
學習完了圖的各種技術,你肯定想摩拳擦掌了,今天這一課時我們就來看一下在 Uber 這樣的北美一線大廠是怎樣利用圖來增強核心業務能力的。
Uber Pool 是 Uber 類似于滴滴拼車的共享乘車產品。拼車產品能夠自動把路線重疊的乘客配對起來,這樣對于所有乘客都能用更便宜的價格來享受乘車服務,路線重疊的越多,共享拼車就能提供越多的折扣。怎樣去設計一個好的拼車路線呢?Uber 設計了這樣的指標,必須是便宜、快捷、方便和友好的。
從工程實現角度考慮,作為工程師我們怎樣才能去測量一個拼車路線是否既快捷又高效呢?怎樣才能準確預測 2 個、3 個,或者 4 個乘客拼在一起會共同享受這個行程?這些都是對于 Uber 拼車匹配系統的工程挑戰。事實上 Uber 的拼車系統從最初上線到初步成型經過了 1 年半的迭代,更新了好幾個版本。這些技術方案都很好地利用了圖,可以說是技術人必讀的工程案例。
#### 項目動機
Uber 最初發布拼車服務是在 2014 年,但其實在很早 Uber 就已經對拼車這樣的服務覬覦已久。只不過一直沒有輔助實行,是因為 Uber 想等到普通的打車服務的服務量達到一定規模,這樣的話,從商業角度考慮才是進行更冒險創新的時機。另外從工程角度考慮,原本的業務可以積累大量數據,為拼車這樣的服務提供數據支撐。這是很值得我們技術人學習的思路。
不要一上來就 Over Engineering 過度技術復雜度。明明 10 個用戶都沒有呢,就要考慮怎樣應對 1 億的流量,然后技術方案半年都做不出來。正確的方式還是要跟著商業階段來走,找到可以應對當前業務規模最簡單的工程方案,同時也要往后看 3 年,但千萬不要看得太多,否則很容易因為工程技術資源不夠,反而影響了業務迭代速度。
話又回到 2014 年。在正式上馬拼車業務之前,Uber 先進行了技術模擬,類似于股票交易的回溯測試,先利用已經積累的歷史打車業務數據,來模擬演算拼車業務的可行性。結果是令人興奮的,他們發現在舊金山,有超過 80% 的行程是和別的行程有很大重疊的。這是一個令人震驚的數字,因為要知道 Uber 當時在路上的車輛僅僅是舊金山路上車輛很小的一部分,即使如此,已經能有相當多的行程可以被匹配了。所以他們清楚地看到了這里面的商業潛力及社會價值。這樣既可以讓司機開同樣的車賺更多的錢,又可以減少路上的車輛保護環境。
#### 技術方案選擇
在最開始的拼車方案設計中,根據乘客輸入的起始點,會收到一個固定的報價,然后 Uber 拼車服務會讓乘客等待 1 分鐘,來匹配其他的乘客和司機,如果 1 分鐘后沒有找到匹配合適的同行乘客,Uber 仍然會按照報價的金額派出單獨的司機來進行接送。在嘗試了這個固定 1 分鐘的方案之后,Uber 發現這個方案還是有很多問題。
他們又嘗試了動態窗口式的匹配系統,也就是說不是所有的乘客都等待固定的 1 分鐘,而是把乘客放在一個動態的匹配窗口,比如 10 分鐘的匹配窗口,那么 8:03 和 8:09 開始叫車的乘客都會待在 8:00 ~ 8:10這樣的一個窗口里等待匹配。很顯然,匹配窗口越大,系統能找到匹配的幾率就越高,但窗口也不是固定大小的,比如對于人口密度比較低的美國中部城市,窗口可以設到 15 分鐘;但對于人口集中的大城市,或者是上下班高峰時,窗口只需要 30 秒就能找到匹配同行的乘客了。因此,窗口時間短,用戶體驗也會更好,因為用戶就不需要等待很長時間了,但是這樣的方案還是有一些缺點。
在同一個時間窗口里找到足夠的司機變得很難。因為 Uber 的系統必須要在 10 分鐘窗口結束時找到拼車司機,不然就要為每一個乘客單獨派送專車司機且按照拼車的價格承諾,也就是對系統造成了成本壓力。10 分鐘的窗口對用戶來講也有點長了,最終上線的 Uber 拼車服務等待時間為 1 分鐘。
#### 簡單的匹配算法
Uber 在 2014 年的時候業務發展非常快,當時強調的工程文化是敏捷迭代。正如我之前所說他們追求先快速上線最簡單的匹配系統,這其實是一個基于貪心算法思想的匹配系統。
貪心算法的基本理念就是找到局部最優,而暫不考慮全局最優。在拼車匹配系統里,一個貪心的匹配就是先快速找到第一個符合條件的拼車配對組合,而不考慮是否是這個時間窗口里最好的匹配。在產品上線的最初階段,事實上貪心算法是非常合適的,因為用戶規模不大,往往一個時間窗口內可供選擇的乘客也不多。如果非要追求全局最優則需要花費大量的時間,并且這個最初上線的系統利用起始點的直線距離以及平局車速來快速估算預計時間。
這個最初的系統會便利所有的兩兩乘客,也就是 O(n^2) 的時間復雜度,這里面的 n 是多少呢?
讓我們來把乘客的起始點標注比如乘客 A 的起始點分別為 A 和 A’,B 的起始點就是 B 和 B’。若要匹配 A 和 B 兩個乘客的話,則有 24 種可能的匹配!比如 ABB’A’、ABA’B’、B’A’BA、B’AA’B、B’ABA’、BAA’B’、AA’B’B、B’BAA’ 等。如果你學過排列組合的話,就知道這個是 4*3*2*1 種可能性,但實際上合理的組合只有 4 種,因為 A’ 終點不可能出現在 A 起點之前,同時,AA’BB’ 這樣的組合也不存在,因為這樣路線就沒有重疊了。
所以對于一個有 n 個乘客的系統來說,我們需要遍歷 4*n^2 種可能,然后再來尋找最優的組合。這樣的暴力搜索法用偽代碼來實現是這樣子的:
```
def?make_matches(all_rides):
????for?r1?in?all_rides:
????????for?r2?in?all_rides:?
????????????orderings?=?[]
????????????for?ordering?in?get_permutations(r1,?r2):
????????????????if?is_good_match(r1,?r2,?ordering):
????????????????????orderings.append(ordering)
????????????best_ordering?=?get_best_ordering(r1,?r2,?orderings)
????????????if?best_ordering:
????????????????make_match(r1,?r2,?best_ordering)
????????????//?etc?...
```
在搜索過程中也要考慮一些篩選條件,比如繞路和接客時間。一個合理的拼車組合,必須要保證對于每一個乘客來說,拼車之后的繞路要在一個可接受的范圍以內。比如說我本來只是一個 10 分鐘的行程,如果因為拼車繞了 20 小時的路肯定是非常糟糕的用戶體驗;相反如果我本來就是 2 個小時的路程,繞路 20 分鐘可能還可以接受,還好繞路其實是很容易計算的。我們可以先計算乘客直接到達目的地的時間,再計算拼車之后到達目的地的時間,這兩個時間差值就是繞路時間。
對于一個 A → B → A’ → B’ 的組合,A 的繞路是 A 到 B 再到 A’ 的行程,減去 A 到 A’ 的行程,相似的也要計算乘客額外的等待接駕時間。還是對于 A→ B→ A’→ B’ 這樣一個行程來說,A 的等待時間是司機→ A 的時間,B 的等待時間是司機→ A → B 的時間。一般來說第二個乘客的接駕時間更長,但是繞路時間更短。
在這個簡單匹配算法后,Uber 開始改進匹配系統。Uber 收到了很多用戶的反饋,因為使用了拼車,必須先要坐到很遠的地方再掉頭回來,覺得這個系統很不智能。Uber 意識到乘客不愿意走回頭路,也就是說整個行程的方向要和本來的方向符合。這也促使了 Uber 改進了第二代和第三代拼車匹配系統。
#### 第三代拼車匹配系統
等迭代到第三代拼車匹配系統時,Uber 的工程師已經認識到了再不使用圖這個武器,已經無法完成業務需要了,這也正是告訴我們學好數據結構的重要性。沒有數據結構的深厚功力,很容易無法承擔業務的重大挑戰。
Uber 發現不能再繼續使用貪心算法了,而是使用權重圖的重要算法:最大匹配算法。這個算法同時要能夠預測短期內的拼車需求,作出一個全局最優的匹配決定。
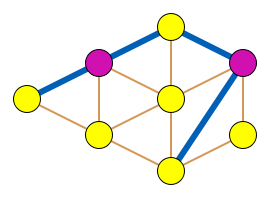
如圖中所示,如果我們用圖來建模拼車系統的話,則可以把乘客的起點和終點都看作是圖中的節點,這個圖中邊的權重可以被認為是開車的時間。一個最優的拼車訂單,是找到一個連接至少 2 個乘客的起點和終點的幾條邊,并且這幾條邊的組合權重之和相比乘客的數量是圖中最小的。這是一個經典的 NP 難題,只能用 n 的多項式時間來完成。
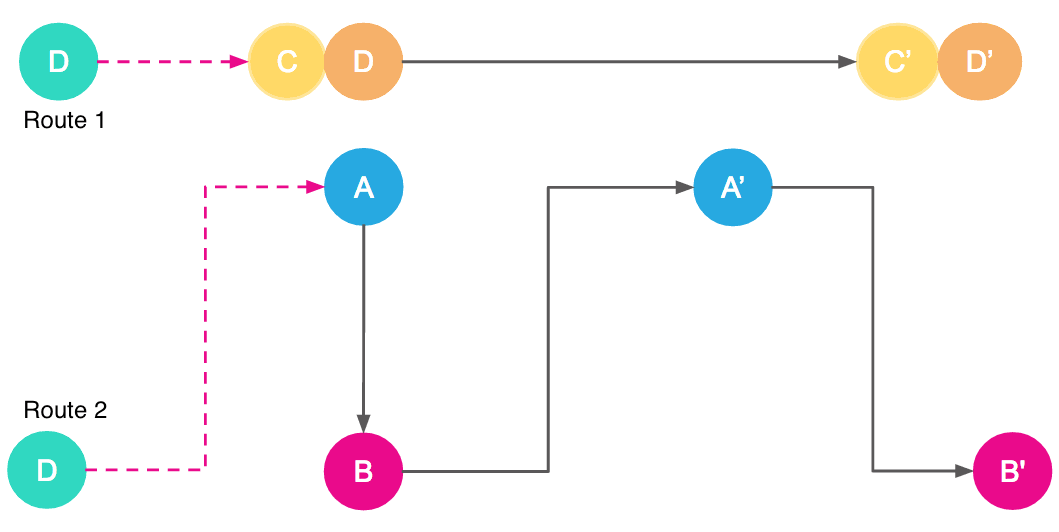
Uber 的工程師在原先的貪心算法上加了一個改進的方案,稱為路線切換。
其實路線切換很簡單,可以說是一個討巧的辦法。它是利用上面的貪心算法找到局部最優,然后再利用司機去接駕的時間繼續為乘客匹配拼車路線,一旦找到更優的匹配就把司機切換了。利用這樣的時間差,Uber 把搜索最優匹配的時間從幾十秒變成了幾分鐘。下圖就是一個路線切換的示意圖。
除了路線切換之外,在第三代拼車匹配系統中,Uber 工程師們還改進了稱為滾雪球式匹配算法。它的意思是一旦通過前面的貪心算法,和路線切換確定了一條拼車路線以后,系統會利用這條路線去不斷嘗試接受新的拼車乘客,也就是說有可能在行程中不斷有新的乘客被加入到這個拼車線路中。
通過這些改進,Uber 工程師很好的去逼近 NP 難題的全局最優,并且這個全局最優在現實中很難解決,因為無法預測未來的乘車需求。Uber 的方案很好地利用了時間差,非常有效率的在拼車線路的不同階段去嘗試找到局部最優匹配。
#### 總結
這一課時我們分析了 Uber 的拼車系統案例,它屬于圖的最大匹配問題,可以看到 Uber 是怎樣一步一步迭代技術方案,并最終逼近最優解的過程,同時對于我們技術團隊的方案設計也很有啟發。在早期業務比較小時千萬不要過度優化,而是要用最簡單的方案快速驗證,收集更多用戶和數據來不斷改進系統。
- 前言
- 開篇
- 開篇詞:從此不再“面試造火箭、工作擰螺絲”
- 模塊一:數組與鏈表的應用
- 第 01 講:數組內存模型
- 第 02 講:位圖數組在 Redis 中的應用
- 第 03 講:鏈表基礎原理
- 第 04 講:鏈表在 Apache Kafka 中的應用
- 模塊二:哈希表的應用
- 第 05 講:哈希函數的本質及生成方式
- 第 06 講:哈希函數在 GitHub 和比特幣中的應用
- 第 07 講:哈希碰撞的本質及解決方式
- 第 08 講:哈希表在 Facebook 和 Pinterest 中的應用
- 模塊三:樹的應用
- 第 09 講:樹的基本原理
- 第 10 講:樹在 Amazon 中的應用
- 第 11 講:平衡樹的性能優化
- 第 12 講:LSM 樹在 Apache HBase 等存儲系統中的應用
- 模塊四:圖的應用
- 第 13 講:用圖來表達更為復雜的數據關系
- 第 14 講:有向無環圖在 Spark 中的應用
- 第 15 講:圖的實現方式與核心算法
- 第 16 講:圖在 Uber 拼車業務中的應用
- 模塊五:數據結構組合拳
- 第 17 講:緩存數據結構在 Nginx 中的應用
- 第 18講:高并發數據結構在 Instagram 與 Twitter 中的應用