
# 可視化分類數據
> 譯者:[hold2010](https://github.com/hold2010)
在[繪制關系圖](relational.html#relational-tutorial)的教程中,我們學習了如何使用不同的可視化方法來展示數據集中多個變量之間的關系。在示例中,我們專注于兩個數值變量之間的主要關系。如果其中一個主要變量是“可分類的”(能被分為不同的組),那么我們可以使用更專業的可視化方法。
在 seaborn 中,有幾種不同的方法可以對分類數據進行可視化。類似于[`relplot()`](../generated/seaborn.relplot.html#seaborn.relplot "seaborn.relplot")與[`scatterplot()`](../generated/seaborn.scatterplot.html#seaborn.scatterplot "seaborn.scatterplot")或者[`lineplot()`](../generated/seaborn.lineplot.html#seaborn.lineplot "seaborn.lineplot")之間的關系,有兩種方法可以制作這些圖。有許多 axes-level 函數可以用不同的方式繪制分類數據,還有一個 figure-level 接口[`catplot()`](../generated/seaborn.catplot.html#seaborn.catplot "seaborn.catplot"),可以對它們進行統一的高級訪問。
將不同的分類圖類型視為三個不同的家族,這是很有幫助的。下面我們將詳細討論,它們是:
分類散點圖:
* [`stripplot()`](../generated/seaborn.stripplot.html#seaborn.stripplot "seaborn.stripplot") (with `kind="strip"`; the default)
* [`swarmplot()`](../generated/seaborn.swarmplot.html#seaborn.swarmplot "seaborn.swarmplot") (with `kind="swarm"`)
分類分布圖:
* [`boxplot()`](../generated/seaborn.boxplot.html#seaborn.boxplot "seaborn.boxplot") (with `kind="box"`)
* [`violinplot()`](../generated/seaborn.violinplot.html#seaborn.violinplot "seaborn.violinplot") (with `kind="violin"`)
* [`boxenplot()`](../generated/seaborn.boxenplot.html#seaborn.boxenplot "seaborn.boxenplot") (with `kind="boxen"`)
分類估計圖:
* [`pointplot()`](../generated/seaborn.pointplot.html#seaborn.pointplot "seaborn.pointplot") (with `kind="point"`)
* [`barplot()`](../generated/seaborn.barplot.html#seaborn.barplot "seaborn.barplot") (with `kind="bar"`)
* [`countplot()`](../generated/seaborn.countplot.html#seaborn.countplot "seaborn.countplot") (with `kind="count"`)
這些家族使用不同的粒度級別來表示數據,我們應該根據實際情況來決定到底要使用哪個。它們有統一的 API,所以我們可以輕松地在不同類型之間進行切換,并從多個角度來觀察數據。
在本教程中,我們主要關注 figure-level 接口[`catplot()`](../generated/seaborn.catplot.html#seaborn.catplot "seaborn.catplot")。這個函數是上述每個函數更高級別的接口,因此當我們顯示每種繪圖時都會引用它們,不清楚的話可以隨時查看特定類型的 API 文檔。
```py
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style="ticks", color_codes=True)
```
## 分類散點圖
在[`catplot()`](../generated/seaborn.catplot.html#seaborn.catplot "seaborn.catplot")中,數據默認使用散點圖表示。在 seaborn 中有兩種不同的分類散點圖,它們采用不同的方法來表示分類數據。 其中一種是屬于一個類別的所有點,將沿著與分類變量對應的軸落在相同位置。[`stripplot()`](../generated/seaborn.stripplot.html#seaborn.stripplot "seaborn.stripplot")方法是[`catplot()`](../generated/seaborn.catplot.html#seaborn.catplot "seaborn.catplot")中 kind 的默認參數,它是用少量隨機“抖動”調整分類軸上的點的位置:
```py
tips = sns.load_dataset("tips")
sns.catplot(x="day", y="total_bill", data=tips);
```
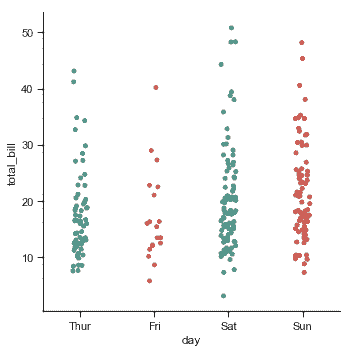
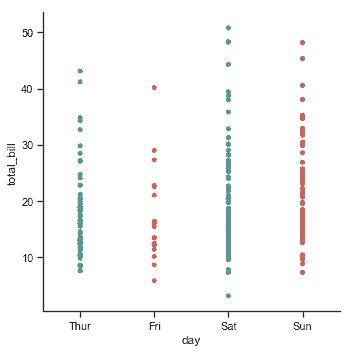
`jitter`參數控制抖動的大小,你也可以完全禁用它:
```py
sns.catplot(x="day", y="total_bill", jitter=False, data=tips);
```
另一種方法使用防止它們重疊的算法沿著分類軸調整點。我們可以用它更好地表示觀測分布,但是只適用于相對較小的數據集。這種繪圖有時被稱為“beeswarm”,可以使用 seaborn 中的[`swarmplot()`](../generated/seaborn.swarmplot.html#seaborn.swarmplot "seaborn.swarmplot")繪制,通過在[`catplot()`](../generated/seaborn.catplot.html#seaborn.catplot "seaborn.catplot")中設置`kind="swarm"`來激活:
```py
sns.catplot(x="day", y="total_bill", kind="swarm", data=tips);
```

與關系圖類似,可以通過使用`hue`語義向分類圖添加另一個維。(分類圖當前不支持`size`和`style`語義 )。 每個不同的分類繪圖函數以不同方式處理`hue` 語義。對于散點圖,我們只需要更改點的顏色:
```py
sns.catplot(x="day", y="total_bill", hue="sex", kind="swarm", data=tips);
```

與數值數據不同,如何沿著軸順序排列分類變量并不總是顯而易見的。通常,seaborn 分類繪圖函數試圖從數據中推斷出類別的順序。 如果您的數據具有 pandas 中的`Categorical`數據類型,則可以在此處設置類別的默認順序。如果傳遞給分類軸的變量看起來是數字,則將對級別進行排序。但是數據仍然被視為分類并在分類軸上的序數位置(特別是 0,1,......)處理,即使用數字來標記它們:
```py
sns.catplot(x="size", y="total_bill", kind="swarm",
data=tips.query("size != 3"));
```
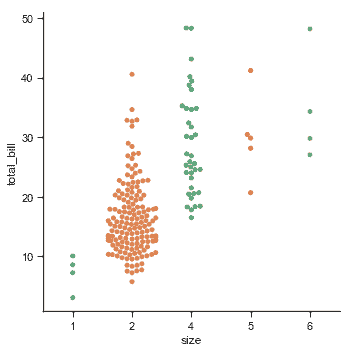
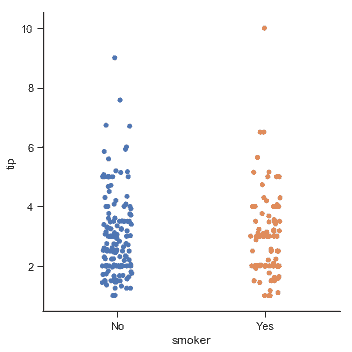
選擇默認排序的另一個選項是獲取數據集中出現的類別級別。也可以使用`order`參數在特定圖表的基礎上控制排序。在同一圖中繪制多個分類圖時,這很重要,我們將在下面看到更多:
```py
sns.catplot(x="smoker", y="tip", order=["No", "Yes"], data=tips);
```
我們已經提到了“分類軸”的概念。在這些示例中,它始終對應于水平軸。但是將分類變量放在垂直軸上通常很有幫助(特別是當類別名稱相對較長或有許多類別時)。為此,我們交換軸上的變量賦值:
```py
sns.catplot(x="total_bill", y="day", hue="time", kind="swarm", data=tips);
```
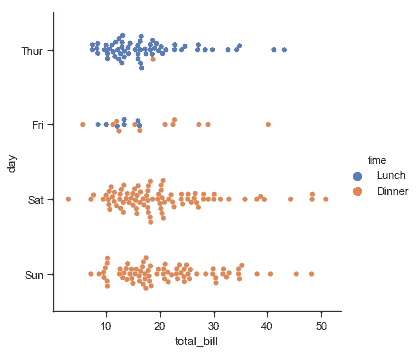
## 類別內觀察點的分布
隨著數據集的大小增加,分類散點圖中每個類別可以提供的值分布信息受到限制。當發生這種情況時,有幾種方法可以總結分布信息,以便于我們可以跨分類級別進行簡單比較。
### 箱線圖
第一個是熟悉的[`boxplot()`](../generated/seaborn.boxplot.html#seaborn.boxplot "seaborn.boxplot")。它可以顯示分布的三個四分位數值以及極值。“胡須”延伸到位于下四分位數和上四分位數的 1.5 IQR 內的點,超出此范圍的觀察值會獨立顯示。這意味著箱線圖中的每個值對應于數據中的實際觀察值。
```py
sns.catplot(x="day", y="total_bill", kind="box", data=tips);
```

添加`hue`語義, 語義變量的每個級別的框沿著分類軸移動,因此它們將不會重疊:
```py
sns.catplot(x="day", y="total_bill", hue="smoker", kind="box", data=tips);
```
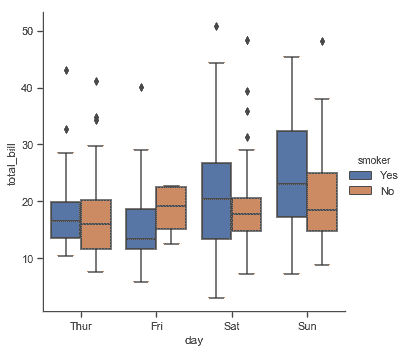
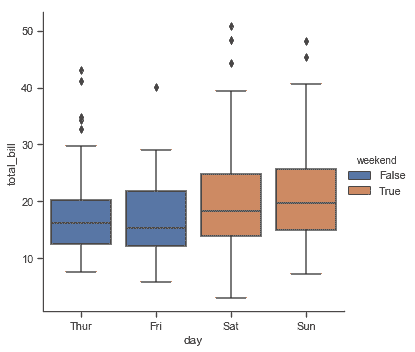
此行為被稱為“dodging”,默認開啟,因為我們假定語義變量嵌套在主分類變量中。如果不是這樣,可以禁用 dodging:
```py
tips["weekend"] = tips["day"].isin(["Sat", "Sun"])
sns.catplot(x="day", y="total_bill", hue="weekend",
kind="box", dodge=False, data=tips);
```
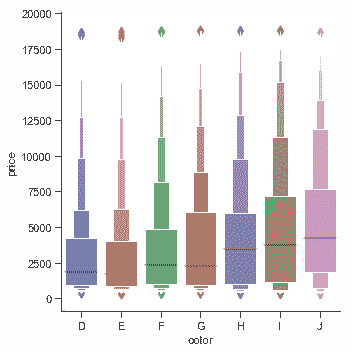
一個相關的函數[`boxenplot()`](../generated/seaborn.boxenplot.html#seaborn.boxenplot "seaborn.boxenplot")可以繪制一個與 Box-plot 類似的圖。它為了顯示更多信息而對分布的形狀進行了優化,比較適合于較大的數據集:
```py
diamonds = sns.load_dataset("diamonds")
sns.catplot(x="color", y="price", kind="boxen",
data=diamonds.sort_values("color"));
```
### 小提琴圖
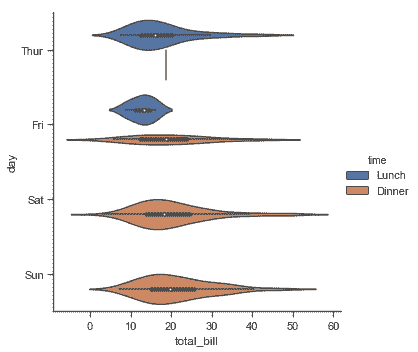
另一種方法是[`violinplot()`](../generated/seaborn.violinplot.html#seaborn.violinplot "seaborn.violinplot"),它將箱線圖與[分布](distributions.html#distribution-tutorial)教程中描述的核密度估算程序結合起來:
```py
sns.catplot(x="total_bill", y="day", hue="time",
kind="violin", data=tips);
```
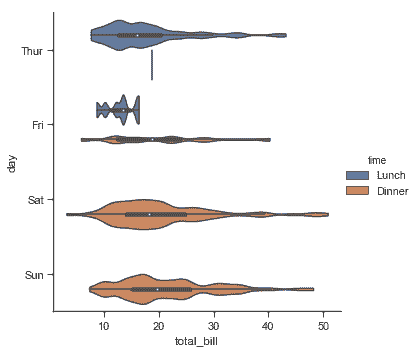
該方法使用核密度估計來提供更豐富的值分布描述。此外,violin 中還顯示了來自箱線圖的四分位數和 whikser 值。缺點是由于 violinplot 使用了 KDE,我們需要調整一些額外參數,與箱形圖相比增加了一些復雜性:
```py
sns.catplot(x="total_bill", y="day", hue="time",
kind="violin", bw=.15, cut=0,
data=tips);
```
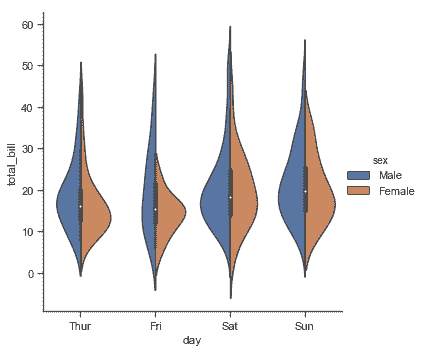
當 hue 參數只有兩個級別時,也可以“拆分”violins,這樣可以更有效地利用空間:
```py
sns.catplot(x="day", y="total_bill", hue="sex",
kind="violin", split=True, data=tips);
```
最后,在 violin 內的繪圖有幾種選項,包括顯示每個獨立的觀察而不是摘要箱線圖值的方法:
```py
sns.catplot(x="day", y="total_bill", hue="sex",
kind="violin", inner="stick", split=True,
palette="pastel", data=tips);
```
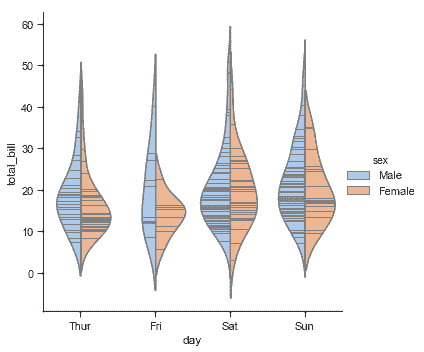
我們也可以將[`swarmplot()`](../generated/seaborn.swarmplot.html#seaborn.swarmplot "seaborn.swarmplot")或`striplot()`與箱形圖或 violin plot 結合起來,展示每次觀察以及分布摘要:
```py
g = sns.catplot(x="day", y="total_bill", kind="violin", inner=None, data=tips)
sns.swarmplot(x="day", y="total_bill", color="k", size=3, data=tips, ax=g.ax);
```

## 類別內的統計估計
對于其他應用程序,你可能希望顯示值的集中趨勢估計,而不是顯示每個類別中的分布。Seaborn 有兩種主要方式來顯示這些信息。重要的是,這些功能的基本 API 與上面討論的 API 相同。
### 條形圖
實現這一目標的是我們熟悉的條形圖。在 seaborn 中,[`barplot()`](../generated/seaborn.barplot.html#seaborn.barplot "seaborn.barplot")函數在完整數據集上運行并應用函數來獲取估計值(默認情況下取平均值)。當每個類別中有多個觀察值時,它還使用自舉來計算估計值周圍的置信區間,并使用誤差條繪制:
```py
titanic = sns.load_dataset("titanic")
sns.catplot(x="sex", y="survived", hue="class", kind="bar", data=titanic);
```
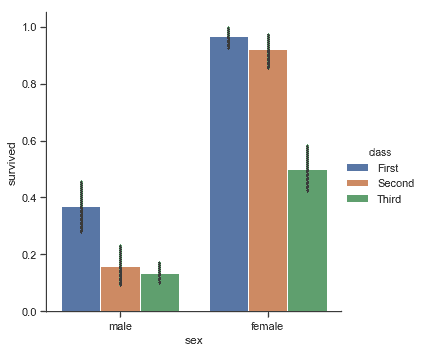
條形圖的一個特例是,當你想要顯示每個類別中的觀察數量而不是計算第二個變量的統計數據時。這類似于分類而非定量變量的直方圖。在 seaborn 中,使用[`countplot()`](../generated/seaborn.countplot.html#seaborn.countplot "seaborn.countplot")函數很容易實現:
```py
sns.catplot(x="deck", kind="count", palette="ch:.25", data=titanic);
```

無論是[`barplot()`](../generated/seaborn.barplot.html#seaborn.barplot "seaborn.barplot")還是[`countplot()`](../generated/seaborn.countplot.html#seaborn.countplot "seaborn.countplot"),都可以使用上面討論的所有選項,也可以調用每個函數的文檔示例中的其他選項:
```py
sns.catplot(y="deck", hue="class", kind="count",
palette="pastel", edgecolor=".6",
data=titanic);
```
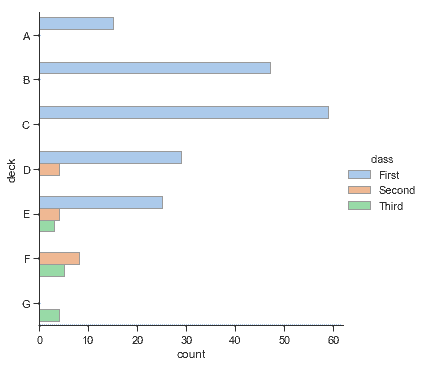
### 點圖
[`pointplot()`](../generated/seaborn.pointplot.html#seaborn.pointplot "seaborn.pointplot")函數提供了另一種可視化相同信息的樣式。此函數還對另一個軸上的高度估計值進行編碼,但不是顯示一個完整的條形圖,而是繪制點估計值和置信區間。另外,[`pointplot()`](../generated/seaborn.pointplot.html#seaborn.pointplot "seaborn.pointplot")連接來自相同`hue`類別的點。我們可以很容易的看出主要關系如何隨著色調語義的變化而變化,因為人類的眼睛很擅長觀察斜率的差異:
```py
sns.catplot(x="sex", y="survived", hue="class", kind="point", data=titanic);
```
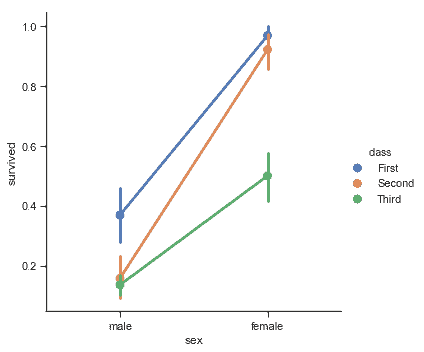
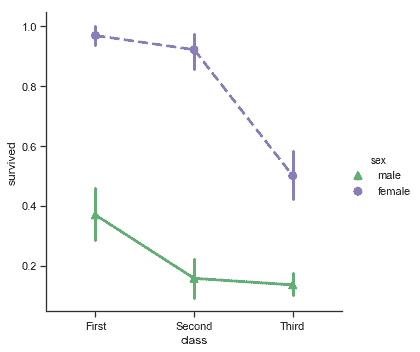
當分類函數缺少關系函數中的`style`語義時, 將 markers 和 linestyles 與色調一起改變,以制作最大可訪問的圖形并在黑白中重現良好,這仍然是一個好主意:
```py
sns.catplot(x="class", y="survived", hue="sex",
palette={"male": "g", "female": "m"},
markers=["^", "o"], linestyles=["-", "--"],
kind="point", data=titanic);
```
## 繪制“寬格式”數據
雖然優選使用“長形式”或“整齊”數據,但這些函數也可以應用于各種“寬格式”的數據,包括 pandas DataFrames 或二維 numpy 數組。這些對象應該直接傳遞給`data`參數:
```py
iris = sns.load_dataset("iris")
sns.catplot(data=iris, orient="h", kind="box");
```

另外,axes-level 函數接受 Pandas 或 numpy 對象的向量,而不是`DataFrame`中的變量:
```py
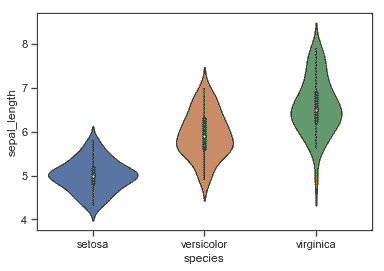
sns.violinplot(x=iris.species, y=iris.sepal_length);
```
要控制上面討論的函數繪制的圖形的大小和形狀,你必須使用 matplotlib 命令來進行設置:
```py
f, ax = plt.subplots(figsize=(7, 3))
sns.countplot(y="deck", data=titanic, color="c");
```
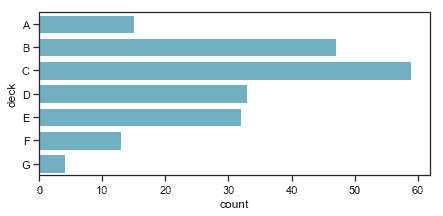
當你需要一個分類圖與一個更復雜的其他類型的圖共存時,你可以采取這種方法。
## 顯示與 facet 的多種關系
就像[`relplot()`](../generated/seaborn.relplot.html#seaborn.relplot "seaborn.relplot")一樣, [`catplot()`](../generated/seaborn.catplot.html#seaborn.catplot "seaborn.catplot")建立在[`FacetGrid`](../generated/seaborn.FacetGrid.html#seaborn.FacetGrid "seaborn.FacetGrid")上,這意味著很容易添加層面變量來可視化高維關系:
```py
sns.catplot(x="day", y="total_bill", hue="smoker",
col="time", aspect=.6,
kind="swarm", data=tips);
```
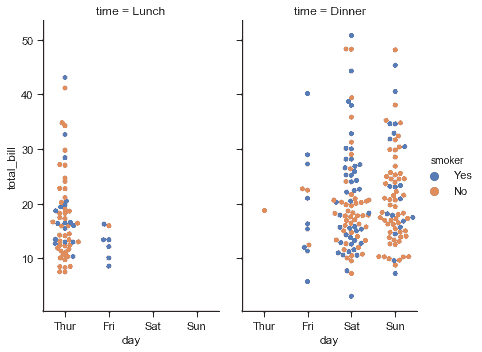
要進一步自定義繪圖,我們可以使用它返回的[`FacetGrid`](../generated/seaborn.FacetGrid.html#seaborn.FacetGrid "seaborn.FacetGrid")對象上的方法:
```py
g = sns.catplot(x="fare", y="survived", row="class",
kind="box", orient="h", height=1.5, aspect=4,
data=titanic.query("fare > 0"))
g.set(xscale="log");
```

- seaborn 0.9 中文文檔
- Seaborn 簡介
- 安裝和入門
- 可視化統計關系
- 可視化分類數據
- 可視化數據集的分布
- 線性關系可視化
- 構建結構化多圖網格
- 控制圖像的美學樣式
- 選擇調色板
- seaborn.relplot
- seaborn.scatterplot
- seaborn.lineplot
- seaborn.catplot
- seaborn.stripplot
- seaborn.swarmplot
- seaborn.boxplot
- seaborn.violinplot
- seaborn.boxenplot
- seaborn.pointplot
- seaborn.barplot
- seaborn.countplot
- seaborn.jointplot
- seaborn.pairplot
- seaborn.distplot
- seaborn.kdeplot
- seaborn.rugplot
- seaborn.lmplot
- seaborn.regplot
- seaborn.residplot
- seaborn.heatmap
- seaborn.clustermap
- seaborn.FacetGrid
- seaborn.FacetGrid.map
- seaborn.FacetGrid.map_dataframe
- seaborn.PairGrid
- seaborn.PairGrid.map
- seaborn.PairGrid.map_diag
- seaborn.PairGrid.map_offdiag
- seaborn.PairGrid.map_lower
- seaborn.PairGrid.map_upper
- seaborn.JointGrid
- seaborn.JointGrid.plot
- seaborn.JointGrid.plot_joint
- seaborn.JointGrid.plot_marginals
- seaborn.set
- seaborn.axes_style
- seaborn.set_style
- seaborn.plotting_context
- seaborn.set_context
- seaborn.set_color_codes
- seaborn.reset_defaults
- seaborn.reset_orig
- seaborn.set_palette
- seaborn.color_palette
- seaborn.husl_palette
- seaborn.hls_palette
- seaborn.cubehelix_palette
- seaborn.dark_palette
- seaborn.light_palette
- seaborn.diverging_palette
- seaborn.blend_palette
- seaborn.xkcd_palette
- seaborn.crayon_palette
- seaborn.mpl_palette
- seaborn.choose_colorbrewer_palette
- seaborn.choose_cubehelix_palette
- seaborn.choose_light_palette
- seaborn.choose_dark_palette
- seaborn.choose_diverging_palette
- seaborn.load_dataset
- seaborn.despine
- seaborn.desaturate
- seaborn.saturate
- seaborn.set_hls_values