
# 10 -- Logistic Regression
上一節課,我們介紹了Linear Regression線性回歸,以及用平方錯誤來尋找最佳的權重向量w,獲得最好的線性預測。本節課將介紹Logistic Regression邏輯回歸問題。
### **一、Logistic Regression Problem**
一個心臟病預測的問題:根據患者的年齡、血壓、體重等信息,來預測患者是否會有心臟病。很明顯這是一個二分類問題,其輸出y只有{-1,1}兩種情況。
二元分類,一般情況下,理想的目標函數f(x)>0.5,則判斷為正類1;若f(x)<0.5,則判斷為負類-1。
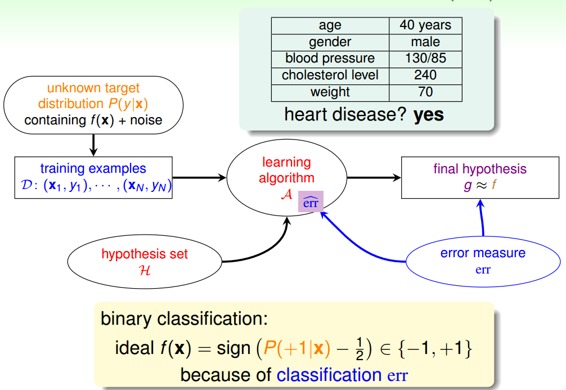
但是,如果我們想知道的不是患者有沒有心臟病,而是到底患者有多大的幾率是心臟病。這表示,我們更關心的是目標函數的值(分布在0,1之間),表示是正類的概率(正類表示是心臟病)。這跟我們原來討論的二分類問題不太一樣,我們把這個問題稱為軟性二分類問題(’soft’ binary classification)。這個值越接近1,表示正類的可能性越大;越接近0,表示負類的可能性越大。

對于軟性二分類問題,理想的數據是分布在[0,1]之間的具體值,但是實際中的數據只可能是0或者1,我們可以把實際中的數據看成是理想數據加上了噪聲的影響。
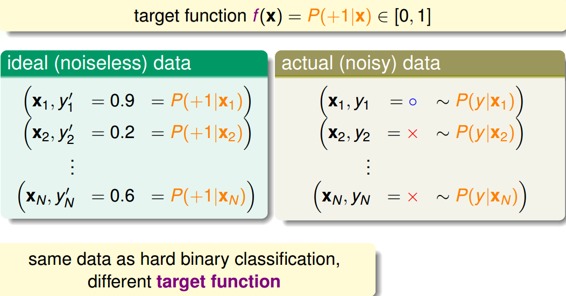
如果目標函數是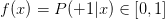的話,我們如何找到一個好的Hypothesis跟這個目標函數很接近呢?
首先,根據我們之前的做法,對所有的特征值進行加權處理。計算的結果s,我們稱之為’risk score’:

但是特征加權和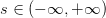,如何將s值限定在[0,1]之間呢?一個方法是使用sigmoid Function,記為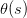。那么我們的目標就是找到一個hypothesis: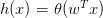。

Sigmoid Function函數記為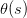,滿足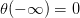,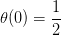,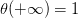。這個函數是平滑的、單調的S型函數。則對于邏輯回歸問題,hypothesis就是這樣的形式:
那我們的目標就是求出這個預測函數h(x),使它接近目標函數f(x)。
### **二、Logistic Regression Error**
現在我們將Logistic Regression與之前講的Linear Classification、Linear Regression做個比較:
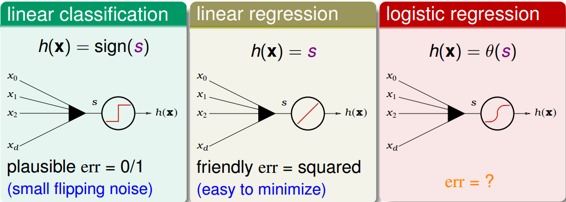
這三個線性模型都會用到線性scoring function 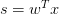。linear classification的誤差使用的是0/1 err;linear regression的誤差使用的是squared err。那么logistic regression的誤差該如何定義呢?
先介紹一下“似然性”的概念。目標函數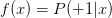,如果我們找到了hypothesis很接近target function。也就是說,在所有的Hypothesis集合中找到一個hypothesis與target function最接近,能產生同樣的數據集D,包含y輸出label,則稱這個hypothesis是最大似然likelihood。

logistic function: 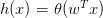滿足一個性質: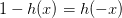。那么,似然性h:
因為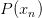對所有的h來說,都是一樣的,所以我們可以忽略它。那么我們可以得到logistic h正比于所有的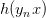乘積。我們的目標就是讓乘積值最大化。

如果將w代入的話:
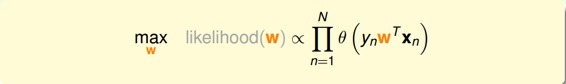
為了把連乘問題簡化計算,我們可以引入ln操作,讓連乘轉化為連加:
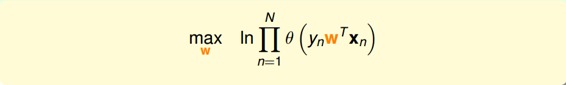
接著,我們將maximize問題轉化為minimize問題,添加一個負號就行,并引入平均數操作:
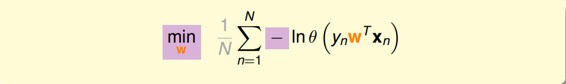
將logistic function的表達式帶入,那么minimize問題就會轉化為如下形式:
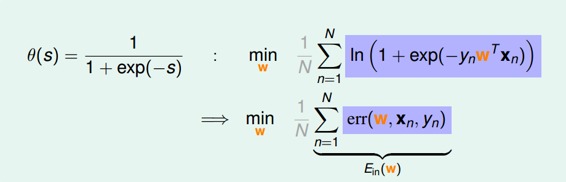
至此,我們得到了logistic regression的err function,稱之為cross-entropy error交叉熵誤差:

### **三、Gradient of Logistic Regression Error**
我們已經推導了的表達式,那接下來的問題就是如何找到合適的向量w,讓最小。
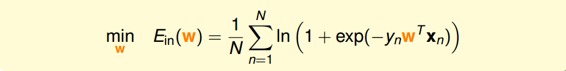
Logistic Regression的是連續、可微、二次可微的凸曲線(開口向上),根據之前Linear Regression的思路,我們只要計算的梯度為零時的w,即為最優解。

對計算梯度,學過微積分的都應該很容易計算出來:
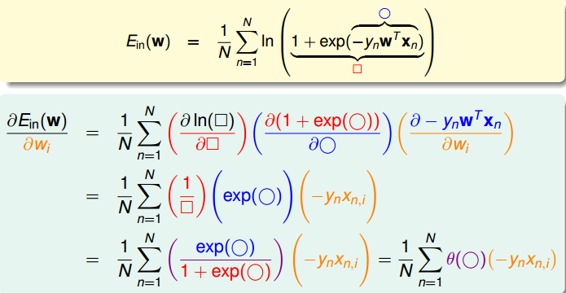
最終得到的梯度表達式為:
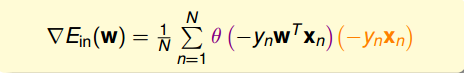
為了計算最小值,我們就要找到讓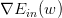等于0的位置。
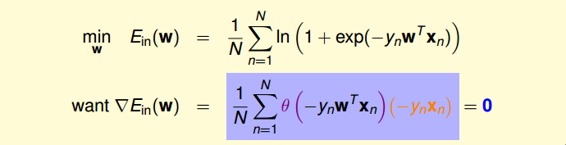
上式可以看成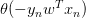是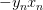的線性加權。要求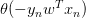與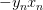的線性加權和為0,那么一種情況是線性可分,如果所有的權重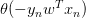為0,那就能保證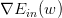為0。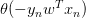是sigmoid function,根據其特性,只要讓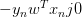,即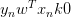。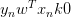表示對于所有的點,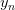與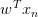都是同號的,這表示數據集D必須是全部線性可分的才能成立。
然而,保證所有的權重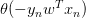為0是不太現實的,總有不等于0的時候,那么另一種常見的情況是非線性可分,只能通過使加權和為零,來求解w。這種情況沒有closed-form解,與Linear Regression不同,只能用迭代方法求解。

之前所說的Linear Regression有closed-form解,可以說是“一步登天”的;但是PLA算法是一步一步修正迭代進行的,每次對錯誤點進行修正,不斷更新w值。PLA的迭代優化過程表示如下:

w每次更新包含兩個內容:一個是每次更新的方向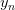,用表示,另一個是每次更新的步長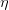。參數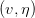和終止條件決定了我們的迭代優化算法。

### **四、Gradient Descent**
根據上一小節PLA的思想,迭代優化讓每次w都有更新:
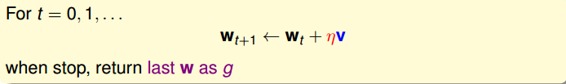
我們把曲線看做是一個山谷的話,要求最小,即可比作下山的過程。整個下山過程由兩個因素影響:一個是下山的單位方向;另外一個是下山的步長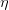。

利用微分思想和線性近似,假設每次下山我們只前進一小步,即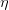很小,那么根據泰勒Taylor一階展開,可以得到:
關于Taylor展開的介紹,可參考我另一篇博客:
[多元函數的泰勒(Taylor)展開式](http://blog.csdn.net/red_stone1/article/details/70260070)
迭代的目的是讓越來越小,即讓。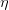是標量,因為如果兩個向量方向相反的話,那么他們的內積最小(為負),也就是說如果方向與梯度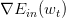反向的話,那么就能保證每次迭代都成立。則,我們令下降方向為:
是單位向量,每次都是沿著梯度的反方向走,這種方法稱為梯度下降(gradient descent)算法。那么每次迭代公式就可以寫成:
下面討論一下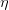的大小對迭代優化的影響: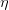如果太小的話,那么下降的速度就會很慢;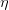如果太大的話,那么之前利用Taylor展開的方法就不準了,造成下降很不穩定,甚至會上升。因此,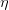應該選擇合適的值,一種方法是在梯度較小的時候,選擇小的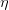,梯度較大的時候,選擇大的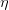,即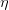正比于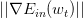。這樣保證了能夠快速、穩定地得到最小值。
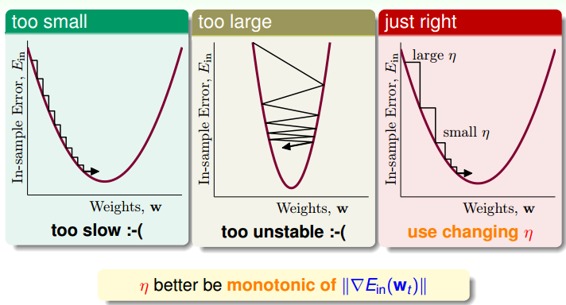
對學習速率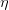做個更修正,梯度下降算法的迭代公式可以寫成:
其中:
總結一下基于梯度下降的Logistic Regression算法步驟如下:
* **初始化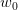**
* **計算梯度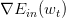**
* **迭代跟新**
* **滿足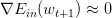或者達到迭代次數,迭代結束**
### **五、總結**
我們今天介紹了Logistic Regression。首先,從邏輯回歸的問題出發,將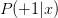作為目標函數,將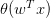作為hypothesis。接著,我們定義了logistic regression的err function,稱之為cross-entropy error交叉熵誤差。然后,我們計算logistic regression error的梯度,最后,通過梯度下降算法,計算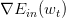時對應的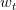值。
**_注明:_**
文章中所有的圖片均來自臺灣大學林軒田《機器學習基石》課程
- 臺灣大學林軒田機器學習筆記
- 機器學習基石
- 1 -- The Learning Problem
- 2 -- Learning to Answer Yes/No
- 3 -- Types of Learning
- 4 -- Feasibility of Learning
- 5 -- Training versus Testing
- 6 -- Theory of Generalization
- 7 -- The VC Dimension
- 8 -- Noise and Error
- 9 -- Linear Regression
- 10 -- Logistic Regression
- 11 -- Linear Models for Classification
- 12 -- Nonlinear Transformation
- 13 -- Hazard of Overfitting
- 14 -- Regularization
- 15 -- Validation
- 16 -- Three Learning Principles
- 機器學習技法
- 1 -- Linear Support Vector Machine
- 2 -- Dual Support Vector Machine
- 3 -- Kernel Support Vector Machine
- 4 -- Soft-Margin Support Vector Machine
- 5 -- Kernel Logistic Regression
- 6 -- Support Vector Regression
- 7 -- Blending and Bagging
- 8 -- Adaptive Boosting
- 9 -- Decision Tree
- 10 -- Random Forest
- 11 -- Gradient Boosted Decision Tree
- 12 -- Neural Network
- 13 -- Deep Learning
- 14 -- Radial Basis Function Network
- 15 -- Matrix Factorization
- 16(完結) -- Finale