
# 2 -- Learning to Answer Yes/No
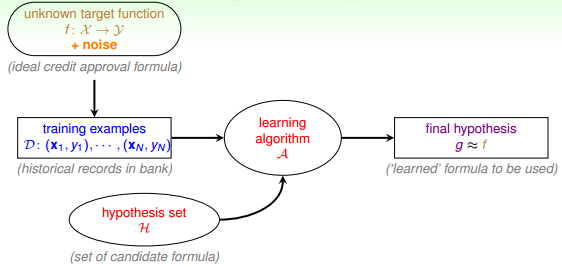
上節課,我們主要簡述了機器學習的定義及其重要性,并用流程圖的形式介紹了機器學習的整個過程:根據模型H,使用演算法A,在訓練樣本D上進行訓練,得到最好的h,其對應的g就是我們最后需要的機器學習的模型函數,一般g接近于目標函數f。本節課將繼續深入探討機器學習問題,介紹感知機Perceptron模型,并推導課程的第一個機器學習算法:Perceptron Learning Algorithm(PLA)。
### **一、Perceptron Hypothesis Set**
引入這樣一個例子:某銀行要根據用戶的年齡、性別、年收入等情況來判斷是否給該用戶發信用卡。現在有訓練樣本D,即之前用戶的信息和是否發了信用卡。這是一個典型的機器學習問題,我們要根據D,通過A,在H中選擇最好的h,得到g,接近目標函數f,也就是根據先驗知識建立是否給用戶發信用卡的模型。銀行用這個模型對以后用戶進行判斷:發信用卡(+1),不發信用卡(-1)。
在這個機器學習的整個流程中,有一個部分非常重要:就是模型選擇,即Hypothesis Set。選擇什么樣的模型,很大程度上會影響機器學習的效果和表現。下面介紹一個簡單常用的Hypothesis Set:感知機(Perceptron)。
還是剛才銀行是否給用戶發信用卡的例子,我們把用戶的個人信息作為特征向量x,令總共有d個特征,每個特征賦予不同的權重w,表示該特征對輸出(是否發信用卡)的影響有多大。那所有特征的加權和的值與一個設定的閾值threshold進行比較:大于這個閾值,輸出為+1,即發信用卡;小于這個閾值,輸出為-1,即不發信用卡。感知機模型,就是當特征加權和與閾值的差大于或等于0,則輸出h(x)=1;當特征加權和與閾值的差小于0,則輸出h(x)=-1,而我們的目的就是計算出所有權值w和閾值threshold。

為了計算方便,通常我們將閾值threshold當做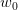,引入一個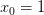的量與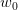相乘,這樣就把threshold也轉變成了權值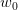,簡化了計算。h(x)的表達式做如下變換:
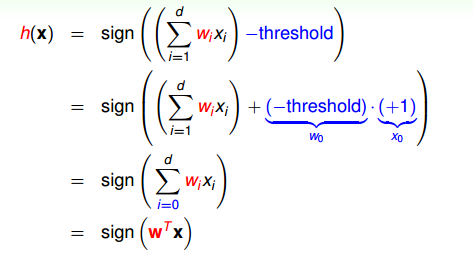
為了更清晰地說明感知機模型,我們假設Perceptrons在二維平面上,即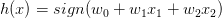。其中,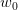是平面上一條分類直線,直線一側是正類(+1),直線另一側是負類(-1)。權重w不同,對應于平面上不同的直線。

那么,我們所說的Perceptron,在這個模型上就是一條直線,稱之為linear(binary) classifiers。注意一下,感知器線性分類不限定在二維空間中,在3D中,線性分類用平面表示,在更高維度中,線性分類用超平面表示,即只要是形如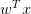的線性模型就都屬于linear(binary) classifiers。
同時,需要注意的是,這里所說的linear(binary) classifiers是用簡單的感知器模型建立的,線性分類問題還可以使用logistic regression來解決,后面將會介紹。
### **二、Perceptron Learning Algorithm(PLA)**
根據上一部分的介紹,我們已經知道了hypothesis set由許多條直線構成。接下來,我們的目的就是如何設計一個演算法A,來選擇一個最好的直線,能將平面上所有的正類和負類完全分開,也就是找到最好的g,使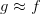。
如何找到這樣一條最好的直線呢?我們可以使用逐點修正的思想,首先在平面上隨意取一條直線,看看哪些點分類錯誤。然后開始對第一個錯誤點就行修正,即變換直線的位置,使這個錯誤點變成分類正確的點。接著,再對第二個、第三個等所有的錯誤分類點就行直線糾正,直到所有的點都完全分類正確了,就得到了最好的直線。這種“逐步修正”,就是PLA思想所在。

下面介紹一下PLA是怎么做的。首先隨機選擇一條直線進行分類。然后找到第一個分類錯誤的點,如果這個點表示正類,被誤分為負類,即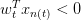,那表示w和x夾角大于90度,其中w是直線的法向量。所以,x被誤分在直線的下側(相對于法向量,法向量的方向即為正類所在的一側),修正的方法就是使w和x夾角小于90度。通常做法是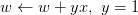,如圖右上角所示,一次或多次更新后的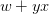與x夾角小于90度,能保證x位于直線的上側,則對誤分為負類的錯誤點完成了直線修正。
同理,如果是誤分為正類的點,即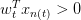,那表示w和x夾角小于90度,其中w是直線的法向量。所以,x被誤分在直線的上側,修正的方法就是使w和x夾角大于90度。通常做法是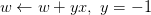,如圖右下角所示,一次或多次更新后的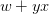與x夾角大于90度,能保證x位于直線的下側,則對誤分為正類的錯誤點也完成了直線修正。
按照這種思想,遇到個錯誤點就進行修正,不斷迭代。要注意一點:每次修正直線,可能使之前分類正確的點變成錯誤點,這是可能發生的。但是沒關系,不斷迭代,不斷修正,最終會將所有點完全正確分類(PLA前提是線性可分的)。這種做法的思想是“知錯能改”,有句話形容它:“A fault confessed is half redressed.”
實際操作中,可以一個點一個點地遍歷,發現分類錯誤的點就進行修正,直到所有點全部分類正確。這種被稱為Cyclic PLA。

下面用圖解的形式來介紹PLA的修正過程:
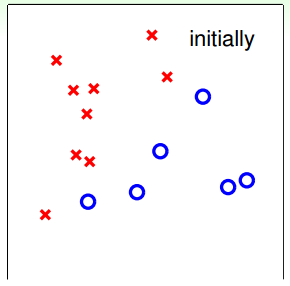
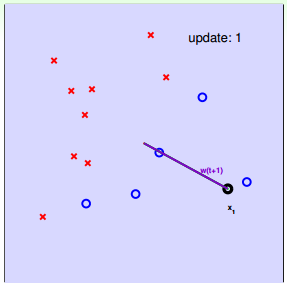
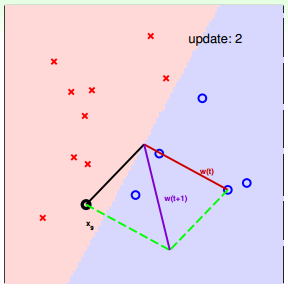
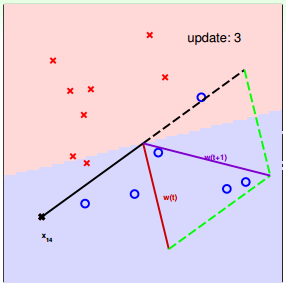
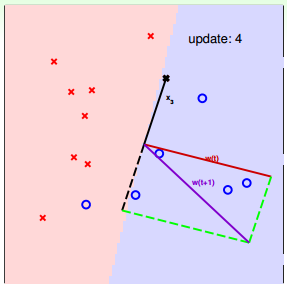
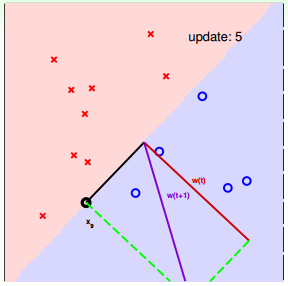
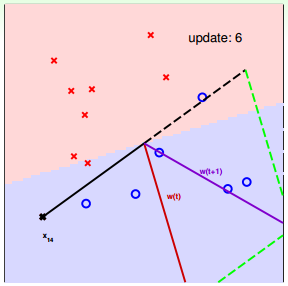
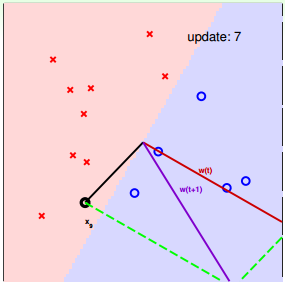
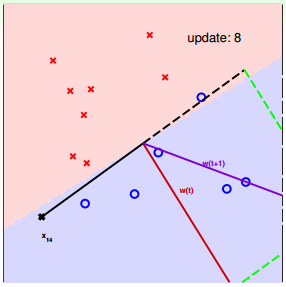
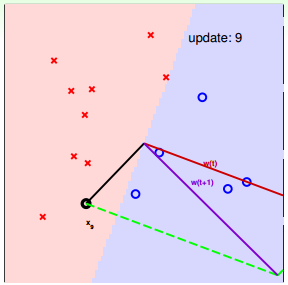
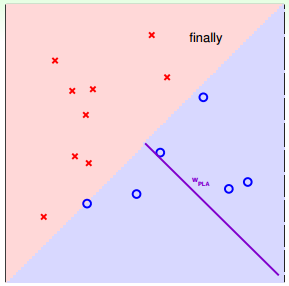
對PLA,我們需要考慮以下兩個問題:
* PLA迭代一定會停下來嗎?如果線性不可分怎么辦?
* PLA停下來的時候,是否能保證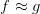?如果沒有停下來,是否有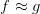?
### **三、Guarantee of PLA**
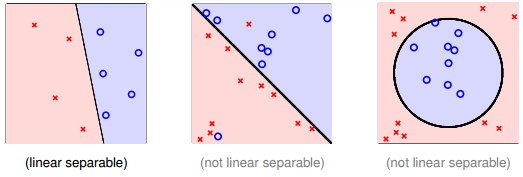
PLA什么時候會停下來呢?根據PLA的定義,當找到一條直線,能將所有平面上的點都分類正確,那么PLA就停止了。要達到這個終止條件,就必須保證D是線性可分(linear separable)。如果是非線性可分的,那么,PLA就不會停止。
對于線性可分的情況,如果有這樣一條直線,能夠將正類和負類完全分開,令這時候的目標權重為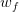,則對每個點,必然滿足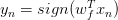,即對任一點:
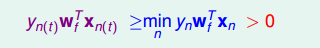
PLA會對每次錯誤的點進行修正,更新權重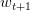的值,如果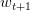與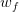越來越接近,數學運算上就是內積越大,那表示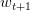是在接近目標權重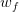,證明PLA是有學習效果的。所以,我們來計算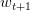與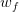的內積:
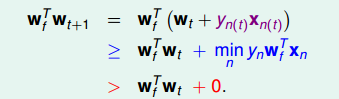
從推導可以看出,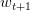與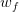的內積跟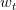與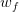的內積相比更大了。似乎說明了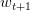更接近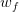,但是內積更大,可能是向量長度更大了,不一定是向量間角度更小。所以,下一步,我們還需要證明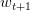與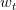向量長度的關系:

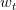只會在分類錯誤的情況下更新,最終得到的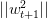相比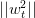的增量值不超過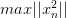。也就是說,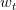的增長被限制了,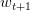與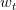向量長度不會差別太大!
如果令初始權值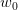,那么經過T次錯誤修正后,有如下結論:
下面貼出來該結論的具體推導過程:


上述不等式左邊其實是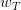與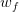夾角的余弦值,隨著T增大,該余弦值越來越接近1,即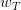與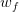越來越接近。同時,需要注意的是,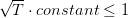,也就是說,迭代次數T是有上界的。根據以上證明,我們最終得到的結論是: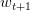與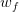的是隨著迭代次數增加,逐漸接近的。而且,PLA最終會停下來(因為T有上界),實現對線性可分的數據集完全分類。
### **四、Non-Separable Data**
上一部分,我們證明了線性可分的情況下,PLA是可以停下來并正確分類的,但對于非線性可分的情況,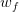實際上并不存在,那么之前的推導并不成立,PLA不一定會停下來。所以,PLA雖然實現簡單,但也有缺點:

對于非線性可分的情況,我們可以把它當成是數據集D中摻雜了一下noise,事實上,大多數情況下我們遇到的D,都或多或少地摻雜了noise。這時,機器學習流程是這樣的:
在非線性情況下,我們可以把條件放松,即不苛求每個點都分類正確,而是容忍有錯誤點,取錯誤點的個數最少時的權重w:
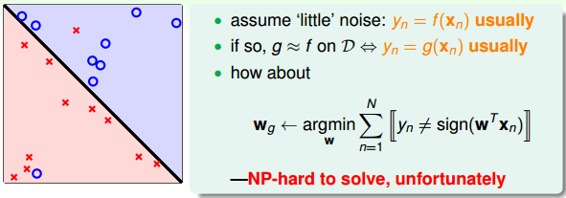
事實證明,上面的解是NP-hard問題,難以求解。然而,我們可以對在線性可分類型中表現很好的PLA做個修改,把它應用到非線性可分類型中,獲得近似最好的g。
修改后的PLA稱為Packet Algorithm。它的算法流程與PLA基本類似,首先初始化權重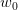,計算出在這條初始化的直線中,分類錯誤點的個數。然后對錯誤點進行修正,更新w,得到一條新的直線,在計算其對應的分類錯誤的點的個數,并與之前錯誤點個數比較,取個數較小的直線作為我們當前選擇的分類直線。之后,再經過n次迭代,不斷比較當前分類錯誤點個數與之前最少的錯誤點個數比較,選擇最小的值保存。直到迭代次數完成后,選取個數最少的直線對應的w,即為我們最終想要得到的權重值。

如何判斷數據集D是不是線性可分?對于二維數據來說,通常還是通過肉眼觀察來判斷的。一般情況下,Pocket Algorithm要比PLA速度慢一些。
### **五、總結**
本節課主要介紹了線性感知機模型,以及解決這類感知機分類問題的簡單算法:PLA。我們詳細證明了對于線性可分問題,PLA可以停下來并實現完全正確分類。對于不是線性可分的問題,可以使用PLA的修正算法Pocket Algorithm來解決。
**_注明:_**
文章中所有的圖片均來自臺灣大學林軒田《機器學習基石》課程。
- 臺灣大學林軒田機器學習筆記
- 機器學習基石
- 1 -- The Learning Problem
- 2 -- Learning to Answer Yes/No
- 3 -- Types of Learning
- 4 -- Feasibility of Learning
- 5 -- Training versus Testing
- 6 -- Theory of Generalization
- 7 -- The VC Dimension
- 8 -- Noise and Error
- 9 -- Linear Regression
- 10 -- Logistic Regression
- 11 -- Linear Models for Classification
- 12 -- Nonlinear Transformation
- 13 -- Hazard of Overfitting
- 14 -- Regularization
- 15 -- Validation
- 16 -- Three Learning Principles
- 機器學習技法
- 1 -- Linear Support Vector Machine
- 2 -- Dual Support Vector Machine
- 3 -- Kernel Support Vector Machine
- 4 -- Soft-Margin Support Vector Machine
- 5 -- Kernel Logistic Regression
- 6 -- Support Vector Regression
- 7 -- Blending and Bagging
- 8 -- Adaptive Boosting
- 9 -- Decision Tree
- 10 -- Random Forest
- 11 -- Gradient Boosted Decision Tree
- 12 -- Neural Network
- 13 -- Deep Learning
- 14 -- Radial Basis Function Network
- 15 -- Matrix Factorization
- 16(完結) -- Finale