
# 機器:惠普基于憶阻器的新型數據中心規模計算機-一切仍在變化
> 原文: [http://highscalability.com/blog/2014/12/15/the-machine-hps-new-memristor-based-datacenter-scale-compute.html](http://highscalability.com/blog/2014/12/15/the-machine-hps-new-memristor-based-datacenter-scale-compute.html)
> 摩爾定律的終結是過去 50 年來計算機發生的最好的事情。 摩爾定律一直是安慰的專制。 您可以放心,您的籌碼會不斷進步。 每個人都知道即將發生什么以及何時發生。 整個半導體行業都被迫遵守摩爾定律。 在整個過程中沒有新的發明。 只需在跑步機上踩一下,然后執行預期的操作即可。 我們終于擺脫了束縛,進入了自 1940 年代后期以來我們看到的最激動人心的計算時代。 最終,我們處于人們可以發明的階段,將嘗試并嘗試這些新事物并找到進入市場的方式。 我們最終將以不同的方式和更聰明的方式做事。
>
> - [Stanley Williams](http://en.wikipedia.org/wiki/R._Stanley_Williams) (措辭)
惠普一直在開發一種全新的計算機,其名稱為*機器*(不是 [這臺機器](http://personofinterest.wikia.com/wiki/The_Machine) )。 該機器可能是惠普歷史上最大的 R & D 項目。 這是對硬件和軟件的徹底重建。 巨大的努力。 惠普希望在兩年內啟動并運行其數據中心規模產品的小版本。
故事始于大約四年前我們在 [中首次遇到惠普的](http://highscalability.com/blog/2010/5/5/how-will-memristors-change-everything.html) [Stanley Williams](http://en.wikipedia.org/wiki/R._Stanley_Williams) ? 在憶阻器故事的最新一章中,威廉姆斯先生發表了另一篇令人難以置信的演講: [機器:用于計算大數據的 HP 憶阻器解決方案 [](https://mediacosmos.rice.edu/app/plugin/embed.aspx?ID=vVUTzFCE006yZu3TF1sXKg&displayTitle=false&startTime=0&autoPlay=false&hideControls=false&showCaptions=false&width=420&height=236&destinationID=URka-_E5-0-e4girH4pDPQ&contentID=vq2oQtAqPkeAqm5F6uSnqA&pageIndex=1&pageSize=10) ,進一步揭示了機器的工作方式。
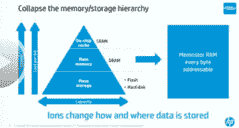
機器的目標是**折疊內存/存儲層次結構**。 今天的計算是低能效的。 **消耗了 80%的能量**和大量時間**在硬盤,內存,處理器和多層高速緩存之間移動位**。 客戶最終花在電費上的錢比買機器本身要多。 因此,該計算機沒有硬盤,DRAM 或閃存。 數據保存在高能效憶阻器,基于離子的非易失性存儲器中,數據通過光子網絡移動,這是另一種非常省電的技術。 當一小部分信息離開核心時,它就以光脈沖的形式離開。
在圖形處理基準上,據報道,“機器”基于能效的性能要好 2-3 個數量級,而基于時間的性能要好一個數量級。 這些基準沒有詳細信息,但這就是要點。
**機器首先放置數據** 。 其概念是圍繞非易失性存儲器構建一個系統,在整個存儲器中自由分配處理器。 當您要運行程序時,請 **將程序發送到內存** 附近的處理器,在本地進行計算,然后將結果發送回去。 計算使用了各種各樣的異構多核處理器。 與僅移動 TB 或 PB 的數據相比,僅傳輸程序所需的位和結果可節省大量資金。
機器不針對標準 HPC 工作負載。 這不是 LINPACK 破壞者。 HP 試圖為客戶解決的問題是客戶要執行查詢并通過搜索大量數據來找出答案。 隨著新數據的出現,需要存儲大量數據并進行實時分析的問題
**為什么構建計算機需要非常不同的體系結構?** 計算機系統無法跟上不斷涌入的大量數據。惠普從其客戶那里得知,他們需要能夠處理越來越多的數據的能力。 **與晶體管的制造速度**相比,收集的位數呈指數增長。 另外,信息收集的增長速度快于硬盤的制造速度。 惠普估計,人們真正想做的事有 250 萬億張 DVD 數據。 全世界從未收集過大量數據,甚至從未查看過。
因此,需要一些新的東西。 至少這是惠普的賭注。 盡管很容易對 HP 正在開發的技術感到興奮,但至少在本世紀末之前,這對您和我來說都不是。 這些將在相當長一段時間內都不是商業產品。 惠普打算將它們用于自己的企業產品,在內部消耗所制造的一切。 我們的想法是,我們還處于技術周期的初期,因此首先要構建高成本的系統,然后隨著數量的增長和流程的改進,該技術將可以進行商業部署。 最終,成本將下降到足以出售更小尺寸的產品。
有趣的是,HP 本質上是在構建自己的云基礎架構,但是他們沒有利用商品硬件和軟件,而是在構建自己最好的定制硬件和軟件。 云通常提供大量的內存,磁盤和 CPU 池,這些池圍繞通過快速網絡連接的實例類型進行組織。 最近,有一種將這些資源池視為獨立于基礎實例的方法。 因此,我們看到諸如 [Kubernetes 和 Mesos](https://mesosphere.com/2014/07/10/mesosphere-announces-kubernetes-on-mesos/) 之類的高級調度軟件正在成為行業中的更大力量。 惠普必須自己構建所有這些軟件,以解決許多相同的問題,以及專用芯片提供的機會。 您可以想象程序員對非常專業的應用程序進行編程以從 The Machine 獲得每盎司的性能,但是 HP 更有可能必須創建一個非常復雜的調度系統來優化程序在 The Machine 上的運行方式。 **軟件的下一步是一種全息應用程序體系結構的演進,其中功能在時間和空間上都是流動的,并且身份在運行時由二維結構產生。** 日程安排優化是云上正在探索的下一個領域。
演講分為兩個主要部分:硬件和軟件。 該項目的三分之二是軟件,但威廉姆斯先生是硬件專家,所以硬件占了大部分。 硬件部分基于**優化圍繞**可用的物理原理的各種功能的思想:**電子計算; 離子存儲 光子通信**。
這是我對威廉姆斯先生的發言 [講話](https://mediacosmos.rice.edu/app/plugin/embed.aspx?ID=vVUTzFCE006yZu3TF1sXKg&displayTitle=false&startTime=0&autoPlay=false&hideControls=false&showCaptions=false&width=420&height=236&destinationID=URka-_E5-0-e4girH4pDPQ&contentID=vq2oQtAqPkeAqm5F6uSnqA&pageIndex=1&pageSize=10) 。 像往常一樣,面對如此復雜的主題,可能會錯過很多東西。 另外,威廉姆斯先生在煎餅周圍扔出了很多有趣的主意,因此強烈建議您觀看演講。 但是在那之前,讓我們來看看 HP 認為機器將是計算的未來……。
## 為什么構建計算機需要不同的體系結構?
計算架構在 60 年來從未改變。 [Von Neumann 架構](http://en.wikipedia.org/wiki/Von_Neumann_architecture) 僅打算使用幾年,但我們仍在使用它。 數據必須在內存,處理器和硬盤之間來回移動。 **如今,移動數據的過程已完全主導了計算**。 這就是在數據中心中花費大量時間并消耗大量電力的原因。
摩爾定律即將終結。 我們已經達到了 14 nm(約 50 個原子)的晶體管。 7 nm 被認為是物理極限。 10 納米將在兩年內準備就緒,而 7 納米將在 2020 年之前準備就緒。 這將使計算效率提高 10 個數量級,這是人類技術有史以來最大的改進。
我們如何看待突破摩爾定律范式? **圍繞可用的**優化物理的各種功能。 50 年來,我們附屬于計算機的東西是電子。 那不會改變。 電子是執行計算過程的理想選擇。 它們很小,很輕,您施加了電壓,移動很快,但是它們的質量足以使它們位于一個很小的空間中,并且相互作用非常強,因此您可以對電子進行邏輯運算。 電子將繼續成為引擎的計算部分。
**我們將使用離子** 而不是使用電子進行存儲。 原因是離子是經典的機械粒子,它們很重,將它們放在某個地方并留在那兒,您可以回到一個世紀后,將離子放在那兒的位置仍然存在。 離子確實是非易失性存儲信息的一種方法。 可以將離子放在小盒子中,然后可以將盒子堆疊起來,與電子相比,可以實現高密度,低成本的存儲。
**數據將使用光子** 移動。 其原因是光子沒有質量,因此它們以光速運動。 可以在同一波導中放置許多不同顏色的光,因此可以節省大量空間和能源。 更高的通信帶寬和更低的功耗。
正在圍繞這些功能中的每一個對機器周圍的硬件進行優化,以便進行計算,存儲和通信。 通過適當地構建它們,存在有利的非線性相互作用。
**通過異構多核芯片的擴散,電子將繼續成為未來** 的計算引擎。 由于摩爾定律的失敗,如今存在多核芯片。 我們之所以擁有多核芯片,是因為一個大而快的芯片的功耗會使其蒸發。 為了解決該問題,將芯片切成小塊。 問題是多核更難編程,但是我們開始弄清楚,人們現在認為多核是一件好事。
并非所有核心都相同,而是核心將有所不同。 代替在芯片上具有相同的 256 個內核,將針對不同類型的功能優化不同的內核。
**挑戰是 Dark Silicon** 。 如果同時點亮一個芯片上的所有內核,則**芯片將被蒸發**。 您實際上從未真正使用過芯片上的所有內核。 與 14nm 相比,在 10nm 下,您必須一次使用一半的內核。 如果內核是特定于功能的,則在不使用內核時將它們變暗是有意義的。 專用加速器是可以超級高效地運行一種類型的計算的核心,但是它只能完成一件事。 對于求解晶體結構,如果您有一個可以在一個時鐘周期內完成傅立葉變換的專用內核,那將非常有幫助。
您不需要龐大的團隊來設計處理器。 有些公司出售處理器設計。 您可以只設計幾個專門的加速器。 這些設計可以招標。 力量的平衡將轉移給設計師,而不是制造商,他們將成為低成本的競標者。
## **憶阻器是離子盒**
**DRAM 本質上吸收電子并將其放入盒子中** 。 隨著盒子的尺寸越來越小,將電子保持在內部的難度越來越大,這意味著 DRAM 必須更頻繁地刷新。 可靠地將電子存儲在 DRAM 或閃存中變得越來越困難。
**解決方案是在存儲介質中使用作為帶電原子的離子代替電子** 。 原子比電子的行為更好,因為它們的質量大得多。 原子是經典的機械粒子,因此即使在 10nm 的盒子中,原子也很高興成為粒子。 將離子放入盒子中,在盒子上施加電壓,離子將在盒子內移動。 關閉電壓,即使在很小的盒子中,離子也將保持原狀,甚至持續數百萬年。 這是非常穩定的非易失性類型的內存。
**可以通過在盒子上施加小電壓并測量電阻**來讀取離子狀態 **。 由于電壓不夠高,離子不會移動。 盒子的電阻取決于離子在里面的位置。 當離子在盒子中均勻分布時,您會得到一個低電阻,您可以將其稱為 1。如果將所有離子推到盒子的一側,則電阻將非常高,您可以將其稱為 0。**
**離子盒是憶阻器**。 與 DRAM 憶阻器相比,**因子**慢 4 倍,可以通過并行訪問來緩和。 憶阻器的功率要求要低得多,因為離子不會泄漏,因此無需刷新。 **的位密度要比**高得多,因為可以將盒子堆疊在一起。 芯片**每位**便宜得多。 基于這些想法,他們多年來一直在制造芯片。 在演講中,顯示的芯片使用了 2.5 年,并使用了 50nm 技術,這意味著當前的迭代要好得多,但是他們無法發表評論。
想法是折疊內存/存儲層次結構,并消除在系統中所有層之間移動數據的所有開銷和時間。 今天的計算問題是能源效率低下。 花費了 80%的能量,并花費了大量時間來獲取位,然后將它們從硬盤,內存,處理器,多層高速緩存中移出,然后再向下移出。 大多數操作系統都關心所有這些數據處理的機制。
## 使用光子進行通信
光子破壞距離。 沒有什么比光速快。
那么為什么我們不像在電信網絡中那樣已經在芯片上使用光子學呢? 互連的成本將是計算機本身成本的一千倍。 **通過機架移動的數據量大于通過北美電信網絡**的數據量。
**惠普一直在努力降低成本**。 光線是移動數據的一種上乘方式。 它具有高帶寬(單根導線中有多個波長),高能效(無能量損失),低延遲(無中繼器)和空間高效(節省了引腳數)。
他們現在正在使用標準硅工藝在硅晶片上集成光子學。
此技術用于在計算機中創建通信結構。 電腦是一個裝有刀片的盒子。 刀片服務器具有憶阻器存儲芯片和多核處理器。 插入刀片時,刀片會自動重新配置光子網絡,以便一切都能相互通信。 接下來要做的是把盒子拿起來并堆放在一起,形成一個架子。 同樣,網絡會自動進行自我配置。 接下來是能夠組裝一個數據中心的機架,然后將它們全部抬起并正確配置。

## 軟件-三分之二
到目前為止,所有硬件僅占項目的 1/3。 The Machine 之上必須裝有操作系統。 一個操作系統可能需要數十年的開發時間。 **惠普正在開發精簡版的 Linux** ,該版本非常快,因為處理掉了數據內部移動的所有邏輯都已被剔除。 他們還創建了**開源社區,以構建操作系統**的本機版本,以及所有最重要的應用程序,例如分析,可視化,艾字節級算法和百萬節點管理。
試圖縮短從研究,開發到產品生產的時間范圍。 大量的工作。 這是一個非常冒險的項目。 規模龐大。 雄心勃勃。 巨大的風險。
## 對任何嘗試進行全新工作的人來說,都是一個重大警告。
**經驗教訓**:他們遇到了無法預料的問題。 然后要做很多工作,以確保可以使用標準制造流程來構建其流程。
如果您嘗試引入真正不同的東西,例如碳納米管或石墨烯,會發生什么? 他們使用所有標準材料所面臨的挑戰是巨大的。 引入異國情調的東西將需要數十年的時間才能真正通過實際的制造過程進行構建。 如果您打算深入研究并大膽地做,則必須**做一些與現有**盡可能接近的事情。 你離那不可能走得太遠。
## 相關文章
* [憶阻器將如何改變一切?](http://highscalability.com/blog/2010/5/5/how-will-memristors-change-everything.html)
* [我們比光而不是電的超高速計算機更近一步](http://www.fastcolabs.com/3039445/were-one-step-closer-to-superfast-computers-that-run-on-light-instead-of-electricity)
* Google 押注 [Quantum Computers](https://plus.google.com/+QuantumAILab/posts)
* [圖靈大教堂](http://www.amazon.com/dp/0375422773) -喬治·戴森
* [IT 的新風格](http://www.hipeac.net/system/files/HiPEAC14-faraboschi-pub.pdf)
- LiveJournal 體系結構
- mixi.jp 體系結構
- 友誼建筑
- FeedBurner 體系結構
- GoogleTalk 架構
- ThemBid 架構
- 使用 Amazon 服務以 100 美元的價格構建無限可擴展的基礎架構
- TypePad 建筑
- 維基媒體架構
- Joost 網絡架構
- 亞馬遜建筑
- Fotolog 擴展成功的秘訣
- 普恩斯的教訓-早期
- 論文:Wikipedia 的站點內部,配置,代碼示例和管理問題
- 擴大早期創業規模
- Feedblendr 架構-使用 EC2 進行擴展
- Slashdot Architecture-互聯網的老人如何學會擴展
- Flickr 架構
- Tailrank 架構-了解如何在整個徽標范圍內跟蹤模因
- Ruby on Rails 如何在 550k 網頁瀏覽中幸存
- Mailinator 架構
- Rackspace 現在如何使用 MapReduce 和 Hadoop 查詢 TB 的數據
- Yandex 架構
- YouTube 架構
- Skype 計劃 PostgreSQL 擴展到 10 億用戶
- 易趣建筑
- FaceStat 的禍根與智慧贏得了勝利
- Flickr 的聯合會:每天進行數十億次查詢
- EVE 在線架構
- Notify.me 體系結構-同步性
- Google 架構
- 第二人生架構-網格
- MySpace 體系結構
- 擴展 Digg 和其他 Web 應用程序
- Digg 建筑
- 在 Amazon EC2 中部署大規模基礎架構的六個經驗教訓
- Wolfram | Alpha 建筑
- 為什么 Facebook,Digg 和 Twitter 很難擴展?
- 全球范圍擴展的 10 個 eBay 秘密
- BuddyPoke 如何使用 Google App Engine 在 Facebook 上擴展
- 《 FarmVille》如何擴展以每月收獲 7500 萬玩家
- Twitter 計劃分析 1000 億條推文
- MySpace 如何與 100 萬個并發用戶一起測試其實時站點
- FarmVille 如何擴展-后續
- Justin.tv 的實時視頻廣播架構
- 策略:緩存 404 在服務器時間上節省了洋蔥 66%
- Poppen.de 建筑
- MocoSpace Architecture-一個月有 30 億個移動頁面瀏覽量
- Sify.com 體系結構-每秒 3900 個請求的門戶
- 每月將 Reddit 打造為 2.7 億頁面瀏覽量時汲取的 7 個教訓
- Playfish 的社交游戲架構-每月有 5000 萬用戶并且不斷增長
- 擴展 BBC iPlayer 的 6 種策略
- Facebook 的新實時消息系統:HBase 每月可存儲 135 億條消息
- Pinboard.in Architecture-付費玩以保持系統小巧
- BankSimple 迷你架構-使用下一代工具鏈
- Riak 的 Bitcask-用于快速鍵/值數據的日志結構哈希表
- Mollom 體系結構-每秒以 100 個請求殺死超過 3.73 億個垃圾郵件
- Wordnik-MongoDB 和 Scala 上每天有 1000 萬個 API 請求
- Node.js 成為堆棧的一部分了嗎? SimpleGeo 說是的。
- 堆棧溢出體系結構更新-現在每月有 9500 萬頁面瀏覽量
- Medialets 體系結構-擊敗艱巨的移動設備數據
- Facebook 的新實時分析系統:HBase 每天處理 200 億個事件
- Microsoft Stack 是否殺死了 MySpace?
- Viddler Architecture-每天嵌入 700 萬個和 1500 Req / Sec 高峰
- Facebook:用于擴展數十億條消息的示例規范架構
- Evernote Architecture-每天有 900 萬用戶和 1.5 億個請求
- TripAdvisor 的短
- TripAdvisor 架構-4,000 萬訪客,200M 動態頁面瀏覽,30TB 數據
- ATMCash 利用虛擬化實現安全性-不變性和還原
- Google+是使用您也可以使用的工具構建的:閉包,Java Servlet,JavaScript,BigTable,Colossus,快速周轉
- 新的文物建筑-每天收集 20 億多個指標
- Peecho Architecture-鞋帶上的可擴展性
- 標記式架構-擴展到 1 億用戶,1000 臺服務器和 50 億個頁面視圖
- 論文:Akamai 網絡-70 個國家/地區的 61,000 臺服務器,1,000 個網絡
- 策略:在 S3 或 GitHub 上運行可擴展,可用且廉價的靜態站點
- Pud 是反堆棧-Windows,CFML,Dropbox,Xeround,JungleDisk,ELB
- 用于擴展 Turntable.fm 和 Labmeeting 的數百萬用戶的 17 種技術
- StackExchange 體系結構更新-平穩運行,Amazon 4x 更昂貴
- DataSift 體系結構:每秒進行 120,000 條推文的實時數據挖掘
- Instagram 架構:1400 萬用戶,1 TB 的照片,數百個實例,數十種技術
- PlentyOfFish 更新-每月 60 億次瀏覽量和 320 億張圖片
- Etsy Saga:從筒倉到開心到一個月的瀏覽量達到數十億
- 數據范圍項目-6PB 存儲,500GBytes / sec 順序 IO,20M IOPS,130TFlops
- 99designs 的設計-數以千萬計的綜合瀏覽量
- Tumblr Architecture-150 億頁面瀏覽量一個月,比 Twitter 更難擴展
- Berkeley DB 體系結構-NoSQL 很酷之前的 NoSQL
- Pixable Architecture-每天對 2000 萬張照片進行爬網,分析和排名
- LinkedIn:使用 Databus 創建低延遲更改數據捕獲系統
- 在 30 分鐘內進行 7 年的 YouTube 可擴展性課程
- YouPorn-每天定位 2 億次觀看
- Instagram 架構更新:Instagram 有何新功能?
- 搜索技術剖析:blekko 的 NoSQL 數據庫
- Pinterest 體系結構更新-1800 萬訪問者,增長 10 倍,擁有 12 名員工,410 TB 數據
- 搜索技術剖析:使用組合器爬行
- iDoneThis-從頭開始擴展基于電子郵件的應用程序
- StubHub 體系結構:全球最大的票務市場背后的驚人復雜性
- FictionPress:在網絡上發布 600 萬本小說
- Cinchcast 體系結構-每天產生 1,500 小時的音頻
- 棱柱架構-使用社交網絡上的機器學習來弄清您應該在網絡上閱讀的內容
- 棱鏡更新:基于文檔和用戶的機器學習
- Zoosk-實時通信背后的工程
- WordPress.com 使用 NGINX 服務 70,000 req / sec 和超過 15 Gbit / sec 的流量
- 史詩般的 TripAdvisor 更新:為什么不在云上運行? 盛大的實驗
- UltraDNS 如何處理數十萬個區域和數千萬條記錄
- 更簡單,更便宜,更快:Playtomic 從.NET 遷移到 Node 和 Heroku
- Spanner-關于程序員使用 NoSQL 規模的 SQL 語義構建應用程序
- BigData 使用 Erlang,C 和 Lisp 對抗移動數據海嘯
- 分析數十億筆信用卡交易并在云中提供低延遲的見解
- MongoDB 和 GridFS 用于內部和內部數據中心數據復制
- 每天處理 1 億個像素-少量競爭會導致大規模問題
- DuckDuckGo 體系結構-每天進行 100 萬次深度搜索并不斷增長
- SongPop 在 GAE 上可擴展至 100 萬活躍用戶,表明 PaaS 未通過
- Iron.io 從 Ruby 遷移到 Go:減少了 28 臺服務器并避免了巨大的 Clusterf ** ks
- 可汗學院支票簿每月在 GAE 上擴展至 600 萬用戶
- 在破壞之前先檢查自己-鱷梨的建筑演進的 5 個早期階段
- 縮放 Pinterest-兩年內每月從 0 到十億的頁面瀏覽量
- Facebook 的網絡秘密
- 神話:埃里克·布魯爾(Eric Brewer)談銀行為什么不是堿-可用性就是收入
- 一千萬個并發連接的秘密-內核是問題,而不是解決方案
- GOV.UK-不是你父親的書庫
- 縮放郵箱-在 6 周內從 0 到 100 萬用戶,每天 1 億條消息
- 在 Yelp 上利用云計算-每月訪問量為 1.02 億,評論量為 3900 萬
- 每臺服務器將 PHP 擴展到 30,000 個并發用戶的 5 條 Rockin'Tips
- Twitter 的架構用于在 5 秒內處理 1.5 億活躍用戶,300K QPS,22 MB / S Firehose 以及發送推文
- Salesforce Architecture-他們每天如何處理 13 億筆交易
- 擴大流量的設計決策
- ESPN 的架構規模-每秒以 100,000 Duh Nuh Nuhs 運行
- 如何制作無限可擴展的關系數據庫管理系統(RDBMS)
- Bazaarvoice 的架構每月發展到 500M 唯一用戶
- HipChat 如何使用 ElasticSearch 和 Redis 存儲和索引數十億條消息
- NYTimes 架構:無頭,無主控,無單點故障
- 接下來的大型聲音如何使用 Hadoop 數據版本控制系統跟蹤萬億首歌曲的播放,喜歡和更多內容
- Google 如何備份 Internet 和數十億字節的其他數據
- 從 HackerEarth 用 Apache 擴展 Python 和 Django 的 13 個簡單技巧
- AOL.com 體系結構如何發展到 99.999%的可用性,每天 800 萬的訪問者和每秒 200,000 個請求
- Facebook 以 190 億美元的價格收購了 WhatsApp 體系結構
- 使用 AWS,Scala,Akka,Play,MongoDB 和 Elasticsearch 構建社交音樂服務
- 大,小,熱還是冷-條帶,Tapad,Etsy 和 Square 的健壯數據管道示例
- WhatsApp 如何每秒吸引近 5 億用戶,11,000 內核和 7,000 萬條消息
- Disqus 如何以每秒 165K 的消息和小于 0.2 秒的延遲進行實時處理
- 關于 Disqus 的更新:它仍然是實時的,但是 Go 摧毀了 Python
- 關于 Wayback 機器如何在銀河系中存儲比明星更多的頁面的簡短說明
- 在 PagerDuty 遷移到 EC2 中的 XtraDB 群集
- 擴展世界杯-Gambify 如何與 2 人組成的團隊一起運行大型移動投注應用程序
- 一點點:建立一個可處理每月 60 億次點擊的分布式系統的經驗教訓
- StackOverflow 更新:一個月有 5.6 億次網頁瀏覽,25 臺服務器,而這一切都與性能有關
- Tumblr:哈希處理每秒 23,000 個博客請求的方式
- 使用 HAProxy,PHP,Redis 和 MySQL 處理 10 億個請求的簡便方法來構建成長型啟動架構
- MixRadio 體系結構-兼顧各種服務
- Twitter 如何使用 Redis 進行擴展-105TB RAM,39MM QPS,10,000 多個實例
- 正確處理事情:通過即時重放查看集中式系統與分散式系統
- Instagram 提高了其應用程序的性能。 這是如何做。
- Clay.io 如何使用 AWS,Docker,HAProxy 和 Lots 建立其 10 倍架構
- 英雄聯盟如何將聊天擴大到 7000 萬玩家-需要很多小兵。
- Wix 的 Nifty Architecture 技巧-大規模構建發布平臺
- Aeron:我們真的需要另一個消息傳遞系統嗎?
- 機器:惠普基于憶阻器的新型數據中心規模計算機-一切仍在變化
- AWS 的驚人規模及其對云的未來意味著什么
- Vinted 體系結構:每天部署數百次,以保持繁忙的門戶穩定
- 將 Kim Kardashian 擴展到 1 億個頁面
- HappyPancake:建立簡單可擴展基金會的回顧
- 阿爾及利亞分布式搜索網絡的體系結構
- AppLovin:通過每天處理 300 億個請求向全球移動消費者進行營銷
- Swiftype 如何以及為何從 EC2 遷移到真實硬件
- 我們如何擴展 VividCortex 的后端系統
- Appknox 架構-從 AWS 切換到 Google Cloud
- 阿爾及利亞通往全球 API 的憤怒之路
- 阿爾及利亞通往全球 API 步驟的憤怒之路第 2 部分
- 為社交產品設計后端
- 阿爾及利亞通往全球 API 第 3 部分的憤怒之路
- Google 如何創造只有他們才能創造的驚人的數據中心網絡
- Autodesk 如何在 Mesos 上實施可擴展事件
- 構建全球分布式,關鍵任務應用程序:Trenches 部分的經驗教訓 1
- 構建全球分布式,關鍵任務應用程序:Trenches 第 2 部分的經驗教訓
- 需要物聯網嗎? 這是美國一家主要公用事業公司從 550 萬米以上收集電力數據的方式
- Uber 如何擴展其實時市場平臺
- 優步變得非常規:使用司機電話作為備份數據中心
- 在不到五分鐘的時間里,Facebook 如何告訴您的朋友您在災難中很安全
- Zappos 的網站與 Amazon 集成后凍結了兩年
- 為在現代時代構建可擴展的有狀態服務提供依據
- 細分:使用 Docker,ECS 和 Terraform 重建基礎架構
- 十年 IT 失敗的五個教訓
- Shopify 如何擴展以處理來自 Kanye West 和 Superbowl 的 Flash 銷售
- 整個 Netflix 堆棧的 360 度視圖
- Wistia 如何每小時處理數百萬個請求并處理豐富的視頻分析
- Google 和 eBay 關于構建微服務生態系統的深刻教訓
- 無服務器啟動-服務器崩潰!
- 在 Amazon AWS 上擴展至 1100 萬以上用戶的入門指南
- 為 David Guetta 建立無限可擴展的在線錄制活動
- Tinder:最大的推薦引擎之一如何決定您接下來會看到誰?
- 如何使用微服務建立財產管理系統集成
- Egnyte 體系結構:構建和擴展多 PB 分布式系統的經驗教訓
- Zapier 如何自動化數十億個工作流自動化任務的旅程
- Jeff Dean 在 Google 進行大規模深度學習
- 如今 Etsy 的架構是什么樣的?
- 我們如何在 Mail.Ru Cloud 中實現視頻播放器
- Twitter 如何每秒處理 3,000 張圖像
- 每天可處理數百萬個請求的圖像優化技術
- Facebook 如何向 80 萬同時觀看者直播
- Google 如何針對行星級基礎設施進行行星級工程設計?
- 為 Mail.Ru Group 的電子郵件服務實施反垃圾郵件的貓捉老鼠的故事,以及 Tarantool 與此相關的內容
- The Dollar Shave Club Architecture Unilever 以 10 億美元的價格被收購
- Uber 如何使用 Mesos 和 Cassandra 跨多個數據中心每秒管理一百萬個寫入
- 從將 Uber 擴展到 2000 名工程師,1000 個服務和 8000 個 Git 存儲庫獲得的經驗教訓
- QuickBooks 平臺
- 美國大選期間城市飛艇如何擴展到 25 億個通知
- Probot 的體系結構-我的 Slack 和 Messenger Bot 用于回答問題
- AdStage 從 Heroku 遷移到 AWS
- 為何將 Morningstar 遷移到云端:降低 97%的成本
- ButterCMS 體系結構:關鍵任務 API 每月可處理數百萬個請求
- Netflix:按下 Play 會發生什么?
- ipdata 如何以每月 150 美元的價格為來自 10 個無限擴展的全球端點的 2500 萬個 API 調用提供服務
- 每天為 1000 億個事件賦予意義-Teads 的 Analytics(分析)管道
- Auth0 體系結構:在多個云提供商和地區中運行
- 從裸機到 Kubernetes
- Egnyte Architecture:構建和擴展多 PB 內容平臺的經驗教訓
- 縮放原理
- TripleLift 如何建立 Adtech 數據管道每天處理數十億個事件
- Tinder:最大的推薦引擎之一如何決定您接下來會看到誰?
- 如何使用微服務建立財產管理系統集成
- Egnyte 體系結構:構建和擴展多 PB 分布式系統的經驗教訓
- Zapier 如何自動化數十億個工作流自動化任務的旅程
- Jeff Dean 在 Google 進行大規模深度學習
- 如今 Etsy 的架構是什么樣的?
- 我們如何在 Mail.Ru Cloud 中實現視頻播放器
- Twitter 如何每秒處理 3,000 張圖像
- 每天可處理數百萬個請求的圖像優化技術
- Facebook 如何向 80 萬同時觀看者直播
- Google 如何針對行星級基礎設施進行行星級工程設計?
- 為 Mail.Ru Group 的電子郵件服務實施反垃圾郵件的貓捉老鼠的故事,以及 Tarantool 與此相關的內容
- The Dollar Shave Club Architecture Unilever 以 10 億美元的價格被收購
- Uber 如何使用 Mesos 和 Cassandra 跨多個數據中心每秒管理一百萬個寫入
- 從將 Uber 擴展到 2000 名工程師,1000 個服務和 8000 個 Git 存儲庫獲得的經驗教訓
- QuickBooks 平臺
- 美國大選期間城市飛艇如何擴展到 25 億條通知
- Probot 的體系結構-我的 Slack 和 Messenger Bot 用于回答問題
- AdStage 從 Heroku 遷移到 AWS
- 為何將 Morningstar 遷移到云端:降低 97%的成本
- ButterCMS 體系結構:關鍵任務 API 每月可處理數百萬個請求
- Netflix:按下 Play 會發生什么?
- ipdata 如何以每月 150 美元的價格為來自 10 個無限擴展的全球端點的 2500 萬個 API 調用提供服務
- 每天為 1000 億個事件賦予意義-Teads 的 Analytics(分析)管道
- Auth0 體系結構:在多個云提供商和地區中運行
- 從裸機到 Kubernetes
- Egnyte Architecture:構建和擴展多 PB 內容平臺的經驗教訓