
這一講的內容以 Amazon 云服務為例,來分享分布式 SQL 數據庫如何使用樹這樣的數據結構優化 SQL 執行的。雖然我迫不及待地想和你直接深入底層技術原理,但是在講解非常酷的技術細節之前,我們還是先回過頭看一下什么是 SQL 執行優化?為什么要優化 SQL 執行?
#### 什么是 SQL
SQL(Structured Query Language)在硅谷科技公司一般讀作 sequel,其實在 1970 年代 IBM 發明 SQL 的時候它本來被稱作 SEQUEL(Structured English Query Language),但后來因為 SEQUEL 作為商標已經被注冊了,只能改名為 SQL。不熟悉這段歷史的人有時候會讀作 S-Q-L(分開三個字母讀),雖然也聽得懂的,但沒有那么地道了!
SQL 被用來管理和查詢關系型數據庫。比如:
```
SELECT?name?FROM?table;
```
這樣一行 SQL 可以選取下表中所有的 name 這一列:

執行這行 SQL 指令的輸出一般就是 Alex、David、Patrick。
SQL 在 20 世紀 80 年代成為了 ANSI/ISO 國際標準。但即使是國際標準,不同的關系型數據庫的實現都有很多不同,比如 MySQL、PostgreSQL 對于 SQL 標準的實現就不同。更不用說在專門優化的大型分布式數據庫就更不一樣了,比如本文要介紹的 Amazon 云服務 AWS 里所使用的 SQL 執行引擎,就擁有很多獨門秘籍的實現。
#### 為什么要優化 SQL 的執行
我們已經了解了 SQL 最常用的用途就是查詢數據。然而關系型數據庫在執行 SQL 語句時必須要考慮效率,即:
* 需要多長時間完成這條 SQL 查詢?
* 需要多少計算資源,包括 CPU、磁盤、電能去執行這條 SQL 語句?
關系型數據庫具體怎樣執行 SQL 語句我們稱之為執行計劃(Execution Plan),很不幸的是同樣一條 SQL 語句的可選執行計劃非常多。我們來看一個例子:
```
SELECT?*
FROM?customers?c,?orders?o
WHERE?c.id?=?o.cust_id?AND?c.creation_timestamp?<?1579069516;
```
這個例子的 SQL 從語義上理解的話,是想要在 customers 和 orders 這兩種表中,找出所有 customers 的 creation_timestamp 早于某個時間的所有數據,看起來似乎很好理解啊。其實背后的 SQL 引擎在執行它的時候是有很多糾結的,糾結什么呢?就是選擇執行計劃。
由于篇幅有限,在這里就不再羅列所有可能的執行計劃了。但是為了闡述我的觀點,以下列舉了幾個執行計劃的例子:
* Creation_timestamp 小于這樣一個過濾條件應該在 JOIN 語句前執行呢,還是在 JOIN 語句之后執行?
* 對于 JOIN 語句我們應該使用 merge join,還是 hash join,還是用建立的 index 使用 nested loop join 呢?
* 如果是 hash join 或者 nested loop join 的話,我們應該是先遍歷 cutomers 表然后查找對應的 orders,還是先遍歷 orders 表再查找對應的 customers 呢?
* 如果我們對于 creation_timestamp 建立有二級索引(Secondary Index)的話,我們是應該用二級索引查找 creation_timestamp 還是用主索引查找 ID 比較快?
作為數據庫 SQL 引擎,這些問題的答案都是相互依賴的,也都是需要交叉考慮的。比如說如果選擇 nested loop join,可能搭配使用二級索引比較好;但是如果使用 merge join 的話,可能還是使用主索引比較好。最優的執行計劃還取決于我們的表有多少行,各種物理操作的相對速度,還有不同數據的存儲位置和數據值的分布等,可以說要考慮的參數是非常非常的多!
所以在 Amazon AWS 這樣大型的分布式 SQL 數據庫中,對 SQL 的執行計劃進行了大量的優化。一個簡單的 SQL 執行引擎模型是這樣子的:
* 首先是 SQL 解析器(Parser),它負責把用戶輸入的 SQL 解析成 SQL 語法樹(AST),對的,就是我們講的樹!
* 后面的 SQL 優化器(Optimizer)接受前面解析的原生語法樹,對它進行優化重寫語法樹和執行計劃。一般優化器不僅僅會看語法樹,還需要結合特定的用戶數據庫配置,數據實際分布進行優化。
* 最后面的 SQL 執行器(Executor)才會去真正的執行優化重寫的 SQL 語法樹。

* [ ] SQL 語法樹是個什么樹
AST(Abstract Syntax Tree)即語法樹,在計算機科學中是用樹來表達源代碼的一種方式。我們理解的編譯器很大一部分工作就是把源碼表示成語法樹。不過在這里不展開語法樹的講解,因為這實在是一個巨大深奧的計算機科學主題,這一講會專注在理解 SQL 這個語言的 AST 表達上。
我們來看一個很簡單的例子:
```
SELECT?name?FROM?table;
```
還是在我們剛才表中選取 name 這一列。

如果用語法樹表達的話會是下面圖中的樣子,這個樹的根是 SELECT 節點,在下面左子樹是 name,右子樹是 FROM 節點為根的子樹。FROM 節點下面是 table 葉子節點。
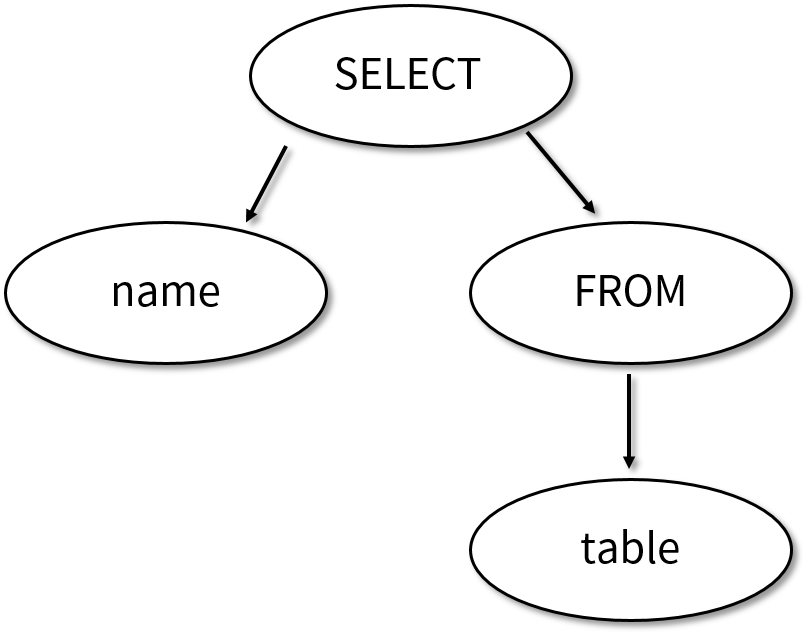
在用 AST 表達 SQL 語句時,SQL 操作符永遠是子樹的根,而樹的葉子則是比如這里的 name 或者 table。
用 AST 解析 SQL 語句之后,我們對于 SQL 語句的分析和優化就變得更為直接了。你可以很快找出這個 SQL 語句的操作就是 SELECT 和 FROM,他們都是子樹的根節點。每一個 SQL 語句中的 token 在語法書中都擁有了語義上的含義,比如 from 和 name 不僅僅是單詞不一樣,他們在語義上是不同的含義,from 是操作,而 name 是一張表中的列名稱。
我們可以根據解析后的語法樹對這棵樹做進一步的修改,比如在 FROM 下面的子節點我們知道是一個表的名字,可以把表的完整路徑解析出來;再比如我們知道 SELECT 下面的左子樹是一個表的列名稱,可以把完整的表名稱解析出來。在做完這些名字的解析之后,這個 SQL 語法樹就變成了如下圖所示的樣子。
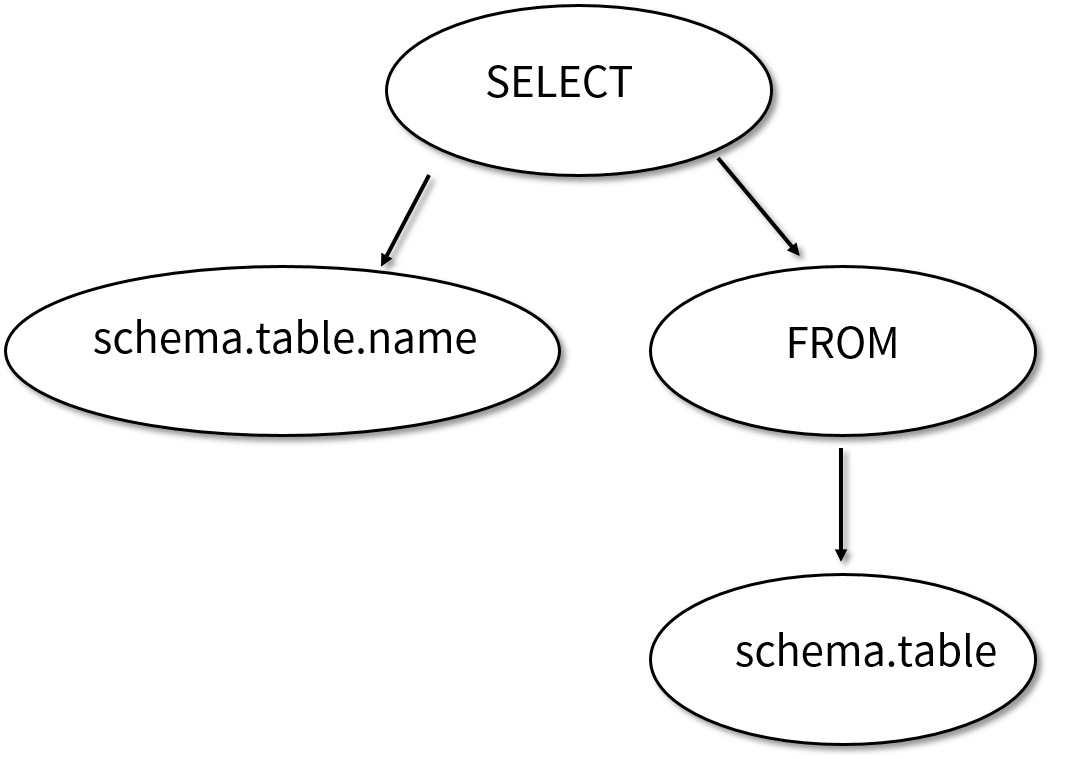
我們可以看到,原來的 name 節點變成了 schema.table.name,而原來的 table 節點變成了 schema.table,這些名稱的解析只需要通過操作樹的節點就可以了,是不是很方便啊!
#### 樹的序列化和 S-expression
我們已經知道了在大型分布式樹的數據庫中,SQL 的語法樹解析是整個 SQL 引擎的第一步。那么在后續的優化器和執行器中我們是怎樣傳遞這棵樹的呢?要知道,在 Amazon 分布式數據庫中,眾多系統不僅僅是幾個簡單的函數而已,往往是好幾個不同的服務器組合而成,在不同的服務器 RPC 之間傳遞樹,我們需要把樹序列化成可以在網絡中傳輸解析的格式。
這就是 S-expression 了,S-expression 有時候也簡稱為 sexp,最初是由 Lisp 語言發明并被人們廣泛使用。現在的 S-expression 已經有很多變種,常見的 S-expression 被定義為:
* 一個不可分的元素(atom)
* 或者是 “(x y)”,左括號,x,y,右括號的形式,其中 x 和 y 都是 S-expression
其實從這個定義來看的話,也和我們樹的定義非常像,都是遞歸式定義。我們來看看剛才 SQL 語法樹用 S-expression 怎樣表示?還記得我們 SQL 語法樹的根是一個 SELECT 節點嘛,下面還有一個以 FROM 為根節點的子樹。你也許想到了我們可能需要一個嵌套的 S-expression,的確如此,正是像下面這樣:
```
(SELECT?schema.table.name?(FROM?schema.table))
```
?我們需要有一個嵌套的括號,在這里,括號的第一個 token 被定義成這個括號表達的子樹的根,每一個嵌套的括號就是一個子樹。
S-expression 的反序列化也很簡單,只需要把每一個括號展開成一個子樹就可以了!這樣你就可以在系統中的不同服務之間用 RPC 傳遞這樣的 S-expression。把一些中間計算的樹傳遞給之后的系統服務。
#### 總結
這一講我們學習了樹在 Amazon 這樣的超大型分布式數據庫系統中是如何應用的。首先了解了為什么超大型分布式數據庫需要對 SQL 引擎進行優化;然后分析了怎么解析 SQL 語法樹,怎樣用樹表達一個 SQL 語句,為什么樹的表達能給我們處理 SQL 語句帶來便利;最后學習了 S-expression 怎樣序列化表達通用的樹。
- 前言
- 開篇
- 開篇詞:從此不再“面試造火箭、工作擰螺絲”
- 模塊一:數組與鏈表的應用
- 第 01 講:數組內存模型
- 第 02 講:位圖數組在 Redis 中的應用
- 第 03 講:鏈表基礎原理
- 第 04 講:鏈表在 Apache Kafka 中的應用
- 模塊二:哈希表的應用
- 第 05 講:哈希函數的本質及生成方式
- 第 06 講:哈希函數在 GitHub 和比特幣中的應用
- 第 07 講:哈希碰撞的本質及解決方式
- 第 08 講:哈希表在 Facebook 和 Pinterest 中的應用
- 模塊三:樹的應用
- 第 09 講:樹的基本原理
- 第 10 講:樹在 Amazon 中的應用
- 第 11 講:平衡樹的性能優化
- 第 12 講:LSM 樹在 Apache HBase 等存儲系統中的應用
- 模塊四:圖的應用
- 第 13 講:用圖來表達更為復雜的數據關系
- 第 14 講:有向無環圖在 Spark 中的應用
- 第 15 講:圖的實現方式與核心算法
- 第 16 講:圖在 Uber 拼車業務中的應用
- 模塊五:數據結構組合拳
- 第 17 講:緩存數據結構在 Nginx 中的應用
- 第 18講:高并發數據結構在 Instagram 與 Twitter 中的應用