
# 8 -- Adaptive Boosting
上節課我們主要開始介紹Aggregation Models,目的是將不同的hypothesis得到的集合起來,利用集體智慧得到更好的預測模型G。首先我們介紹了Blending,blending是將已存在的所有結合起來,可以是uniformly,linearly,或者non-linearly組合形式。然后,我們討論了在沒有那么多的情況下,使用bootstrap方式,從已有數據集中得到新的類似的數據集,從而得到不同的。這種做法稱為bagging。本節課將繼續從這些概念出發,介紹一種新的演算法。
### **Motivation of Boosting**
我們先來看一個簡單的識別蘋果的例子,老師展示20張圖片,讓6歲孩子們通過觀察,判斷其中哪些圖片的內容是蘋果。從判斷的過程中推導如何解決二元分類問題的方法。
顯然這是一個監督式學習,20張圖片包括它的標簽都是已知的。首先,學生Michael回答說:所有的蘋果應該是圓形的。根據Michael的判斷,對應到20張圖片中去,大部分蘋果能被識別出來,但也有錯誤。其中錯誤包括有的蘋果不是圓形,而且圓形的水果也不一定是蘋果。如下圖所示:

上圖中藍色區域的圖片代表分類錯誤。顯然,只用“蘋果是圓形的”這一個條件不能保證分類效果很好。我們把藍色區域(分類錯誤的圖片)放大,分類正確的圖片縮小,這樣在接下來的分類中就會更加注重這些錯誤樣本。
然后,學生Tina觀察被放大的錯誤樣本和上一輪被縮小的正確樣本,回答說:蘋果應該是紅色的。根據Tina的判斷,得到的結果如下圖所示:

上圖中藍色區域的圖片一樣代表分類錯誤,即根據這個蘋果是紅色的條件,使得青蘋果和草莓、西紅柿都出現了判斷錯誤。那么結果就是把這些分類錯誤的樣本放大化,其它正確的樣本縮小化。同樣,這樣在接下來的分類中就會更加注重這些錯誤樣本。
接著,學生Joey經過觀察又說:蘋果也可能是綠色的。根據Joey的判斷,得到的結果如下圖所示:
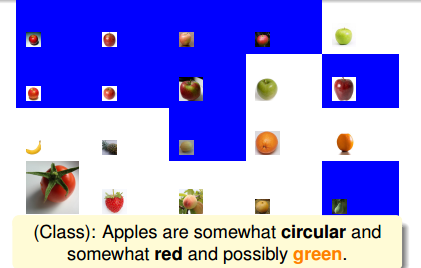
上圖中藍色區域的圖片一樣代表分類錯誤,根據蘋果是綠色的條件,使得圖中藍色區域都出現了判斷錯誤。同樣把這些分類錯誤的樣本放大化,其它正確的樣本縮小化,在下一輪判斷繼續對其修正。
后來,學生Jessica又發現:上面有梗的才是蘋果。得到如下結果:

經過這幾個同學的推論,蘋果被定義為:圓的,紅色的,也可能是綠色的,上面有梗。從一個一個的推導過程中,我們似乎得到一個較為準確的蘋果的定義。雖然可能不是非常準確,但是要比單一的條件要好得多。也就是說把所有學生對蘋果的定義融合起來,最終得到一個比較好的對蘋果的總體定義。這種做法就是我們本節課將要討論的演算法。這些學生代表的就是簡單的hypotheses ,將所有融合,得到很好的預測模型G。例如,二維平面上簡單的hypotheses(水平線和垂直線),這些簡單最終組成的較復雜的分類線能夠較好地將正負樣本完全分開,即得到了好的預測模型。
所以,上個蘋果的例子中,不同的學生代表不同的hypotheses ;最終得到的蘋果總體定義就代表hypothesis G;而老師就代表演算法A,指導學生的注意力集中到關鍵的例子中(錯誤樣本),從而得到更好的蘋果定義。其中的數學原理,我們下一部分詳細介紹。

### **Diversity by Re-weighting**
在介紹這個演算法之前,我們先來講一下上節課就介紹過的bagging。Bagging的核心是bootstrapping,通過對原始數據集D不斷進行bootstrap的抽樣動作,得到與D類似的數據集,每組都能得到相應的,從而進行aggregation的操作。現在,假如包含四個樣本的D經過bootstrap,得到新的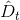如下:
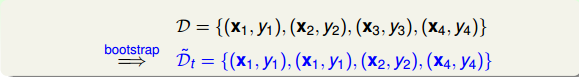
那么,對于新的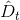,把它交給base algorithm,找出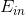最小時對應的,如下圖右邊所示。
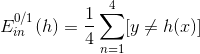
由于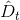完全是D經過bootstrap得到的,其中樣本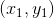出現2次,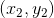出現1次,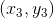出現0次,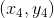出現1次。引入一個參數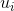來表示原D中第i個樣本在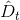中出現的次數,如下圖左邊所示。
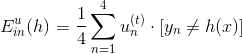

參數u相當于是權重因子,當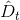中第i個樣本出現的次數越多的時候,那么對應的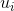越大,表示在error function中對該樣本的懲罰越多。所以,從另外一個角度來看bagging,它其實就是通過bootstrap的方式,來得到這些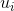值,作為犯錯樣本的權重因子,再用base algorithn最小化包含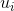的error function,得到不同的。這個error function被稱為bootstrap-weighted error。
這種算法叫做Weightd Base Algorithm,目的就是最小化bootstrap-weighted error。
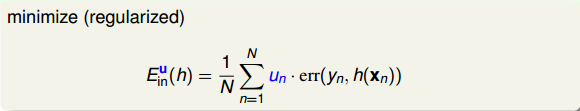
其實,這種weightd base algorithm我們之前就介紹過類似的算法形式。例如在soft-margin SVM中,我們引入允許犯錯的項,同樣可以將每個點的error乘以權重因子。加上該項前的參數C,經過QP,最終得到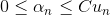,有別于之前介紹的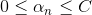。這里的相當于每個犯錯的樣本的懲罰因子,并會反映到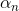的范圍限定上。
同樣在logistic regression中,同樣可以對每個犯錯誤的樣本乘以相應的,作為懲罰因子。表示該錯誤點出現的次數,越大,則對應的懲罰因子越大,則在最小化error時就應該更加重視這些點。
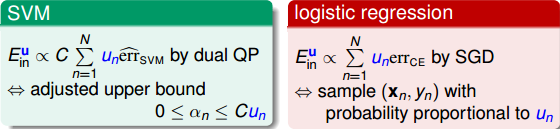
其實這種example-weighted learning,我們在機器學習基石課程第8次筆記中就介紹過class-weighted的思想。二者道理是相通的。
知道了u的概念后,我們知道不同的u組合經過base algorithm得到不同的。那么如何選取u,使得到的之間有很大的不同呢?之所以要讓所有的差別很大,是因為上節課aggregation中,我們介紹過越不一樣,其aggregation的效果越好,即每個人的意見越不相同,越能運用集體的智慧,得到好的預測模型。
為了得到不同的,我們先來看看和是怎么得到的:

如上所示,是由得到的,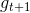是由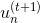得到的。如果這個模型在使用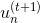的時候得到的error很大,即預測效果非常不好,那就表示由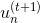計算的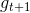會與有很大不同。而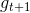與差異性大正是我們希望看到的。
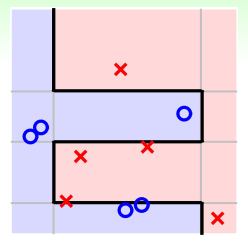
怎么做呢?方法是利用在使用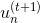的時候表現很差的條件,越差越好。如果在作用下,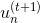中的表現(即error)近似為0.5的時候,表明對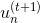的預測分類沒有什么作用,就像拋硬幣一樣,是隨機選擇的。這樣的做法就能最大限度地保證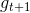會與有較大的差異性。其數學表達式如下所示:
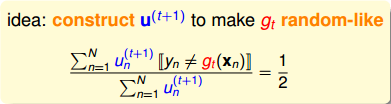
乍看上面這個式子,似乎不好求解。但是,我們對它做一些等價處理,其中分式中分子可以看成作用下犯錯誤的點,而分母可以看成犯錯的點和沒有犯錯誤的點的集合,即所有樣本點。其中犯錯誤的點和沒有犯錯誤的點分別用橘色方塊和綠色圓圈表示:
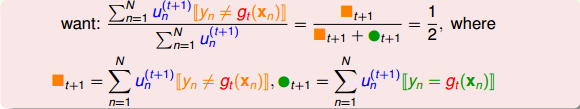
要讓分式等于0.5,顯然只要將犯錯誤的點和沒有犯錯誤的點的數量調成一樣就可以了。也就是說,在作用下,讓犯錯的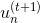數量和沒有犯錯的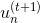數量一致就行(包含權重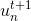)。一種簡單的方法就是利用放大和縮小的思想(本節課開始引入識別蘋果的例子中提到的放大圖片和縮小圖片就是這個目的),將犯錯誤的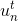和沒有犯錯誤的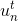做相應的乘積操作,使得二者值變成相等。例如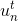 of incorrect為1126,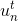 of correct為6211,要讓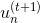中錯誤比例正好是0.5,可以這樣做,對于incorrect 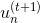:
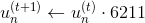
對于correct 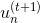:
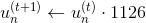
或者利用犯錯的比例來做,令weighted incorrect rate和weighted correct rate分別設為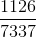和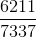。一般求解方式是令犯錯率為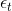,在計算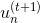的時候,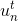分別乘以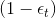和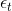。

### **Adaptive Boosting Algorithm**
上一部分,我們介紹了在計算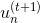的時候,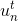分別乘以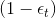和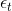。下面將構造一個新的尺度因子:
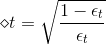
那么引入這個新的尺度因子之后,對于錯誤的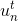,將它乘以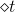;對于正確的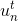,將它除以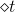。這種操作跟之前介紹的分別乘以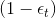和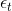的效果是一樣的。之所以引入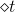是因為它告訴我們更多的物理意義。因為如果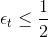,得到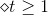,那么接下來錯誤的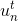與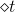的乘積就相當于把錯誤點放大了,而正確的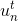與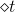的相除就相當于把正確點縮小了。這種scale up incorrect和scale down correct的做法與本節課開始介紹的學生識別蘋果的例子中放大錯誤的圖片和縮小正確的圖片是一個原理,讓學生能夠將注意力更多地放在犯錯誤的點上。通過這種scaling-up incorrect的操作,能夠保證得到不同于的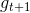。

值得注意的是上述的結論是建立在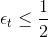的基礎上,如果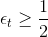,那么就做相反的推論即可。關于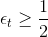的情況,我們稍后會進行說明。
從這個概念出發,我們可以得到一個初步的演算法。其核心步驟是每次迭代時,利用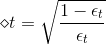把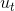更新為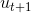。具體迭代步驟如下:

但是,上述步驟還有兩個問題沒有解決,第一個問題是初始的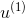應為多少呢?一般來說,為了保證第一次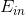最小的話,設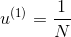即可。這樣最開始的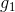就能由此推導。第二個問題,最終的G(x)應該怎么求?是將所有的g(t)合并uniform在一起嗎?一般來說并不是這樣直接uniform求解,因為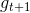是通過得來的,二者在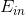上的表現差別比較大。所以,一般是對所有的g(t)進行linear或者non-linear組合來得到G(t)。
接下來的內容,我們將對上面的第二個問題進行探討,研究一種算法,將所有的g(t)進行linear組合。方法是計算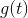的同時,就能計算得到其線性組合系數,即aggregate linearly on the fly。這種算法使最終求得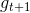的時候,所有的線性組合系數也求得了,不用再重新計算了。這種Linear Aggregation on the Fly算法流程為:

如何在每次迭代的時候計算呢?我們知道與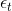是相關的: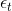越小,對應的應該越大,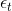越大,對應的應該越小。又因為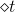與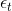是正相關的,所以,應該是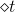的單調函數。我們構造為:
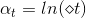
這樣取值是有物理意義的,例如當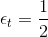時,error很大,跟擲骰子這樣的隨機過程沒什么兩樣,此時對應的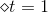,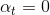,即此對G沒有什么貢獻,權重應該設為零。而當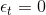時,沒有error,表示該預測非常準,此時對應的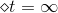,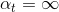,即此對G貢獻非常大,權重應該設為無窮大。
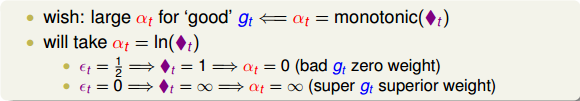
這種算法被稱為Adaptive Boosting。它由三部分構成:base learning algorithm A,re-weighting factor 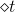和linear aggregation 。這三部分分別對應于我們在本節課開始介紹的例子中的Student,Teacher和Class。

綜上所述,完整的adaptive boosting(AdaBoost)Algorithm流程如下:

從我們之前介紹過的VC bound角度來看,AdaBoost算法理論上滿足:

上式中,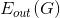的上界由兩部分組成,一項是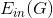,另一項是模型復雜度O(*)。模型復雜度中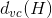是的VC Dimension,T是迭代次數,可以證明G的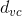服從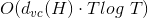。
對這個VC bound中的第一項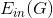來說,有一個很好的性質:如果滿足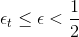,則經過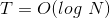次迭代之后,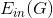能減小到等于零的程度。而當N很大的時候,其中第二項也能變得很小。因為這兩項都能變得很小,那么整個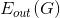就能被限定在一個有限的上界中。
其實,這種性質也正是AdaBoost算法的精髓所在。只要每次的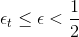,即所選擇的矩g比亂猜的表現好一點點,那么經過每次迭代之后,矩g的表現都會比原來更好一些,逐漸變強,最終得到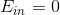且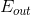很小。

### **Adaptive Boosting in Action**
上一小節我們已經介紹了選擇一個“弱弱”的算法A(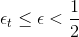,比亂猜好就行),就能經過多次迭代得到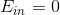。我們稱這種形式為decision stump模型。下面介紹一個例子,來看看AdaBoost是如何使用decision stump解決實際問題的。
如下圖所示,二維平面上分布一些正負樣本點,利用decision stump來做切割。
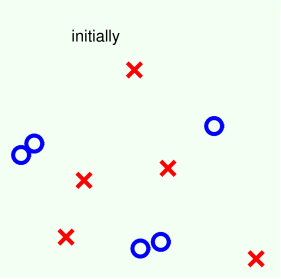
第一步:
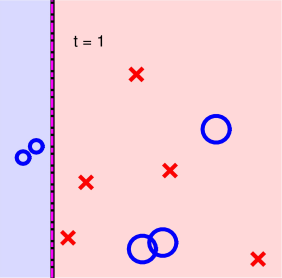
第二步:
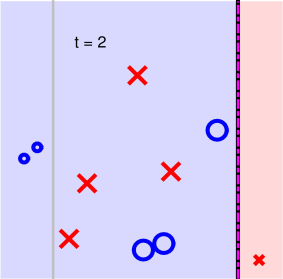
第三步:
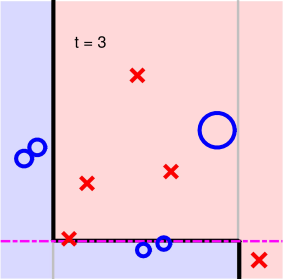
第四步:
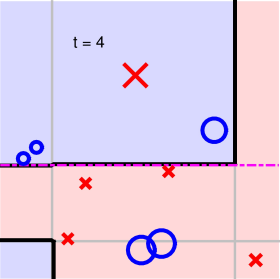
第五步:
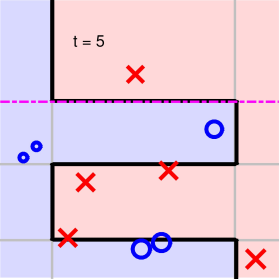
可以看到,經過5次迭代之后,所有的正負點已經被完全分開了,則最終得到的分類線為:
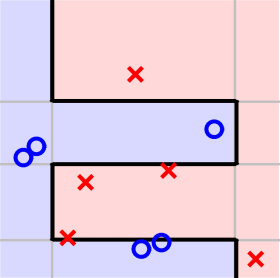
另外一個例子,對于一個相對比較復雜的數據集,如下圖所示。它的分界線從視覺上看應該是一個sin波的形式。如果我們再使用AdaBoost算法,通過decision stump來做切割。在迭代切割100次后,得到的分界線如下所示。
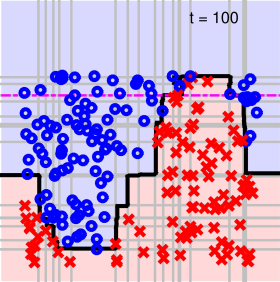
可以看出,AdaBoost-Stump這種非線性模型得到的分界線對正負樣本有較好的分離效果。
課程中還介紹了一個AdaBoost-Stump在人臉識別方面的應用:

### **總結**
本節課主要介紹了Adaptive Boosting。首先通過講一個老師教小學生識別蘋果的例子,來引入Boosting的思想,即把許多“弱弱”的hypotheses合并起來,變成很強的預測模型。然后重點介紹這種算法如何實現,關鍵在于每次迭代時,給予樣本不同的系數u,宗旨是放大錯誤樣本,縮小正確樣本,得到不同的小矩g。并且在每次迭代時根據錯誤值的大小,給予不同不同的權重。最終由不同的進行組合得到整體的預測模型G。實際證明,Adaptive Boosting能夠得到有效的預測模型。
**_注明:_**
文章中所有的圖片均來自臺灣大學林軒田《機器學習技法》課程
- 臺灣大學林軒田機器學習筆記
- 機器學習基石
- 1 -- The Learning Problem
- 2 -- Learning to Answer Yes/No
- 3 -- Types of Learning
- 4 -- Feasibility of Learning
- 5 -- Training versus Testing
- 6 -- Theory of Generalization
- 7 -- The VC Dimension
- 8 -- Noise and Error
- 9 -- Linear Regression
- 10 -- Logistic Regression
- 11 -- Linear Models for Classification
- 12 -- Nonlinear Transformation
- 13 -- Hazard of Overfitting
- 14 -- Regularization
- 15 -- Validation
- 16 -- Three Learning Principles
- 機器學習技法
- 1 -- Linear Support Vector Machine
- 2 -- Dual Support Vector Machine
- 3 -- Kernel Support Vector Machine
- 4 -- Soft-Margin Support Vector Machine
- 5 -- Kernel Logistic Regression
- 6 -- Support Vector Regression
- 7 -- Blending and Bagging
- 8 -- Adaptive Boosting
- 9 -- Decision Tree
- 10 -- Random Forest
- 11 -- Gradient Boosted Decision Tree
- 12 -- Neural Network
- 13 -- Deep Learning
- 14 -- Radial Basis Function Network
- 15 -- Matrix Factorization
- 16(完結) -- Finale