
在上一講中,我們一起學習了哈希函數這個概念,哈希函數不只是在生成哈希表這種數據結構中扮演著重要的角色,它其實在密碼學中也起著關鍵性的作用。密碼學這個概念聽上去離我們很遙遠,但其實它已經被應用在我們身邊各式各樣的軟件中。所以這一講我們一起來看看哈希函數是如何被應用在?GitHub?中的,以及再看看鏈表和哈希函數在比特幣中是怎么應用的。
#### 加密哈希函數
一個哈希函數如果能夠被安全地應用在密碼學中,我們稱它為加密哈希函數(Cryptographic Hash Function)。“數字摘要”這個名詞,你應該不會陌生,它也是通過加密哈希函數,由任意長度的一個信息轉換出來的一個固定長度的哈希值。
數字摘要通常是用于檢驗一段數據或者一個文件的完整性(Integrity)的,而驗證數據文件完整性就是利用了哈希函數里的其中一個特性:“兩個相同的對象作為哈希函數的輸入,它們總會得到一樣的哈希值”。而當這個數據文件里面的任何一點內容被修改之后,通過哈希函數所產生的哈希值也就不一樣了,從而我們就可以判定這個數據文件是被修改過的文件。在很多地方,我們也會稱這樣的哈希值為檢驗和(Checksum)。當然了,我們也不能忘了哈希函數的另外一個特性:“兩個不同的對象作為哈希函數的輸入,它們不一定會得到不同的哈希值”。
常見的加密哈希函數算法,有 MD(Message Digest)算法和 SHA(Secure Hash Algorithm)算法。
> MD?算法可以通過輸入產生一個?128?位的哈希值出來,用于確保信息傳輸的完整性;而在?SHA?算法中,比較常見的有?SHA-1、SHA-256?算法等,它們也是可以通過輸入而產生一個?160?位或者?256?位的哈希值出來,它們與?MD?算法一樣,都是用于確保信息傳輸的完整性,對這些算法感興趣的同學,可以自行延伸閱讀?MD?和?SHA?的百科資料。
這些加密哈希函數算法,它們所做的事情并不是要為每一個數據文件都生成一個唯一的哈希值出來,而是通過這些加密哈希函數算法,使得不同的數據文件生成出來的哈希值產生哈希碰撞的概率非常的小,小到幾乎不可能。這樣的話,我們就有把握說,當兩份數據文件通過加密哈希函數所生成出來的哈希值一致時,這兩份數據文件就是同一份數據文件。
* [ ] SHA-1 加密算法
但是如果有一天,我們可以人為地去修改數據文件,讓兩份不同的文件通過加密哈希函數之后生成同樣的哈希值,那采用這些加密哈希函數去做驗證的應用就有可能會被別有用心的黑客所攻擊了。在?2017?年的時候,SHA-1?加密算法被正式宣布攻破了,這意味著什么呢?這意味著那些采用?SHA-1?加密算法去驗證數據完整性的應用有可能會被人為地制造哈希碰撞而遭到攻擊。
采用?SHA-1?加密算法來做數據完整性驗證的一個很著名的應用就是?Git。簡單地說,Git?采用了?SHA-1?算法來對每一個文件對象都進行了一次哈希值運算,所以每一個提交的文件都會有自己的一個哈希值。在?Git?里面要找到一個文件對象其實是通過哈希值來尋找的。
而在我們提交代碼,運行“git commit”命令的時候,Git?會將所有的這些文件,外加一些元數據(Metadata)再做一次?SHA-1?運算來得到一個新的哈希值,這些元數據里就包括了上一次?commit?時所生成的哈希值。將上一次?commit?所產生的哈希值也包括進來主要為了防止有人惡意地去修改中間的一些?commit,這樣,所有后面的?commit?就可以發現,自己所保存的上一次?commit?的哈希值和被修改過的?commit?的哈希值不一致了,也就是說中間的?commit?被人篡改了。
* [ ] GitHub 面臨的問題
現在我們知道了,Git?其實是通過?SHA-1?算法所產生的哈希值去找到一個文件對象的,那如果有惡意程序可以對兩個不同的文件制造出相同的哈希值,也就是產生哈希碰撞,這樣?Git?就無法確定到底哪一個文件才是“真的”。
著名的代碼軟件托管平臺?GitHub?其實也面臨著同樣的問題。當然了,根據?2017?年所公布的實驗結果,真的要人為的去制造一個?SHA-1?哈希沖突攻擊的話,現階段的代價是非常昂貴的,比方說需要耗費 6500 年的單核?CPU?計算時間,或者說需要消耗?110 年的單核?GPU?計算時間,所以單單靠著暴力枚舉的方法是不太可行的。
而根據?Github.com?的報告,一些針對?Github.com?的碰撞攻擊其實是運用了一些特殊的技巧來減少這些運算時間,而這些攻擊里面都會有一個固定的“字節模式”可循。所以?GitHub.com?會針對每一個上傳的文件都執行一種?SHA-1?碰撞的檢測,而他們所用的檢測工具也是開源的(檢測工具源代碼)。
Linux?和?Git?之父?Linus?也對于?SHA-1?被攻破發表了一些自己的看法,下面我也附上了他本人親自回復的一封郵件,感興趣的話可以自行來查看這封郵件的內容。
* [ ] 比特幣的本質
比特幣是區塊鏈技術中比較著名的一項應用,同時,比特幣也和鏈表、哈希函數這兩種數據結構有著千絲萬縷的關系。
比特幣是由一個網名為“中本聰”的人所提出的,在?2009?年誕生的一個虛擬加密貨幣,它的本質思想是以區塊鏈為基礎而搭建起來的一個去中心化的記賬系統。我們平時所使用的記賬系統,無論是使用實體銀行卡或者是使用移動支付,其交易信息都會記錄在一個統一的數據庫中。而在去中心化的記賬系統里,則會把這些交易信息進行加密直接存放在用戶那里。
比特幣將所有的交易記錄都存放在了一個叫區塊(Block)的數據結構里面,我們可以把這里的區塊看作是鏈表數據結構中的一個節點。當用戶需要將新的交易記錄打包的時候,可以自己創建一個新的區塊出來,放在整個區塊鏈的結尾,也就相當于在一個鏈表的結尾插入一個新的節點,而在整個區塊鏈中的第一個區塊,也就是鏈表的頭節點,叫做創世區塊(Genesis Block)。
與鏈表數據結構使用內存地址去尋找下一個節點不同的是,區塊鏈采用了哈希值的方式去尋找節點。在比特幣里,它采用的是?SHA-256?這種加密哈希函數,將每一個區塊都計算出一個?256?位的哈希值。在每一個新的區塊中都會保存著上一個區塊所計算出來的哈希值,通過這個哈希值,我們就可以找到哪一個區塊是這個新區塊的上一個區塊。所有的區塊都可以通過這種機制去尋找上一個區塊,從而遍歷整個區塊鏈,直到找到創世區塊為止。
當然了,不是每個人都是有“資格”去創建一個新區塊的。就如上一講中所講述的區塊鏈“挖礦”原理一樣,只有當一個用戶“挖礦”成功了,那這個用戶才有資格去打包交易信息并建立一個新的區塊。一個典型的比特幣區塊鏈就如下圖所示:
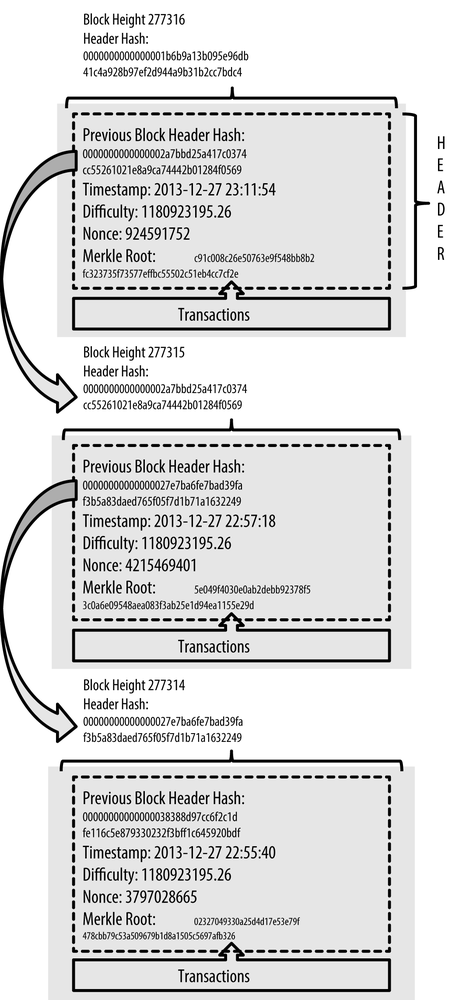
備注:圖片來自《Mastering Bitcoin》圖書的第 7 章。
- 前言
- 開篇
- 開篇詞:從此不再“面試造火箭、工作擰螺絲”
- 模塊一:數組與鏈表的應用
- 第 01 講:數組內存模型
- 第 02 講:位圖數組在 Redis 中的應用
- 第 03 講:鏈表基礎原理
- 第 04 講:鏈表在 Apache Kafka 中的應用
- 模塊二:哈希表的應用
- 第 05 講:哈希函數的本質及生成方式
- 第 06 講:哈希函數在 GitHub 和比特幣中的應用
- 第 07 講:哈希碰撞的本質及解決方式
- 第 08 講:哈希表在 Facebook 和 Pinterest 中的應用
- 模塊三:樹的應用
- 第 09 講:樹的基本原理
- 第 10 講:樹在 Amazon 中的應用
- 第 11 講:平衡樹的性能優化
- 第 12 講:LSM 樹在 Apache HBase 等存儲系統中的應用
- 模塊四:圖的應用
- 第 13 講:用圖來表達更為復雜的數據關系
- 第 14 講:有向無環圖在 Spark 中的應用
- 第 15 講:圖的實現方式與核心算法
- 第 16 講:圖在 Uber 拼車業務中的應用
- 模塊五:數據結構組合拳
- 第 17 講:緩存數據結構在 Nginx 中的應用
- 第 18講:高并發數據結構在 Instagram 與 Twitter 中的應用