在如今的計算機系統設計中,有很多的應用已經不再局限于在單機環境下運行了,這些應用會將本身或者底層的存儲本身部署在分布式環境中,像是數據庫的分片(Sharding),或者是將數據部署到分布式環境下的多臺機器集群中,從而達到負載均衡。那我們今天就一起來看看,數據結構在分布式環境應用中扮演著怎么樣的一個角色。
我們在第 05 課時中,學習了哈希函數的本質,現在一起回顧一下。哈希函數的定義是將任意長度的一個對象映射到一個固定長度的值上,而這個值稱作哈希值。
哈希函數一般有以下三個特性:
* 任何對象作為哈希函數的輸入都可以得到一個相應的哈希值;
* 兩個相同的對象作為哈希函數的輸入,它們總會得到一樣的哈希值;
* 兩個不同的對象作為哈希函數的輸入,它們不一定會得到不同的哈希值。
哈希函數其實是在解決分布式環境部署的一個重要算法,我們就以把數據部署到分布式環境機器集群為例,來說明一下它的重要性。
#### 服務器部署例子
假設現在維護著一個應用,這個應用在同一個時間段會有大量用戶讀取數據這樣的一個場景。為了緩解服務器的壓力,我們決定將數據分別存儲在 3 臺不同的機器中,這樣就可以達到負載均衡的效果。
那要怎么樣將數據均勻地分發到不同機器中呢?最簡單的一種哈希函數設計就是將所有的數據都事先給予一個數字編號,然后采用一個簡單的取模運算后將它們分發出去。取模運算這樣的哈希函數是指根據機器節點的數量,將數據的編號對機器節點的數量做除法,得到的余數就是這個數據最終保存機器的位置。
下面我們來詳細說明。現在客戶需要檢索以下三個數據,它們的數據編號分別為 7737、8989 和 8338。因為前面已經決定了需要 3 臺機器來存儲這些數據,所以哈希函數所要做的運算就是用數據編號除以 3,得到的余數就是存儲數據的機器編號,也就是數據編號 %3 運算,結果如下表所示:
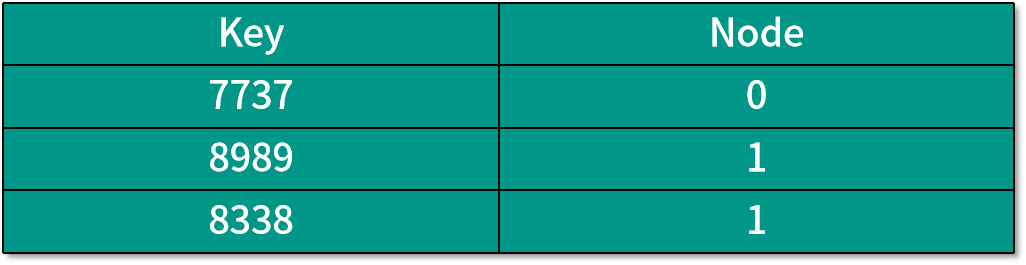
這種方法非常的直觀和簡單,但是卻有一個致命的缺點,那就是當我們改變機器數量的時候,有很多數據的哈希運算結果將會改變。這種情況發生在,當我們的服務器壓力過大想要擴充服務器數量的時候;又或者是服務器數量已經很充足,公司想要節省開支而減少服務器數量的時候。
我們來舉個簡單的例子看看當發生這種情況時后臺的數據會有什么樣的變化。
當服務器數量還是 3 的時候,編號在前 10 的數據,經過哈希運算后保存數據的機器如下表所示:
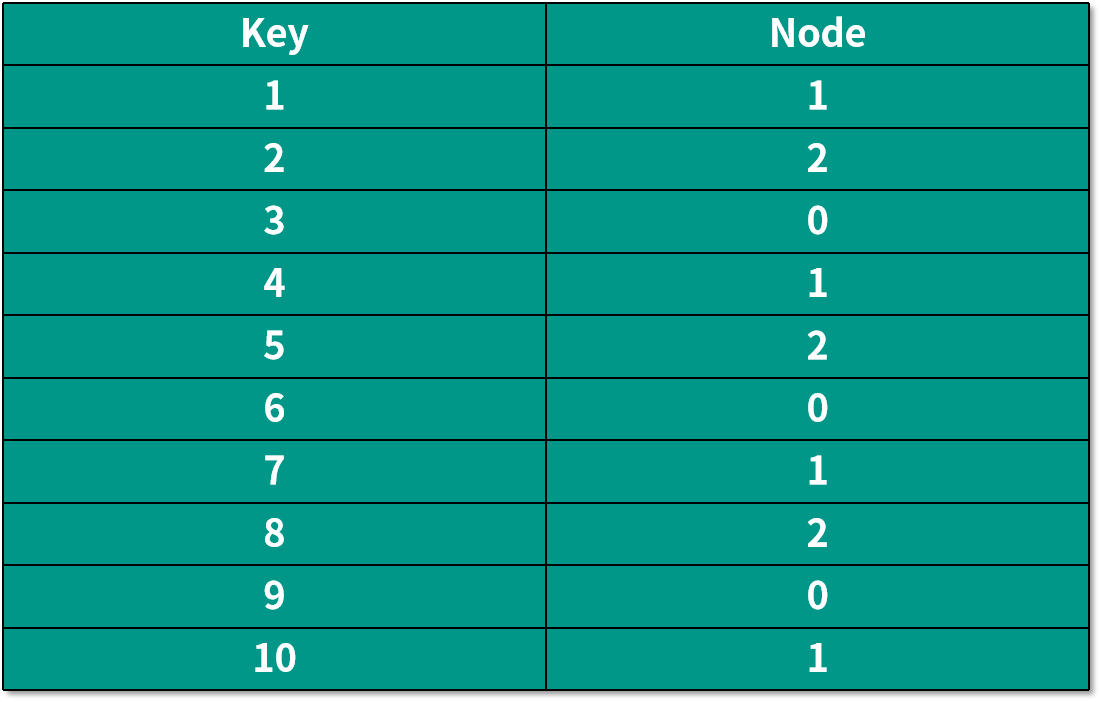
如果我們需要增加一個服務器,也就是機器數量變成 4 的時候,編號在前 10 的數據,經過哈希運算后保存數據的機器如下表所示:
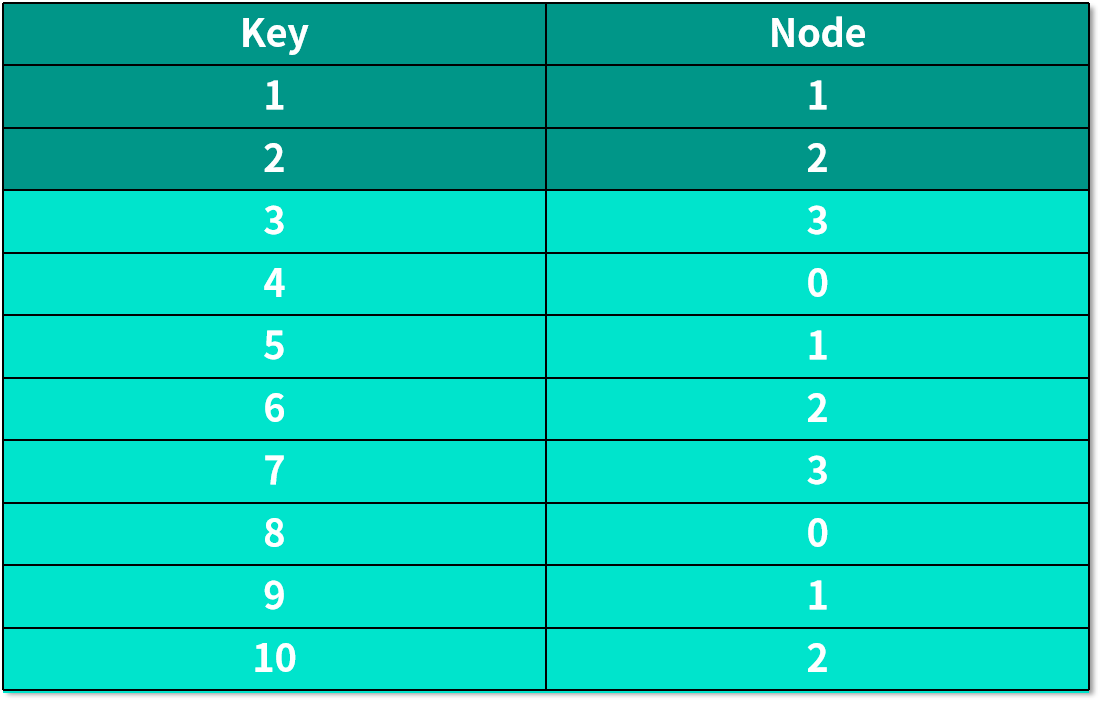
背景被標藍的行,表示保存這個數據的機器發生了變化。這也就意味著:應用的后臺需要重新將數據分配一遍,而如果有用戶在重新分配數據的這段時間剛好想要訪問這些數據,比如說,用戶想訪問 key 為 3 的數據,到了 3 號服務器,因為數據還未被重新分配,實際保存這個數據的服務器是 0 號服務器,就會造成想要訪問的數據不存在,這時候用戶只能將所有服務器遍歷一遍,看看哪一個服務器保存了這個數據。
這樣的缺點在數據量十分龐大又或者服務器非常多的時候,對應用是十分不利的。為了克服這個缺點,我們需要用到另外一種算法,那就是“一致性哈希算法”。
#### 一致性哈希算法的定義
一致性哈希算法(Consistent Hashing)是 David Karger 在 MIT 于 1997 年提出的一個概念,該算法可以使哈希算法的計算獨立于機器的數量。那么下面我們就來看看一致性哈希算法是如何運作的。
一致性哈希算法會將計算出來的哈希值映射到一個環中,為了方便說明,因為一個圓環是 360 度,所以這里采用取模 360 的計算方式將哈希值映射到環中,也就是說在計算出每個數據或者服務器的哈希值 H 后,我們采取 H % 360的計算方式來得到這個數據或者服務器在圓環中的位置。當然在實際應用中,你也可以采用其他的計算方式將哈希值映射在環上。

一致性哈希算法通常涉及了以下 3 個步驟:
* 計算出分布式環境下機器對應的哈希值,然后根據哈希值將其映射到圓環上,對于計算分布式環境下機器的哈希值,我們一般根據機器的 IP 地址來進行計算;
* 計算出數據的哈希值,然后根據哈希值將其映射到圓環上;
* 把映射到圓環上的數據存放到在順時針方向上最接近它的機器中,如果機器映射在圓環上的值和數據映射在圓環上的值相同,則將數據直接存儲在該機器中。
#### 一致性哈希算法是怎么工作的
好了,那現在我們用實際的例子來看看一致性哈希算法是如何工作的。
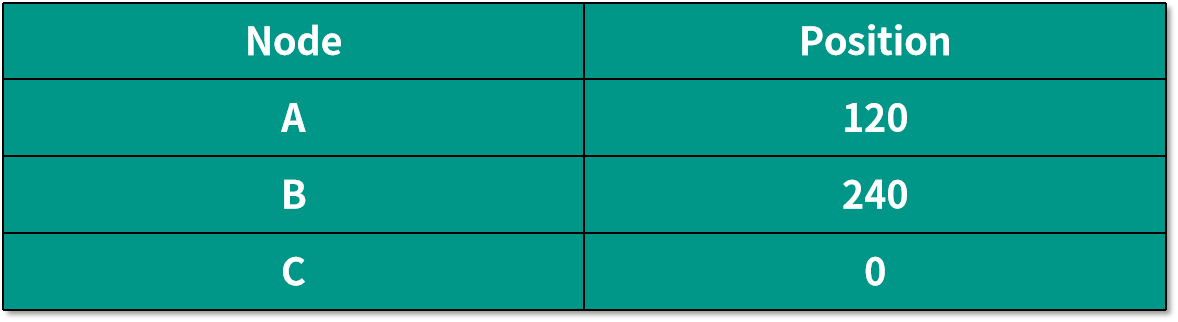
我們還是按照一開始將數據部署到 3 臺機器的情況來講解。假設三個機器映射到環中的位置如下表所示:
數據映射到環中的位置如下表所示:
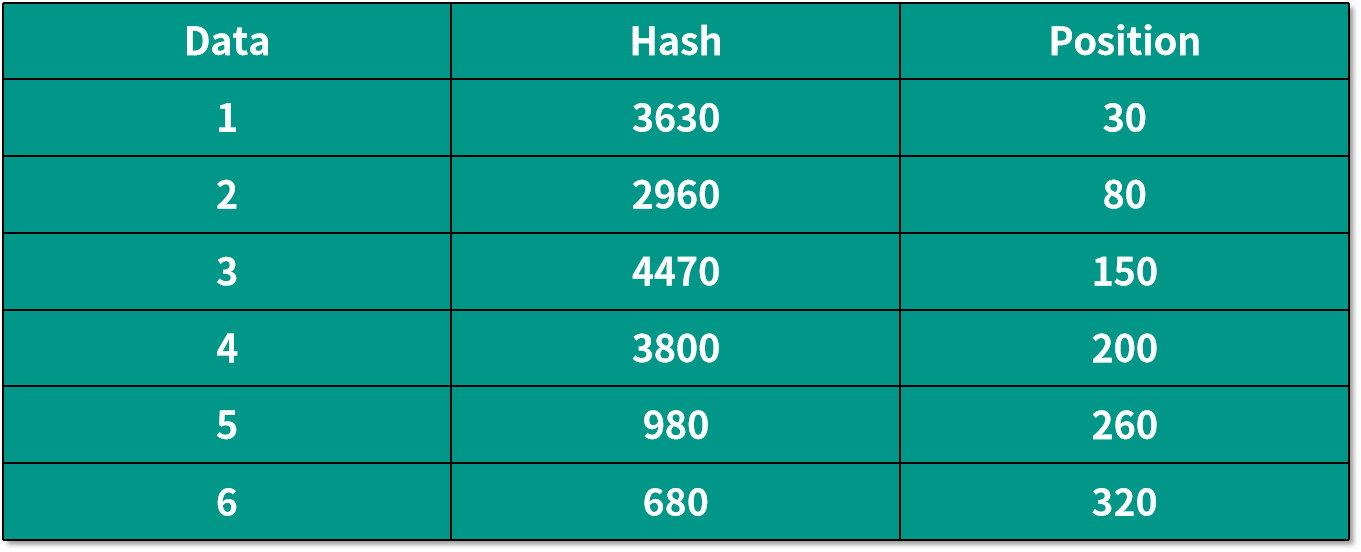
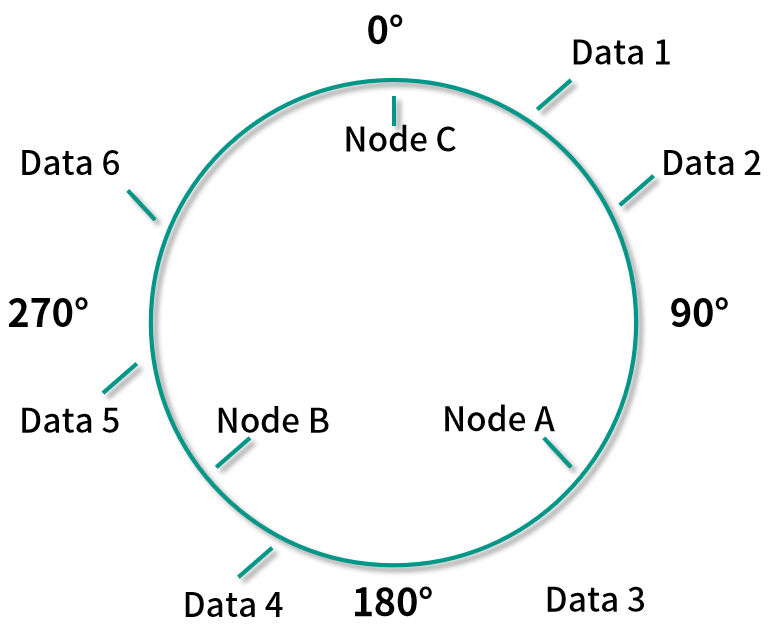
根據上面的算法,將所有映射好的數據按順時針保存到相應的機器節點中,就是說將 Data 1 和 Data 2 放到 Node A 中,Data 3 和 Data 4 放到 Node B 中,Data 5 和 Data 6 放到 Node C 中。
如果這個時候我們需要添加一個新的機器 Node D,映射到環上后的位置如下所示:
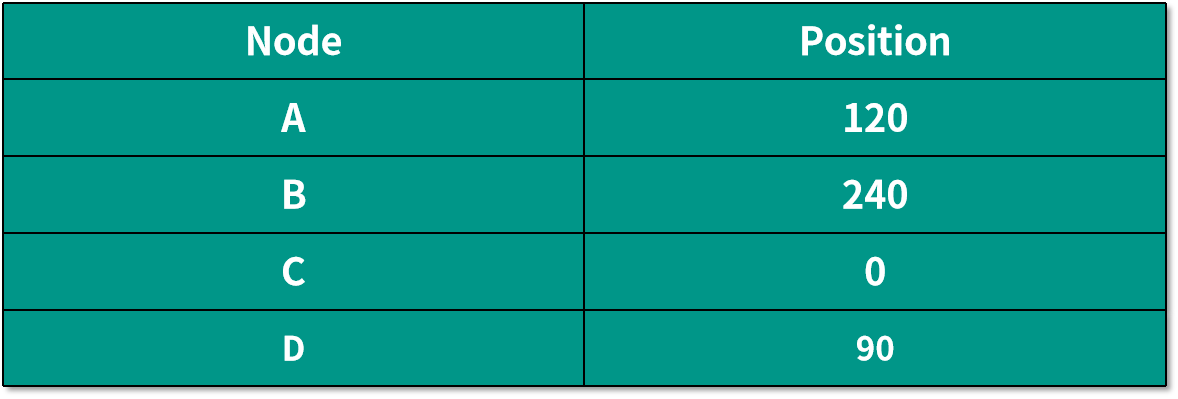

根據算法,這時候只有 Data 1 和 Data 2 需要重新分配到 Node D 中,而不是像之前普通的哈希算法,需要將幾乎所有的數據都重新分配一遍。
一致性哈希算法,可以將增加或者刪除一個機器導致數據重新分配的平均時間復雜度從 O(K) 降到 O(K / N + log(N)),這里的 K 代表數據的個數,N 代表機器的個數。當然了,一致性哈希算法還涉及到很多其他問題,比如數據是否平均分配到了不同的機器中,想深入了解的話建議看看 Karger 的這篇論文。
我們在第 08 講中,曾經講過 Facebook 自己做了一個名叫 Mcrouter 的服務器出來,可以將不同的數據請求導向不同的 Memcache 機器上。同樣的,Facebook 旗下的 Instagram 應用,有著大量的照片和視頻需要保存在緩存中,從而加速數據讀取速度,而管理這些 Mcrouter 服務器背后的算法正是一致性哈希算法。
#### Twitter 如何利用 B 樹和 Redis 實現超大規模 Timeline
在最后我還想和你介紹另外一個在北美熱門的應用軟件 Twitter 所使用到的數據結構。Twitter 作為一個社交平臺,同時擁有著高活躍度的用戶,用戶讀取數據的低延時性是必不可少的,所以緩存成為了平臺中的重要一環。
在 Twitter 里面的一個相當重要的功能就是 Timeline 時間線功能。Timeline 功能會將社交網絡中的各種內容展示給用戶,用戶通過不停下拉來獲取最新的內容,這也是一個典型的讀操作遠遠大于寫操作的應用場景。實際上,Timeline 里面保存的并不是 Twitter 推文的實際內容,而且對應推文的一個 ID,這些 ID 對應的實際內容被保存在了 Redis 緩存中。
通過之前的學習,我們知道 Redis 本質就是一個哈希表,哈希表是無法對數據進行排序的,那有什么辦法可以解決這個問題呢?如果你還記得第 12 講里面 LSM Tree 的本質,就明白了這個問題是通過 B-Tree 來解決的。沒錯,Twitter 也是通過在 Redis 中維護 B-Tree 來達到對一個用戶 Timeline 中推文時間的排序。
- 前言
- 開篇
- 開篇詞:從此不再“面試造火箭、工作擰螺絲”
- 模塊一:數組與鏈表的應用
- 第 01 講:數組內存模型
- 第 02 講:位圖數組在 Redis 中的應用
- 第 03 講:鏈表基礎原理
- 第 04 講:鏈表在 Apache Kafka 中的應用
- 模塊二:哈希表的應用
- 第 05 講:哈希函數的本質及生成方式
- 第 06 講:哈希函數在 GitHub 和比特幣中的應用
- 第 07 講:哈希碰撞的本質及解決方式
- 第 08 講:哈希表在 Facebook 和 Pinterest 中的應用
- 模塊三:樹的應用
- 第 09 講:樹的基本原理
- 第 10 講:樹在 Amazon 中的應用
- 第 11 講:平衡樹的性能優化
- 第 12 講:LSM 樹在 Apache HBase 等存儲系統中的應用
- 模塊四:圖的應用
- 第 13 講:用圖來表達更為復雜的數據關系
- 第 14 講:有向無環圖在 Spark 中的應用
- 第 15 講:圖的實現方式與核心算法
- 第 16 講:圖在 Uber 拼車業務中的應用
- 模塊五:數據結構組合拳
- 第 17 講:緩存數據結構在 Nginx 中的應用
- 第 18講:高并發數據結構在 Instagram 與 Twitter 中的應用