
[TOC]
# 并行和并發
**并行(parallel):** 指在同一時刻,有多條指令在多個處理器上同時執行。
**并發(concurrency):** 指在同一時刻只能有一條指令執行,但多個進程指令被快速的輪換執行,使得在宏觀上具有多個進程同時執行的效果,但在微觀上并不是同時執行的,只是把時間分成若干段,使多個進程快速交替的執行。
# MMU
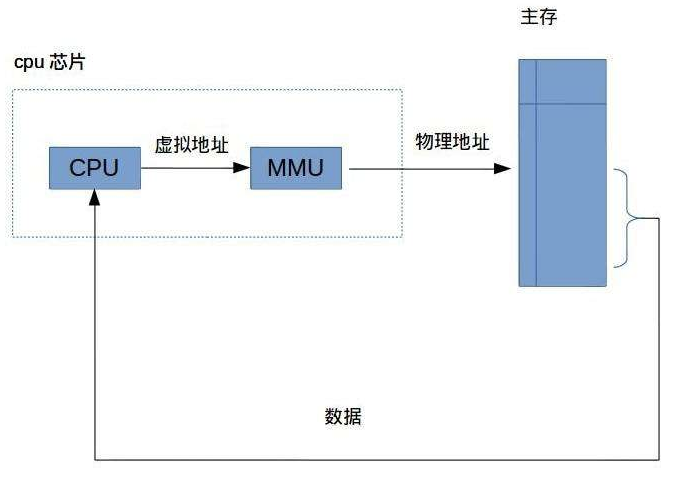
MMU是Memory Management Unit的縮寫,中文名是[內存管理](https://baike.baidu.com/item/%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86)單元,它是[中央處理器](https://baike.baidu.com/item/%E4%B8%AD%E5%A4%AE%E5%A4%84%E7%90%86%E5%99%A8)(CPU)中用來管理[虛擬存儲器](https://baike.baidu.com/item/%E8%99%9A%E6%8B%9F%E5%AD%98%E5%82%A8%E5%99%A8)、物理存儲器的控制線路,同時也負責[虛擬地址](https://baike.baidu.com/item/%E8%99%9A%E6%8B%9F%E5%9C%B0%E5%9D%80)映射為[物理地址](https://baike.baidu.com/item/%E7%89%A9%E7%90%86%E5%9C%B0%E5%9D%80),以及提供硬件機制的內存訪問授權,多用戶多進程操作系統。
# 進程控制塊PCB
進程運行時,內核為進程每個進程分配一個PCB(進程控制塊),維護進程相關的信息,Linux內核的進程控制塊是task\_struct結構體。
在 /usr/src/linux-headers-xxx/include/linux/sched.h 文件中可以查看struct task\_struct 結構體定義:
> $ cat /usr/src/linux-headers-4.10.0-28/include/linux/sched.h
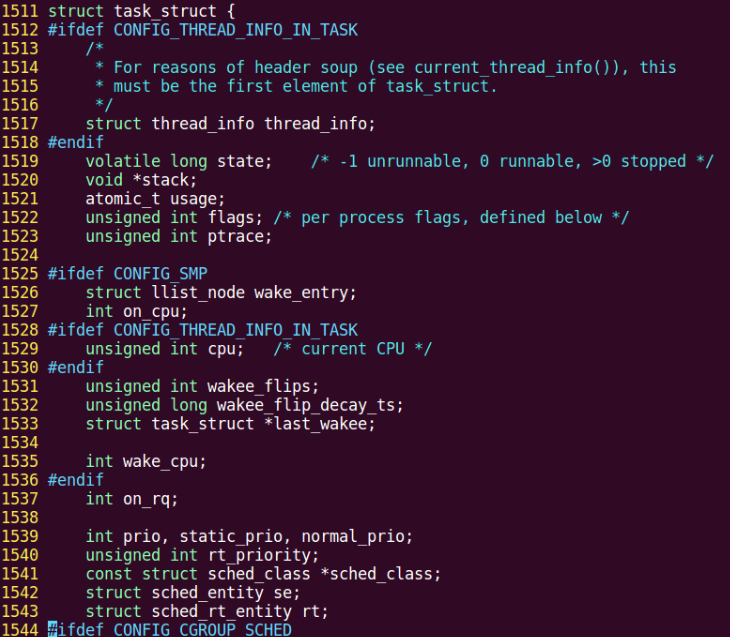
其內部成員有很多,我們掌握以下部分即可:
* 進程id。系統中每個進程有唯一的id,在C語言中用pid\_t類型表示,其實就是一個非負整數。
* 進程的狀態,有就緒、運行、掛起、停止等狀態。
* 進程切換時需要保存和恢復的一些CPU寄存器。
* 描述虛擬地址空間的信息。
* 描述控制終端的信息。
* 當前工作目錄(Current Working Directory)。
* umask掩碼。
* 文件描述符表,包含很多指向file結構體的指針。
* 和信號相關的信息。
* 用戶id和組id。
* 會話(Session)和進程組。
* 進程可以使用的資源上限(Resource Limit)
# 進程狀態
進程狀態反映進程執行過程的變化。這些狀態隨著進程的執行和外界條件的變化而轉換。
在三態模型中,進程狀態分為三個基本狀態,即**運行態,就緒態,阻塞態**。
在五態模型中,進程分為**新建態、終止態,運行態,就緒態,阻塞態**。
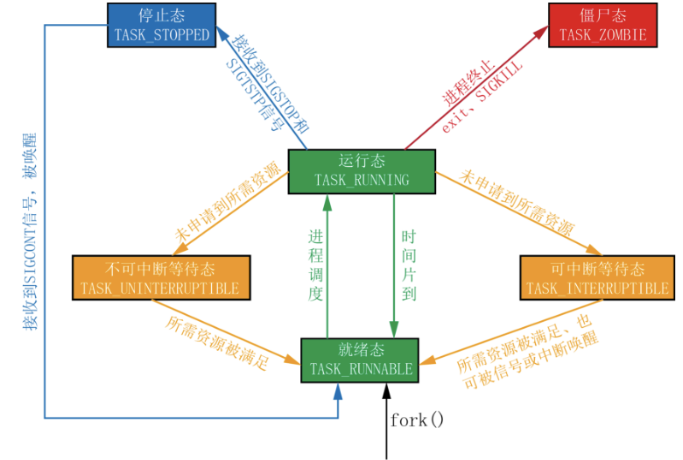
**①TASK\_RUNNING:** 進程正在被CPU執行。當一個進程剛被創建時會處于TASK\_RUNNABLE,表示己經準備就緒,正等待被調度。
**②TASK\_INTERRUPTIBLE(可中斷):**進程正在睡眠(也就是說它被阻塞)等待某些條件的達成。一旦這些條件達成,內核就會把進程狀態設置為運行。處于**此狀態的進程也會因為接收到信號而提前被喚醒**,**比如給一個TASK\_INTERRUPTIBLE狀態的進程發送SIGKILL信號,這個進程將先被喚醒(進入TASK\_RUNNABLE狀態),然后再響應SIGKILL信號而退出**(變為TASK\_ZOMBIE狀態),并不會從TASK\_INTERRUPTIBLE狀態直接退出。
**③TASK\_UNINTERRUPTIBLE(不可中斷):** 處于等待中的進程,待資源滿足時被喚醒,**但不可以由其它進程通過信號或中斷喚醒**。由于不接受外來的任何信號,**因此無法用kill殺掉這些處于該狀態的進程**。而**TASK\_UNINTERRUPTIBLE狀態存在的意義就在于**,**內核的某些處理流程是不能被打斷的**。如果響應異步信號,程序的執行流程中就會被插入一段用于處理異步信號的流程,于是原有的流程就被中斷了,這可能使某些設備陷入不可控的狀態。處于TASK\_UNINTERRUPTIBLE狀態一般總是非常短暫的,通過ps命令基本上不可能捕捉到。
**④TASK\_ZOMBIE(僵死):** 表示進程已經結束了,**但是其父進程還沒有調用wait4或waitpid()來釋放進程描述符**。為了父進程能夠獲知它的消息,子進程的進程描述符仍然被保留著。一旦父進程調用了wait4(),進程描述符就會被釋放。
**⑤TASK\_STOPPED(停止):** 進程停止執行。當進程接收到SIGSTOP,SIGTSTP,SIGTTIN,SIGTTOU等信號的時候。此外,**在調試期間接收到任何信號**,都會使進程進入這種狀態。**當接收到SIGCONT信號,會重新回到TASK\_RUNNABLE**。
如何查看進程狀態:

stat中的參數意義如下:
| **參數** | **含義** |
| --- | --- |
| D | 不可中斷 Uninterruptible(usually IO) |
| R | 正在運行,或在隊列中的進程 |
| S(大寫) | 處于休眠狀態 |
| T | 停止或被追蹤 |
| Z | 僵尸進程 |
| W | 進入內存交換(從內核2.6開始無效) |
| X | 死掉的進程 |
| < | 高優先級 |
| N | 低優先級 |
| s | 包含子進程 |
| + | 位于前臺的進程組 |
# 進程號和相關函數
每個進程都由一個進程號來標識,其類型為 pid\_t(整型),進程號的范圍:0~32767。進程號總是唯一的,但進程號可以重用。當一個進程終止后,其進程號就可以再次使用。
接下來,再給大家介紹三個不同的進程號。
**進程號(PID)**:
標識進程的一個非負整型數。
**父進程號(PPID)**:
任何進程( 除 init 進程)都是由另一個進程創建,該進程稱為被創建進程的父進程,對應的進程號稱為父進程號(PPID)。如,A 進程創建了 B 進程,A 的進程號就是 B 進程的父進程號。
**進程組號(PGID)**:
進程組是一個或多個進程的集合。他們之間相互關聯,進程組可以接收同一終端的各種信號,關聯的進程有一個進程組號(PGID) 。這個過程有點類似于 QQ 群,組相當于 QQ 群,各個進程相當于各個好友,把各個好友都拉入這個 QQ 群里,主要是方便管理,特別是通知某些事時,只要在群里吼一聲,所有人都收到,簡單粗暴。但是,這個進程組號和 QQ 群號是有點區別的,默認的情況下,當前的進程號會當做當前的進程組號。
**getpid函數**
~~~
#include <sys/types.h>
#include <unistd.h>
?
pid_t getpid(void);
功能:
獲取本進程號(PID)
參數:
無
返回值:
本進程號
~~~
**getppid函數**
~~~
#include <sys/types.h>
#include <unistd.h>
?
pid_t getppid(void);
功能:
獲取調用此函數的進程的父進程號(PPID)
參數:
無
返回值:
調用此函數的進程的父進程號(PPID)
~~~
**getpgid函數**
~~~
#include <sys/types.h>
#include <unistd.h>
?
pid_t getpgid(pid_t pid);
功能:
獲取進程組號(PGID)
參數:
pid:進程號
返回值:
參數為 0 時返回當前進程組號,否則返回參數指定的進程的進程組號
~~~
示例程序:
~~~
int main()
{
pid_t pid, ppid, pgid;
?
pid = getpid();
printf("pid = %d\n", pid);
?
ppid = getppid();
printf("ppid = %d\n", ppid);
?
pgid = getpgid(pid);
printf("pgid = %d\n", pgid);
?
return 0;
}
~~~
# 進程創建
系統允許一個進程創建新進程,新進程即為子進程,子進程還可以創建新的子進程,形成進程樹結構模型。
~~~
#include <sys/types.h>
#include <unistd.h>
?
pid_t fork(void);
功能:
用于從一個已存在的進程中創建一個新進程,新進程稱為子進程,原進程稱為父進程。
參數:
無
返回值:
成功:子進程中返回 0,父進程中返回子進程 ID。pid_t,為整型。
失敗:返回-1。
失敗的兩個主要原因是:
1)當前的進程數已經達到了系統規定的上限,這時 errno 的值被設置為 EAGAIN。
2)系統內存不足,這時 errno 的值被設置為 ENOMEM。
~~~
示例代碼
~~~
int main()
{
fork();
printf("id ==== %d\n", getpid()); // 獲取進程號
?
return 0;
}
~~~
從運行結果,我們可以看出,fork() 之后的打印函數打印了兩次,而且打印了兩個進程號,這說明,fork() 之后確實創建了一個新的進程,新進程為子進程,原來的進程為父進程。
## 區分父子進程
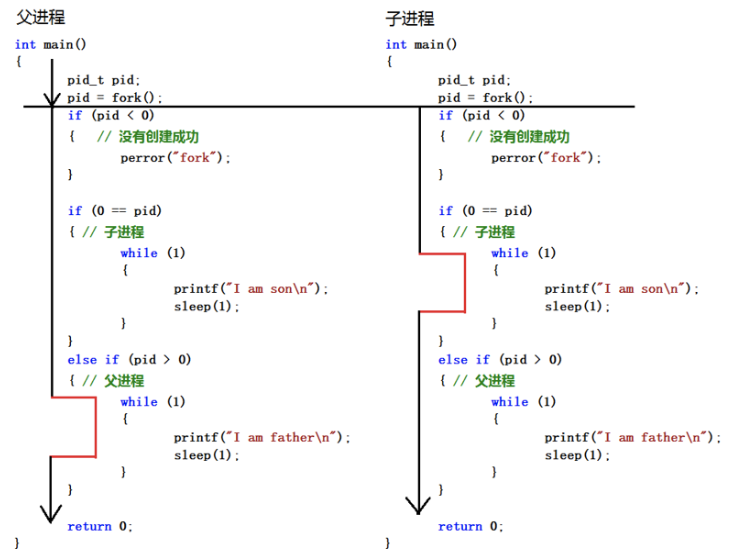
子進程是父進程的一個復制品,可以簡單認為父子進程的代碼一樣的。那大家想過沒有,這樣的話,父進程做了什么事情,子進程也做什么事情(如上面的例子),是不是不能實現滿足我們實現多任務的要求呀,那我們是不是要想個辦法區別父子進程呀,這就通過 fork() 的返回值。
fork() 函數被調用一次,但返回兩次。兩次返回的區別是:子進程的返回值是 0,而父進程的返回值則是新子進程的進程 ID
~~~
int main()
{
pid_t pid;
pid = fork();
if (pid < 0)
{ // 沒有創建成功
perror("fork");
return 0;
}
?
if (0 == pid)
{ // 子進程
while (1)
{
printf("I am son\n");
sleep(1);
}
}
else if (pid > 0)
{ // 父進程
while (1)
{
printf("I am father\n");
sleep(1);
}
}
?
return 0;
}
~~~
通過運行結果,可以看到,父子進程各做一件事(各自打印一句話)。這里,我們只是看到只有一份代碼,實際上,fork() 以后,有兩個地址空間在獨立運行著,有點類似于有兩個獨立的程序(父子進程)在運行著。
一般來說,在 fork() 之后是父進程先執行還是子進程先執行是不確定的。這取決于內核所使用的調度算法。
需要注意的是,在子進程的地址空間里,子進程是從 fork() 這個函數后才開始執行代碼
## 父子進程地址空間
~~~
int a = 10; // 全局變量
?
int main()
{
int b = 20; //局部變量
pid_t pid;
pid = fork();
if (pid < 0)
{ // 沒有創建成功
perror("fork");
}
?
if (0 == pid)
{ // 子進程
a = 111;
b = 222; // 子進程修改其值
printf("son: a = %d, b = %d\n", a, b);
}
else if (pid > 0)
{ // 父進程
sleep(1); // 保證子進程先運行
printf("father: a = %d, b = %d\n", a, b);
}
?
return 0;
}
~~~
通過得知,在子進程修改變量 a,b 的值,并不影響到父進程 a,b 的值。
# GDB調試多進程
~~~
gcc -9 源碼
~~~
使用gdb調試的時候,gdb只能跟蹤一個進程。可以在fork函數調用之前,通過指令設置gdb調試工具跟蹤父進程或者是跟蹤子進程。默認跟蹤父進程。
* set follow-fork-mode child 設置gdb在fork之后跟蹤子進程。
* set follow-fork-mode parent 設置跟蹤父進程(默認)。
注意,一定要在gdb中的fork函數調用之前設置才有效。
# 進程退出函數
~~~
#include <stdlib.h>
void exit(int status);
?
#include <unistd.h>
void _exit(int status);
功能:
結束調用此函數的進程。
參數:
status:返回給父進程的參數(低 8 位有效),至于這個參數是多少根據需要來填寫。
返回值:
無
~~~
用法是一樣的,無非時所包含的頭文件不一樣,還有的區別就是:exit()屬于標準庫函數,`_exit()`屬于系統調用函數。
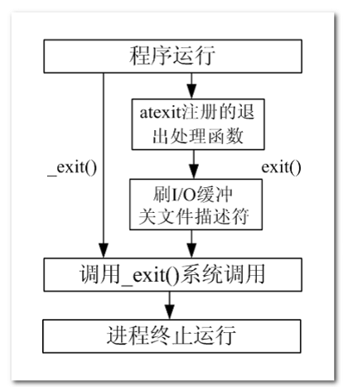
# 等待子進程退出函數
在每個進程退出的時候,內核釋放該進程所有的資源、包括打開的文件、占用的內存等。但是仍然為其保留一定的信息,這些信息主要主要指進程控制塊PCB的信息(包括進程號、退出狀態、運行時間等)。
父進程可以通過調用wait或waitpid得到它的退出狀態同時徹底清除掉這個進程。
wait() 和 waitpid() 函數的功能一樣,區別在于,wait() 函數會阻塞,waitpid() 可以設置不阻塞,waitpid() 還可以指定等待哪個子進程結束。
注意:一次wait或waitpid調用只能清理一個子進程,清理多個子進程應使用循環。
## wait函數
~~~
#include <sys/types.h>
#include <sys/wait.h>
?
pid_t wait(int *status);
功能:
等待任意一個子進程結束,如果任意一個子進程結束了,此函數會回收該子進程的資源。
參數:
status : 進程退出時的狀態信息。
返回值:
成功:已經結束子進程的進程號
失敗: -1
~~~
調用 wait() 函數的進程會掛起(阻塞),直到它的一個子進程退出或收到一個不能被忽視的信號時才被喚醒(相當于繼續往下執行)。
若調用進程沒有子進程,該函數立即返回;若它的子進程已經結束,該函數同樣會立即返回,并且會回收那個早已結束進程的資源。
所以,wait()函數的主要功能為回收已經結束子進程的資源。
如果參數 status 的值不是 NULL,wait() 就會把子進程退出時的狀態取出并存入其中,這是一個整數值(int),指出了子進程是正常退出還是被非正常結束的。
這個退出信息在一個 int 中包含了多個字段,直接使用這個值是沒有意義的,我們需要用宏定義取出其中的每個字段。
**宏函數可分為如下三組:**
1) WIFEXITED(status)
為非0 → 進程正常結束
WEXITSTATUS(status)
如上宏為真,使用此宏 → 獲取進程退出狀態 (exit的參數)
2) WIFSIGNALED(status)
為非0 → 進程異常終止
WTERMSIG(status)
如上宏為真,使用此宏 → 取得使進程終止的那個信號的編號。
3) WIFSTOPPED(status)
為非0 → 進程處于暫停狀態
WSTOPSIG(status)
如上宏為真,使用此宏 → 取得使進程暫停的那個信號的編號。
WIFCONTINUED(status)
為真 → 進程暫停后已經繼續運行
## waitpid函數
~~~
#include <sys/types.h>
#include <sys/wait.h>
?
pid_t waitpid(pid_t pid, int *status, int options);
功能:
等待子進程終止,如果子進程終止了,此函數會回收子進程的資源。
?
參數:
pid : 參數 pid 的值有以下幾種類型:
pid > 0 等待進程 ID 等于 pid 的子進程。
pid = 0 等待同一個進程組中的任何子進程,如果子進程已經加入了別的進程組,waitpid 不會等待它。
pid = -1 等待任一子進程,此時 waitpid 和 wait 作用一樣。
pid < -1 等待指定進程組中的任何子進程,這個進程組的 ID 等于 pid 的絕對值。
?
status : 進程退出時的狀態信息。和 wait() 用法一樣。
?
options : options 提供了一些額外的選項來控制 waitpid()。
0:同 wait(),阻塞父進程,等待子進程退出。
WNOHANG:沒有任何已經結束的子進程,則立即返回。
WUNTRACED:如果子進程暫停了則此函數馬上返回,并且不予以理會子進程的結束狀態。(由于涉及到一些跟蹤調試方面的知識,加之極少用到)
返回值:
waitpid() 的返回值比 wait() 稍微復雜一些,一共有 3 種情況:
1) 當正常返回的時候,waitpid() 返回收集到的已經回收子進程的進程號;
2) 如果設置了選項 WNOHANG,而調用中 waitpid() 發現沒有已退出的子進程可等待,則返回 0;
3) 如果調用中出錯,則返回-1,這時 errno 會被設置成相應的值以指示錯誤所在,如:當 pid 所對應的子進程不存在,或此進程存在,但不是調用進程的子進程,waitpid() 就會出錯返回,這時 errno 被設置為 ECHILD;
~~~
# 孤兒和僵尸進程
**孤兒進程**
父進程運行結束,但子進程還在運行(未運行結束)的子進程就稱為孤兒進程(Orphan Process)。
每當出現一個孤兒進程的時候,內核就把孤兒進程的父進程設置為 init ,而 init 進程會循環地 wait() 它的已經退出的子進程。這樣,當一個孤兒進程凄涼地結束了其生命周期的時候,init 進程就會代表黨和政府出面處理它的一切善后工作。
因此孤兒進程并不會有什么危害。
**僵尸進程**
進程終止,父進程尚未回收,子進程殘留資源(PCB)存放于內核中,變成僵尸(Zombie)進程。
這樣就會導致一個問題,如果進程不調用wait() 或 waitpid() 的話, 那么保留的那段信息就不會釋放,其進程號就會一直被占用,但是系統所能使用的進程號是有限的,如果大量的產生僵尸進程,將因為沒有可用的進程號而導致系統不能產生新的進程,此即為僵尸進程的危害,應當避免。
# 進程替換
可以通過 ./ 運行,讓一個可執行程序成為一個進程。
但是,如果我們本來就運行著一個程序(進程),我們如何在這個進程內部啟動一個外部程序,由內核將這個外部程序讀入內存,使其執行起來成為一個進程呢?這里我們通過 exec 函數族實現。
exec 函數族,顧名思義,就是一簇函數,在 Linux 中,并不存在 exec() 函數,exec 指的是一組函數,一共有 6 個:
~~~
#include <unistd.h>
extern char **environ;
?
int execl(const char *path, const char *arg, .../* (char *) NULL */);
int execlp(const char *file, const char *arg, ... /* (char *) NULL */);
int execle(const char *path, const char *arg, .../*, (char *) NULL, char * const envp[] */);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[], char *const envp[]);
?
int execve(const char *filename, char *const argv[], char *const envp[]);
~~~
其中只有 execve() 是真正意義上的系統調用,其它都是在此基礎上經過包裝的庫函數。
exec 函數族的作用是根據指定的文件名或目錄名找到可執行文件,并用它來取代調用進程的內容,換句話說,就是在調用進程內部執行一個可執行文件。
進程調用一種 exec 函數時,該進程完全由新程序替換,而新程序則從其 main 函數開始執行。因為調用 exec 并不創建新進程,所以前后的進程 ID (當然還有父進程號、進程組號、當前工作目錄……)并未改變。exec 只是用另一個新程序替換了當前進程的正文、數據、堆和棧段(進程替換)。
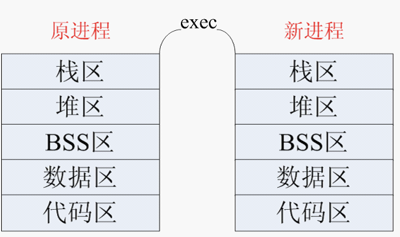
**exec 函數族使用說明**
exec 函數族的 6 個函數看起來似乎很復雜,但實際上無論是作用還是用法都非常相似,只有很微小的差別。
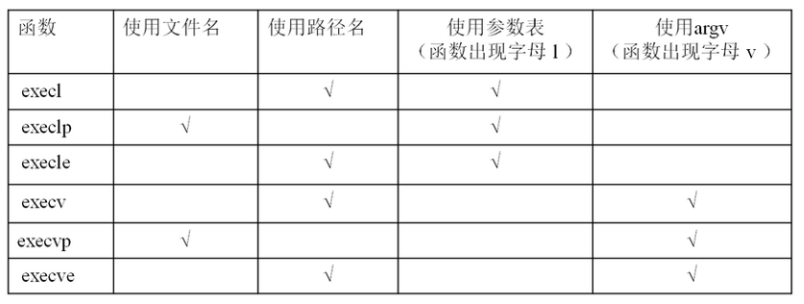
補充說明:
| l(list) | 參數地址列表,以空指針結尾 |
| --- | --- |
| v(vector) | 存有各參數地址的指針數組的地址 |
| p(path) | 按 PATH 環境變量指定的目錄搜索可執行文件 |
| e(environment) | 存有環境變量字符串地址的指針數組的地址 |
exec 函數族與一般的函數不同,exec 函數族中的函數執行成功后不會返回,
**而且,exec 函數族下面的代碼執行不到**。
只有調用失敗了,它們才會返回 -1,失敗后從原程序的調用點接著往下執行
- c語言
- 基礎知識
- 變量和常量
- 宏定義和預處理
- 隨機數
- register變量
- errno全局變量
- 靜態變量
- 類型
- 數組
- 類型轉換
- vs中c4996錯誤
- 數據類型和長度
- 二進制數,八進制數和十六進制數
- 位域
- typedef定義類型
- 函數和編譯
- 函數調用慣例
- 函數進棧和出棧
- 函數
- 編譯
- sizeof
- main函數接收參數
- 宏函數
- 目標文件和可執行文件有什么
- 強符號和弱符號
- 什么是鏈接
- 符號
- 強引用和弱引用
- 字符串處理函數
- sscanf
- 查找子字符串
- 字符串指針
- qt
- MFC
- 指針
- 簡介
- 指針詳解
- 案例
- 指針數組
- 偏移量
- 間接賦值
- 易錯點
- 二級指針
- 結構體指針
- 字節對齊
- 函數指針
- 指針例子
- main接收用戶輸入
- 內存布局
- 內存分區
- 空間開辟和釋放
- 堆空間操作字符串
- 內存處理函數
- 內存分頁
- 內存模型
- 棧
- 棧溢出攻擊
- 內存泄露
- 大小端存儲法
- 寄存器
- 結構體
- 共用體
- 枚舉
- 文件操作
- 文件到底是什么
- 文件打開和關閉
- 文件的順序讀寫
- 文件的隨機讀寫
- 文件復制
- FILE和緩沖區
- 文件大小
- 插入,刪除,更改文件內容
- typeid
- 內部鏈接和外部鏈接
- 動態庫
- 調試器
- 調試的概念
- vs調試
- 多文件編程
- extern關鍵字
- 頭文件規范
- 標準庫以及標準頭文件
- 頭文件只包含一次
- static
- 多線程
- 簡介
- 創建線程threads.h
- 創建線程pthread
- gdb
- 簡介
- mac使用gdb
- setjump和longjump
- 零拷貝
- gc
- 調試器原理
- c++
- c++簡介
- c++對c的擴展
- ::作用域運算符
- 名字控制
- cpp對c的增強
- const
- 變量定義數組
- 盡量以const替換#define
- 引用
- 內聯函數
- 函數默認參數
- 函數占位參數
- 函數重載
- extern "C"
- 類和對象
- 類封裝
- 構造和析構
- 深淺拷貝
- explicit關鍵字
- 動態對象創建
- 靜態成員
- 對象模型
- this
- 友元
- 單例
- 繼承
- 多態
- 運算符重載
- 賦值重載
- 指針運算符(*,->)重載
- 前置和后置++
- 左移<<運算符重載
- 函數調用符重載
- 總結
- bool重載
- 模板
- 簡介
- 普通函數和模板函數調用
- 模板的局限性
- 類模板
- 復數的模板類
- 類模板作為參數
- 類模板繼承
- 類模板類內和類外實現
- 類模板和友元函數
- 類模板實現數組
- 類型轉換
- 異常
- 異常基本語法
- 異常的接口聲明
- 異常的棧解旋
- 異常的多態
- 標準異常庫
- 自定義異常
- io
- 流的概念和類庫結構
- 標準io流
- 標準輸入流
- 標準輸出流
- 文件讀寫
- STL
- 簡介
- string容器
- vector容器
- deque容器
- stack容器
- queue容器
- list容器
- set/multiset容器
- map/multimap容器
- pair對組
- 深淺拷貝問題
- 使用時機
- 常用算法
- 函數對象
- 謂詞
- 內建函數對象
- 函數對象適配器
- 空間適配器
- 常用遍歷算法
- 查找算法
- 排序算法
- 拷貝和替換算法
- 算術生成算法
- 集合算法
- gcc
- GDB
- makefile
- visualstudio
- VisualAssistX
- 各種插件
- utf8編碼
- 制作安裝項目
- 編譯模式
- 內存對齊
- 快捷鍵
- 自動補全
- 查看c++類內存布局
- FFmpeg
- ffmpeg架構
- 命令的基本格式
- 分解與復用
- 處理原始數據
- 錄屏和音
- 濾鏡
- 水印
- 音視頻的拼接與裁剪
- 視頻圖片轉換
- 直播
- ffplay
- 常見問題
- 多媒體文件處理
- ffmpeg代碼結構
- 日志系統
- 處理流數據
- linux
- 系統調用
- 常用IO函數
- 文件操作函數
- 文件描述符復制
- 目錄相關操作
- 時間相關函數
- 進程
- valgrind
- 進程通信
- 信號
- 信號產生函數
- 信號集
- 信號捕捉
- SIGCHLD信號
- 不可重入函數和可重入函數
- 進程組
- 會話
- 守護進程
- 線程
- 線程屬性
- 互斥鎖
- 讀寫鎖
- 條件變量
- 信號量
- 網絡
- 分層模型
- 協議格式
- TCP協議
- socket
- socket概念
- 網絡字節序
- ip地址轉換函數
- sockaddr數據結構
- 網絡套接字函數
- socket模型創建流程圖
- socket函數
- bind函數
- listen函數
- accept函數
- connect函數
- C/S模型-TCP
- 出錯處理封裝函數
- 多進程并發服務器
- 多線程并發服務器
- 多路I/O復用服務器
- select
- poll
- epoll
- epoll事件
- epoll例子
- epoll反應堆思想
- udp
- socket IPC(本地套接字domain)
- 其他常用函數
- libevent
- libevent簡介