
## **Path Mapper**
數據結構編輯器,GH當中,最強的數據結構處理運算器,沒有之一。可以做很多事情。我們可以直接右鍵點擊,選擇一些已經預設好的功能。

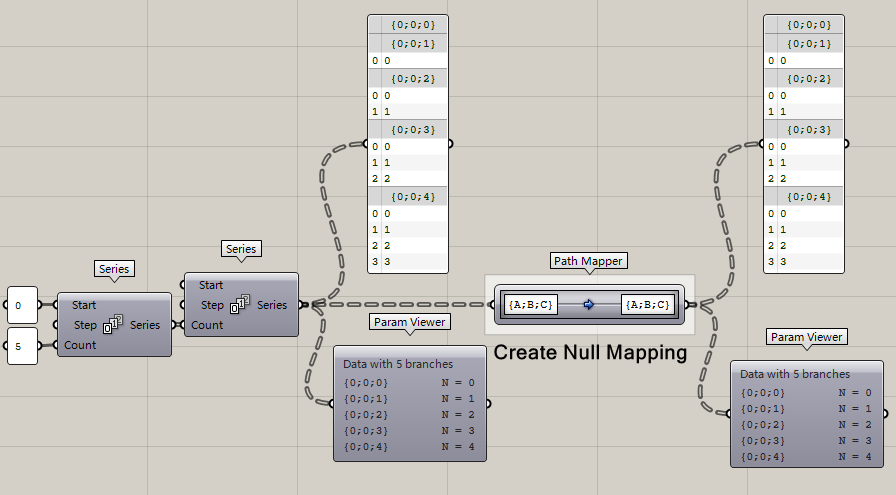
**Create Null Mapping**
NUll嘛,自然就是什么都不操作唄,之前什么樣,之后還什么樣。但是你可以看到Path Mapper運算器上顯示了文字{A;B;C},而這個就是輸入端的數據結構格式。意思是有三級路徑,只不過實際上前兩組是冗余的{0;0}。
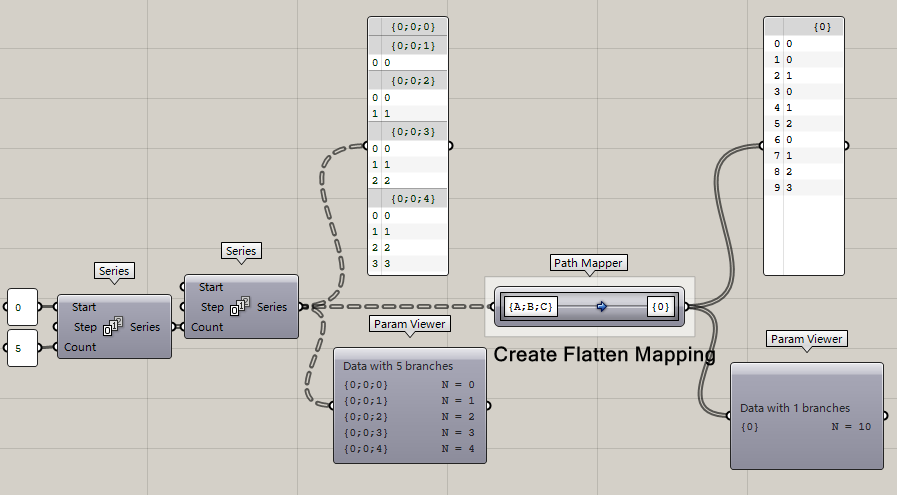
**Create Flatten Mapping**
即我們前面剛講的運算器flatten,flatten的本質嘛,不就是砍掉所有數據結構,把所有數據按順序放在{0}或者你指定的其他路徑內嘛,所以你學了path mapper應該是對數據結構有了更深的理解。
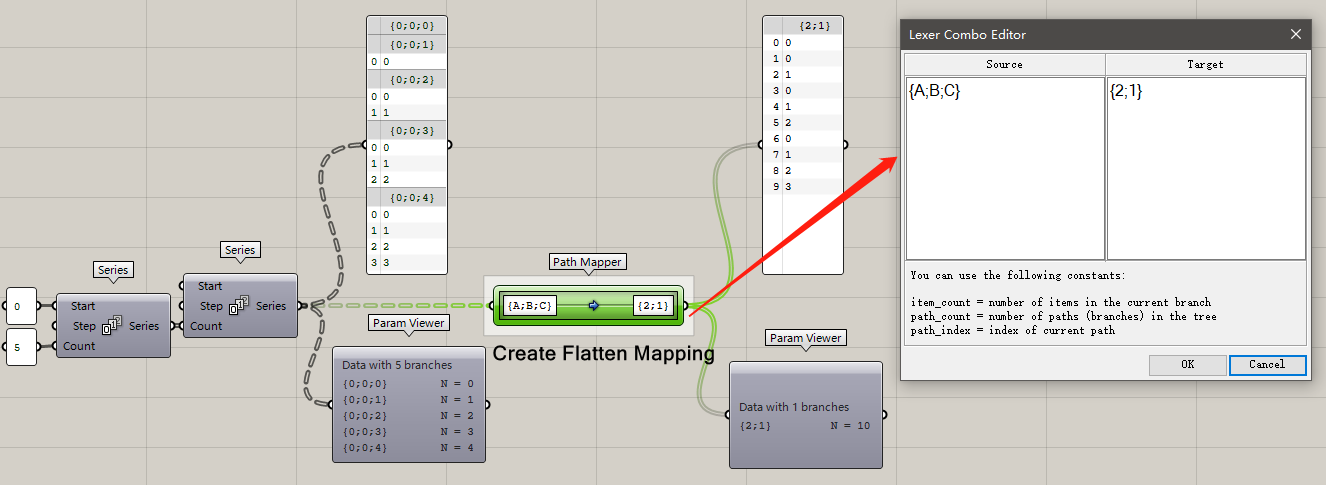
所以這時你完全可以雙擊path mapper打開編輯窗口,修改Target路徑名稱,想怎么改就怎么改。
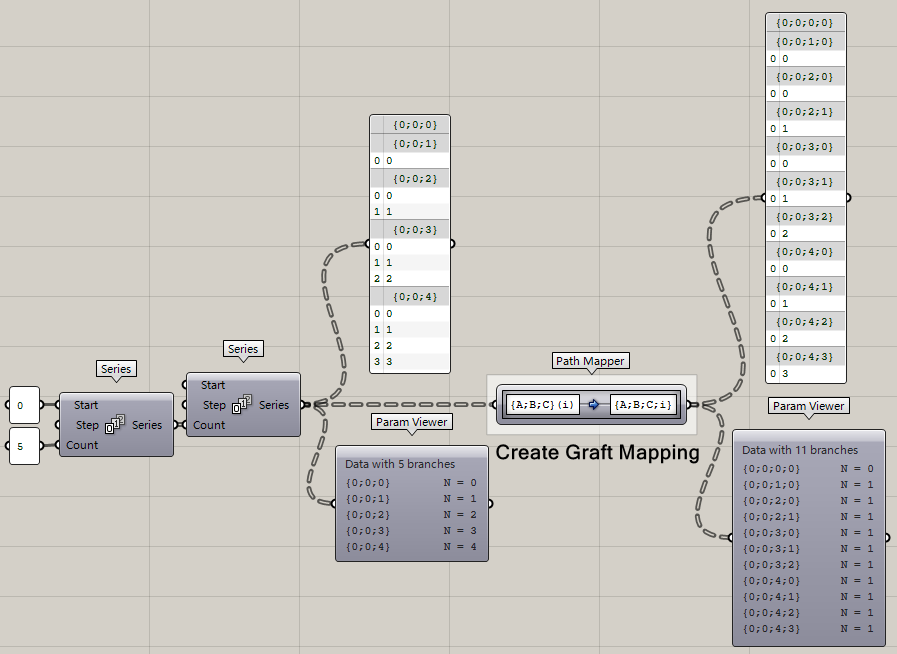
**Creat Graft Mapping**
即Graft,給數據單獨成組,那你可以看到,Path Mapper上顯示{A;B;C}(i)到{A;B;C;i},也就是說,本來三級路徑,i是數據個數,現在,編程四級數據,多了一級“i”,也就是根據數據個數,再分組。這就是Graft的本質。
**Create Trim Mapping?**
即,Trim Tree,修剪數據,網上砍了一級,Path Mapper上顯示{A;B;C}到{A;B},C哪去了?被砍了唄,所以C級路徑上的所有數據都被放到{0;0}里了,而{0;0}本身只有一支,所以所有數據都被放到一起了。
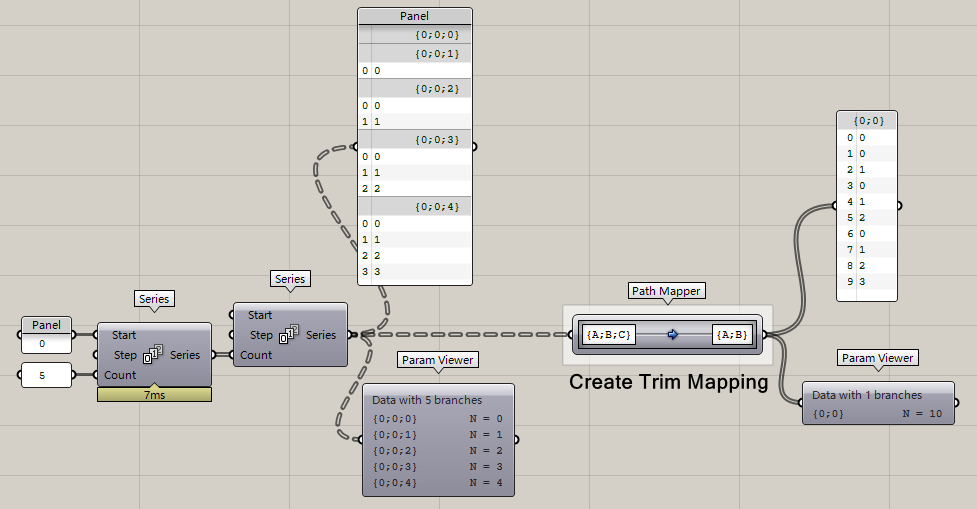
那要是想砍兩級咧?簡單:
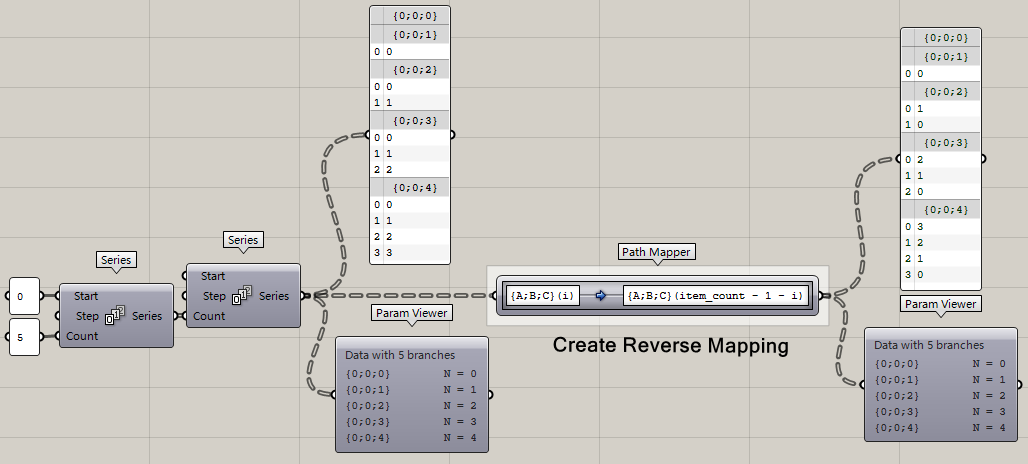
**Create Reverse Mapping**
即運算器revers list,翻轉數列,不就是把前面的數據放到后面,后面的放到前面,所以你可以看到path mapper變成了,{A;B;C}(i)到{A;B;C}(item\_count - 1 - i),而item\_count就是用來求列表長度的,-1是因為列表從0開始計數,-i那就是翻轉數列咧~是不是清晰了呢~?
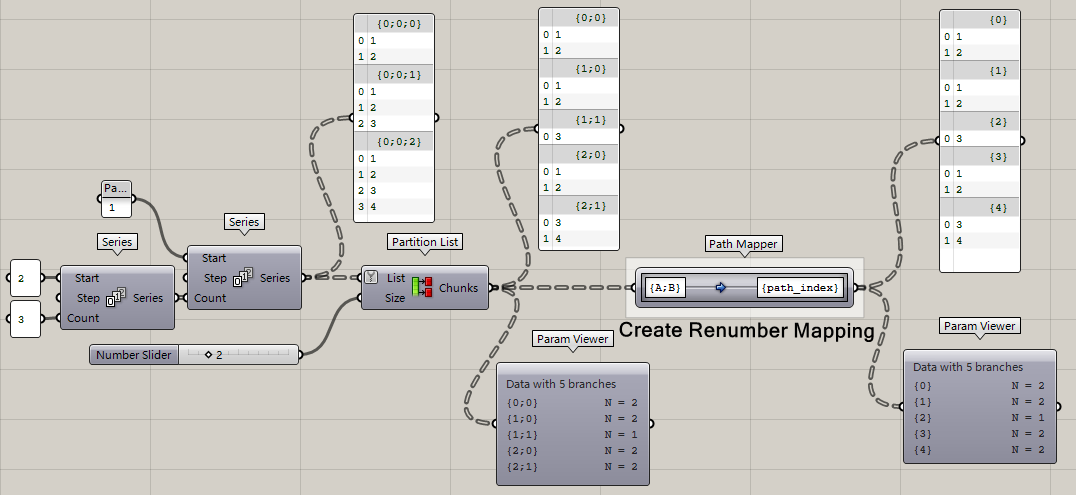
**Create Renumber Mapping**
無視原數據結構分級,講所有數據結構分支逐個排列。管你之前十幾大組幾小組,現在統統01234挨個排列數據結構。而這里的path\_index,其實就是用路徑名稱的序號來代替原數據結構。
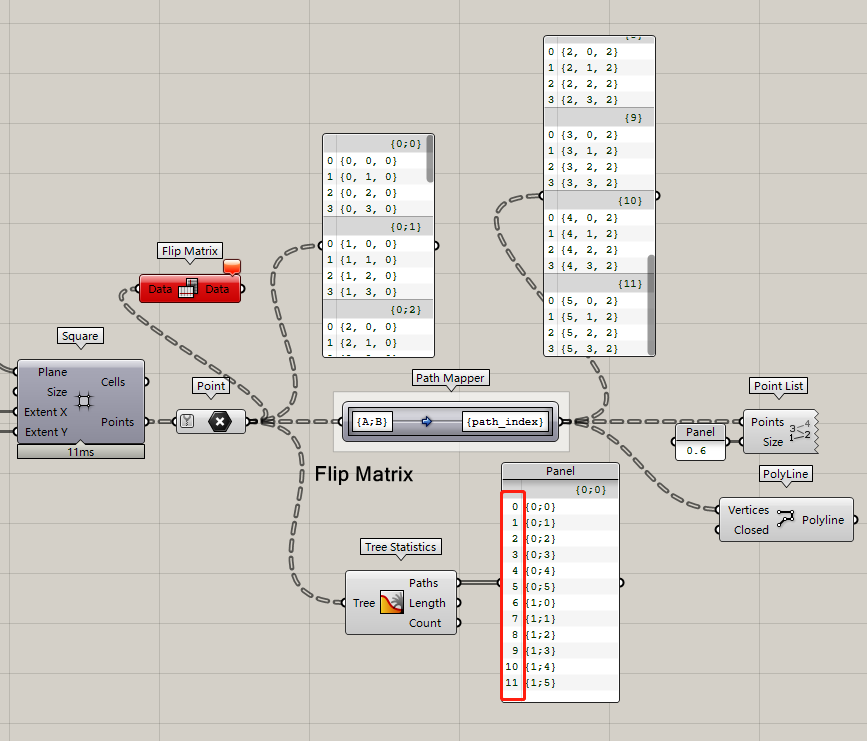
經過上面的默認功能的介紹,相信你已經知道Path Mapper是一個多么強大的運算器了,別急,還沒結束,我們再來看看path mapper還可以干什么~比如:
{A}(i)-{i}(A),就是flip matrix,翻轉數據結構的本質。
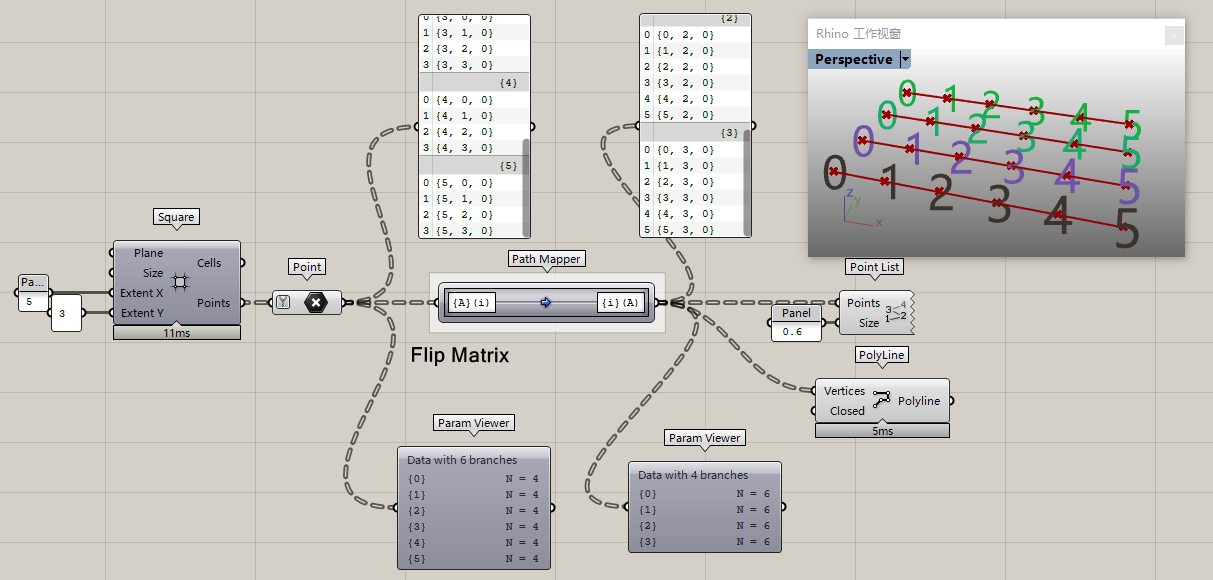
ok~升級一下難度~變成三組數據結構,這時候flip matrix就失效了,flip matrix處理不了復雜數據結構,這時候你就必須依賴Path mapper了。
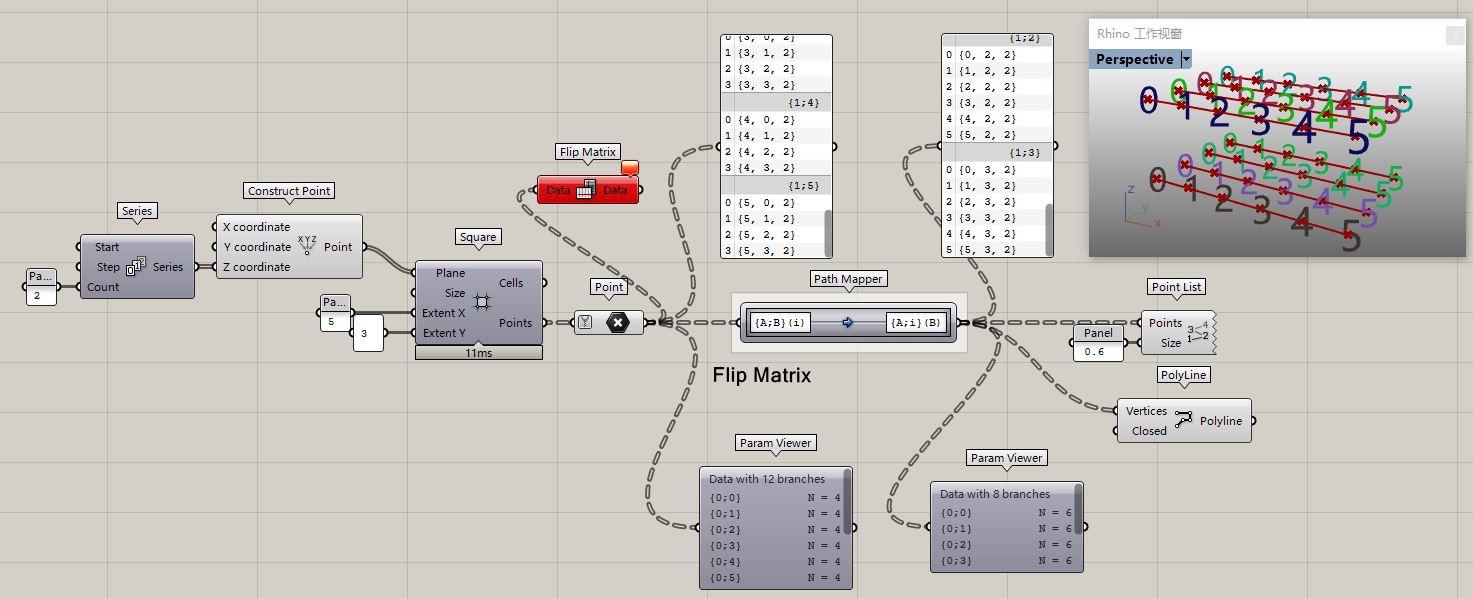
你也可以~再進一步~使得上下可以連線。總之,你可以隨心所欲的修改其分組方式。
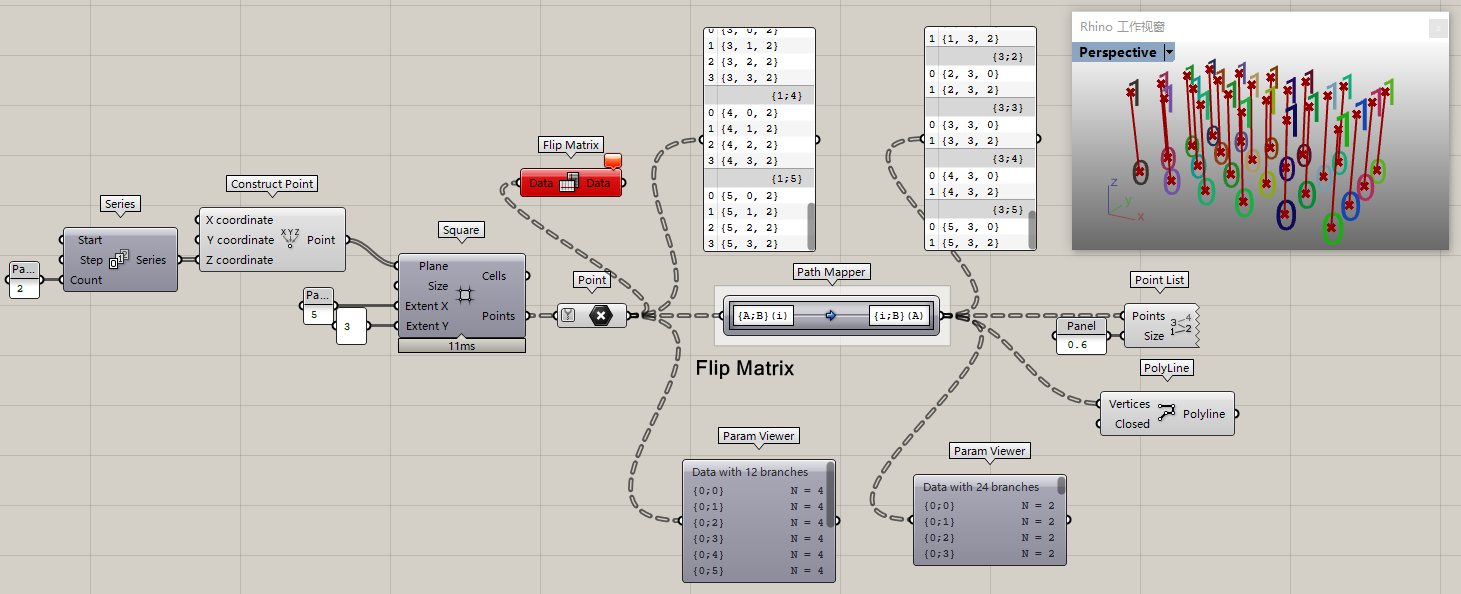
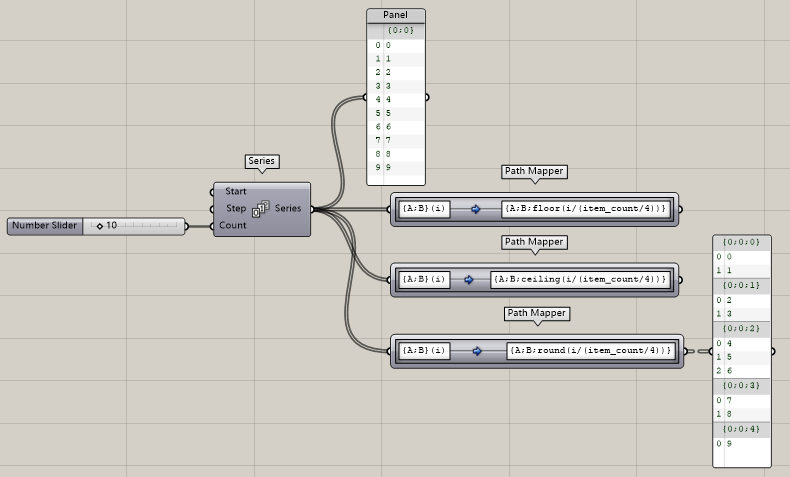
再比如呢:{A;B}(i)--{A;B;floor(i/(item\_count/4))},把數據分成四組,不論數據到底有多少個,統統分成四組。不過我估計大家會有點迷糊,看不大懂是什么意思,沒事,我來給大家解讀一下。
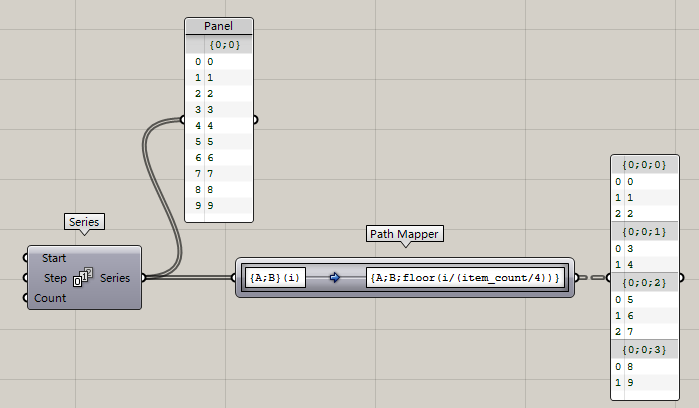?首先,你在輸入的時候不要使用中文輸入法,可能會出錯,然后呢,我們來看item\_count求得就是當前分支內list的數量,求出來應該是10,因為咱們之前的series等差數列總共就十個數嘛,然后/4,這里需要注意一下“/”“\\”這倆是不一樣的,區別就是:

所以在使用的時候千萬別用錯了。所以item\_count求出10再除以4得到2.5,然后是i/(item\_count/4),那么我們知道,i其實是list里的序號,那我們簡單列舉幾個你就知道了,
i=0也就是序號為0的時候,0/2.5=0
i=1也就是序號為1的時候,1/2.5=0.4
i=2也就是序號為2的時候,2/2.5=0.8
i=3也就是序號為3的時候,3/2.5=1.2
i=4也就是序號為4的時候,4/2.5=1.6
i=5也就是序號為5的時候,5/2.5=2
i=6也就是序號為5的時候,6/2.5=2.4
......
依次類推,會得到十個值是不,那再看前面還有一個flooor(x)的函數,這是啥?其實你之前就接觸過,簡單說,就是返回不大于x的最大的整數。

所以呢
i=0也就是序號為0的時候,floor(0/2.5)=0
i=1也就是序號為1的時候,floor(1/2.5)=0
i=2也就是序號為2的時候,floor(2/2.5)=0
i=3也就是序號為3的時候,floor(3/2.5)=1
i=4也就是序號為4的時候,floor(4/2.5)=1
i=5也就是序號為5的時候,floor(5/2.5)=2
i=6也就是序號為6的時候,floor(6/2.5)=2
......
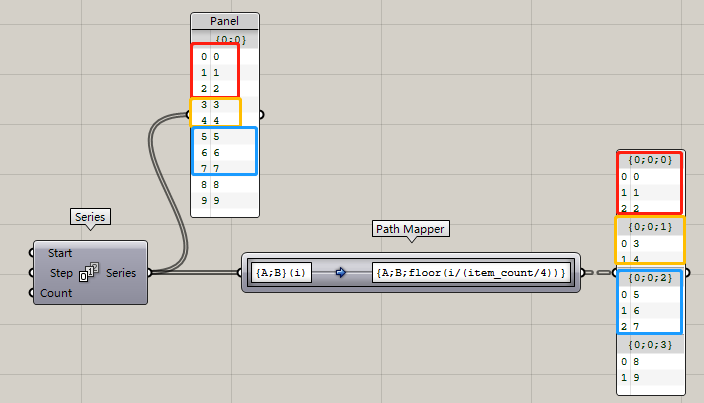
懂了不~這樣就把整個列表分成了四組,自動去求每一個數據該分到哪一組,所以才會有上圖這樣每組數量還不一樣的情況出現。但是不論你數據量是多少,永遠給你分成四組。
所以,拓展一下,如果你改成ceiling(x)會怎么樣?
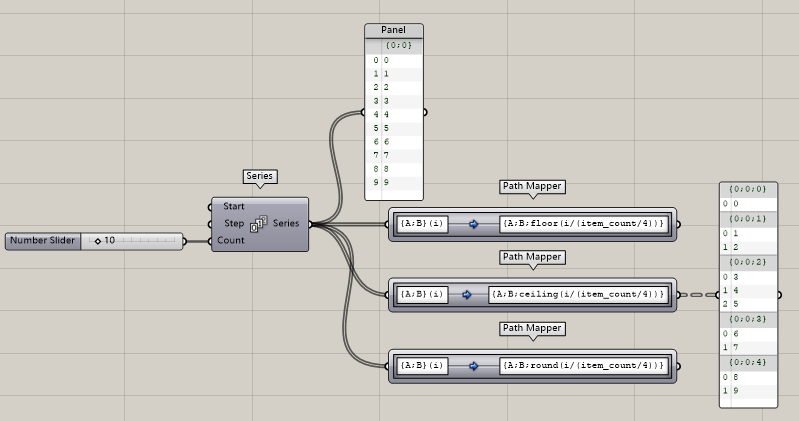
那,如果是四舍五入的round(x)呢?不過比較尷尬的是沒有輸入端,如果我想改組數我還得雙擊進來改,而不能和slider等運算器聯動。
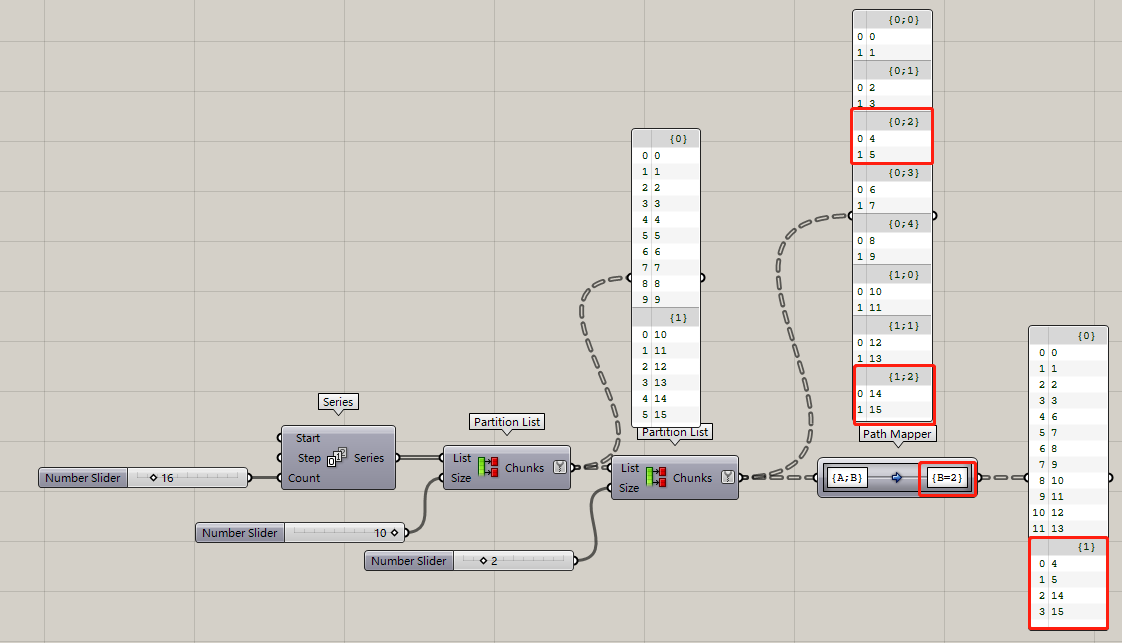
所以,path mapper是一個自由度很大的數據結構處理運算器。再比如把所有B級路徑=2的數據支分到一組,其余的分到另一組:
再比如,講數據結構兩兩合并

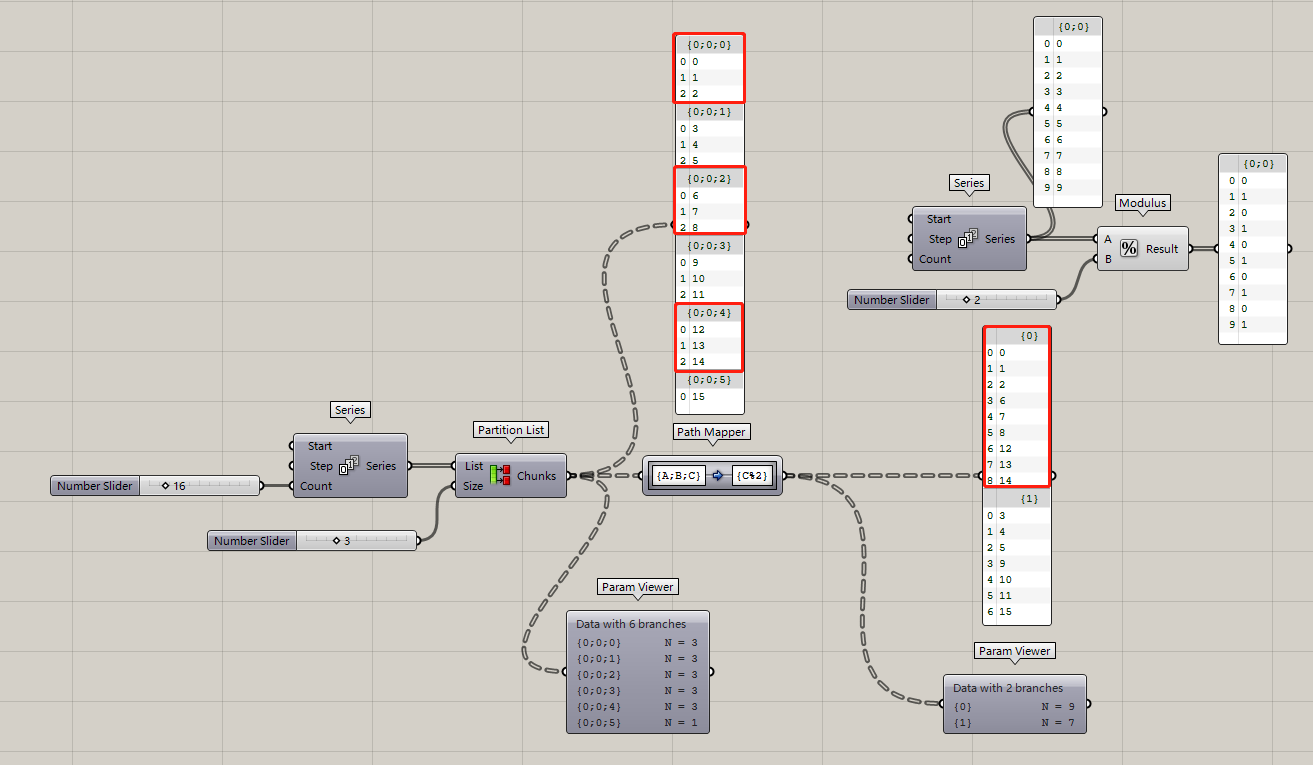
再比如,講列表中的數據兩兩分組,作用上等于Partition List。

再比如,講數據結構按照奇偶的路徑分成兩組數據。
翻轉數據結構:
諸如此類,用法其實很多,完全看你需要,單單這一個運算器我們就已經說的足夠多了,雖然即便如此還沒有全部囊括,有時間遇到了再補充吧, 不過好處是,大部分情況下,你都不會遇到這么復雜的數據處理的情況,但是這個東西對于幫助你理解數據結構來說還是很有用的。
* * *
- 前言
- 關于犀流堂
- 犀流研習班二十三期寒假班
- 往期學員評價
- Params
- Geometry
- Point
- Vector
- Circle
- Circular Arc
- Curve
- Line
- Plane
- Rectangle
- Box
- Brep
- Mesh
- Mesh Face
- PlanktonMesh
- Surface
- Twisted Box
- Field
- Geometry
- Geometry Cache
- Geometry Pipeline
- Group
- Transform
- SubD
- Primitive
- Boolean
- Integer
- Number
- Text
- Colour
- Complex
- Culture
- Domain
- Domian2
- Guid
- Matrix
- Time
- Data
- Data Path
- File Path
- Shader
- Input
- Slider
- Panel
- Boolean Toggle
- Button
- Control Knob
- Digit Scroller
- MD slider
- Value List
- Calendar
- Clock
- Colour Pick
- Colour Swatch
- Colour Wheel
- Gradient
- Graph Mapper
- Image Sampler
- File +Import PDB+Atom Data
- Import 3DM
- Import Coordinates
- Import Image
- Import Shp
- Object Details
- Read File
- Util
- Bifocals
- Cherry Picker
- Jump
- Param Viewer
- Scribble
- Data Dam
- Data Recorder
- Relay
- Suirify
- Timer
- Cluster Input & Cluster Output
- Data Input & Data Output
- Fitness Landscape
- Gene Pool & Galapagos
- Grasshopper Player運算器組
- Maths
- Domain
- Construct Domain
- Deconstruct Domain
- Bounds
- Consecutive Domains
- Divide Domain
- Find Domain
- Includes
- Remap Numbers
- Construct Domian2
- Deconstruct Domain2
- Bounds 2D
- Divide Domain2
- Matrix
- Operators
- Addition
- Division
- Multiplication
- Negative
- Power
- Subtraction
- Absolute
- Factorial
- Integer Division
- Modulus
- Mass Addition
- Mass Multiplication
- Relative Differences
- Equality
- Larger Than
- Similarity
- Smalller Than
- Gate And+Not+Or+Xor
- Gate Majority+Nand+Nor+Xnor
- Polynomials
- Cube & Cube Root
- Square & Square Root
- One Over X
- Power
- Power of 2
- Power of e
- Log N & Logarithm &Natrue Logarithm
- Script
- Evaluate
- Expression
- C# & VB & Python
- Time
- Construct Date
- Construct Exotic Date
- Construct Smooth Time
- Construct Time
- Deconstruct Date
- Combine Date & Time
- Date Range
- Interpolate Date
- Trig
- Cosine & Sinc & Sine & Tangent
- ArcCosine & ArcSine & ArcTangent & CoSecant & CoTangent &Secant
- Degrees & Radians
- Right Trigonometry & Triangle Trigonometry
- Centroid
- Circumcentre
- Incentre
- Orthocentre
- Util
- Epsilon & Golden Ratio & Natural logarithm & Pi
- Extremes
- Maximum & Minimum
- Round
- Average
- Blur Numbers
- Interpolate data
- Smooth Numbers
- Truncate
- Weighted Average
- Complex
- Sets
- List
- Insert Items
- Item Index
- List Item
- List Length
- Partition List
- Replace Items
- Reverse List
- Shift List
- Sort List
- Split list
- Sub List
- Dispatch
- Null Item
- Pick'n'Choose
- Replace Nulls
- Weave
- Combine Data
- Sift Pattern
- Cross Reference
- Longest List
- Shortest List
- Sequence
- Cull Index
- Cull Nth
- Cull Pattern
- Random Reduce
- Char Sequence
- Duplicate Data
- Fibonacci
- Range
- Repeat Data
- Sequence
- Series
- Stack Data
- Jitter
- Random
- Sets
- Create Set
- Set Difference
- Set Difference(s)
- Set Intersection
- Set Majority
- Set Union
- Carthesian Product
- Disjoint
- Member Index
- Replace Members
- SubSet
- Delete Consecutive
- Find similar member
- Key/Value Search
- Text
- Characters
- Concatenate
- Text Join
- Text Length
- Text Split
- Format
- Text Case
- Text Fragment
- Text Trim
- Match Text
- Replace Text
- Sort Text
- Text Distance
- Tree
- Clean Tree
- Flatten Tree
- Graft Tree
- Prune Tree
- Simplify tree
- Tree Statistics
- Trim Tree
- Unflatten Tree
- Entwine
- Explode Tree
- Flip Matrix
- Merge
- Match Tree
- Path Mapper
- Shift Paths
- Split Tree
- Stream Filter
- Stream Gate
- Relative Item
- Relative Items
- Tree Branch
- Tree Item
- Deconstruct Path&Construct Path
- Path Compare
- Replace Paths
- Vector
- Field
- Line Charge & Tensor Display
- Point Charge & Scalar Display
- Spin Force
- Vector Force
- Merge Fields & Break Field
- Evaluate Field
- Field Line
- Perpendicular Display
- Scalar Display
- direction display
- Grid
- Hexagonal
- Radial
- Rectangular
- Square
- Triangular
- Populate 2D
- Populate 3D
- Populate Geometry
- Plane
- Deconstruct Plane
- XY plane & XZPlane & YZ Plane
- Construct Plane
- Line + Line
- Line + Pt
- Plane 3Pt
- Plane Fit
- Plane Normal
- Plane Offset
- Plane Origin
- Adjust Plane
- Align Plane
- Align Planes
- Flip Plane
- Plane Closest Point
- Plane Coordinates
- Rotate Plane
- Point
- Construct Point & Deconstruct
- Numbers to Points
- Points to Numbers
- Barycentric
- Distance
- Point Cylindrical
- Point Oriented
- Point Polar
- To Polar
- Closest Point
- Closest Points
- Cull Duplicates
- Point Groups
- Project Point
- Pull Point
- Sort Along Curve
- Sort Points
- Vector
- Deconstruct Vector
- Vector XYZ
- Unit Vector
- Unit X Y Z
- Amplitude
- Angle
- Cross Product
- Dot Product
- Reverse
- Rotate
- Vector 2Pt
- Vector Length
- Curve
- Analysis
- Control Points
- Curve Middle
- Control Polygon
- Deconstruct Arc
- Deconstuct Rectangle
- End Points
- Polygon Center
- Closed
- Curvature Graph
- Curve Closest Point
- Curve Nearest Object
- Curve Proximity
- Curve Side
- Discontinuity
- Extremes
- Planar
- Curvature
- Curve Frame
- Derivatives
- Evaluate Curve
- Horizontal Frame
- Perp Frame
- Point On Curve
- Torsion
- Curve Domain
- Evaluate Length
- Length
- Length Domain
- Length Parameter
- Segment Lengths
- Point In Curve
- Point in Curves
- Division
- Contour
- Contour (ex)
- Dash Pattern
- Divide Curve
- Divide Distance
- Divide Length
- Shatter
- Curve Frames
- Horizontal Frames
- Perp Frames
- Primitive
- Fit Line
- Line
- Line 2Plane
- Line 4Pt
- Line SDL
- Tangent Lines
- Tangent Lines (Ex)
- Tangent Lines (In)
- Circle
- Circle 3Pt
- Circle CNR
- Circle Fit
- Circle TanTan
- Circle TanTanTan
- Ellipse
- InCircle
- InEllipse
- Arc
- Arc 3Pt
- Arc SED
- BiArc
- Modified Arc
- Tangent Arcs
- Polygon
- Polygon Edge
- Rectangle
- Rectangle 2Pt
- Rectangle 3Pt
- Spline
- Bezier Span
- Interpolate
- Interpolate (t)
- Kinky Curve
- Nurbs Curve
- PolyArc
- PolyLine
- Tangent Curve
- Curve On Surface
- Geodesic
- Iso Curve
- Sub Curve
- Tween Curve
- Knot Vector & Nurbs Curve PWK
- Blend Curve
- Blend Curve Pt
- Catenary
- Connect Curves
- Util
- Explode & Join
- Extend Curve
- Flip Curve
- Shortest Walk
- Fillet(t)
- Fillet
- Fillet Distance
- Offset Curve
- Offset Curve Loose
- Offset on Srf
- Project
- Pull Curve
- Seam
- Curve To Polyline
- Fit Curve
- Polyline Collapse
- Rebuild Curve
- Reduce
- Simplify Curve
- Smooth Polyline
- Surface
- Analysis
- Box Corners
- Box Properties
- Deconstruct Box
- Evaluate Box
- Brep Edges
- Brep Topology
- Brep Wireframe
- Deconstruct Brep
- Dimensions
- Is Planar
- Surface Points
- Area
- Area Moments
- Volume
- Brep Closest Point
- Surface Closest Point & Evaluate Surface
- Point In Brep
- Point In Breps
- Point In Trim
- Shape In Brep
- Osculating Circles
- Principal Curvature
- Surface Curvature
- Volume Moments
- Freeform
- 4Point Surface
- Surface From Points
- Boundary Surfaces
- Control Point Loft
- Edge Surface
- Fit Loft
- Loft & Loft Options
- Network Surface
- Ruled Surface
- Sum Surface
- Extrude
- Extrude Along
- Extrude Linear
- Extrude Point
- Fragment Patch
- Patch
- Pipe
- Pipe Variable
- Sweep1
- Sweep2
- Rail Revolution
- Revolution
- Primitive
- Plane Surface
- Plane Through Shape
- Bounding Box
- Box 2Pt
- Box Rectangle
- Center Box
- Domain Box
- Cone
- Cylinder
- Quad Sphere
- Sphere
- Sphere 4Pt
- Sphere Fit
- Util
- Divide Surface
- Surface Frames
- Copy Trim
- Isotrim
- Retrim
- Untrim
- Brep Join
- Cap Holes
- Cap Holes Ex
- Merge Faces
- Flip
- Offset Surface
- Offset Surface Loose
- Convex Edges
- Edges from Directions
- Edges from Linearity
- Edges from Points
- Fillet Edge
- Edges from Faces
- Edges from Length
- Subd
- Mesh from SubD
- SubD from Mesh
- MultiPipe
- SubD Control Polygon
- SubD Edges
- SubD Fuse
- SubD Edge Tags
- Mesh
- Analysis
- Deconstruct Mesh & Face
- Face Normals
- Mesh Edges
- Mesh ConvertQuads & Mesh Explode
- Mesh Triangulate
- Face Circles
- Face Boundaries
- Mesh Inclusion
- Mesh Area
- Mesh Closest Point & Mesh Eval
- Mesh NakedEdge
- Mesh Volume
- Mesh AddAttributes & Mesh ExtractAttributes
- Primitive
- Construct Mesh & Mesh Quad
- Mesh Colours
- Mesh Spray
- Mesh Triangle
- Mesh Box
- Mesh Pipe
- Mesh Plane
- Mesh Sphere
- Mesh Sphere Ex
- Mesh Sweep
- Triangulation
- Convex Hull
- PlanktonFromPoints & DeconstructPlankton
- Delaunay Edges
- Delaunay Mesh
- Substrate
- Facet Dome
- Voronoi
- Voronoi 3D
- Voronoi Cell
- Voronoi Groups
- OcTree
- Proximity 2D
- Proximity 3D
- QuadTree
- MetaBall
- MetaBall(t)
- MetaBall(t) Custom
- 3D ConvexHull
- 3D Delaunay
- 3D Voronoi
- Convex Hull Points
- TriRemesh
- Quad Remesh & Settings
- Util
- Mesh Brep & Settings (Custom)
- Settings(Speed)& Settings(quality)
- Mesh FromPoints
- Mesh Surface
- Simple Mesh
- Blur Mesh
- Cull Faces
- Cull Vertices
- Delete Faces
- Delete Vertices
- Mesh Join & Disjoint Mesh
- Mesh Shadow
- Mesh Split Plane
- Smooth Mesh
- Align Vertices
- Flip Mesh
- Mesh CullUnused Vertices
- Mesh Flip
- Mesh UnifyNormals
- Mesh WeldVertices
- Quadrangulate
- Triangulate
- Unweld Mesh & Weld Mesh
- Exposure
- Occlusion
- Intersect
- Mathematical
- Brep / Line
- Curve / Line
- Line / Line
- Mesh / Ray
- Surface / Line
- Brep / Plane
- Contour
- Contour (ex)
- Curve / Plane
- Line / Plane
- Mesh / Plane
- Plane / Plane
- Plane / Plane / Plane
- Plane Region
- IsoVist
- IsoVist Ray
- Physical
- Curve / Curve
- Curve / Self
- Multiple Curves
- Multiple Curves
- Brep / Brep
- Brep / Curve
- Surface / Curve
- Surface Split
- Mesh / Curve
- Mesh / Mesh
- Collision Many/Many
- Collision One/Many
- Region
- Split with Brep
- Split with Breps
- Trim with Brep
- Trim with Breps
- Trim with Region
- Trim with Regions
- Shape
- Boundary Volume
- Solid Difference
- Solid Intersection
- Solid Union
- Split Brep
- Trim Solid
- Region Difference
- Region Intersection
- Region Union
- Mesh Difference
- Mesh Intersection
- Mesh Split
- Mesh Union
- Box Slits
- Region Slits
- Split Brep Multiple
- Transform
- Affine
- Camera Obscura
- Scale
- Scale NU
- Shear
- Shear Angle
- Box Mapping
- Orient Direction
- Project
- Project Along
- Rectangle Mapping
- Triangle Mapping
- Array
- Box Array
- Curve Array
- Linear Array
- Polar Array
- Rectangular Array
- Kaleidoscope
- Euclidean
- Mirror
- Move
- Move Away From
- Move To Plane
- Orient
- Rotate
- Rotate 3D
- Rotate Axis
- Rotate Direction
- Morph
- Blend Box
- Surface Box & Box Morph
- Twisted Box
- Bend Deform
- Flow
- Maelstrom
- Mirror Curve
- Mirror Surface
- Splop
- Sporph
- Stretch
- Surface Morph
- Taper
- Twist
- Map to Surface
- Point Deform
- Spatial Deform
- Spatial Deform (custom)
- Util
- Compound & Transform
- Inverse Transform
- Split
- Transform Matrix
- Group & Ungroup
- Merge Group
- Split Group
- Display
- Colour
- Colour CMYK
- Colour HSL
- Colour HSV
- Colour L*ab
- Colour LCH
- Colour RGB
- Colour RGB (f)
- Split AHSL & Split AHSV & Split ARGB
- Colour XYZ
- Dimensions
- Text Tag
- Text Tag 3D
- Aligned Dimension
- Line Dimension
- Linear Dimension
- Marker Dimension
- Serial Dimension
- Angular Dimension
- Angular Dimensions (Mesh)
- Arc Dimension
- Circular Dimension
- Make2D & Make2D Parallel View
- Make2D Perspective View
- Make2D Rhino View
- Graphs
- Bar Graph
- Legend
- Pie Chart
- Quick Graph
- Image Gallery
- Value Tracker
- Preview
- Create Material & Custom Preview
- Cloud Display
- Dot Display
- Symbol (Simple) & Symbol Display
- Symbol (Advanced)
- Vecor
- Point List
- Point Order
- Vector Display
- Vector Display Ex
- Kangaroo 2.0
- 日常百問
- Rhino百問
- 請問如何可以調整材質貼圖大小?如何給材質?
- Rhino可以給多重曲面中某一個面單獨賦予一個材質么?
- Rhino顯示有破面怎么辦?
- Rhino可以像Su一樣有很真實的陰影么?
- Rhino可以像Su一樣一鍵放置小人來放置視角么?
- 為什么我rhino和su一樣的模型,rhino會比su卡?
- 如何讓極地模式等顯示模式像鋼筆模式一樣顯示外輪廓?
- Rhino建方盒子建筑快么?優秀的建模習慣是什么?
- Tspline建的模型內部結構是什么樣子的?
- 曲面UV可以旋轉么?
- Rhino導出cad的自由曲線沒辦法單線變墻怎么辦?
- 請問WeaveBird如何安裝?6.0可以裝Wb么?
- Rhino顯示中如何顯示線寬?
- Rhino當中的填充圖案太少怎么辦?可以導入cad的么?
- Rhino里如何把圖片轉化成矢量線條?
- Rhino想導出DEA格式進Lumion的時候報錯,好大一個錯誤提示框為何?
- Rhino注解點可以導入CAD么?
- Rhino導出或者導入CAD文件?有什么注意事項?
- Rhino6.0可以使用weavebird么?
- rhino如何批量展開多重曲面?
- 如何在當前顯示模式下讓某個物體以其他顯示模式里顯示?
- Rhino可以像su一樣照片匹配建模么?
- 如何選中一個物件整體著色顯示,而不是只有線框顯示?
- Mesh網格的線亂七八糟的,如何可以正常顯示?只有邊線沒有內部亂七八糟的線?
- Rhino當中如何在交點處打斷線?
- 如何在著色模式里顯示物件材質?
- Rhino如何選中物體的時候全部著色顯示而不是只顯示邊線看起來比較亂?
- 為什么rhino導出的cad文件在打印時無法修改為黑色?
- 犀牛如何全屏顯示?
- Rhino布爾為什么會失敗?
- rhino和GH里調整曲線接縫點的命令是干嘛的,有什么作用?
- Rhino模型又大又卡怎么辦?
- Rhino當中的模板,單位,公差如何選擇?
- 請問我的截屏面和x y軸都不平行,還是個斜方向的,請問如何導出這個截屏面的剖面呢?
- Rhino可以和su的場景一樣同時保存圖層和視圖變化么?
- Rhino6.0的幫助文檔好卡呀,有5.0那樣的離線文檔么?
- make2d有斷線?make2d時間太長?make2d質量不高怎么辦?
- Rhino輸入命令沒有提示了是為什么?就是輸入命令不自動補全?
- Rhino可以像cad那樣修改物件顯示順序?比如我想讓一根線顯示在另一根線上?
- 請問大家在rhino里是怎么放家具的呢?比如su導入rhino有很多三角面,而且很卡?怎么做比較好?
- rhino如何設置2d樹木或者2d人面向攝像機或跟隨鏡頭一起旋轉?
- Rhino無法刪除圖層怎么辦?
- Rhino如何把建筑落到地形上?
- Rhino模型中剖面不是橫平豎直的,是帶角度的,如何讓視窗正對剖面?
- 在rhino里面直接畫線,怎么調出來像CAD那樣的十字光標?
- Rhino如何像Su一樣設置組件為唯一?
- Rhino如何出斜軸測圖?和一點北京一樣的那種?
- 可以把渲染圓管,圓角,厚度抽離成物體而不僅僅是顯示效果么?
- 犀流堂的模型都好大呀,動不動幾十兆幾百兆,這咋用呀?文件太大太卡怎么辦?
- 請問可以分享一下老師得配置文件么?
- Make2D的線稿導入CAD怎么什么都看不到??有的線還變成一段一段的直線了?
- rhino如何對圖層快速打開關閉進行一鍵操作?
- 犀牛這么好用為什么要用su?
- rhino為什么只能在xy平面畫?如何直接在面上畫線?
- Rhino如何導入Revit?
- 學建筑還有前途么?末日黃花?沒有錢途?
- Revit如何導入Rhino?
- Rhino建模時如何管理圖層?如何分圖層比較高效?
- Rhino吃什么配置?
- Tspline或者Rhino7.0的subd最終得到的造型是多重曲面,沒法曲面流動?怎么做表皮呢?
- Rhino可以像cad和su那樣指定點復制么?別原位復制粘貼。
- 如何讓倒角處能顯示邊緣線?
- Rhino如何把兩根線合并成一根線?不是組合曲線,是完整的一根線。
- “只打開一個圖層”命令每次都要點擊選取好麻煩怎么辦?
- Rhino中如何統一Mesh面法線方向?
- Rhino中如何統一曲線方向?
- 如何批量導出所有的已命名視圖?----by wucl12
- 各位有誰知道自由曲線施工時如何定位,圖紙上要怎么表達呢?
- 如何批量讓物體按照自身中心進行縮放?
- Rhino模型建好了之后如何出平立剖?
- Rhino如何刪除部分重疊的曲線?類似CAD中OverKill命令?
- 請問網格如何和曲面相交求交線?Intersect無法使用。
- Rhino如何對多個物體以其物體中心進行縮放而不發生移動?
- 為什么rhino里畫的曲線原地復制之后還有誤差?為什么不是0?
- 為什么Rhino不記錄我設置的工具列配置還有布局?
- 老師的OD顯示模式是如何設置的?
- Rhino有Su那樣的手繪草圖風格顯示模式么?
- rhino可以做轉折剖嗎?
- Rhino和GH文件無法拖入界面打開?顯示禁止符號?
- Rhino單線字體怎么用?有什么字體可以作為單線字體?
- Rhino如何按照圖層導出物件?
- 模型近處被鏡頭裁剪,模型顯示不全怎么辦?
- 老師的快捷鍵在哪里可以找到?能發一份么?
- Rhino如何像Su那樣指定兩點之間等分陣列的功能?
- rhino如何根據圖層顏色創建圖層材質?
- 如何編輯圖塊的時候自動隱藏其他物件?
- GH百問
- GH如何安裝插件?
- 如何修改數值的小數點后位數?
- 如何在一個列表中獲得指定數據的所有序號?
- 為什么我跟著教程做的網格地形無法bake?
- GH當中的科學計數法如何調整正常顯示?
- 如何像犀流堂一樣把logo導入GH當中?
- GH中如何刪除重面?
- GH中封閉路徑無法單軌掃略?
- 如何根據是否與曲線相交來對圖形分組?
- GH如何偏移多重曲面成體?以及兩側偏移?
- GH中如何根據圖片生成曲線,即矢量線條?
- 想做穿孔鋁板表皮,貼圖太假,想做實體模型太卡,怎么辦?
- 如何下載網上的地圖數據?如何生成城市建筑模型?
- 如何提取鋼結構中心線?
- GH如何做動畫?有教程么?
- 我覺得我GH學的差不多了,想接觸代碼,請問學什么代碼好?怎么學?
- gh做動畫如何切視角?
- GH中如何批量展開多重曲面?
- GH如何像rhino一樣縮回曲面?
- 請問如何像網站課程里一樣顯示運算器名稱?
- gh中把物體bake到rhino中,在rhino中處理一下,然后又拾取回來的電池,是哪個喲?
- GH中如何獲得拾取的物件的圖層名稱?
- GH如何抽取奇數列和偶數列?
- GH如何在交點處打斷線?
- GH當中可以批量進行Squish么,就是雙曲面展開?
- 請問gh中如何把曲線投影到網格上?
- GH當中如何實現Rhino當中兩個曲面之間建立均分曲面的命令?
- GH中單軌掃掠失敗,但是Rhino當中手工做卻可以成功,怎么辦?
- grasshopper怎么阻止載入某些插件?
- GH種如何bake線條顏色以及物件材質?
- GH如何刪除重復曲線?
- 如何在gh當中獲取當前日期時間
- 如何給電池設置過期時間,超過時間,電池自動作廢?
- 請問我gh里計算面積的時候顯示2.9232e+9,這是什么意思呢?可以改成正常顯示么?
- 請問有沒有offset crv on mesh這個功能呢?類似于offset crv on srf?
- 給定截面如何批量掃掠生成線腳或者說是裝飾線或者說是結構?
- 為什么GH里兩個數一摸一樣但是卻判斷不相等?
- 如何設置運算器顯示樣式,加透明度加白邊?像犀流堂視頻里一樣?
- GH種如何偏移網格成體?
- 如何學習一個新的GH插件?比如Human?Lunchbox?
- Rhino不是Nurbs軟件么,那GH中的Mesh運算器是不是對建筑沒用呀?可以不學么?
- ABC三個字母,有多少種排列組合方式?GH咋做?
- 如何統一全部曲面方向?
- GH如何創建文字線稿?3D文字?
- 請問如何把GH背景變成白色?并隱藏格線?
- GH中雙擊界面搜索輸入后沒有結果是為什么?
- 如何在GH中控制修改線的線型?
- GH有漢化么?
- 在gh中如何根據數字位數在數字前加零,比如5變成005?
- GH的C#運算器可否直接調用GH中的電池?
- Grasshopper中如何像Meshoutline命令一樣獲取當前視角的外輪廓邊緣呢?
- Grasshopper 插件安裝失敗怎么辦?
- GH中可以設置材質么?可以設置貼圖軸么?
- GH中如何延伸曲面?
- Rhino7.0當中GH里的占位電池無法刪除怎么辦?--月神
- GH中如何統一mesh網格方向
- GH中如何顯示網格Mesh的邊緣線?
- GH中電池之間連線太多,怎么樣可以快速刪除連線?批量取消運算器之間的連接?
- GH中如何沿著曲面進行陣列,即rhino中的ArrayCrvOnSrf命令
- GH如何控制Rhino中的太陽?
- GH做動畫如何實現鏡頭切換?
- Grasshopper中可以給運算器設置快捷鍵么?設置了如何保存呢?
- GH導出幀動畫如何讓背景透明?
- GH連電池的時候一卡一卡的,連一次卡一下,新建一個GH就不卡了
- 請教一下如何在不關閉犀牛的情況下重啟gh?
- GH的工作區/畫布可以變成透明么?這樣就不用開個窗口了
- 如何批量導出所有的已命名視圖?C# for gh代碼版
- gh中可以批量添加燈光么?Rhino燈光無法成圖塊怎么辦?
- GH中如何獲取多重曲面中的正切邊緣?
- GH中如何進行ArcBlend也就是弧形混接?
- Kangaroo在建筑設計上有啥具體應用呢?
- 怎么把樹形數據shift到只保留第一分支啊,就是不管是{a;b;c;d}還是{a;b;c}還是{a;b}都只保留啊{a}
- 如何用GH篩選凹多邊形?
- GH中封閉曲線,多截面雙規失敗報錯怎么辦?
- GH中著色后的mesh在bake到rhino里后無法渲染或導出后沒有顏色怎么辦?
- 如何計算一個不規則點陣的大概面積?
- GH中如何進行混接曲面?
- GH中如何自文字中篩選出來純數字?
- 其他
- 犀流堂網站的成本是多少?