
>[success] # 詞法解析
~~~
1.生活中經常我們會有一些對話比如'今天我吃了魚香肉絲',或者是'I ate noodles today' 但是實際
上如果我們大腦不進行分詞理解這些語句實際變得無意義就像'Iatenoodlestoday' 只是一堆字符串
詞法解析就像,我們大腦幫我們翻譯的一樣'今天''我''吃了''魚香肉絲'
2.如何可以讓程序也像人一樣可以對這些詞進行分類,其實在學習語言的過程時候已經知道了答
案,在我們第一次去學習漢字時候往往第一步是學習每一個'字',在將'字組成詞',同理在學習
英語時候需要先學習'26個字母',再學的是將不同'26個字母組成單詞',無論是'漢字'還是'單詞'
組成的字它們會有一些新的標記例如'名詞'、'動詞'等
3.現在按照我們讓大腦可以進行'詞法分析'學習步驟,來實現編程語言的詞法分析,第一步就是
'掃描',這個步驟將輸入的內容當作一個無意義的字符串,讀取時候它所看到的只是一次一個字符
例如'今天 我吃了魚香肉絲',掃描后變成了['今', '天', ' ', '我', '吃', '了', '魚', '香', '肉', '絲']
4.得到了這些我們在然后生成詞素(lexeme)。詞素是組成編程語言的最小的有意義的單元實
變成類似['今天','','我','吃', '了', '魚香','肉絲'],此時這個階段不知道它們是什么“類型”的詞。只知道
單詞在文本本身中的結束和開始位置。例如'今天' start:0 end:1
5.現在要做的是識別詞類型,將識別的單詞統一轉換成詞法單元'token' 形式即'<種別碼,屬性值>'
舉個例子來看'<名詞,今天><代詞,我>...'
~~~
>[info] ## 詞法單元'token'
兩個例子來源
[MOOC編譯原理](https://www.icourse163.org/course/HIT-1002123007?tid=1467039443)
[Reading Code Right, With Some Help From The Lexer](https://medium.com/basecs/reading-code-right-with-some-help-from-the-lexer-63d0be3d21d)
>[danger] ##### 例子一

* 舉個例子

>[danger] ##### 舉個前端例子的'token'
~~~
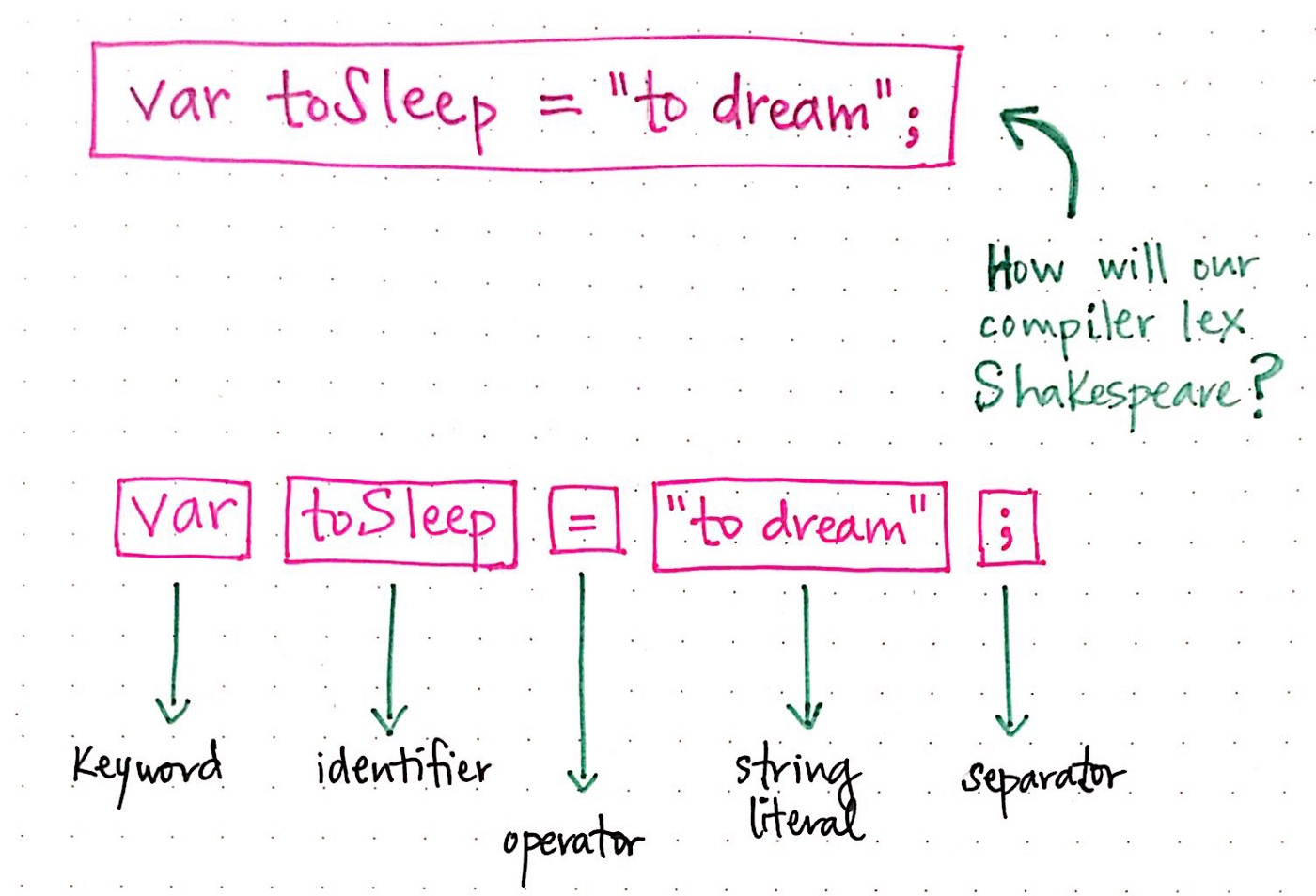
1.var toSleep = "to dream";,可以看到空格并不會作為一個詞法單元('token'),但這完全是因為js
不需要,但如果你是python 開發就會知道'空格最為縮減是完全有作為詞法單元('token')'必要
~~~
>[info] ## 做一個自己詞法解析器
~~~
1.詞法編輯器步驟,'讀取每個字'=》'將字組成詞素(lexeme)'=》'做好令牌token標記'
2.js程序語言比自然語言要稍微好處理點,首先js 和自然語句都一樣都需有語法,即屬于自己
的特定規則
2.1.空白:JS中連續的空格、換行、縮進等這些如果不在字符串里,就沒有任何實際邏輯意義,
所以把連續的空白符直接組合在一起作為一個語法單元。
2.2.注釋:行注釋或塊注釋,雖然對于人類來說有意義,但是對于計算機來說知道這是個“注釋”
就行了,并不關心內容,所以直接作為一個不可再拆的語法單元
2.3.字符串:對于機器而言,字符串的內容只是會參與計算或展示,里面再細分的內容也是沒
必要分析的
2.4.數字:JS語言里就有16、10、8進制以及科學表達法等數字表達語法,數字也是個具備含
義的最小單元
2.5.標識符:沒有被引號擴起來的連續字符,可包含字母、_、$、及數字(數字不能作為開
頭)。標識符可能代表一個變量,或者true、false這種內置常量、也可能是if、return、
function這種關鍵字,是哪種語義,分詞階段并不在乎,只要正確切分就好了。
2.6.運算符:+、-、*、/、>、<等等
2.7.括號:(...)可能表示運算優先級、也可能表示函數調用,分詞階段并不關注是哪種語義,
只把“(”或“)”當做一種基本語法單元
2.8.還有其他:如中括號、大括號、分號、冒號、點等等
~~~
>[danger] ##### 舉個例子
~~~
if (1 > 0) {
alert("if \"1 > 0\"");
}
~~~
~~~
1.第一步'掃描'拆解成單獨字符
[
'i', 'f', '(', 'a', ' ', '=',
'=', '=', ' ', '1', ')', '{',
'\n', ' ', ' ', ' ', ' ', 'c',
'o', 'n', 's', 'o', 'l', 'e',
'.', 'l', 'o', 'g', '(', 'a',
')', '\n', '}'
]
2.做詞素(lexeme),這里就變得簡單了,js關鍵字即具備實際意義可以組成語句的并不像
自然語言那么多。而且大多數情況下通過'空格'即是每一個詞最小單位例如'if' 等,這里將
詞素(lexeme)和 token 作為一步一起輸出(<種別碼,屬性值>),js像表達類似(<種別碼,屬性值>)
這里選擇了對象,下面例子可以看出'if' 被標記為'Keyword' 即關鍵字
[
{
"type": "Keyword",
"value": "if"
},
{
"type": "Punctuator",
"value": "("
},
{
"type": "Identifier",
"value": "a"
},
{
"type": "Punctuator",
"value": "==="
},
{
"type": "Numeric",
"value": "1"
},
{
"type": "Punctuator",
"value": ")"
},
{
"type": "Punctuator",
"value": "{"
},
{
"type": "Identifier",
"value": "console"
},
{
"type": "Punctuator",
"value": "."
},
{
"type": "Identifier",
"value": "log"
},
{
"type": "Punctuator",
"value": "("
},
{
"type": "Identifier",
"value": "a"
},
{
"type": "Punctuator",
"value": ")"
},
{
"type": "Punctuator",
"value": "}"
}
]
~~~
* 詞素(lexeme)

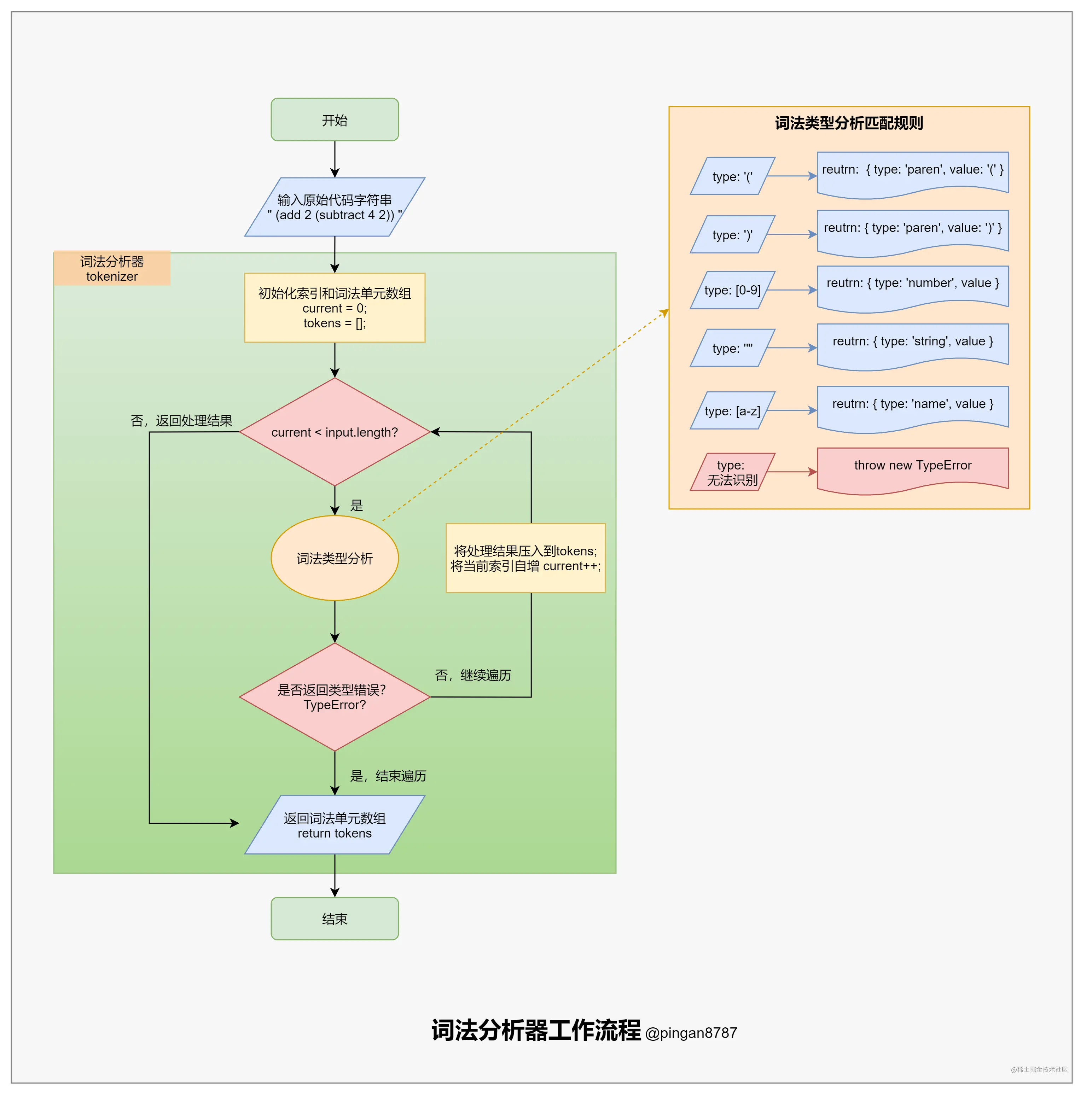
>[danger] ##### 形象的圖形理解
* 圖片來自【圖文詳解】200行JS代碼,帶你實現代碼編譯器(人人都能學會)
- https://juejin.cn/post/6844904105937207304#heading-24
~~~
1.這拆分過程其實就是簡單粗暴地一個字符一個字符地遍歷,然后分情況討論
~~~
>[danger] ##### 開始敲代碼
~~~
function tokenizeCode(code) {
// 當前讀取指針位置
let current = 0;
// 令牌結果
const tokens = [];
// 當前字符
let currentChar = "";
while (current < code.length) {
currentChar = code[current];
// 如果是; 就是結束符 直接存起來
// 類似 const b = 2;const a = 1 此時; 也是有語義的
if (currentChar === ";") {
tokens.push({
type: "sep",
value: ";",
});
// 將指針指向下一個字符
++current;
// 這個字符不需要其他特殊出來因此可以直接處理 下一個
continue;
}
// 處理() 情況
if (currentChar === "(" || currentChar === ")") {
tokens.push({
type: "parens",
value: currentChar,
});
// 將指針指向下一個字符
++current;
// 這個字符不需要其他特殊出來因此可以直接處理 下一個
continue;
}
// 處理{} 情況
if (currentChar === "}" || currentChar === "{") {
// 與 ; 類似只是語法單元類型不同
tokens.push({
type: "brace",
value: currentChar,
});
++current;
continue;
}
// 處理 < > = 但實際情況比這復雜 還會有 >= <= == === 等情況
if (currentChar === ">" || currentChar === "<") {
// 與 ; 類似只是語法單元類型不同
tokens.push({
type: "operator",
value: currentChar,
});
++current;
continue;
}
// 處理數字
if (/[0-9]/.test(currentChar)) {
let value = "";
// 當情況為 1234 這種情況時候,即將1234 看作一個整體
// 需要一直循環到最后一個數字截至
while (/[0-9]/.test(currentChar)) {
value += currentChar;
currentChar = code[++current];
}
tokens.push({
type: "number",
value: value,
});
++current;
continue;
}
// 處理字符串 也就是引號" 開頭到下一個 "結束
// 期望輸出結果 例如"aa" { type: "string", value: "\"aa\"" },
// 可以看到對結果輸出多了\ 轉義符 這就是對字符處理稍微注意地方
if (currentChar === '"' || currentChar === "'") {
let value = "";
// 保存實際對應的閉合標簽
const closeTag = currentChar;
value += currentChar;
while (currentChar !== closeTag) {
currentChar = code[++current];
value += currentChar;
}
currentChar = code[++current];
value += currentChar;
const token = {
type: "string",
value,
};
tokens.push(token);
++current;
continue;
}
if (/[a-zA-Z\$\_]/.test(currentChar)) {
// 標識符是以字母、$、_開始的
let value = "";
// 標識符是以字母、$、_開始的 和數字同理
// 即 if else for 這些
while (/[a-zA-Z\$\_]/.test(currentChar)) {
value += currentChar;
currentChar = code[++current];
}
tokens.push({
type: "identifier",
value: value,
});
++current;
continue;
}
if (/\s/.test(currentChar)) {
// let value = "";
// while (/\s/.test(currentChar)) {
// value += currentChar;
// currentChar = code[++current];
// }
// tokens.push({
// type: "whitespace",
// value: value,
// });
++current;
continue;
}
// 還可以有更多的判斷來解析其他類型的語法單元
// 遇到其他情況就拋出異常表示無法理解遇到的字符
throw new Error("Unexpected " + currentChar);
}
return tokens;
}
const code = `
if (1 > 0) {
alert("aaaa");
}
`;
console.log(tokenizeCode(code));
~~~
* 打印結果
~~~
1.像 const if 這種等 這種沒有雙引號包裹的,因此可以我們理解為是變量名或者系統關鍵字,即
屬于'標識符'(可以看上面案對標識符說明)
~~~
~~~
[
{ type: 'identifier', value: 'if' },
{ type: 'parens', value: '(' },
{ type: 'number', value: '1' },
{ type: 'operator', value: '>' },
{ type: 'number', value: '0' },
{ type: 'brace', value: '{' },
{ type: 'identifier', value: 'alert' },
{ type: 'string', value: '"a' },
{ type: 'identifier', value: 'aaa' },
{ type: 'parens', value: ')' },
{ type: 'sep', value: ';' },
{ type: 'brace', value: '}' }
]
~~~
>[info] ## 文章內容參考來源
[Rebuilding Babel: The Tokenizer](https://www.nan.fyi/tokenizer)
https://github.com/narendrasss/compiler/blob/main/src/tokenizer.ts
[MOOC編譯原理](https://www.icourse163.org/course/HIT-1002123007?tid=1467039443)
[Babel是如何讀懂JS代碼的
](https://zhuanlan.zhihu.com/p/27289600)[Reading Code Right, With Some Help From The Lexer](https://medium.com/basecs/reading-code-right-with-some-help-from-the-lexer-63d0be3d21d)
https://github.com/YongzeYao/the-super-tiny-compiler-CN/blob/master/the-super-tiny-compiler.js
- 工程化 -- Node
- vscode -- 插件
- vscode -- 代碼片段
- 前端學會調試
- 谷歌瀏覽器調試技巧
- 權限驗證
- 包管理工具 -- npm
- 常見的 npm ci 指令
- npm -- npm install安裝包
- npm -- package.json
- npm -- 查看包版本信息
- npm - package-lock.json
- npm -- node_modules 層級
- npm -- 依賴包規則
- npm -- install 安裝流程
- npx
- npm -- 發布自己的包
- 包管理工具 -- pnpm
- 模擬數據 -- Mock
- 頁面渲染
- 渲染分析
- core.js && babel
- core.js -- 到底是什么
- 編譯器那些術語
- 詞法解析 -- tokenize
- 語法解析 -- ast
- 遍歷節點 -- traverser
- 轉換階段、生成階段略
- babel
- babel -- 初步上手之了解
- babel -- 初步上手之各種配置(preset-env)
- babel -- 初步上手之各種配置@babel/helpers
- babel -- 初步上手之各種配置@babel/runtime
- babel -- 初步上手之各種配置@babel/plugin-transform-runtime
- babel -- 初步上手之各種配置(babel-polyfills )(未來)
- babel -- 初步上手之各種配置 polyfill-service
- babel -- 初步上手之各種配置(@babel/polyfill )(過去式)
- babel -- 總結
- 各種工具
- 前端 -- 工程化
- 了解 -- Yeoman
- 使用 -- Yeoman
- 了解 -- Plop
- node cli -- 開發自己的腳手架工具
- 自動化構建工具
- Gulp
- 模塊化打包工具為什么出現
- 模塊化打包工具(新) -- webpack
- 簡單使用 -- webpack
- 了解配置 -- webpack.config.js
- webpack -- loader 淺解
- loader -- 配置css模塊解析
- loader -- 圖片和字體(4.x)
- loader -- 圖片和字體(5.x)
- loader -- 圖片優化loader
- loader -- 配置解析js/ts
- webpack -- plugins 淺解
- eslit
- plugins -- CleanWebpackPlugin(4.x)
- plugins -- CleanWebpackPlugin(5.x)
- plugin -- HtmlWebpackPlugin
- plugin -- DefinePlugin 注入全局成員
- webapck -- 模塊解析配置
- webpack -- 文件指紋了解
- webpack -- 開發環境運行構建
- webpack -- 項目環境劃分
- 模塊化打包工具 -- webpack
- webpack -- 打包文件是個啥
- webpack -- 基礎配置項用法
- webpack4.x系列學習
- webpack -- 常見loader加載器
- webpack -- 移動端px轉rem處理
- 開發一個自己loader
- webpack -- plugin插件
- webpack -- 文件指紋
- webpack -- 壓縮css和html構建
- webpack -- 清里構建包
- webpack -- 復制靜態文件
- webpack -- 自定義插件
- wepack -- 關于靜態資源內聯
- webpack -- source map 對照包
- webpack -- 環境劃分構建
- webpack -- 項目構建控制臺輸出
- webpack -- 項目分析
- webpack -- 編譯提速優護體積
- 提速 -- 編譯階段
- webpack -- 項目優化
- webpack -- DefinePlugin 注入全局成員
- webpack -- 代碼分割
- webpack -- 頁面資源提取
- webpack -- import按需引入
- webpack -- 搖樹
- webpack -- 多頁面打包
- webpack -- eslint
- webpack -- srr打包后續看
- webpack -- 構建一個自己的配置后續看
- webpack -- 打包組件和基礎庫
- webpack -- 源碼
- webpack -- 啟動都做了什么
- webpack -- cli做了什么
- webpack - 5
- 模塊化打包工具 -- Rollup
- 工程化搭建代碼規范
- 規范化標準--Eslint
- eslint -- 擴展配置
- eslint -- 指令
- eslint -- vscode
- eslint -- 原理
- Prettier -- 格式化代碼工具
- EditorConfig -- 編輯器編碼風格
- 檢查提交代碼是否符合檢查配置
- 整體流程總結
- 微前端
- single-spa
- 簡單上手 -- single-spa
- 快速理解systemjs
- single-sap 不使用systemjs
- monorepo -- 工程
- Vue -- 響應式了解
- Vue2.x -- 源碼分析
- 發布訂閱和觀察者模式
- 簡單 -- 了解響應式模型(一)
- 簡單 -- 了解響應式模型(二)
- 簡單 --了解虛擬DOM(一)
- 簡單 --了解虛擬DOM(二)
- 簡單 --了解diff算法
- 簡單 --了解nextick
- Snabbdom -- 理解虛擬dom和diff算法
- Snabbdom -- h函數
- Snabbdom - Vnode 函數
- Snabbdom -- init 函數
- Snabbdom -- patch 函數
- 手寫 -- 虛擬dom渲染
- Vue -- minVue
- vue3.x -- 源碼分析
- 分析 -- reactivity
- 好文
- grpc -- 瀏覽器使用gRPC
- grcp-web -- 案例
- 待續