
這一講是哈希表模塊的最后一講,相信經過前三講的學習之后,你已經對哈希函數、哈希碰撞以及哈希表這個數據結構有了深刻的了解。那今天我想和你分享一下哈希表這種數據結構是如何在硅谷的大廠中被應用到的。
#### 均攤時間復雜度
我們知道,哈希表是一個可以根據鍵來直接訪問在內存中存儲位置的值的數據結構。雖然哈希表無法對存儲在自身的數據進行排序,但是它的插入和刪除操作的均攤時間復雜度都屬于均攤 ?O(1) (Amortized O(1))。均攤時間復雜度可以這樣來理解:如果說一個數據結構的均攤時間復雜度是 X,那么這個數據結構的時間復雜度在大部分情況下都可以達到 X,只有當在極少數的情況下出現時間復雜度不是 X。
為什么在分析哈希表的時候我們會用到均攤時間復雜度呢?這主要是因為在處理哈希碰撞的時候,需要花費額外的時間去尋找下一個可用空間,這樣造成的時間復雜度并不是 O(1)。極端情況下,所有插入的數據如果都產生了哈希碰撞,而我們采用的是分離鏈接法來解決哈希碰撞,那時間復雜度就變成了 O(N)。當然了,在現實中,其實哈希算法都已經設計得非常好了,造成哈希碰撞的情況是少數的,大部分時間,它的時間復雜度還是 O(1)。
所以若在面試中有面試官問你哈希表的時間復雜度,就可以好好的分析一下均攤時間復雜度了。
因為這種特性,使得哈希表的應用十分廣泛,很常見的一種應用就是緩存(Cache),緩存這個概念其實不單單只是針對于內存來說的,可以抽象地把緩存看作是一種讀取速度更快的媒介。比如說,對于同樣的數據,因為讀取內存上的數據會比硬盤上的數據更快一些,所以我們可以把內存看作是硬盤的緩存;當我們想要的數據結果需要通過數據庫查詢操作來完成的時候,把可以查詢的結果存放在一臺機器上,這樣當下一次讀取時就可以直接從這臺機器上讀取而不是通過耗時的數據庫操作,此時就可以把這臺機器看作是數據庫的緩存了。
Memcached 和 Redis 這兩個框架是現在應用得最廣泛的兩種緩存系統,它們的底層數據結構本質都是哈希表。那么下面我們就來一起看看它們是如何被應用在 Facebook 和 Pinterest 中的,進而了解哈希表這種數據結構的實戰應用。
* [ ] Memcached 緩存
Memcache 是一種分布式的鍵值對存儲系統,它的值可以存儲多種文件格式,比如圖片、視頻等。Memcache 的一個很大特點就是數據完全保存在內存中,也就是說如果一臺運行著 Memcache 的機器突然掛掉了,那保存在上面的數據就會全部丟失,所以我們可以把保存在 Memcache 中的數據看作是 Memcache 維護了一個超級大的哈希表數據結構,并沒有任何內容保存在硬盤中。
同樣的,因為每臺機器的內存容量是有限的,如果存儲的數據占滿了一臺機器的內存之后,再有新的數據想保存進 Memcache 的話,就必須把舊的數據刪除掉。
* [ ] 哈希表在 Facebook 中的應用
Facebook 會把每個用戶發布過的文字和視頻、去過的地方、點過的贊、喜歡的東西等內容都保存下來,想要在一臺機器上存儲如此海量數據是完全不可能的,所以 Facebook 的做法是會維護為成千上萬臺機器運行 Memcache,不同的數據會保存在不同的 Memcache 中,這里我們可以看作是不同的數據都有不同的哈希表來維護它們。
對此,Facebook 自己做了一個名叫 mcrouter 的服務器集群出來,可以將不同的數據請求導向不同的 Memcache,而他們還開源了這個管理 mcrouter 的代碼(開源代碼)。
社交軟件有一個很大的特點就是讀操作會遠遠高于寫操作,也就是說當用戶打開 Facebook 之后,基本是在不斷地刷新好友發布的內容,而 Facebook 在全球擁有著超過 24 億的用戶,如果每個用戶的刷新都需要到數據庫進行查詢操作的話,那數據庫肯定扛不住這么大的流量。
但是很多數據不從數據庫讀取的話是拿不到最新數據的,怎么辦呢?解決的方案是在第一次讀取數據之后,將這些通過數據庫算出的結果存放在 Memcache 中并設定一個過期時間。只要數據沒有超過設置的過期時間,后續的所有讀取都不需要通過數據庫計算,而是直接從 Memcache 中讀取。下面就以幾個 Facebook 的實際應用來說明一下。
* [ ] 好友生日提醒
最簡單的應用就是 Facebook 里的好友生日提醒了,其做法是將用戶 ID 和用戶的生日日期作為鍵值對存放在 Memcache 中。每個用戶在當天登錄的時候,會先以所有的好友 ID 作為鍵,去 Memcache 中尋找是否有他們的數據存在,如果存在則判斷當天的日期是否是好友生日的日期,然后決定是否發送生日提醒;如果不存在,則先去數據庫中拿出所有好友的生日日期,然后存在 Memcache 中,最后返回給用戶判斷。
當然了,Facebook 的設定是允許用戶修改生日日期的,這樣就無法將用戶的生日直接存放在 Memcache 之后就一勞永逸了,如果用戶修改了自己的生日在更新數據庫的同時也需要發送請求刪除 Memcache 中的數據。
就是這樣簡單的一個功能,其實每天都會對 Memcache 這個哈希表產生數十億次操作。
* [ ] 通過訪問直播鏈接來看回放
而另外一個大量利用了哈希表這個數據結構的 Facebook 應用是 Facebook Live。Facebook Live 是一個直播應用,它的一個特點是即使用戶錯過了直播時間,后面也可以通過訪問直播鏈接來觀看回放。在這里,Facebook 把每一個直播的視頻流數據按照每一秒鐘的時間分割成一個塊(Segment),每一個視頻流塊都會被存放在 Memcache 中。當用戶讀取直播視頻流的時候,會以直播 ID 加上這個時間進度作為哈希表的鍵,來讀取每一秒的直播視頻。
2016 年 Facebook 技術講座的整體架構如下圖所示:
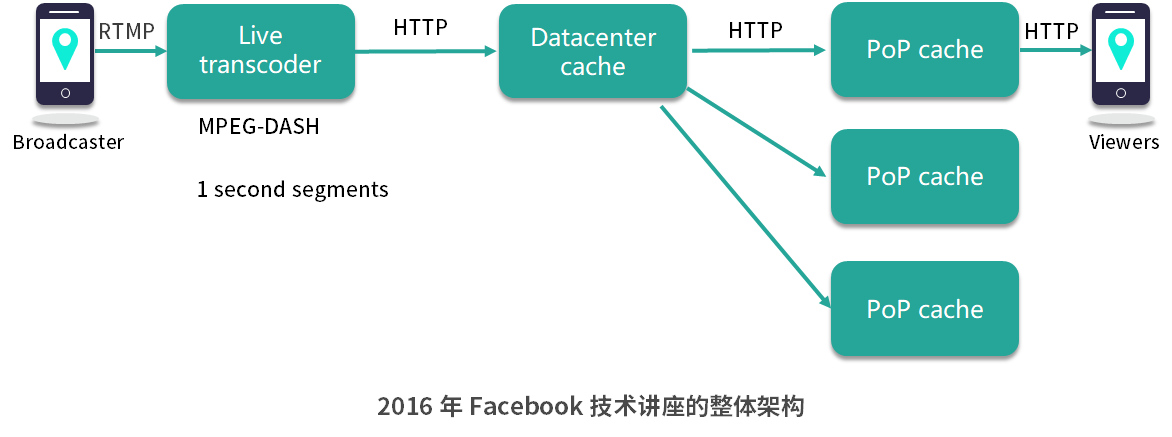
從上圖中可以看到,直播視頻其實在經過處理之后首先會被存入數據庫,然后在往上一層再做了一個 Memcache 內容緩存。
* [ ] Redis 緩存
說到以哈希表作為底層數據結構的系統,除了 Memcache 之外,另外一個著名系統就是 Redis 了。Redis 與 Memcache 一樣,同樣是一個保存鍵值對的存儲系統。它與 Memcache 的一個很大不同是,保存在 Redis 上的數據會每間隔一段時間寫入到磁盤中,以防止當機器宕機后可以重新恢復數據。
Redis 所支持的數據類型也十分簡單,包括 Strings、Lists、Sets、Sorted Sets、Hashes 和之前介紹的 Bitmaps 等。下面將介紹 Redis 是如何被利用在“美版小紅書” Pinterest 中的。
* [ ] 哈希表在 Pinterest 中的應用
在 Pinterest 的應用里,每個用戶都可以發布一個叫 Pin 的東西,Pin 可以是自己原創的一些想法,也可以是物品,還可以是圖片視頻等,不同的 Pin 可以被歸類到一個 Board 里面。比如說在一個體育 Board 里面,可以有用戶發布的球鞋的 Pin,體育視頻的 Pin,或者對某個體育明星采訪的 Pin。
我們可以通過關注 Board 和 Pin 來獲取推薦系統給用戶發布的內容。比方說,如果一個用戶關注了 Board A,那每當 Board A 有新的 Pin 加進去的時候都會推送給這個用戶。用戶 A 也可以通過關注用戶 B,那以后用戶 B 所發布的每一個 Pin 和 Board 都會推送給用戶 A。
Pinterest 在全球擁有著超過 3 億的活躍用戶,上面也提到過,社交軟件的讀操作會遠遠高于寫操作,推薦系統的算法在很大程度上是通過讀取每個用戶的關系圖來進行推薦的。如果每次用戶的內容推薦都需要到數據庫中去讀取他所關注的用戶,同時再讀取關注的用戶發布過的 Board 和 Pin,這樣的話讀取速度會非常慢。所以 Pinterest 將很多這些關系圖都保存在了 Redis 里面,從而不必從數據庫中讀取內容。
從 Pinterest 公布的工程論文中可以知道,他們會將一個用戶所關注的其他用戶保存在 Sorted Sets 里。一個 Set 是一個集合,本質上也可以看作是一個哈希表,而我們所關心的只是這個哈希表中的鍵,而不是它的值。比如說我們所關心的是這個 Set 里某一個鍵是否已經被插入了,如果是,則表示這個鍵存在 Set 里。
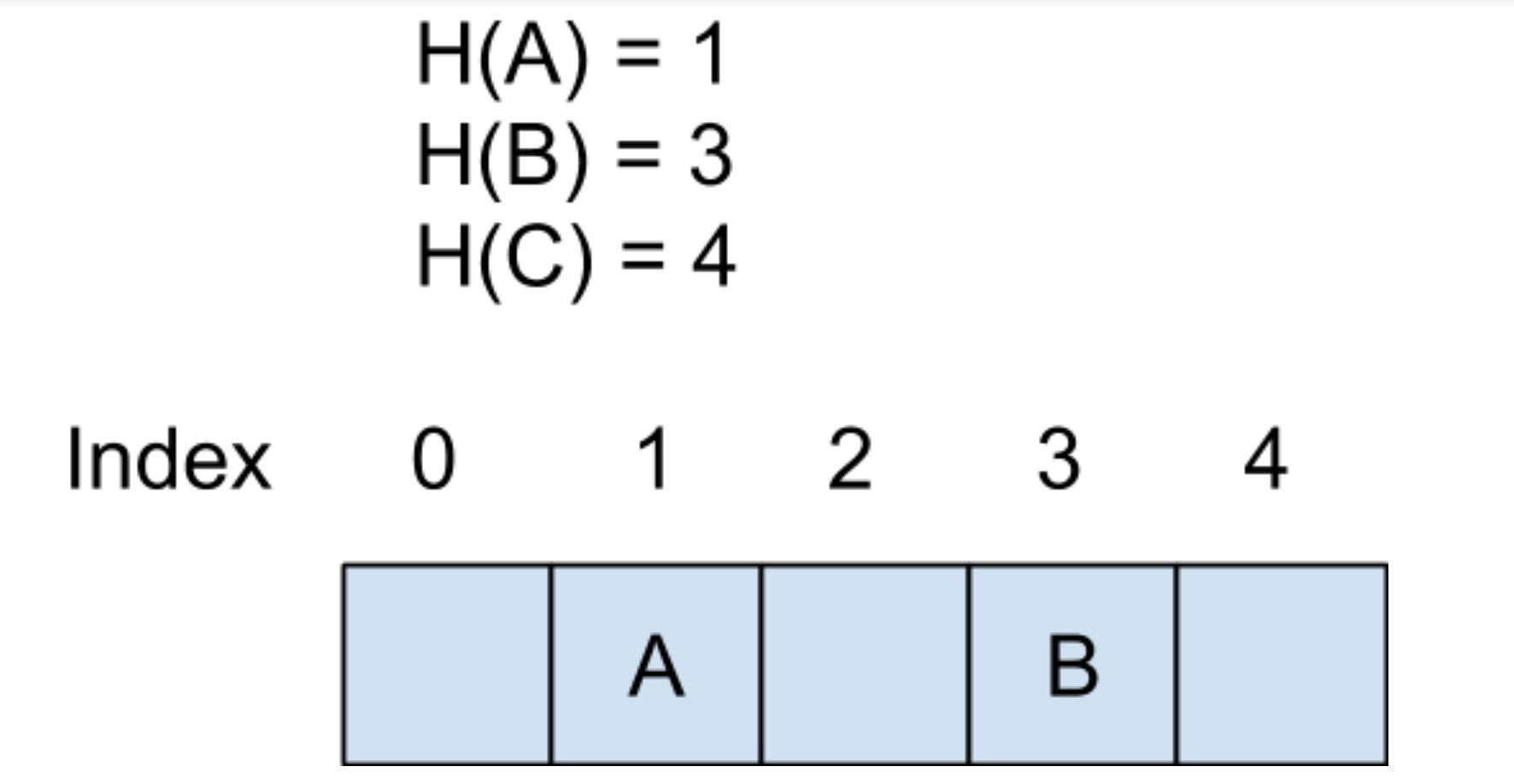
下面以一個例子來說明一下,假設這里的哈希函數是 H(X),鍵 A 和鍵 B 都已經插入到哈希表中了,而 C 并沒有插入,所以我們判斷出 A 和 B 是在這個集合里的,而 C 并不存在集合里。? ?
Sorted Sets 這個類型其實就是在 Set 外的基礎上加上了一個 Score 的概念,Redis 內部會根據 Score 的大小對插入的鍵進行排序。比如說,Pinterest 會把一個用戶所關注的其他用戶按照以關注時間戳為 Score,關注的用戶 ID 作為鍵存放在 Sorted Sets 里。
這樣做的好處就是當一個用戶在查看自己所有關注過的用戶時,可以讀取所有存儲在這個 Sorted Sets 里的數據,而因為 Score 的值是關注這個用戶的時間戳,所以讀取數據出來的時候,會按照自己關注他們的時間順序讀取出來,而不是亂序地讀取關注過的用戶。
Pinterest 也會將對于一個 Board 的所有關注用戶存放在 Redis 的 Hash 里。這樣,一個 Board 每次發布一個新的 Pin 之后,就無需到數據庫中尋找應該推送這個 Pin 給哪些用戶了,而是直接從 Redis 中讀取所有關注了這個 Board 的用戶。
- 前言
- 開篇
- 開篇詞:從此不再“面試造火箭、工作擰螺絲”
- 模塊一:數組與鏈表的應用
- 第 01 講:數組內存模型
- 第 02 講:位圖數組在 Redis 中的應用
- 第 03 講:鏈表基礎原理
- 第 04 講:鏈表在 Apache Kafka 中的應用
- 模塊二:哈希表的應用
- 第 05 講:哈希函數的本質及生成方式
- 第 06 講:哈希函數在 GitHub 和比特幣中的應用
- 第 07 講:哈希碰撞的本質及解決方式
- 第 08 講:哈希表在 Facebook 和 Pinterest 中的應用
- 模塊三:樹的應用
- 第 09 講:樹的基本原理
- 第 10 講:樹在 Amazon 中的應用
- 第 11 講:平衡樹的性能優化
- 第 12 講:LSM 樹在 Apache HBase 等存儲系統中的應用
- 模塊四:圖的應用
- 第 13 講:用圖來表達更為復雜的數據關系
- 第 14 講:有向無環圖在 Spark 中的應用
- 第 15 講:圖的實現方式與核心算法
- 第 16 講:圖在 Uber 拼車業務中的應用
- 模塊五:數據結構組合拳
- 第 17 講:緩存數據結構在 Nginx 中的應用
- 第 18講:高并發數據結構在 Instagram 與 Twitter 中的應用