
# 10 -- Random Forest
上節課我們主要介紹了Decision Tree模型。Decision Tree算法的核心是通過遞歸的方式,將數據集不斷進行切割,得到子分支,最終形成數的結構。C&RT算法是決策樹比較簡單和常用的一種算法,其切割的標準是根據純度來進行,每次切割都是為了讓分支內部純度最大。最終,決策樹不同的分支得到不同的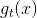(即樹的葉子,C&RT算法中,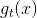是常數)。本節課將介紹隨機森林(Random Forest)算法,它是我們之前介紹的Bagging和上節課介紹的Decision Tree的結合。
### **Random Forest Algorithm**
首先我們來復習一下之前介紹過的兩個機器學習模型:Bagging和Decision Tree。Bagging是通過bootstrap的方式,從原始的數據集D中得到新的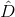;然后再使用一些base algorithm對每個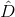都得到相應的;最后將所有的通過投票uniform的形式組合成一個G,G即為我們最終得到的模型。Decision Tree是通過遞歸形式,利用分支條件,將原始數據集D切割成一個個子樹結構,長成一棵完整的樹形結構。Decision Tree最終得到的G(x)是由相應的分支條件b(x)和分支樹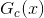遞歸組成。

Bagging和Decison Tree算法各自有一個很重要的特點。Bagging具有減少不同的方差variance的特點。這是因為Bagging采用投票的形式,將所有uniform結合起來,起到了求平均的作用,從而降低variance。而Decision Tree具有增大不同的方差variance的特點。這是因為Decision Tree每次切割的方式不同,而且分支包含的樣本數在逐漸減少,所以它對不同的資料D會比較敏感一些,從而不同的D會得到比較大的variance。
所以說,Bagging能減小variance,而Decision Tree能增大variance。如果把兩者結合起來,能否發揮各自的優勢,起到優勢互補的作用呢?這就是我們接下來將要討論的aggregation of aggregation,即使用Bagging的方式把眾多的Decision Tree進行uniform結合起來。這種算法就叫做隨機森林(Random Forest),它將完全長成的C&RT決策樹通過bagging的形式結合起來,最終得到一個龐大的決策模型。

Random Forest算法流程圖如下所示:

Random Forest算法的優點主要有三個。第一,不同決策樹可以由不同主機并行訓練生成,效率很高;第二,隨機森林算法繼承了C&RT的優點;第三,將所有的決策樹通過bagging的形式結合起來,避免了單個決策樹造成過擬合的問題。

以上是基本的Random Forest算法,我們再來看一下如何讓Random Forest中決策樹的結構更有多樣性。Bagging中,通過bootstrap的方法得到不同于D的D’,使用這些隨機抽取的資料得到不同的。除了隨機抽取資料獲得不同的方式之外,還有另外一種方法,就是隨機抽取一部分特征。例如,原來有100個特征,現在只從中隨機選取30個來構成決策樹,那么每一輪得到的樹都由不同的30個特征構成,每棵樹都不一樣。假設原來樣本維度是d,則只選擇其中的d’(d’小于d)個維度來建立決策樹結構。這類似是一種從d維到d’維的特征轉換,相當于是從高維到低維的投影,也就是說d’維z空間其實就是d維x空間的一個隨機子空間(subspace)。通常情況下,d’遠小于d,從而保證算法更有效率。Random Forest算法的作者建議在構建C&RT每個分支b(x)的時候,都可以重新選擇子特征來訓練,從而得到更具有多樣性的決策樹。

所以說,這種增強的Random Forest算法增加了random-subspace。

上面我們講的是隨機抽取特征,除此之外,還可以將現有的特征x,通過數組p進行線性組合,來保持多樣性:
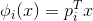
這種方法使每次分支得到的不再是單一的子特征集合,而是子特征的線性組合(權重不為1)。好比在二維平面上不止得到水平線和垂直線,也能得到各種斜線。這種做法使子特征選擇更加多樣性。值得注意的是,不同分支i下的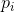是不同的,而且向量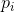中大部分元素為零,因為我們選擇的只是一部分特征,這是一種低維映射。

所以,這里的Random Forest算法又有增強,由原來的random-subspace變成了random-combination。順便提一下,這里的random-combination類似于perceptron模型。

### **Out-Of-Bag Estimate**
上一部分我們已經介紹了Random Forest算法,而Random Forest算法重要的一點就是Bagging。接下來將繼續探討bagging中的bootstrap機制到底蘊含了哪些可以為我們所用的東西。
通過bootstrap得到新的樣本集D’,再由D’訓練不同的。我們知道D’中包含了原樣本集D中的一些樣本,但也有些樣本沒有涵蓋進去。如下表所示,不同的下,紅色的_表示在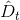中沒有這些樣本。例如對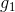來說,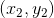和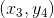沒有包含進去,對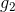來說,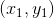和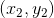沒有包含進去,等等。每個中,紅色_表示的樣本被稱為out-of-bag(OOB) example。
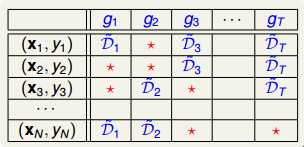
首先,我們來計算OOB樣本到底有多少。假設bootstrap的數量N’=N,那么某個樣本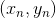是OOB的概率是:
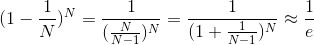
其中,e是自然對數,N是原樣本集的數量。由上述推導可得,每個中,OOB數目大約是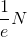,即大約有三分之一的樣本沒有在bootstrap中被抽到。
然后,我們將OOB與之前介紹的Validation進行對比:
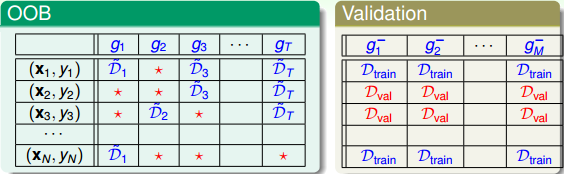
在Validation表格中,藍色的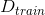用來得到不同的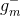,而紅色的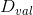用來驗證各自的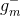。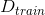與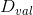沒有交集,一般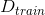是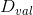的數倍關系。再看左邊的OOB表格,之前我們也介紹過,藍色的部分用來得到不同的,而紅色的部分是OOB樣本。而我們剛剛也推導過,紅色部分大約占N的。通過兩個表格的比較,我們發現OOB樣本類似于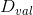,那么是否能使用OOB樣本來驗證的好壞呢?答案是肯定的。但是,通常我們并不需要對單個進行驗證。因為我們更關心的是由許多組合成的G,即使表現不太好,只要G表現足夠好就行了。那么問題就轉化成了如何使用OOB來驗證G的好壞。方法是先看每一個樣本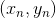是哪些的OOB資料,然后計算其在這些上的表現,最后將所有樣本的表現求平均即可。例如,樣本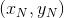是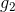,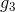,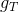的OOB,則可以計算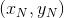在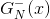上的表現為:
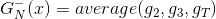
這種做法我們并不陌生,就像是我們之前介紹過的Leave-One-Out Cross Validation,每次只對一個樣本進行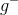的驗證一樣,只不過這里選擇的是每個樣本是哪些的OOB,然后再分別進行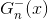的驗證。每個樣本都當成驗證資料一次(與留一法相同),最后計算所有樣本的平均表現:
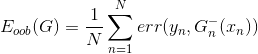
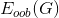估算的就是G的表現好壞。我們把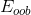稱為bagging或者Random Forest的self-validation。
這種self-validation相比于validation來說還有一個優點就是它不需要重復訓練。如下圖左邊所示,在通過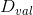選擇到表現最好的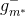之后,還需要在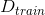和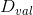組成的所有樣本集D上重新對該模型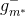訓練一次,以得到最終的模型系數。但是self-validation在調整隨機森林算法相關系數并得到最小的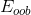之后,就完成了整個模型的建立,無需重新訓練模型。隨機森林算法中,self-validation在衡量G的表現上通常相當準確。

### **Feature Selection**
如果樣本資料特征過多,假如有10000個特征,而我們只想從中選取300個特征,這時候就需要舍棄部分特征。通常來說,需要移除的特征分為兩類:一類是冗余特征,即特征出現重復,例如“年齡”和“生日”;另一類是不相關特征,例如疾病預測的時候引入的“保險狀況”。這種從d維特征到d’維特征的subset-transform 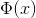稱為Feature Selection,最終使用這些d’維的特征進行模型訓練。

特征選擇的優點是:
* **提高效率,特征越少,模型越簡單**
* **正則化,防止特征過多出現過擬合**
* **去除無關特征,保留相關性大的特征,解釋性強**
同時,特征選擇的缺點是:
* **篩選特征的計算量較大**
* **不同特征組合,也容易發生過擬合**
* **容易選到無關特征,解釋性差**

值得一提的是,在decision tree中,我們使用的decision stump切割方式也是一種feature selection。
那么,如何對許多維特征進行篩選呢?我們可以通過計算出每個特征的重要性(即權重),然后再根據重要性的排序進行選擇即可。

這種方法在線性模型中比較容易計算。因為線性模型的score是由每個特征經過加權求和而得到的,而加權系數的絕對值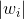正好代表了對應特征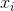的重要性為多少。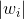越大,表示對應特征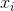越重要,則該特征應該被選擇。w的值可以通過對已有的數據集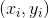建立線性模型而得到。

然而,對于非線性模型來說,因為不同特征可能是非線性交叉在一起的,所以計算每個特征的重要性就變得比較復雜和困難。例如,Random Forest就是一個非線性模型,接下來,我們將討論如何在RF下進行特征選擇。
RF中,特征選擇的核心思想是random test。random test的做法是對于某個特征,如果用另外一個隨機值替代它之后的表現比之前更差,則表明該特征比較重要,所占的權重應該較大,不能用一個隨機值替代。相反,如果隨機值替代后的表現沒有太大差別,則表明該特征不那么重要,可有可無。所以,通過比較某特征被隨機值替代前后的表現,就能推斷出該特征的權重和重要性。
那么random test中的隨機值如何選擇呢?通常有兩種方法:一是使用uniform或者gaussian抽取隨機值替換原特征;一是通過permutation的方式將原來的所有N個樣本的第i個特征值重新打亂分布(相當于重新洗牌)。比較而言,第二種方法更加科學,保證了特征替代值與原特征的分布是近似的(只是重新洗牌而已)。這種方法叫做permutation test(隨機排序測試),即在計算第i個特征的重要性的時候,將N個樣本的第i個特征重新洗牌,然后比較D和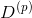表現的差異性。如果差異很大,則表明第i個特征是重要的。

知道了permutation test的原理后,接下來要考慮的問題是如何衡量上圖中的performance,即替換前后的表現。顯然,我們前面介紹過performance可以用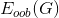來衡量。但是,對于N個樣本的第i個特征值重新洗牌重置的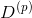,要對它進行重新訓練,而且每個特征都要重復訓練,然后再與原D的表現進行比較,過程非常繁瑣。為了簡化運算,RF的作者提出了一種方法,就是把permutation的操作從原來的training上移到了OOB validation上去,記為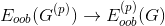。也就是說,在訓練的時候仍然使用D,但是在OOB驗證的時候,將所有的OOB樣本的第i個特征重新洗牌,驗證G的表現。這種做法大大簡化了計算復雜度,在RF的feature selection中應用廣泛。

### **Random Forest in Action**
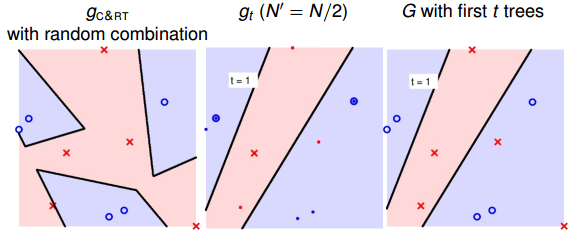
最后,我們通過實際的例子來看一下RF的特點。首先,仍然是一個二元分類的例子。如下圖所示,左邊是一個C&RT樹沒有使用bootstrap得到的模型分類效果,其中不同特征之間進行了隨機組合,所以有斜線作為分類線;中間是由bootstrap(N’=N/2)后生成的一棵決策樹組成的隨機森林,圖中加粗的點表示被bootstrap選中的點;右邊是將一棵決策樹進行bagging后的分類模型,效果與中間圖是一樣的,都是一棵樹。
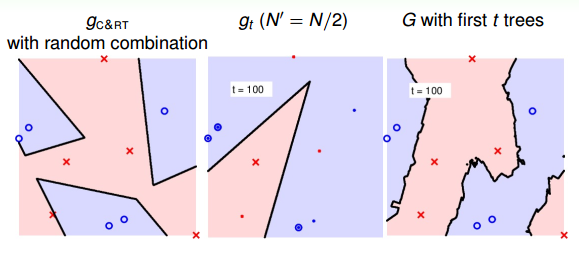
當t=100,即選擇了100棵樹時,中間的模型是第100棵決策樹構成的,還是只有一棵樹;右邊的模型是由100棵決策樹bagging起來的,如下圖所示:
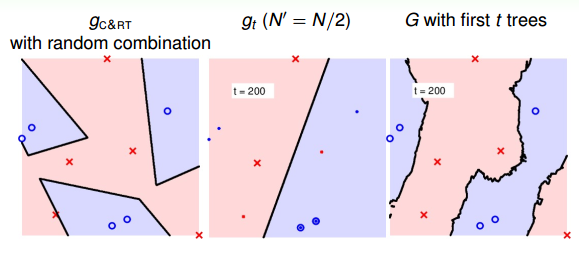
當t=200時:
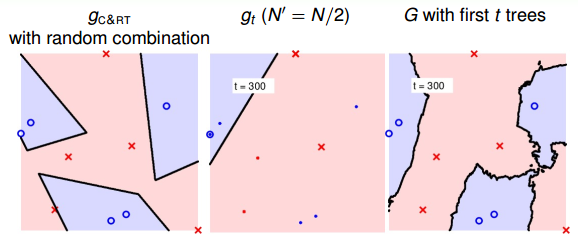
當t=300時:
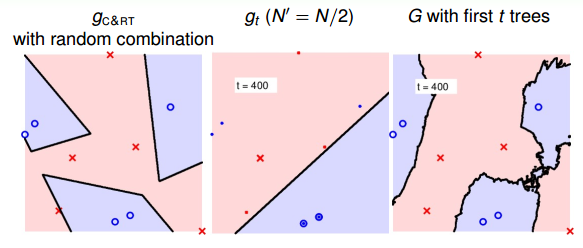
當t=400時:
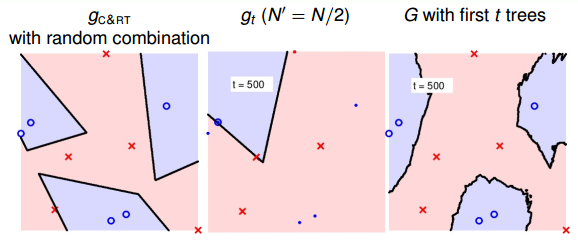
當t=500時:
當t=600時:
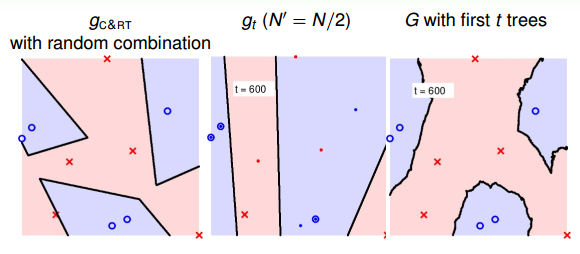
當t=700時:
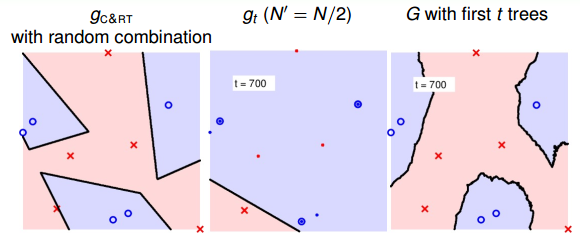
當t=800時:
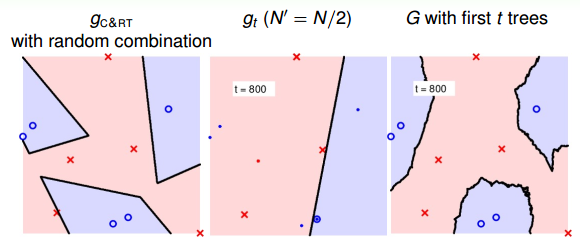
當t=900時:
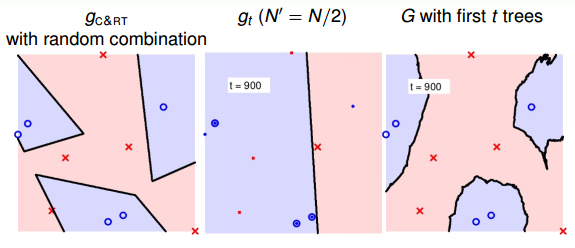
當t=1000時:
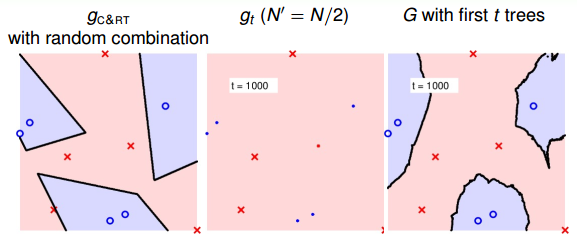
隨著樹木個數的增加,我們發現,分界線越來越光滑而且得到了large-margin-like boundary,類似于SVM一樣的效果。也就是說,樹木越多,分類器的置信區間越大。
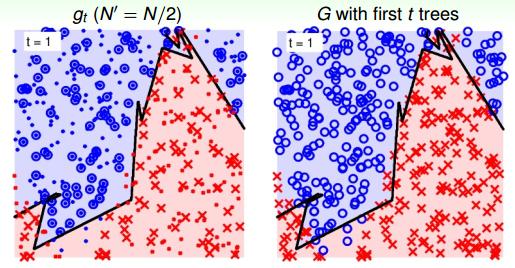
然后,我們再來看一個比較復雜的例子,二維平面上分布著許多離散點,分界線形如sin函數。當只有一棵樹的時候(t=1),下圖左邊表示單一樹組成的RF,右邊表示所有樹bagging組合起來構成的RF。因為只有一棵樹,所以左右兩邊效果一致。
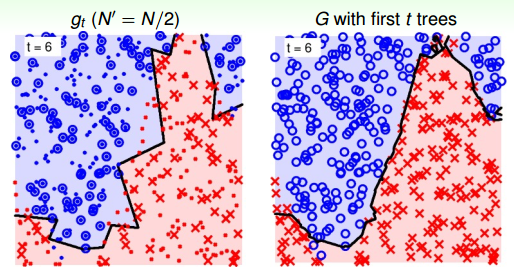
當t=6時:
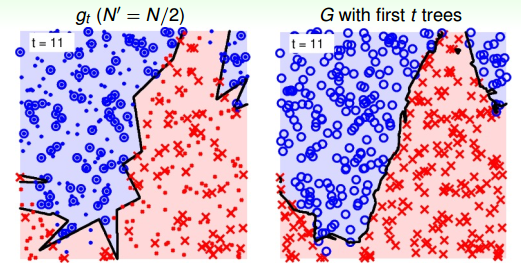
當t=11時:
當t=16時:
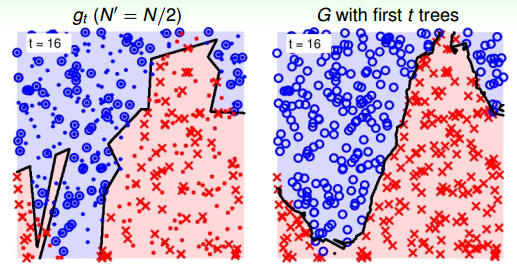
當t=21時:
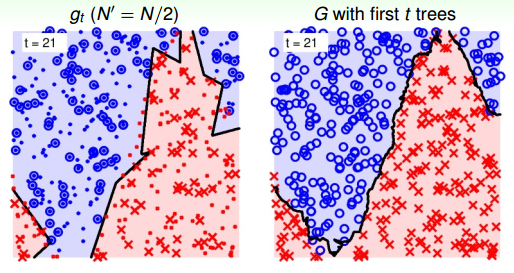
可以看到,當RF由21棵樹構成的時候,分界線就比較平滑了,而且它的邊界比單一樹構成的RF要robust得多,更加平滑和穩定。
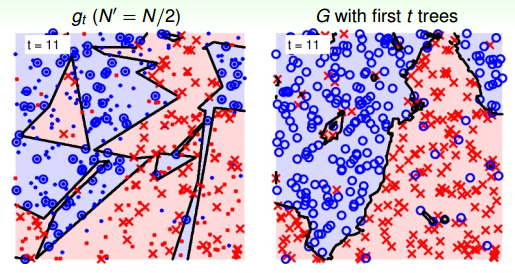
最后,基于上面的例子,再讓問題復雜一點:在平面上添加一些隨機噪聲。當t=1時,如下圖所示:
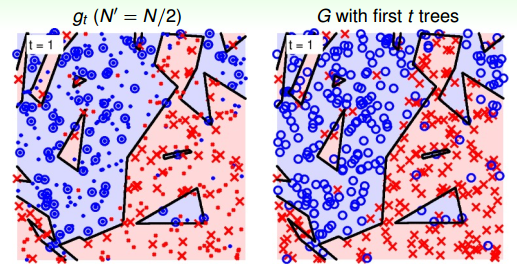
當t=6時:
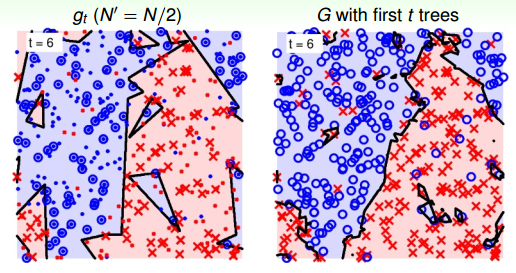
當t=11時:
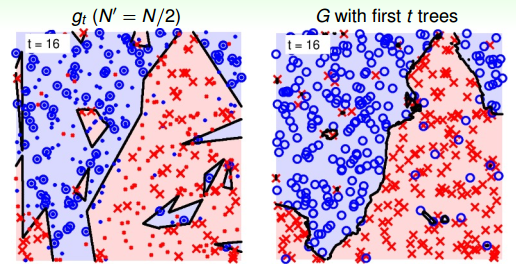
當t=16時:
當t=21時:
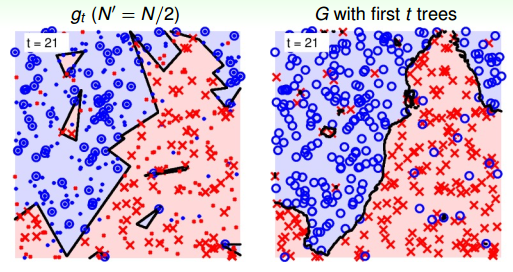
從上圖中,我們發現21棵樹的時候,隨機noise的影響基本上能夠修正和消除。這種bagging投票的機制能夠保證較好的降噪性,從而得到比較穩定的結果。
經過以上三個例子,我們發現RF中,樹的個數越多,模型越穩定越能表現得好。在實際應用中,應該盡可能選擇更多的樹。值得一提的是,RF的表現同時也與random seed有關,即隨機的初始值也會影響RF的表現。

### **總結:**
本節課主要介紹了Random Forest算法模型。RF將bagging與decision tree結合起來,通過把眾多的決策樹組進行組合,構成森林的形式,利用投票機制讓G表現最佳,分類模型更穩定。其中為了讓decision tree的隨機性更強一些,可以采用randomly projected subspaces操作,即將不同的features線性組合起來,從而進行各式各樣的切割。同時,我們也介紹了可以使用OOB樣本來進行self-validation,然后可以使用self-validation來對每個特征進行permutaion test,得到不同特征的重要性,從而進行feature selection。總的來說,RF算法能夠得到比較平滑的邊界,穩定性強,前提是有足夠多的樹。
**_注明:_**
文章中所有的圖片均來自臺灣大學林軒田《機器學習技法》課程
- 臺灣大學林軒田機器學習筆記
- 機器學習基石
- 1 -- The Learning Problem
- 2 -- Learning to Answer Yes/No
- 3 -- Types of Learning
- 4 -- Feasibility of Learning
- 5 -- Training versus Testing
- 6 -- Theory of Generalization
- 7 -- The VC Dimension
- 8 -- Noise and Error
- 9 -- Linear Regression
- 10 -- Logistic Regression
- 11 -- Linear Models for Classification
- 12 -- Nonlinear Transformation
- 13 -- Hazard of Overfitting
- 14 -- Regularization
- 15 -- Validation
- 16 -- Three Learning Principles
- 機器學習技法
- 1 -- Linear Support Vector Machine
- 2 -- Dual Support Vector Machine
- 3 -- Kernel Support Vector Machine
- 4 -- Soft-Margin Support Vector Machine
- 5 -- Kernel Logistic Regression
- 6 -- Support Vector Regression
- 7 -- Blending and Bagging
- 8 -- Adaptive Boosting
- 9 -- Decision Tree
- 10 -- Random Forest
- 11 -- Gradient Boosted Decision Tree
- 12 -- Neural Network
- 13 -- Deep Learning
- 14 -- Radial Basis Function Network
- 15 -- Matrix Factorization
- 16(完結) -- Finale