
在經過了前面?16?個課時的學習之后,我們已經將所有的基礎數據結構都學習了一遍。由于每個數據結構都有自身的優缺點,所以在實際應用的時候,我們應該先了解應用場景的需求。比如說,一個需要頻繁刪改數據的場景和只是頻繁添加和讀取數據的場景,我們所選取的數據結構是不盡相同的。然而,當想要彌補一個數據結構其中的短板時,往往會通過結合另外一種數據結構,來實現取長補短。
在今天這一課時中,我將著重介紹在業界中的幾個常見應用,它們都是將幾個不同的基礎數據結構結合起來,從而打出一套漂亮的數據結構“組合拳”。
#### LRU?緩存
LRU?緩存是利用了?Least Recently Used?算法來實現的一種最最常見的緩存策略。LRU?算法其實不單單只是在緩存策略中被大量用到,它還在計算機操作系統的內存管理中也是一種常見的策略。下面我們先來介紹一下什么是?LRU?算法。
假設有一個應用希望能夠加快數據的訪問速度,因此在內存中設置了緩存來進行加速,為了方便說明,我們假設內存中只能夠存儲?3?個數據,當有更新的數據需要保存在緩存中時,我們必須按照?LRU?算法把最老的數據剔除掉。
當訪問第一個數據?A?的時候,因為緩存中還沒有任何數據,所以可以直接將?A?放到緩存中。如下圖所示:

緊接著應用又訪問了?B?和?C,我們按照從左到右由新到舊的順序來表示緩存中存儲的數據,如下圖所示:

也就是說在最左邊的數據?C?是我們最新放入緩存中的數據,最右邊的?A?是我們最早放入緩存中的數據。
當應用需要再次訪問?A?的時候,應用不需要去硬盤中讀取了,可以直接從緩存中讀取,而此時的緩存如下圖所示,也就是說,數據?B?變成了最早訪問的數據:

此時,應用需要訪問數據?D,而緩存中已經保存滿了?3?個數據,我們必須將最老的數據剔除,也就是剔除掉?B。現在的緩存如下圖所示:

好了,LRU?的算法其實理解起來不算困難,整個算法需要有以下幾個操作:
* Get?操作用于獲取相應的數據;
* Remove?操作將一個數據從緩存中刪除;
* Set?操作用于將相應的數據存放在緩存中,如果緩存空間并未滿,則將數據直接存入緩存;如果緩存空間已滿,則調用?Remove?操作將最舊的數據從緩存中刪除,然后再將新數據存放在緩存中。
那我們要選擇哪一種數據結構來表達這個算法好呢?
因為?LRU?算法里有?Get、Set?和?Remove?操作,所以你很快就想到了哈希表這個數據結構,對于哈希表來說,這些操作的時間復雜度是?O(1)。但哈希表的缺點是無法知道數據插入的順序,這樣我們也就無法得知哪個數據是最新的、哪個數據是最舊的。
那鏈表也許是一個不錯的選擇,我們可以維護一個頭節點指向緩存中最新的數據,尾節點指向緩存中最老的數據。當需要添加新數據而緩存還沒有滿的時候,可以直接將數據添加到鏈表頭,但這里有一個問題,我們要如何判斷這個新數據已經存在于緩存中了呢?需要遍歷一遍整個鏈表,其所需的時間復雜度是?O(N)。
同理,Get?和?Remove?操作同樣需要遍歷整個鏈表,平均下來時間復雜度也是?O(N)。這樣,我們雖然解決了維護一個從最新使用到最舊的數據問題,但是時間復雜度卻提高了。
#### 哈希表和鏈表的結合
最終的解決方法也許你已經想到了,就是將哈希表和鏈表結合起來,哈希表的值保存了鏈表節點的位置。因為我們需要記錄數據的使用情況,一個常見的操作是將鏈表中某一個節點數據移動至鏈表頭,所以在這里采用雙向鏈表,從而可以更方便地將鏈表中的數據移動至鏈表頭。哈希表的作用是可以使查找一個數據的時間復雜度降到?O(1)。
這個時候,緩存的內存圖如下圖所示:?
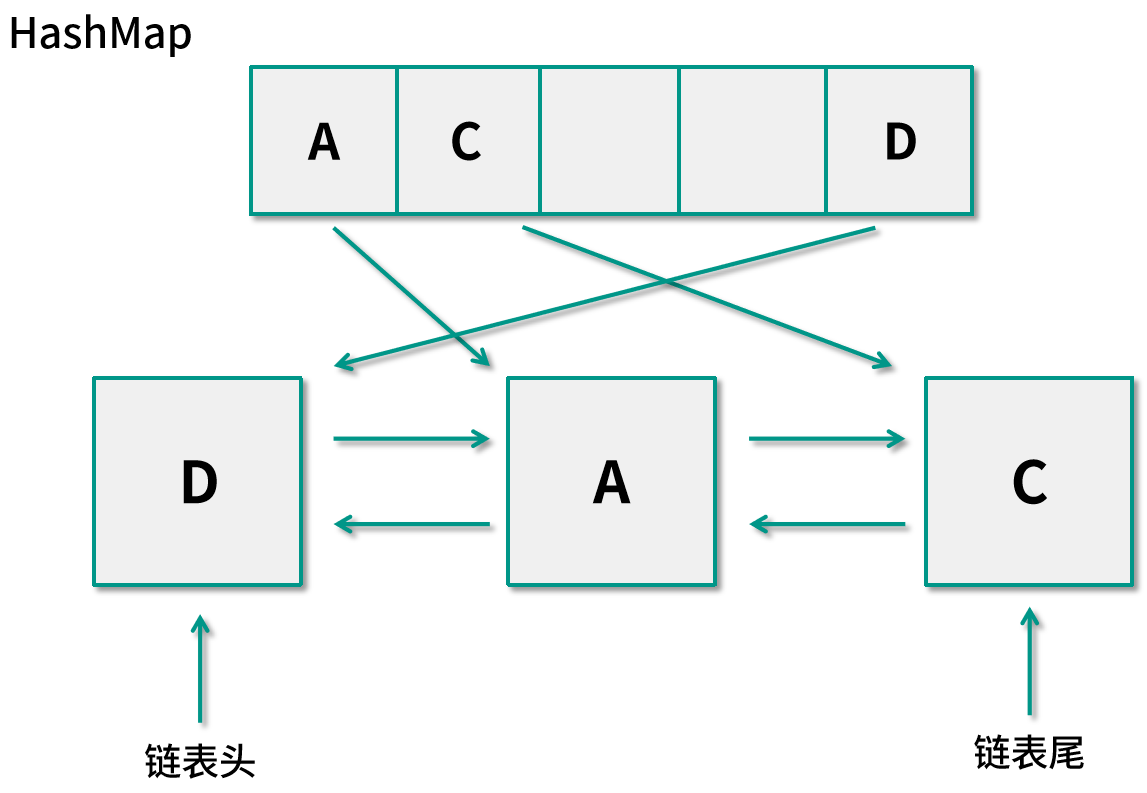
我們來再舉例說明一下幾個關鍵操作在融合了哈希表和雙向鏈表后的時間復雜度。
假設應用再次需要訪問數據?C,我們需要先判斷緩存中是否已經保存過這個數據了,此時只需要從哈希表中查看,發現?C?已經存在,通過哈希表的值我們可以直接定位到?C?節點在鏈表中的位置,再將這個節點移動到雙向鏈表的鏈表頭,這個操作的時間復雜度為?O(1),內存圖如下所示:
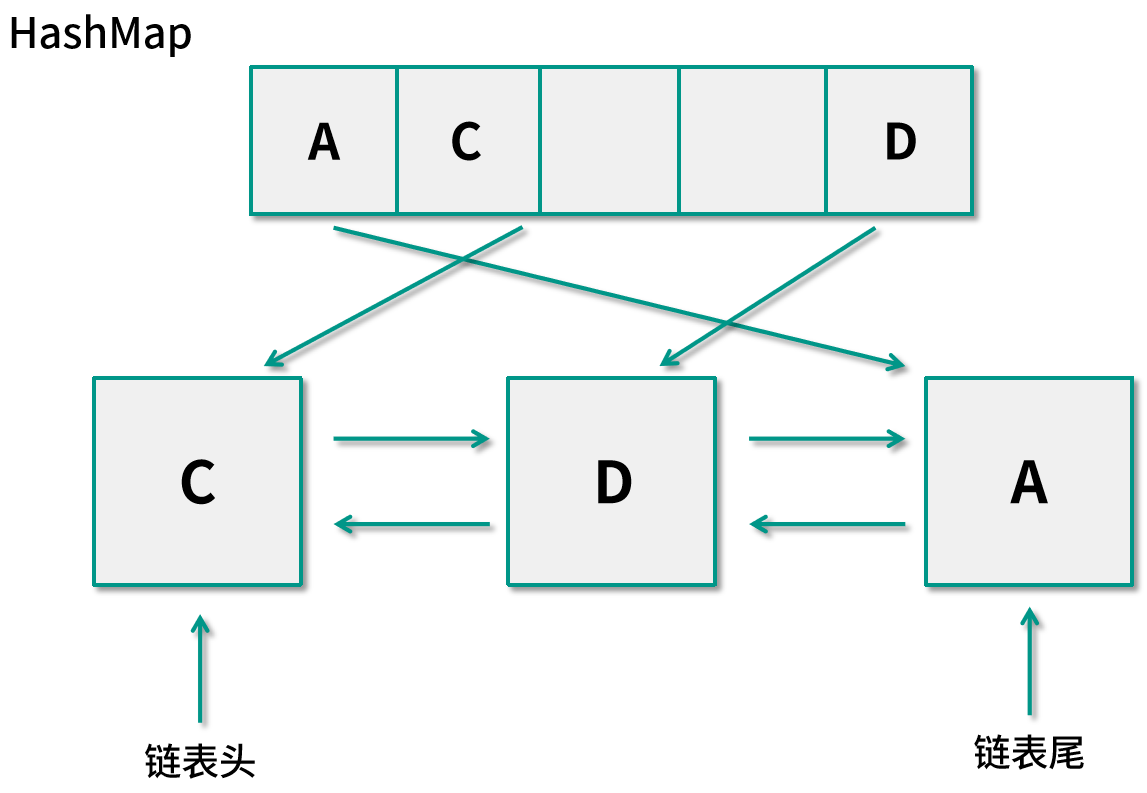
如果應用需要訪問數據?B,我們還是需要判斷緩存中是否已經保存過這個數據了,通過哈希表可以發現并不存在,而緩存中的數據已經滿了,所以需要剔除最舊的數據?A,也就是保存在雙向鏈表鏈表尾的節點。因為維護了尾節點,我們可以在?O(1)?的時間內找到它,同時將哈希表中的數據也刪除掉。現在的尾節點則指向了?D,而鏈表頭則指向了新加入的節點?B,內存如下圖所示:
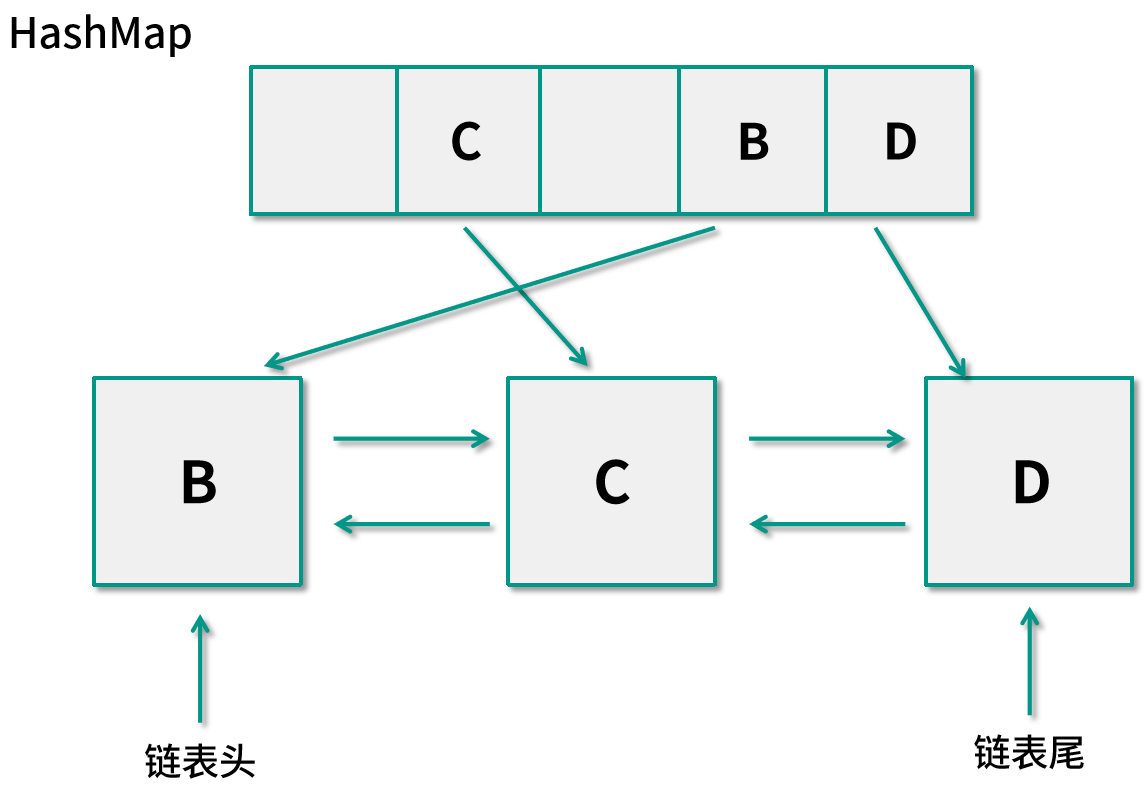
這樣的數據結構組合可以將所有的操作時間復雜度都優化到了?O(1),像?Memcached?和?Nginx?這樣反向代理都會使用這種?LRU?算法。
當然了,如果你是使用?Java?的話,應該聽說過一個叫?LinkedHashMap?的?Collection,它的核心實現部分其實和上面講到的哈希表與鏈表的結合很像,感興趣的話可以自行研究一下它的實現方式。(點擊這里查看源代碼)
#### Trie?樹
這里我還想和你介紹另外一個高級數據結構,那就是?Trie?樹。Trie?樹也被稱為前綴樹或者字典樹,下面我們通過一個例子來說明一下?Trie?樹的優點。
我們希望能夠快速插入并且查找一系列的字符串,比如說以下的字符串:String、Stringent、Strings、Strong,當然了,使用哈希表來達到這個要求是毫無問題的。但是如果現在我們再額外加一些限制,比如說要存儲的字符串不單單是正常的英文單詞,還可以是十分長的無規則的字符串,在內存空間也十分有限的情況下,我們要如何應對呢?這個時候?Trie?樹就派上用場了。
以上面的?4?個字符串為例,其實它們都有著一些相同的前綴,比如說?String、Stringent,Strings?有?String?這樣的相同前綴,String、Stringent、Strings、Strong?有?Str?這樣的相同前綴。我們可以通過?Trie?樹來優化存儲空間,使不同的字符串盡量共享相同的前綴,一個根據上面?4?個字符串構建出來的?Trie?樹,如下圖所示:
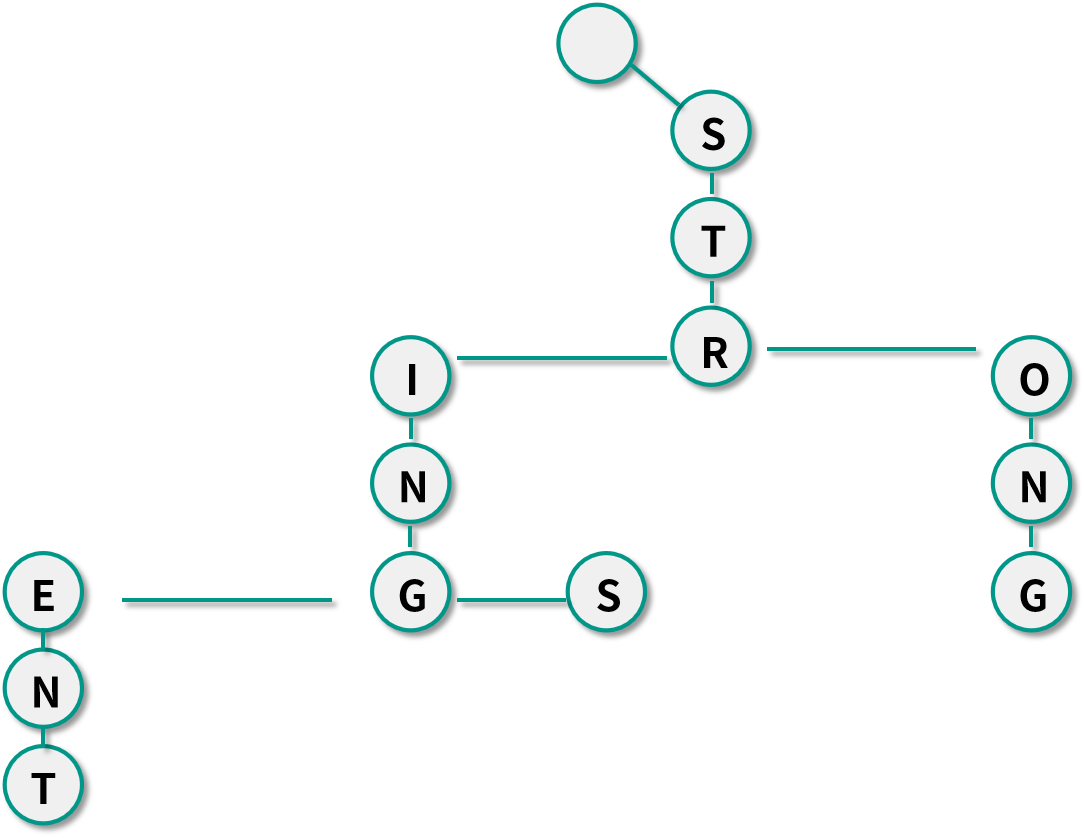
根據這種思想,在插入一個字符串的時候,會按照字母順序將每一個字母作為?Trie?樹的節點保存起來。在查找字符串是否存在的時候,只需要順著?Trie?樹的根節點從上至下往下搜索便可了。當然了,Trie?樹的每一個節點可以不單單保存一個字母,可以根據應用的需求來增加其他的值。
Trie?樹的應用十分廣泛,比如說常見的?DNS?反向解析,也就是通過一個?IP?地址到域名的解析,同樣會用到?Trie?樹。因為?IP?地址從理論上,每一部分都是由?0?到?255?組成的,這里面有著相當多的共同前綴,如果使用?Trie?樹來進行?DNS?反向解析的話,則可以節省大量的內存空間。
- 前言
- 開篇
- 開篇詞:從此不再“面試造火箭、工作擰螺絲”
- 模塊一:數組與鏈表的應用
- 第 01 講:數組內存模型
- 第 02 講:位圖數組在 Redis 中的應用
- 第 03 講:鏈表基礎原理
- 第 04 講:鏈表在 Apache Kafka 中的應用
- 模塊二:哈希表的應用
- 第 05 講:哈希函數的本質及生成方式
- 第 06 講:哈希函數在 GitHub 和比特幣中的應用
- 第 07 講:哈希碰撞的本質及解決方式
- 第 08 講:哈希表在 Facebook 和 Pinterest 中的應用
- 模塊三:樹的應用
- 第 09 講:樹的基本原理
- 第 10 講:樹在 Amazon 中的應用
- 第 11 講:平衡樹的性能優化
- 第 12 講:LSM 樹在 Apache HBase 等存儲系統中的應用
- 模塊四:圖的應用
- 第 13 講:用圖來表達更為復雜的數據關系
- 第 14 講:有向無環圖在 Spark 中的應用
- 第 15 講:圖的實現方式與核心算法
- 第 16 講:圖在 Uber 拼車業務中的應用
- 模塊五:數據結構組合拳
- 第 17 講:緩存數據結構在 Nginx 中的應用
- 第 18講:高并發數據結構在 Instagram 與 Twitter 中的應用