
# 1 -- The Learning Problem
最近在看NTU林軒田的《機器學習基石》課程,個人感覺講的非常好。整個基石課程分成四個部分:
* When Can Machine Learn?
* Why Can Machine Learn?
* How Can Machine Learn?
* How Can Machine Learn Better?
每個部分由四節課組成,總共有16節課。那么,從這篇開始,我們將連續對這門課做課程筆記,共16篇,希望能對正在看這們課的童鞋有所幫助。下面開始第一節課的筆記:The Learning Problem。
### **一、What is Machine Learning**
什么是“學習”?學習就是人類通過觀察、積累經驗,掌握某項技能或能力。就好像我們從小學習識別字母、認識漢字,就是學習的過程。而機器學習(Machine Learning),顧名思義,就是讓機器(計算機)也能向人類一樣,通過觀察大量的數據和訓練,發現事物規律,獲得某種分析問題、解決問題的能力。
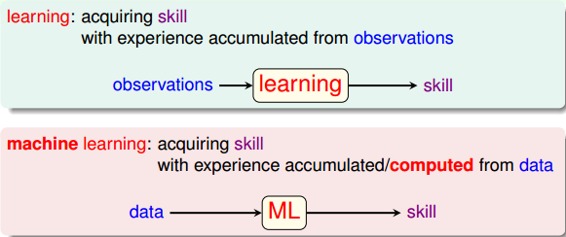
機器學習可以被定義為:Improving some performance measure with experence computed from data. 也就是機器從數據中總結經驗,從數據中找出某種規律或者模型,并用它來解決實際問題。
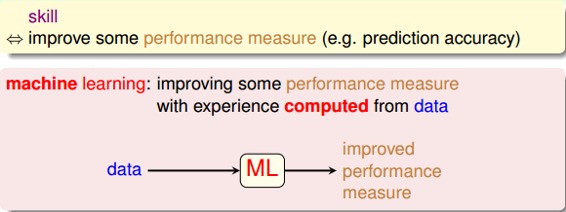
什么情況下會使用機器學習來解決問題呢?其實,目前機器學習的應用非常廣泛,基本上任何場合都能夠看到它的身影。其應用場合大致可歸納為三個條件:
* 事物本身存在某種潛在規律
* 某些問題難以使用普通編程解決
* 有大量的數據樣本可供使用

### **二、Applications of Machine Learning**
機器學習在我們的衣、食、住、行、教育、娛樂等各個方面都有著廣泛的應用,我們的生活處處都離不開機器學習。比如,打開購物網站,網站就會給我們自動推薦我們可能會喜歡的商品;電影頻道會根據用戶的瀏覽記錄和觀影記錄,向不同用戶推薦他們可能喜歡的電影等等,到處都有機器學習的影子。
### **三、Components of Machine Learning**
本系列的課程對機器學習問題有一些基本的術語需要注意一下:
* 輸入x
* 輸出y
* 目標函數f,即最接近實際樣本分布的規律
* 訓練樣本data
* 假設hypothesis,一個機器學習模型對應了很多不同的hypothesis,通過演算法A,選擇一個最佳的hypothesis對應的函數稱為矩g,g能最好地表示事物的內在規律,也是我們最終想要得到的模型表達式。

實際中,機器學習的流程圖可以表示為:
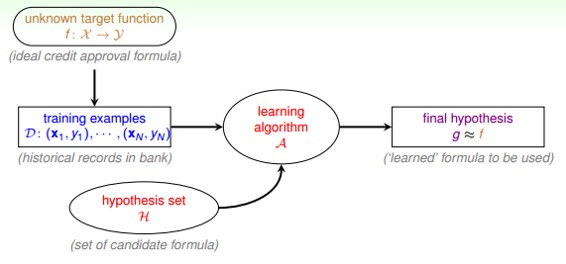
對于理想的目標函數f,我們是不知道的,我們手上拿到的是一些訓練樣本D,假設是監督式學習,其中有輸入x,也有輸出y。機器學習的過程,就是根據先驗知識選擇模型,該模型對應的hypothesis set(用H表示),H中包含了許多不同的hypothesis,通過演算法A,在訓練樣本D上進行訓練,選擇出一個最好的hypothes,對應的函數表達式g就是我們最終要求的。一般情況下,g能最接近目標函數f,這樣,機器學習的整個流程就完成了。
### **四、Machine Learning and Other Fields**
與機器學習相關的領域有:
* 數據挖掘(Data Mining)
* 人工智能(Artificial Intelligence)
* 統計(Statistics)
其實,機器學習與這三個領域是相通的,基本類似,但也不完全一樣。機器學習是這三個領域中的有力工具,而同時,這三個領域也是機器學習可以廣泛應用的領域,總得來說,他們之間沒有十分明確的界線。
### **五、總結**
本節課主要介紹了什么是機器學習,什么樣的場合下可以使用機器學習解決問題,然后用流程圖的形式展示了機器學習的整個過程,最后把機器學習和數據挖掘、人工智能、統計這三個領域做個比較。本節課的內容主要是概述性的東西,比較簡單,所以筆記也相對比較簡略。
這里附上林軒田(Hsuan-Tien Lin)關于這門課的主頁:
[http://www.csie.ntu.edu.tw/~htlin/](http://www.csie.ntu.edu.tw/~htlin/)
**_注明:_**
文章中所有的圖片均來自臺灣大學林軒田《機器學習基石》課程。
- 臺灣大學林軒田機器學習筆記
- 機器學習基石
- 1 -- The Learning Problem
- 2 -- Learning to Answer Yes/No
- 3 -- Types of Learning
- 4 -- Feasibility of Learning
- 5 -- Training versus Testing
- 6 -- Theory of Generalization
- 7 -- The VC Dimension
- 8 -- Noise and Error
- 9 -- Linear Regression
- 10 -- Logistic Regression
- 11 -- Linear Models for Classification
- 12 -- Nonlinear Transformation
- 13 -- Hazard of Overfitting
- 14 -- Regularization
- 15 -- Validation
- 16 -- Three Learning Principles
- 機器學習技法
- 1 -- Linear Support Vector Machine
- 2 -- Dual Support Vector Machine
- 3 -- Kernel Support Vector Machine
- 4 -- Soft-Margin Support Vector Machine
- 5 -- Kernel Logistic Regression
- 6 -- Support Vector Regression
- 7 -- Blending and Bagging
- 8 -- Adaptive Boosting
- 9 -- Decision Tree
- 10 -- Random Forest
- 11 -- Gradient Boosted Decision Tree
- 12 -- Neural Network
- 13 -- Deep Learning
- 14 -- Radial Basis Function Network
- 15 -- Matrix Factorization
- 16(完結) -- Finale