
Spark 是當今最流行的分布式大規模數據處理引擎之一,被廣泛應用在各類大數據處理的場景中,而大數據處理框架的核心就是用有向無環圖(DAG)來優化數據處理任務的。我們來看一個例子吧。
假設你的大數據處理任務是根據活躍在街頭的美團外賣電動車的數量來預測美團的股價,而你負責處理所有美團外賣電動車的圖片。在真實的商用環境下,你可能至少需要 10 個子任務:
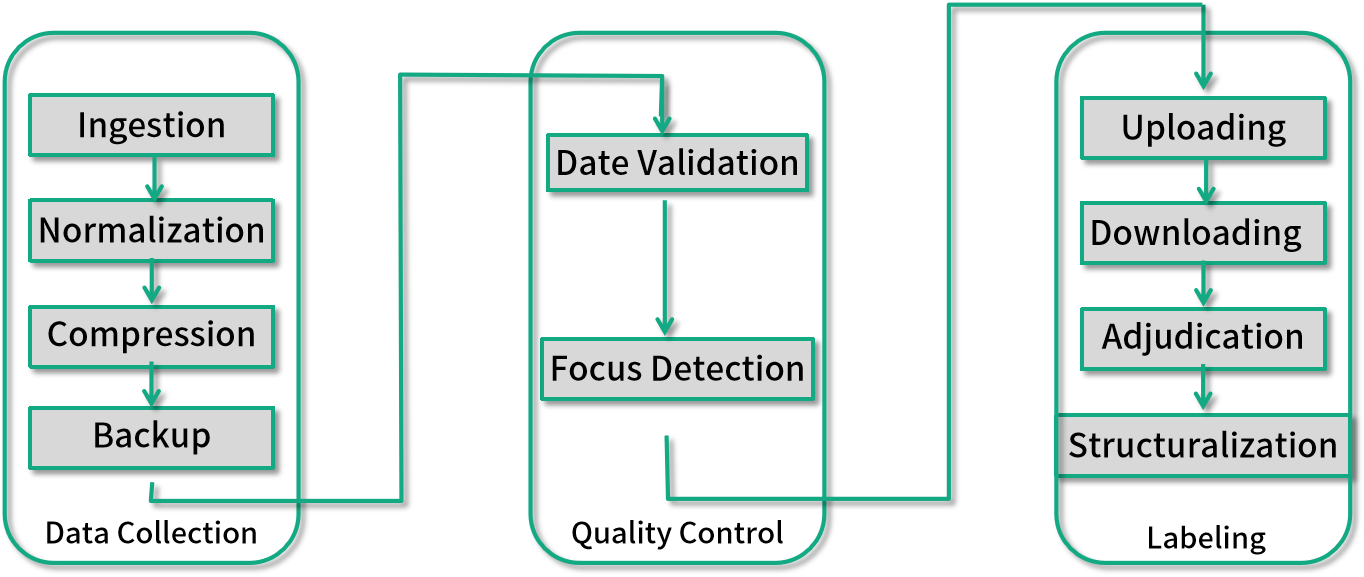
為什么需要這么多數據處理任務?且聽我一一解釋。
首先我們需要搜集每日的外賣電動車圖片,往往數據搜集的工作不僅僅是公司本身完成的,部分也有外包或者眾包,所以在數據搜集(Data Collection)部分,你至少需要以下 4 個數據來處理任務。
* (1)數據導入(Data Ingestion):用來把散落在比如眾包公司上傳到網盤的照片下載到你的存儲系統中。
* (2)數據統一化(Data Normalization):用來把不同外包公司各式各樣的格式統一。
* (3)數據壓縮(Compression):你需要在質量可接受的范圍內保持最小的存儲資源消耗。
* (4)數據備份(Backup):大規模的數據處理系統我們都需要一定的數據冗余來降低風險。
僅僅是數據搜集離真正的業務應用還差得遠,真實的世界是如此的不完美,我們需要一部分數據質量控制(Quality Control)流程,比如:
* (1)數據時間有效性驗證(Date Validation),檢測上傳的圖片是否是你想要的日期;
* (2)照片對焦檢測(Focus Detection),你需要篩選掉那些對焦不上,完全無法使用的照片;
最后才到你的重頭戲,即找到這些圖片里的外賣電動車,而這一步因為人工的介入是最難控制時間。
此時,你需要:
* (1)數據標注問題上傳(Question Uploading),上傳到你的標注工具,讓你的標注者開始工作;
* (2)標注結果下載 (Answer Downloading),抓取標注完的數據;
* (3)標注異議整合(Adjudication),標注異議經常發生,比如一個標注者認為是美團外賣電動車,另一個標注者認為是京東快遞電動車;
* (4)標注結果結構化(Structuralization),要讓標注結果可用,你需要把可能非結構化的標注結果轉化成你的存儲系統接受的結構。
這樣,復雜的數據處理如果再去人工維護的話,則令人苦不堪言,因為你需要知道先執行哪個任務再執行哪個任務。
#### 有向無環圖
為了解決這個問題,在 Spark 等大數據處理框架中可用有向無環圖(DAG)來抽象表達。因為有向圖能為多個步驟的數據處理依賴關系,建立很好的模型。我們來復習一下上一講中有向無環圖的概念。
比如下圖是一個有向圖:
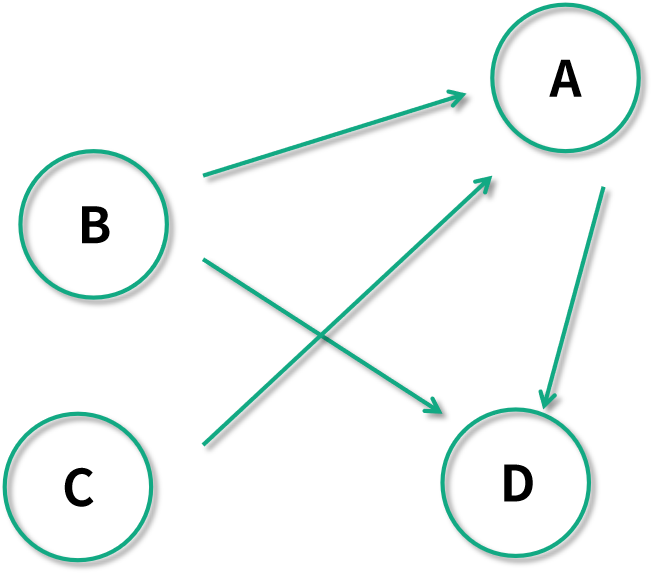
有向圖可以表達任務之間的依賴關系,比如 B 指向 A,我們可以表達要執行任務 A ,則需要先完成任務 B 才可以。
比如下圖是一個有環圖。下圖中 B 任務依賴于 D,C 任務依賴于 B,E 任務依賴于 C,D 任務又依賴于 B。有環圖在表達任務關系的時候是一個災難,因為你沒法找到是從哪個任務開始處理的。
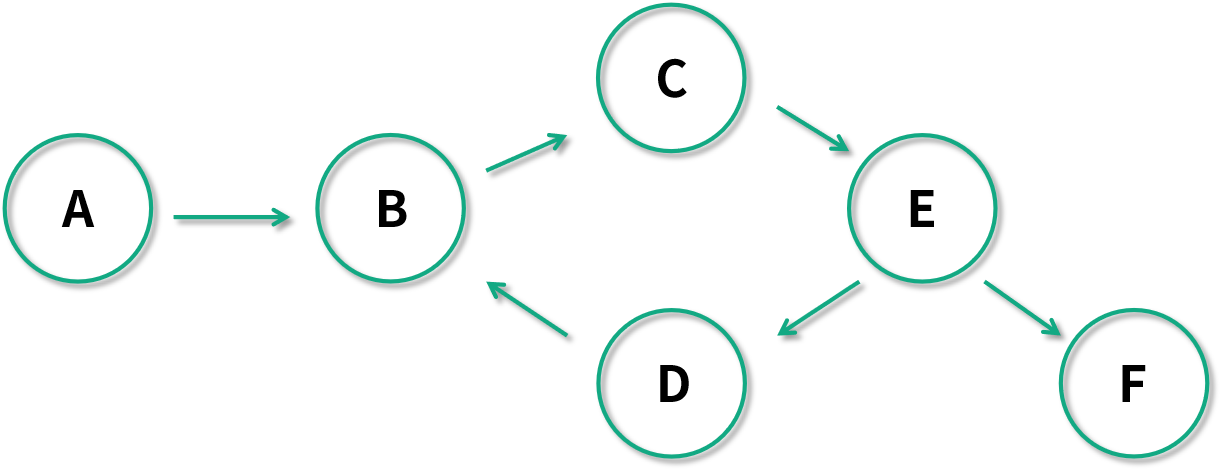
* [ ] 如何用有向無環圖抽象表達數據處理的任務
回顧了有向和無環圖的特性,我們來看如何用有向無環圖(DAG)來抽象表達數據處理任務。下面列舉一個生活中的任務處理案例。
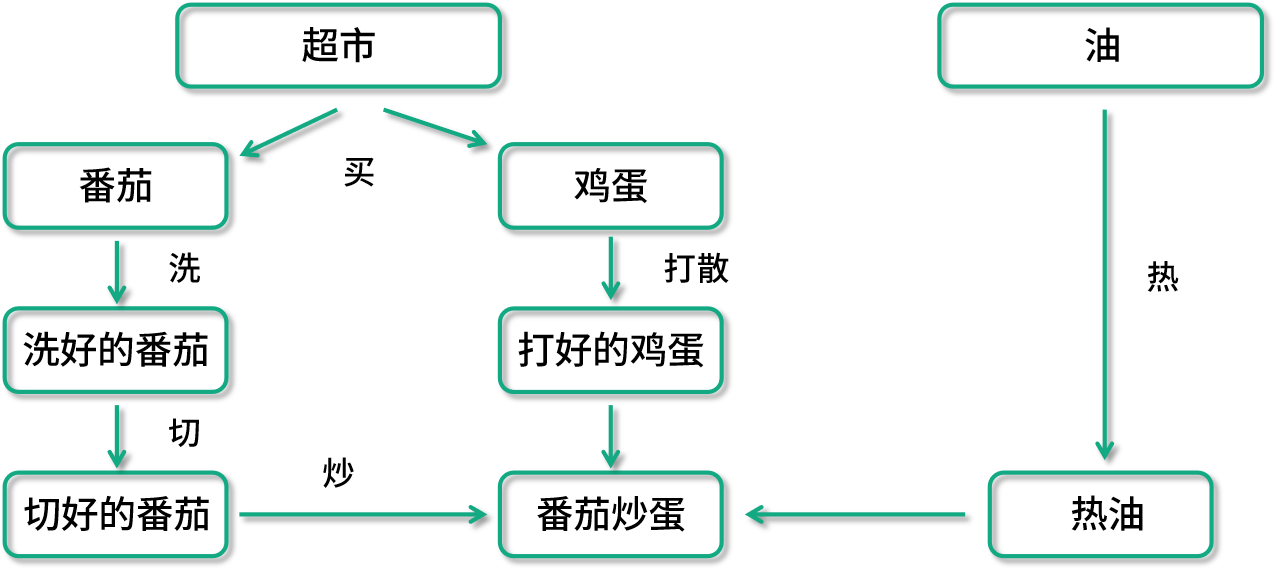
西紅柿炒雞蛋這樣一個菜,就是一個有向無環圖概念的典型案例。比如看這里面番茄的處理,最后一步炒的步驟依賴于切好的番茄、打好的蛋、熱好的油,切好的番茄又依賴于洗好的番茄等操作。如果用 Spark 來實現的話,在這個圖里面,每一個箭頭都會是一個獨立的數據轉換操作(Transformation)。
Spark 利用有向無環圖表達數據處理后可以對數據處理流程做自動優化。回到剛才的番茄炒雞蛋的例子,哪些情況我們需要自動的優化呢?
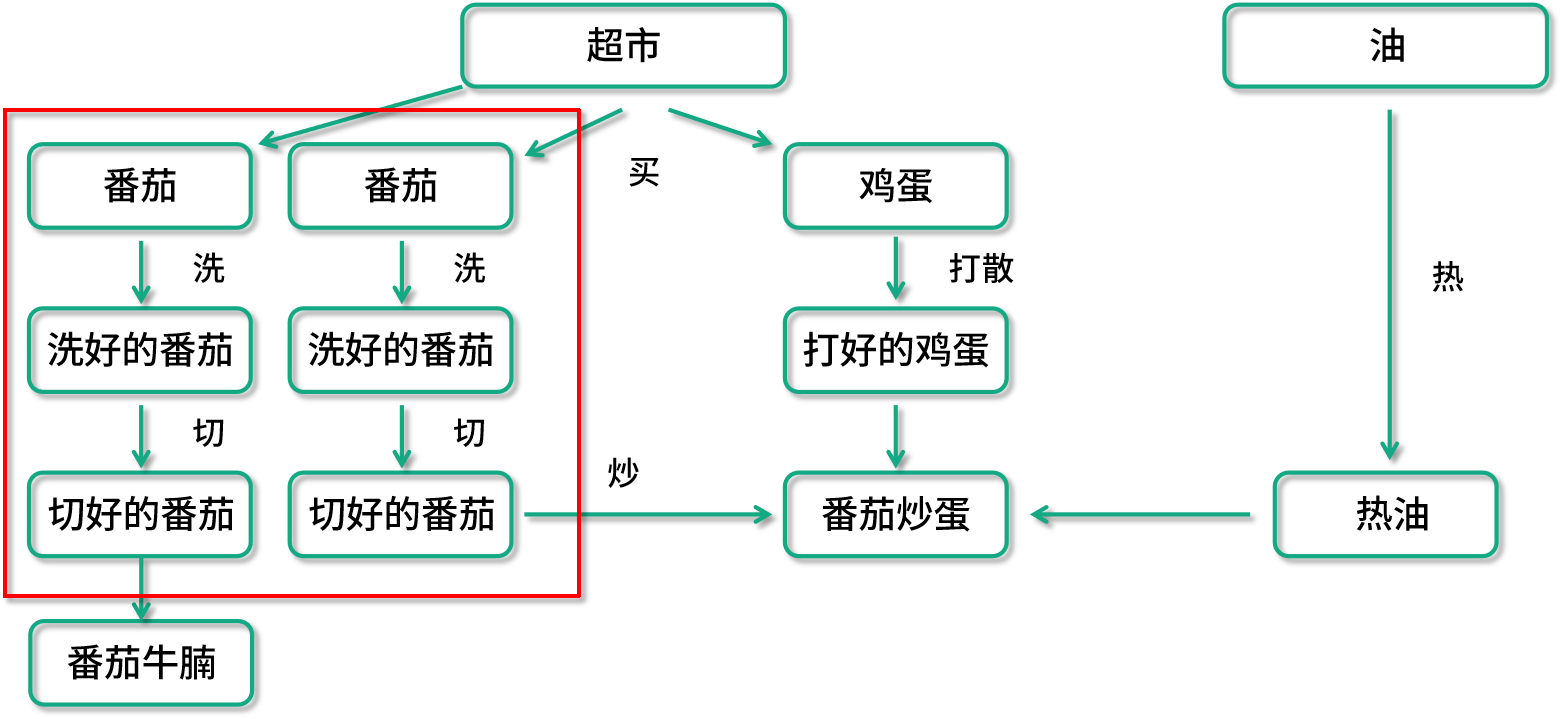
設想一下我們的數據在處理食譜上又增加了番茄牛腩的需求,用戶的數據處理有向圖就變成了這個樣子了。在理想的情況下,我們的計算引擎要能夠自動發現紅框中的兩條數據處理流程是重復的,它要能把兩條數據處理過程進行合并。這樣的話,番茄就不會被重復準備了;同樣的,如果需求突然不再需要番茄炒蛋了,只需要番茄牛腩,在數據流水線的預處理部分也應該把一些無關的數據操作優化掉,比如整個雞蛋的處理過程就不應該在運行時出現。
另一種自動的優化是計算資源的自動彈性分配。比如還是在番茄炒蛋這樣一個數據處理流水線中,如果你的規模上來了,今天需要生產 1 噸的番茄炒蛋,明天需要生產 10 噸的番茄炒蛋。此時你會發現,有時候是處理 1000 個番茄,有時候又是 10000 個番茄。如果手動去做資源配置的話,那再也配置不過來了。我們的優化系統也要有這種彈性的勞動力分配機制,它要能自動分配比如 100 臺機器處理 1000 個番茄,如果是 10000 個番茄那就分配 1000 臺機器,但是只給熱油 1 臺機器可能就夠了。
有向無環圖便是 Spark 框架能夠自動優化執行計劃的核心,再看一個例子:
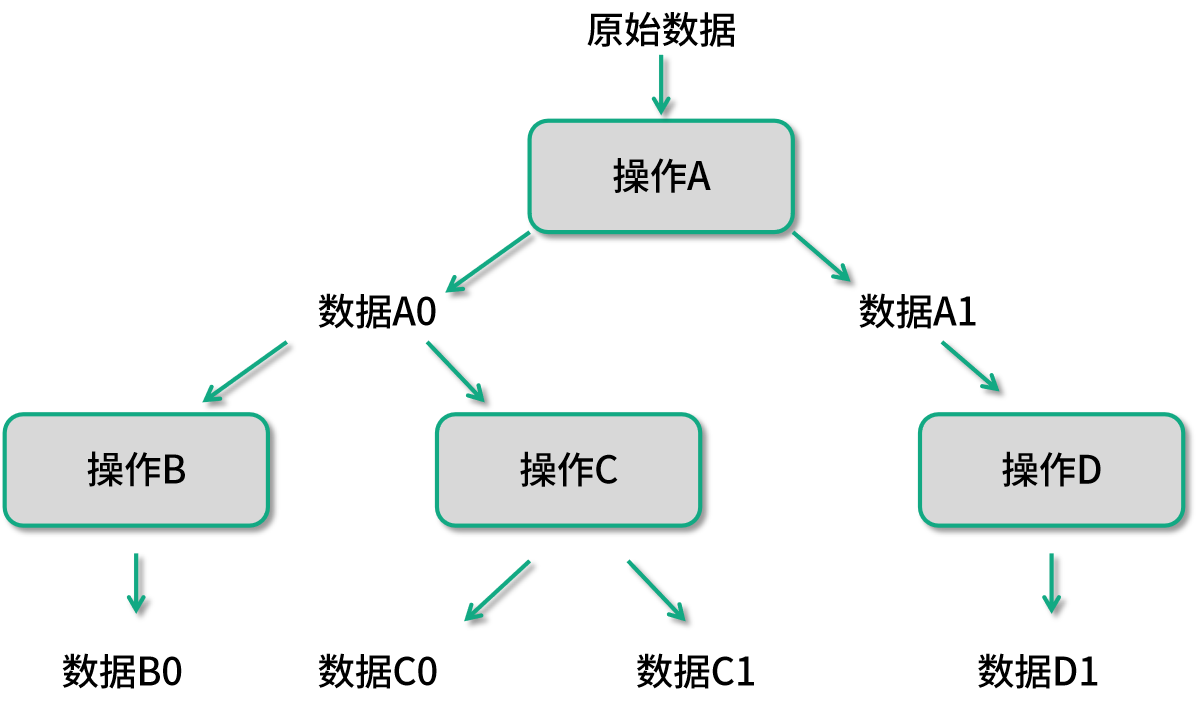
類似圖中這樣的數據處理流程,在 Spark 獲知了整個數據處理流程就會被優化成如下圖所示的樣子:
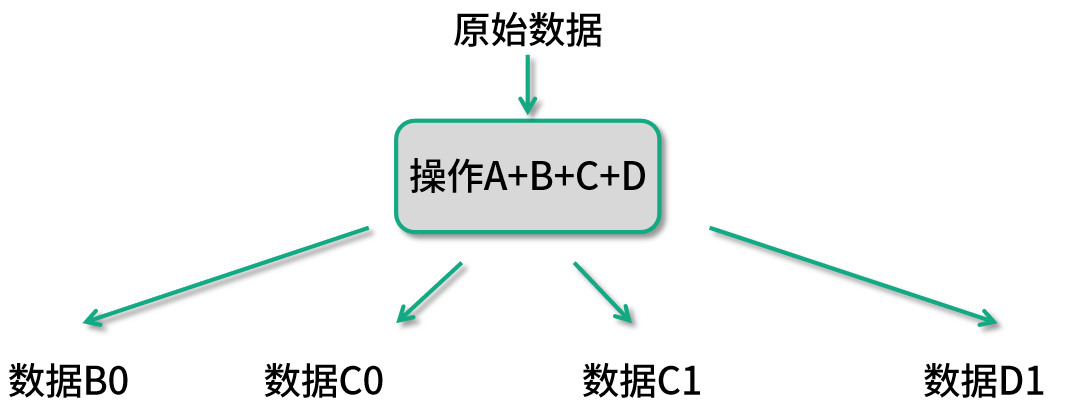
這樣的優化在 Spark 中被稱為兄弟融合優化(Sibling Fusion)。
#### 總結
這一講我們回顧了圖的有向和無環的概念,利用有向圖建模生活中的數據處理問題,并分析了 Spark 怎樣利用有向無環圖優化數據處理。
- 前言
- 開篇
- 開篇詞:從此不再“面試造火箭、工作擰螺絲”
- 模塊一:數組與鏈表的應用
- 第 01 講:數組內存模型
- 第 02 講:位圖數組在 Redis 中的應用
- 第 03 講:鏈表基礎原理
- 第 04 講:鏈表在 Apache Kafka 中的應用
- 模塊二:哈希表的應用
- 第 05 講:哈希函數的本質及生成方式
- 第 06 講:哈希函數在 GitHub 和比特幣中的應用
- 第 07 講:哈希碰撞的本質及解決方式
- 第 08 講:哈希表在 Facebook 和 Pinterest 中的應用
- 模塊三:樹的應用
- 第 09 講:樹的基本原理
- 第 10 講:樹在 Amazon 中的應用
- 第 11 講:平衡樹的性能優化
- 第 12 講:LSM 樹在 Apache HBase 等存儲系統中的應用
- 模塊四:圖的應用
- 第 13 講:用圖來表達更為復雜的數據關系
- 第 14 講:有向無環圖在 Spark 中的應用
- 第 15 講:圖的實現方式與核心算法
- 第 16 講:圖在 Uber 拼車業務中的應用
- 模塊五:數據結構組合拳
- 第 17 講:緩存數據結構在 Nginx 中的應用
- 第 18講:高并發數據結構在 Instagram 與 Twitter 中的應用