
從本講開始將進入數據結構的全新篇章:哈希表。若要構建出哈希表這種數據結構的話,會涉及到兩個重要的算法,分別是哈希函數和解決哈希碰撞的算法。在接下來的第 05 和 06 講中,我們會先一起研究哈希函數的本質以及它的應用;在第 07 和 08 講中,將會探討當遇到哈希碰撞時應該如何解決,以及哈希表在實戰中的應用。
#### 哈希表與哈希函數
說到哈希表,其實本質上是一個數組。通過前面的學習我們知道了,如果要訪問一個數組中某個特定的元素,那么需要知道這個元素的索引。例如,我們可以用數組來記錄自己好友的電話號碼,索引 0 指向的元素記錄著 A 的電話號碼,索引 1 指向的元素記錄著 B 的電話號碼,以此類推。
而當這個數組非常大的時候,全憑記憶去記住哪個索引記錄著哪個好友的號碼是非常困難的。這時候如果有一個函數,可以將我們好友的姓名作為一個輸入,然后輸出這個好友的號碼在數組中對應的索引,是不是就方便了很多呢?這樣的一種函數,其實就是哈希函數。哈希函數的定義是將任意長度的一個對象映射到一個固定長度的值上,而這個值我們可以稱作是哈希值(Hash Value)。
哈希函數一般會有以下三個特性:
* 任何對象作為哈希函數的輸入都可以得到一個相應的哈希值;
* 兩個相同的對象作為哈希函數的輸入,它們總會得到一樣的哈希值;
* 兩個不同的對象作為哈希函數的輸入,它們不一定會得到不同的哈希值。
對于哈希函數的前兩個特性,比較好理解,但是對于第三種特性,我們應該如何解讀呢?那下面就通過一個例子來說明。
我們按照 Java String 類里的哈希函數公式(即下面的公式)來計算出不同字符串的哈希值。String 類里的哈希函數是通過 hashCode 函數來實現的,這里假設哈希函數的字符串輸入為 s,所有的字符串都會通過以下公式來生成一個哈希值:
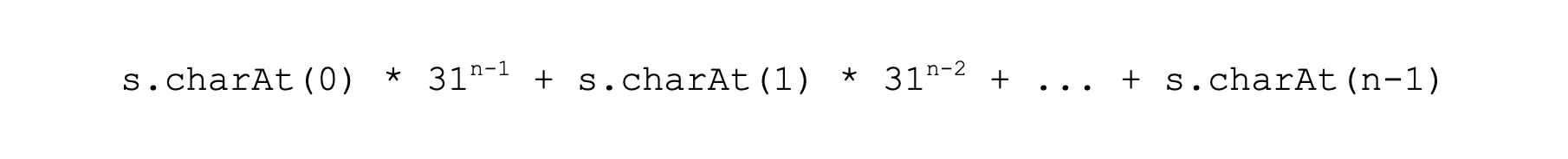
> 這里為什么是“31”?下面會講到哦~
注意:下面所有字符的數值都是按照 ASCII 表獲得的,具體的數值可以在這里查閱。
如果我們輸入“ABC”這個字符串,那根據上面的哈希函數公式,它的哈希值則為
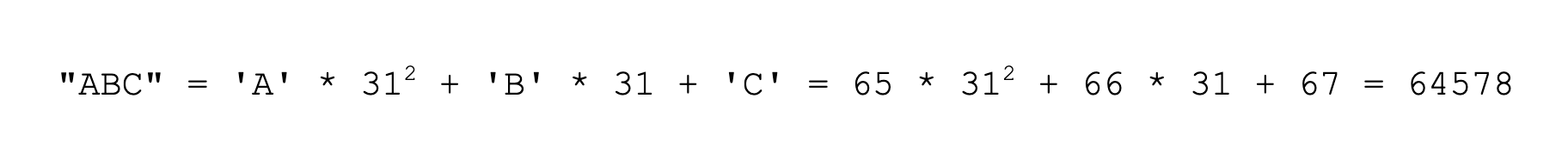
在什么樣的情況下會體現出哈希函數的第三種特性呢?我們再來看看下面這個例子。現在我們想要計算字符串 "Aa" 和 "BB" 的哈希值,還是繼續套用上面的的公式。
"Aa" 的哈希值為
```
"Aa"?=?'A'?*?31?+?'a'?=?65?*?31?+?97?=?2112
```
"BB" 的哈希值為:
```
"BB"?=?'B'?*?31?+?'B'?=?66?*?31?+?66?=?2112
```
可以看到,不同的兩個字符串其實是會輸出相同的哈希值出來的,這時候就會造成哈希碰撞,具體的解決方法將會在第 07 講中詳細討論。
需要注意的是,雖然 hashCode 的算法里都是加法,但是算出來的哈希值有可能會是一個負數。
我們都知道,在計算機里,一個 32 位 int 類型的整數里最高位如果是 0 則表示這個數是非負數,如果是 1 則表示是負數。
如果當字符串通過計算算出的哈希值大于 232-1?時,也就是大于 32 位整數所能表達的最大正整數了,則會造成溢出,此時哈希值就變為負數了。感興趣的小伙伴可以按照上面的公式,自行計算一下“19999999999999999”這個字符串的哈希值會是多少。
* [ ] hashCode 函數中的“魔數”(Magic Number)
細心的你一定發現了,上面所講到的 Java String 類里的 hashCode 函數,一直在使用一個 31 這樣的正整數來進行計算,這是為什么呢?下面一起來研究一下 Java Openjdk-jdk11 中 String.java 的源碼(源碼鏈接),看看這么做有什么好處。
```
public?int?hashCode()?{
????int?h?=?hash;
????if?(h?==?0?&&?value.length?>?0)?{
????????hash?=?h?=?isLatin1()???StringLatin1.hashCode(value)
??????????????????????????????:?StringUTF16.hashCode(value);
????}
????return
```
可以看到,String 類的 hashCode 函數依賴于 StringLatin1 和 StringUTF16 類的具體實現。而 StringLatin1 類中的 hashCode 函數(源碼鏈接)和 StringUTF16 類中的 hashCode 函數(源碼鏈接)所表達的算法其實是一致的。
StringLatin1 類中的 hashCode 函數如下面所示:
```
public?static?int?hashCode(byte[]?value)?{
????int?h?=?0;
????for?(byte?v?:?value)?{
????????h?=?31?*?h?+?(v?&?0xff);
????}
????return?h
```
StringUTF16 類中的 hashCode 函數如下面所示:
```
public?static?int?hashCode(byte[]?value)?{
????int?h?=?0;
????int?length?=?value.length?>>?1;
????for?(int?i?=?0;?i?<?length;?i++)?{
????????h?=?31?*?h?+?getChar(value,?i);
????}
????return?h
```
一個好的哈希函數算法都希望盡可能地減少生成出來的哈希值會造成哈希碰撞的情況。
Goodrich 和 Tamassia 這兩位計算機科學家曾經做過一個實驗,他們對超過 50000 個英文單詞進行了哈希值運算,并使用常數 31、33、37、39 和 41 作為乘數因子,每個常數所算出的哈希值碰撞的次數都小于 7 個。但是最終選擇 31 還是有著另外幾個原因。
從數學的角度來說,選擇一個質數(Prime Number)作為乘數因子可以讓哈希碰撞減少。其次,我們可以看到在上面的兩個 hashCode 源碼中,都有著一條 31 * h 的語句,這條語句在 JVM 中其實都可以被自動優化成“(h << 5) - h”這樣一條位運算加上一個減法指令,而不必執行乘法指令了,這樣可以大大提高運算哈希函數的效率。
所以最終 31 這個乘數因子就被一直保留下來了。
* [ ] 區塊鏈挖礦的本質
通過上面的學習,相信你已經對哈希函數有了一個比較好的了解了。可能也發現了,哈希函數從輸入到輸出,我們可以按照函數的公式算法,很快地計算出哈希值。但是如果告訴你一個哈希值,即便給出了哈希函數的公式也很難算得出原來的輸入到底是什么。例如,還是按照上面 String 類的 hashCode 函數的計算公式:
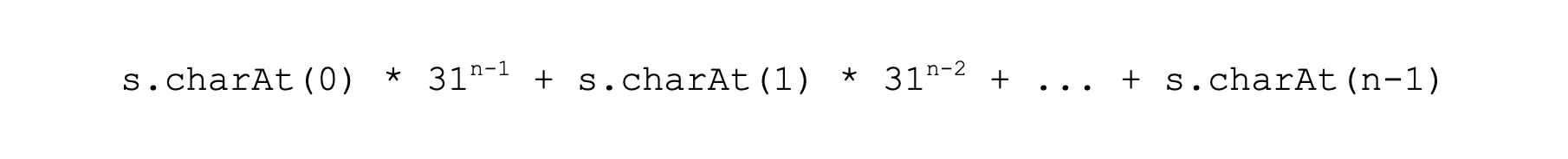
如果告訴了你哈希值是 123456789 這個值,那輸入的字符串是什么呢?我們想要知道答案的話,只能采用暴力破解法,也就是一個一個的字符串去嘗試,直到嘗試出這個哈希值為止。
對于區塊鏈挖礦來說,這個“礦”其實就是一個字符串。“礦工”,也就是進行運算的計算機,必須在規定的時間內找到一個字符串,使得在進行了哈希函數運算之后得到一個滿足要求的值。
我們以比特幣為例,它采用了 SHA256 的哈希函數來進行運算,無論輸入的是什么,SHA256 哈希函數的哈希值永遠都會是一個 256 位的值。而比特幣的獎勵機制簡單來說是通過每 10 分鐘放出一個哈希值,讓“礦工們”利用 SHA256(SHA256(x)) 這樣兩次的哈希運算,來找出滿足一定規則的字符串出來。
比方說,比特幣會要求找出通過上面 SHA256(SHA256(x)) 計算之后的哈希值,這個 256 位的哈希值中的前 50 位都必須為 0 ,誰先找到滿足這個要求的輸入值 x,就等于“挖礦”成功,給予獎勵一個比特幣。我們知道,即便知道了哈希值,也很難算出這個 x 是什么,所以只能一個一個地去嘗試。而市面上所說的挖礦機,其原理是希望能提高運算的速度,讓“礦工”盡快地找到這個 x 出來。
- 前言
- 開篇
- 開篇詞:從此不再“面試造火箭、工作擰螺絲”
- 模塊一:數組與鏈表的應用
- 第 01 講:數組內存模型
- 第 02 講:位圖數組在 Redis 中的應用
- 第 03 講:鏈表基礎原理
- 第 04 講:鏈表在 Apache Kafka 中的應用
- 模塊二:哈希表的應用
- 第 05 講:哈希函數的本質及生成方式
- 第 06 講:哈希函數在 GitHub 和比特幣中的應用
- 第 07 講:哈希碰撞的本質及解決方式
- 第 08 講:哈希表在 Facebook 和 Pinterest 中的應用
- 模塊三:樹的應用
- 第 09 講:樹的基本原理
- 第 10 講:樹在 Amazon 中的應用
- 第 11 講:平衡樹的性能優化
- 第 12 講:LSM 樹在 Apache HBase 等存儲系統中的應用
- 模塊四:圖的應用
- 第 13 講:用圖來表達更為復雜的數據關系
- 第 14 講:有向無環圖在 Spark 中的應用
- 第 15 講:圖的實現方式與核心算法
- 第 16 講:圖在 Uber 拼車業務中的應用
- 模塊五:數據結構組合拳
- 第 17 講:緩存數據結構在 Nginx 中的應用
- 第 18講:高并發數據結構在 Instagram 與 Twitter 中的應用