
# seaborn.lmplot
> 譯者:[P3n9W31](https://github.com/P3n9W31)
```py
seaborn.lmplot(x, y, data, hue=None, col=None, row=None, palette=None, col_wrap=None, height=5, aspect=1, markers='o', sharex=True, sharey=True, hue_order=None, col_order=None, row_order=None, legend=True, legend_out=True, x_estimator=None, x_bins=None, x_ci='ci', scatter=True, fit_reg=True, ci=95, n_boot=1000, units=None, order=1, logistic=False, lowess=False, robust=False, logx=False, x_partial=None, y_partial=None, truncate=False, x_jitter=None, y_jitter=None, scatter_kws=None, line_kws=None, size=None)
```
在 FacetGrid 對象上繪制數據和回歸模型。
這個函數結合了 [`regplot()`](seaborn.regplot.html#seaborn.regplot "seaborn.regplot") 和 [`FacetGrid`](seaborn.FacetGrid.html#seaborn.FacetGrid "seaborn.FacetGrid")。 它預期作為一個能夠將回歸模型運用在數據集處于不同條件下的子數據集的方便的接口
在考慮如何將變量分配到不同方面時,一般規則是使用 `hue` 進行最重要的比較,然后使用 `col` 和 `row `。 但是,請始終考慮您的特定數據集以及您正在創建的可視化目標。
估算回歸模型有許多互斥的選項。 有關詳細信息,請參閱 [tutorial](http://seaborn.pydata.org/tutorial/regression.html#regression-tutorial) 。
此函數的參數涵蓋了 [`FacetGrid`](seaborn.FacetGrid.html#seaborn.FacetGrid "seaborn.FacetGrid")中的大多數選項,盡管這樣,偶爾還是會出現您需要直接使用該類和 [`regplot()`](seaborn.regplot.html#seaborn.regplot "seaborn.regplot") 的情況。
參數:`x, y`:字符串,可選
> 輸入變量; 這些應該是`data`中的列名。
`data`:DataFrame
> Tidy (“long-form”)格式的 DataFrame,其中每列為一個變量,每行為一個觀測樣本。
`hue, col, row`:字符串
> 定義數據子集的變量,將在網格中的不同構面上繪制。 請參閱`* _order`參數以控制此變量的級別順序。
`palette`: 調色板名稱,列表或字典,可選
> 用于`hue`變量的不同級別的顏色。 應該是 [`color_palette()`](seaborn.color_palette.html#seaborn.color_palette "seaborn.color_palette")可以解釋的東西,或者是將色調級別映射到 matplotlib 顏色的字典。
`col_wrap`:整數,可選
> 以此寬度“包裹”列變量,以便列分面(facet)跨越多行。 與`row` 分面(facet)不兼容。
`height`: 標量,可選
> 每個分面(facet)的高度(以英寸為單位)。 另見:`aspect`。
`aspect`:標量,可選
> 每個分面(facet)的縱橫比,因此`aspect * height`給出每個分面(facet)的寬度,單位為英寸。
`markers`:matplotlib 標記代碼或標記代碼列表,可選
> 散點圖的標記。如果是列表,列表中的每個標記將用于`hue`變量的每個級別。
`share{x,y}`:布爾值,‘col’,或 ‘row’ ,可選
> 如果為 true,則分面(facet)之間將跨列共享 y 軸和/或跨行共享 x 軸。
`{hue,col,row}_order`:列表,可選
> 分面變量的級別順序。在默認情況下,這將是級別在“data”中出現的順序,或者,如果變量是 pandas 的分類類別變量,則為類別的順序。
`legend`:布爾值,可選
> 如果為“True”并且有一個`hue`變量,則添加一個圖例。
`legend_out`:布爾值,可選
> 如果為“True”,圖形尺寸將被擴展,圖例將被繪制在圖像中部右側之外。
`x_estimator`:可調用的映射向量->標量,可選
> 將此函數應用于`x`的每個唯一值并繪制結果的估計值。當`x`是離散變量時,這是十分有用的。如果給出`x_ci`,則該估計將被引導并且將繪制置信區間。
`x_bins`:整數或向量,可選
> 將`x`變量加入離散區間,然后估計中心趨勢和置信區間。 此分箱僅影響散點圖的繪制方式; 回歸仍然適合原始數據。該參數被解釋為均勻大小(不必要間隔)的箱的數量或箱中心的位置。使用此參數時,它意味著`x_estimator`的默認值為`numpy.mean`。
`x_ci`:“ci”。“sd”, 在[0,100]間的整數或 None,可選
> 繪制“x”離散值的集中趨勢時使用的置信區間的大小。 如果為`“ci”`,遵循`ci`參數的值。 如果是“sd”,則跳過 bootstrapping 并顯示每個 bin 中觀察值的標準偏差。
`scatter`:布爾值,可選
> 如果為 `True`,則繪制帶有基礎觀測值(或`x_estimator` 值)的散點圖。
`fit_reg`:布爾值,可選
> 如果為 `True`,則估計并繪制與 `x` 和 `y` 變量相關的回歸模型。
`ci`:在[0,100]間的整數或 None,可選
> 回歸估計的置信區間的大小。這將使用回歸線周圍的半透明帶繪制。 使用自助法(bootstrap)估計置信區間; 對于大型數據集,建議通過將此參數設置為 None 來避免該計算。
`n_boot`:整數,可選
> 用于估計`ci`的自助法(bootstrap)重采樣數。 默認值試圖在時間和穩定性之間找到平衡; 你可能希望為“最終”版本的圖像增加此值。
`units`:`data`中的變量名,可選
> 如果`x`和`y`觀察結果嵌套在采樣單元中,則可以在此處指定。在通過對所有的單元和觀察樣本(在單元內)執行重新采樣的多級自助法(multilevel bootstrap)來計算置信區間時將考慮這一點。 否則,這不會影響估計或繪制回歸的方式。
`order`:整數,可選
> 如果`order`大于 1,使用`numpy.polyfit`來估計多項式回歸。
`logistic`:布爾值,可選
> 如果為“True”,則假設`y`是二元變量并使用`statsmodels`來估計邏輯回歸模型。 請注意,這比線性回歸的計算密集程度要大得多,因此您可能希望減少引導程序重新采樣(`n_boot`)的數量或將 `ci`設置為“無”。
`lowess`:布爾值,可選
> 如果為“True”,則使用`statsmodels`來估計非參數 lowess 模型(局部加權線性回歸)。 請注意,目前無法為此類模型繪制置信區間。
`robust`:布爾值,可選
> 如果為“True”,則使用`statsmodels`來估計穩健回歸。 這將削弱異常值。 請注意,這比標準線性回歸的計算密集程度要大得多,因此您可能希望減少引導程序重新采樣(`n_boot`)的數量或將 `ci`設置為“無”。
`logx`:布爾值,可選
> 如果為 `True`,則估計形式 y~log(x)的線性回歸,但在輸入空間中繪制散點圖和回歸模型。 請注意,`x`必須為正才能正常工作。
`{x,y}_partial`: `data`中的字符串或矩陣
> 混淆(Confounding)變量以在繪圖之前退回`x`或`y`變量。
`truncate`:布爾值,可選
> 默認情況下,繪制回歸線以在繪制散點圖后填充 x 軸限制。 如果`truncate`是`True`,它將改為受到數據本身限制的限制。
`{x,y}_jitter`:浮點數,可選
> 將此大小的均勻隨機噪聲添加到“x”或“y”變量中。 在擬合回歸之后,噪聲被添加到數據的副本中,并且僅影響散點圖的外觀。 在繪制采用離散值的變量時,這會很有用。
`{scatter,line}_kws`:字典
> 傳遞給`plt.scatter`和`plt.plot`的附加關鍵字參數。
也可以查看
繪制數據和條件模型 fit.Subplot 網格用于繪制條件關系。合并 [`regplot()`](seaborn.regplot.html#seaborn.regplot "seaborn.regplot") 和 [`PairGrid`](seaborn.PairGrid.html#seaborn.PairGrid "seaborn.PairGrid") (與`kind =“reg”`一起使用時)。
注意
[`regplot()`](seaborn.regplot.html#seaborn.regplot "seaborn.regplot") 與 [`lmplot()`](#seaborn.lmplot "seaborn.lmplot") 函數是緊密關聯的,但是前者是一個坐標軸級別的函數,而后者則是一個聯合了[`regplot()`](seaborn.regplot.html#seaborn.regplot "seaborn.regplot") 與 [`FacetGrid `](seaborn.FacetGrid.html#seaborn.FacetGrid "seaborn.FacetGrid")的圖像級別的函數。
示例
這些例子集中在基本的回歸模型圖上,以展示各種方面的選項; 請參閱 [`regplot()`](seaborn.regplot.html#seaborn.regplot "seaborn.regplot") 文檔,以演示繪制數據和模型的其他選項。 還有其他一些如何使用 [`FacetGrid`](seaborn.FacetGrid.html#seaborn.FacetGrid "seaborn.FacetGrid") 文檔中的返回對象操作繪圖的示例。
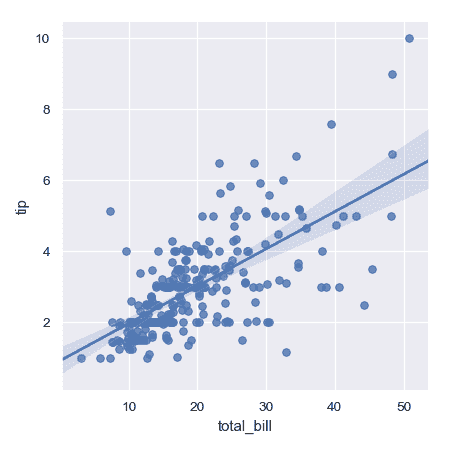
繪制兩個變量之間的簡單線性關系:
```py
>>> import seaborn as sns; sns.set(color_codes=True)
>>> tips = sns.load_dataset("tips")
>>> g = sns.lmplot(x="total_bill", y="tip", data=tips)
```
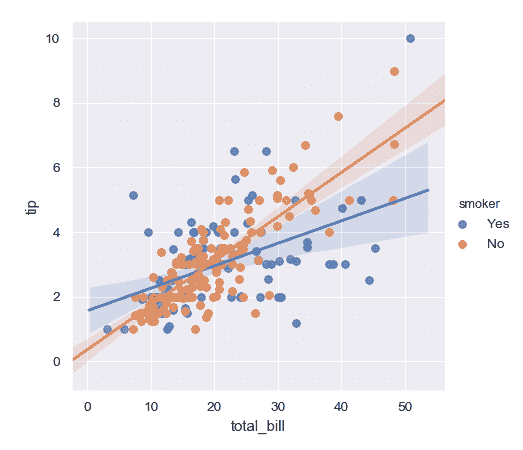
條件在第三個變量上并繪制不同顏色的水平:
```py
>>> g = sns.lmplot(x="total_bill", y="tip", hue="smoker", data=tips)
```
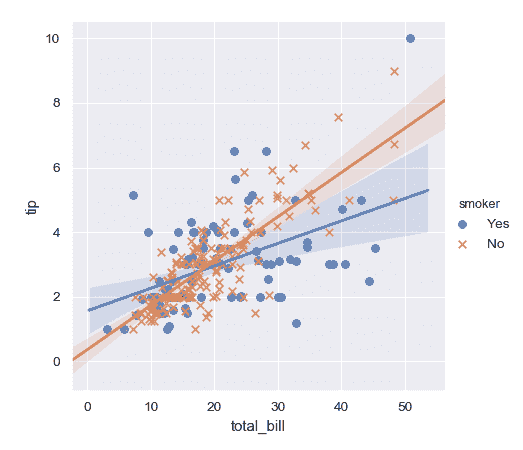
使用不同的標記和顏色,以便繪圖更容易再現為黑白:
```py
>>> g = sns.lmplot(x="total_bill", y="tip", hue="smoker", data=tips,
... markers=["o", "x"])
```
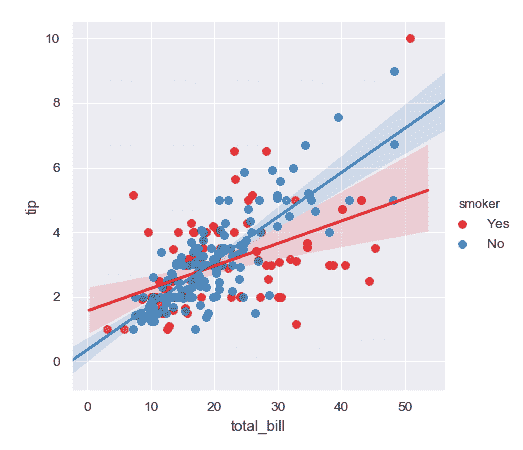
使用不同的調色板:
```py
>>> g = sns.lmplot(x="total_bill", y="tip", hue="smoker", data=tips,
... palette="Set1")
```
使用字典將`hue`級別映射到顏色:
```py
>>> g = sns.lmplot(x="total_bill", y="tip", hue="smoker", data=tips,
... palette=dict(Yes="g", No="m"))
```
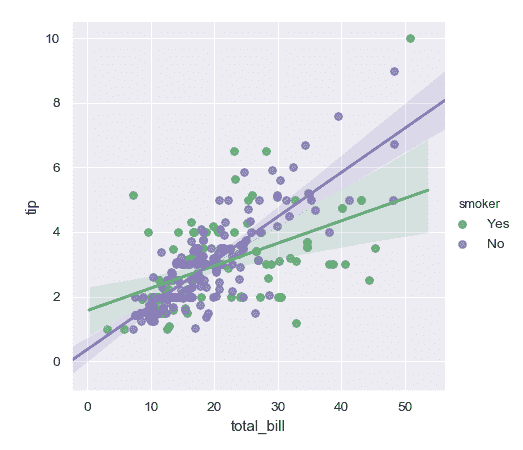
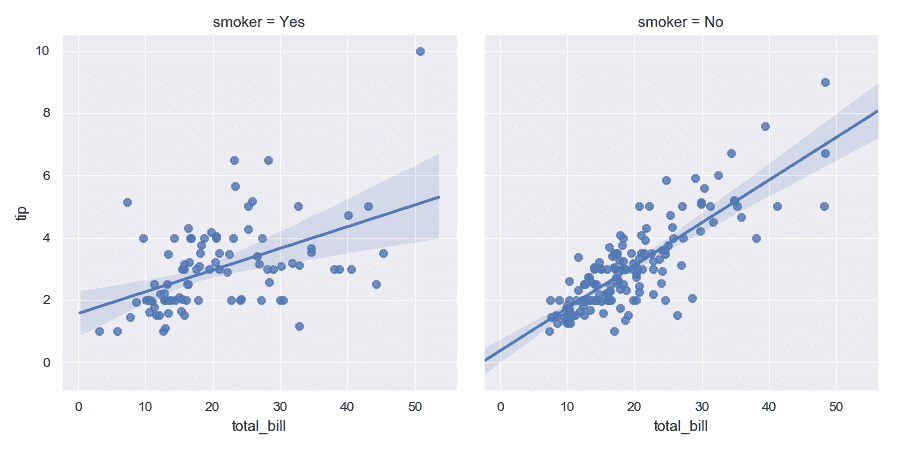
繪制不同列中第三個變量的級別:
```py
>>> g = sns.lmplot(x="total_bill", y="tip", col="smoker", data=tips)
```
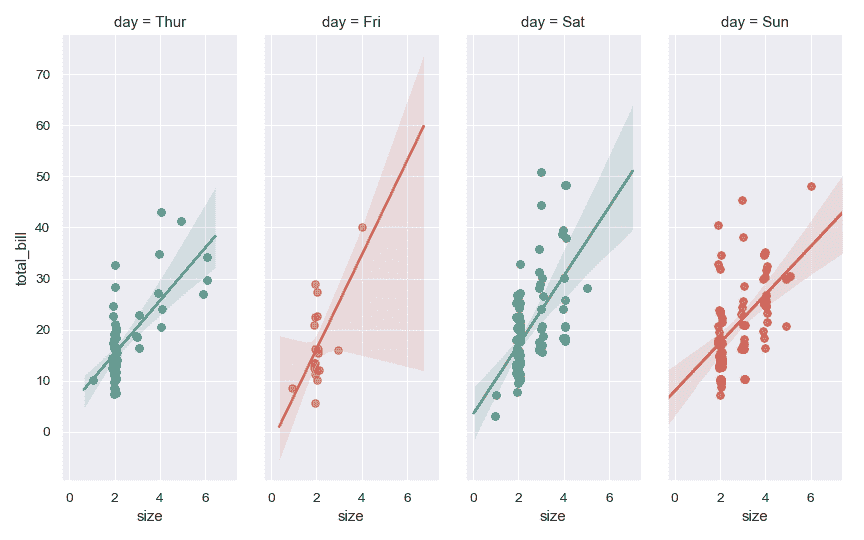
更改構面的高度和縱橫比:
```py
>>> g = sns.lmplot(x="size", y="total_bill", hue="day", col="day",
... data=tips, height=6, aspect=.4, x_jitter=.1)
```
將列變量的級別換行為多行:
```py
>>> g = sns.lmplot(x="total_bill", y="tip", col="day", hue="day",
... data=tips, col_wrap=2, height=3)
```

兩個變量上的條件形成一個完整的網格:
```py
>>> g = sns.lmplot(x="total_bill", y="tip", row="sex", col="time",
... data=tips, height=3)
```

在返回的 [`FacetGrid`](seaborn.FacetGrid.html#seaborn.FacetGrid "seaborn.FacetGrid") 實例上使用方法來進一步調整圖像:
```py
>>> g = sns.lmplot(x="total_bill", y="tip", row="sex", col="time",
... data=tips, height=3)
>>> g = (g.set_axis_labels("Total bill (US Dollars)", "Tip")
... .set(xlim=(0, 60), ylim=(0, 12),
... xticks=[10, 30, 50], yticks=[2, 6, 10])
... .fig.subplots_adjust(wspace=.02))
```

- seaborn 0.9 中文文檔
- Seaborn 簡介
- 安裝和入門
- 可視化統計關系
- 可視化分類數據
- 可視化數據集的分布
- 線性關系可視化
- 構建結構化多圖網格
- 控制圖像的美學樣式
- 選擇調色板
- seaborn.relplot
- seaborn.scatterplot
- seaborn.lineplot
- seaborn.catplot
- seaborn.stripplot
- seaborn.swarmplot
- seaborn.boxplot
- seaborn.violinplot
- seaborn.boxenplot
- seaborn.pointplot
- seaborn.barplot
- seaborn.countplot
- seaborn.jointplot
- seaborn.pairplot
- seaborn.distplot
- seaborn.kdeplot
- seaborn.rugplot
- seaborn.lmplot
- seaborn.regplot
- seaborn.residplot
- seaborn.heatmap
- seaborn.clustermap
- seaborn.FacetGrid
- seaborn.FacetGrid.map
- seaborn.FacetGrid.map_dataframe
- seaborn.PairGrid
- seaborn.PairGrid.map
- seaborn.PairGrid.map_diag
- seaborn.PairGrid.map_offdiag
- seaborn.PairGrid.map_lower
- seaborn.PairGrid.map_upper
- seaborn.JointGrid
- seaborn.JointGrid.plot
- seaborn.JointGrid.plot_joint
- seaborn.JointGrid.plot_marginals
- seaborn.set
- seaborn.axes_style
- seaborn.set_style
- seaborn.plotting_context
- seaborn.set_context
- seaborn.set_color_codes
- seaborn.reset_defaults
- seaborn.reset_orig
- seaborn.set_palette
- seaborn.color_palette
- seaborn.husl_palette
- seaborn.hls_palette
- seaborn.cubehelix_palette
- seaborn.dark_palette
- seaborn.light_palette
- seaborn.diverging_palette
- seaborn.blend_palette
- seaborn.xkcd_palette
- seaborn.crayon_palette
- seaborn.mpl_palette
- seaborn.choose_colorbrewer_palette
- seaborn.choose_cubehelix_palette
- seaborn.choose_light_palette
- seaborn.choose_dark_palette
- seaborn.choose_diverging_palette
- seaborn.load_dataset
- seaborn.despine
- seaborn.desaturate
- seaborn.saturate
- seaborn.set_hls_values