
# 6 可視化數量
> 原文: [6 Visualizing amounts](https://serialmentor.com/dataviz/visualizing-amounts.html)
> 校驗:[飛龍](https://github.com/wizardforcel)
> 自豪地采用[谷歌翻譯](https://translate.google.cn/)
在許多情況下,我們對某些數字的大小感興趣。例如,我們可能需要想像不同品牌汽車的總銷量,或生活在不同城市的總人數,或從事不同運動的奧林匹克運動員的年齡。在所有這些情況下,我們都有一組類別(例如,汽車,城市或運動)和每個類別的定量值。我將這些情況稱為可視化數量,因為這些可視化中的主要重點將放在定量值的大小上。此場景中的標準可視化是條形圖,它有多種變體,包括簡單條形以及分組和堆疊條形。條形圖的替代方案是散點圖和熱圖。
## 6.1 條形圖
為了啟發條形圖的概念,請考慮特定周末最受歡迎電影的總票房銷量。表 6.1 顯示了 2017 年圣誕周末前五周的總票房銷量。電影“Star Wars: The Last Jedi”是本周末最受歡迎的電影,遠遠超過第四名和第五名的電影“The Greatest Showman”和“Ferdinand”差不多 10 倍。
表 6.1:2017 年 12 月 22 日至 24 日周末的最高票房電影。數據來源:[Box Office Mojo](http://www.boxofficemojo.com/),經許可使用
| 排名 | 標題 | 周末總票房 |
| :-: | :-- | --: |
| 1 | Star Wars: The Last Jedi | $71,565,498 |
| 2 | Jumanji: Welcome to the Jungle | $36,169,328 |
| 3 | Pitch Perfect 3 | $19,928,525 |
| 4 | The Greatest Showman | $8,805,843 |
| 5 | Ferdinand | $7,316,746 |
這種數據通常用垂直條形圖顯示。對于每部電影,我們繪制一個從零開始的條形圖,并一直延伸到該電影的周末總值的美元值(圖 6.1)。該可視化稱為條形圖。
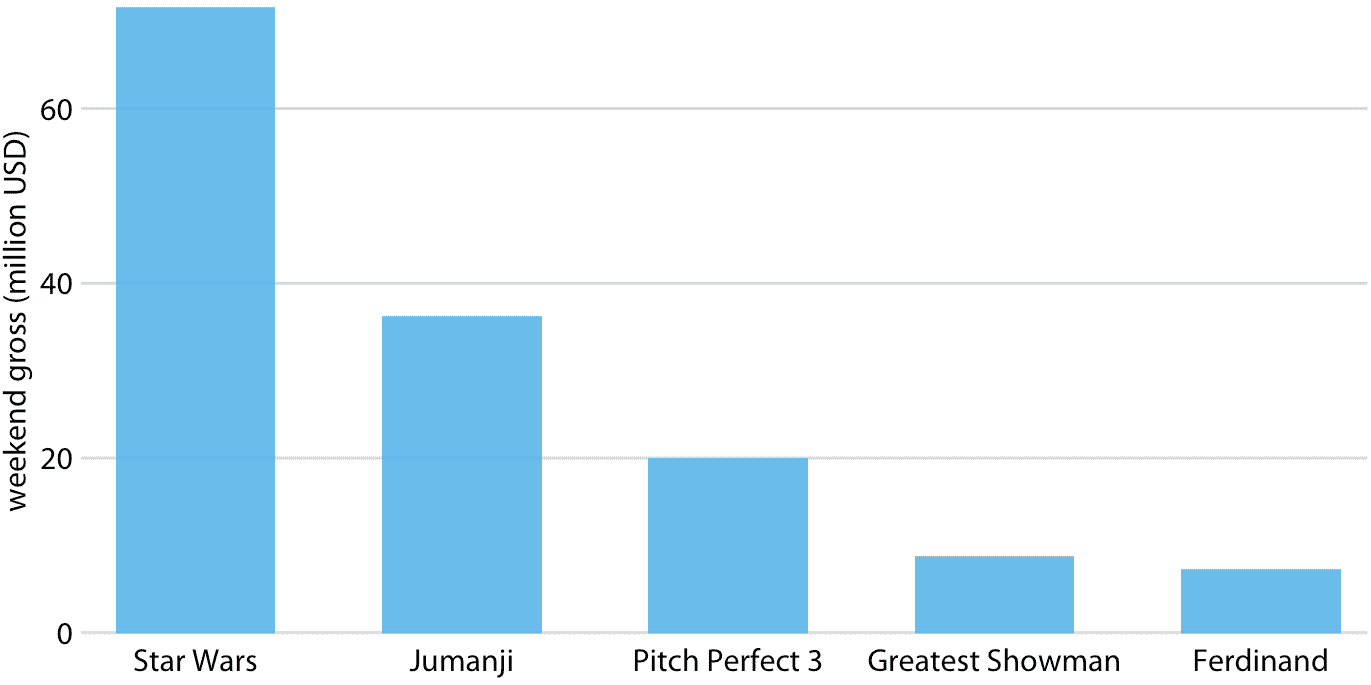
圖 6.1:2017 年 12 月 22 日至 24 日周末的最高票房電影。數據來源:[Box Office Mojo](http://www.boxofficemojo.com/),經許可使用
我們通常遇到的垂直條形的一個問題是,標注每個條形的標簽占用了大量的水平空間。事實上,我不得不將圖 6.1 設置得相當寬,并將條形的間距變大,以便我可以將電影標題放在下面。為了節省水平空間,我們可以將條形放在一起并旋轉標簽(圖 6.2 )。但是,我不是旋轉標簽的大力支持者。我發現最終的繪圖很難閱讀。而且,根據我的經驗,每當標簽太長而不能水平放置時,它們看起來也不好看。
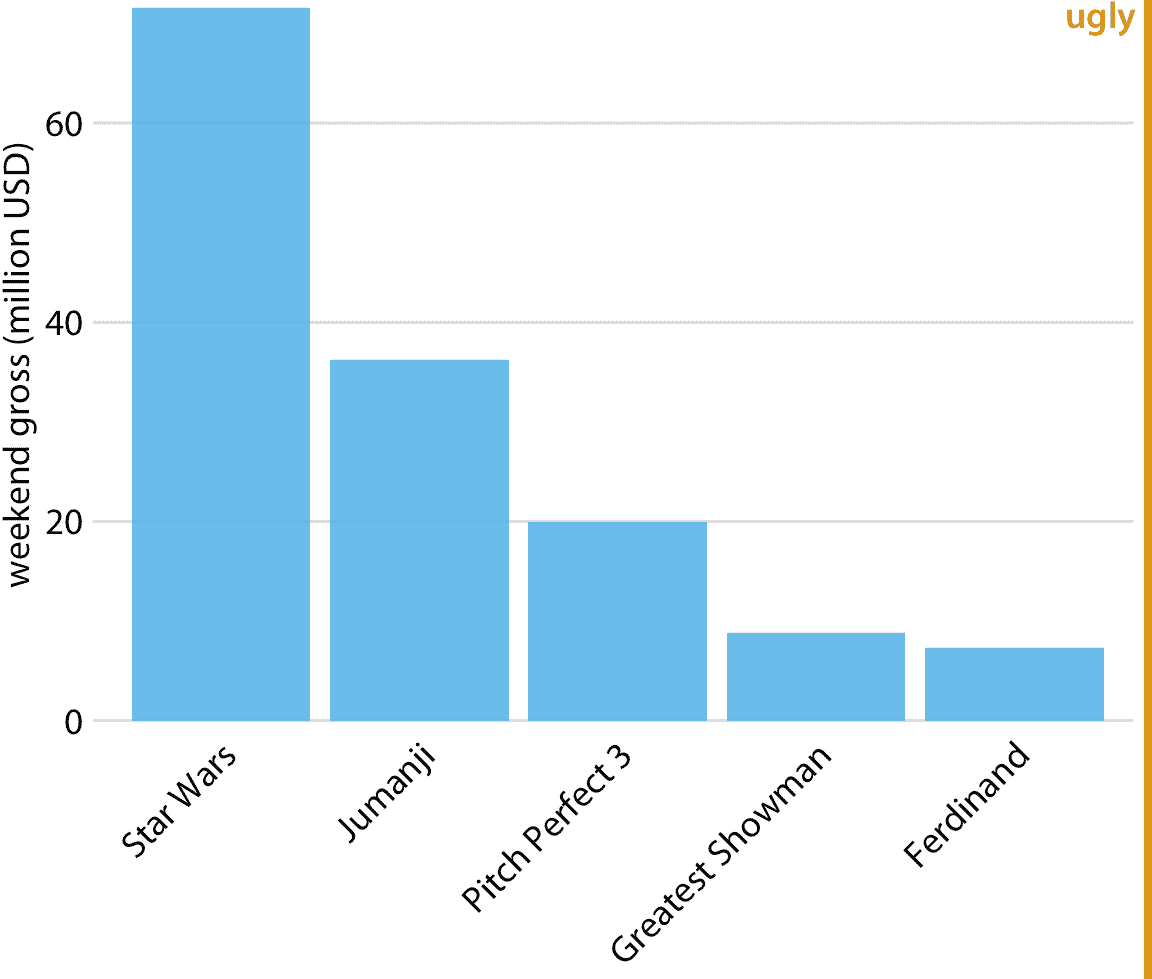
圖 6.2:2017 年 12 月 22 日至 24 日周末的最高票房電影,顯示為帶有旋轉軸刻度標簽的條形圖。旋轉軸刻度標簽往往難以閱讀,并且需要使用繪圖下方的笨拙的空間。出于這些原因,我通常認為旋轉刻度標簽的圖形很難看。數據來源:[Box Office Mojo](http://www.boxofficemojo.com/),經許可使用
長標簽的更好解決方案通常是交換 *x* 和 *y* 軸,使條形水平放置(圖 6.3)。在交換軸之后,我們獲得了一個緊湊的圖形,其中所有可視元素(包括所有文本)都是水平方向的。因此,該圖比圖 6.2 或甚至圖 6.1 更容易閱讀。
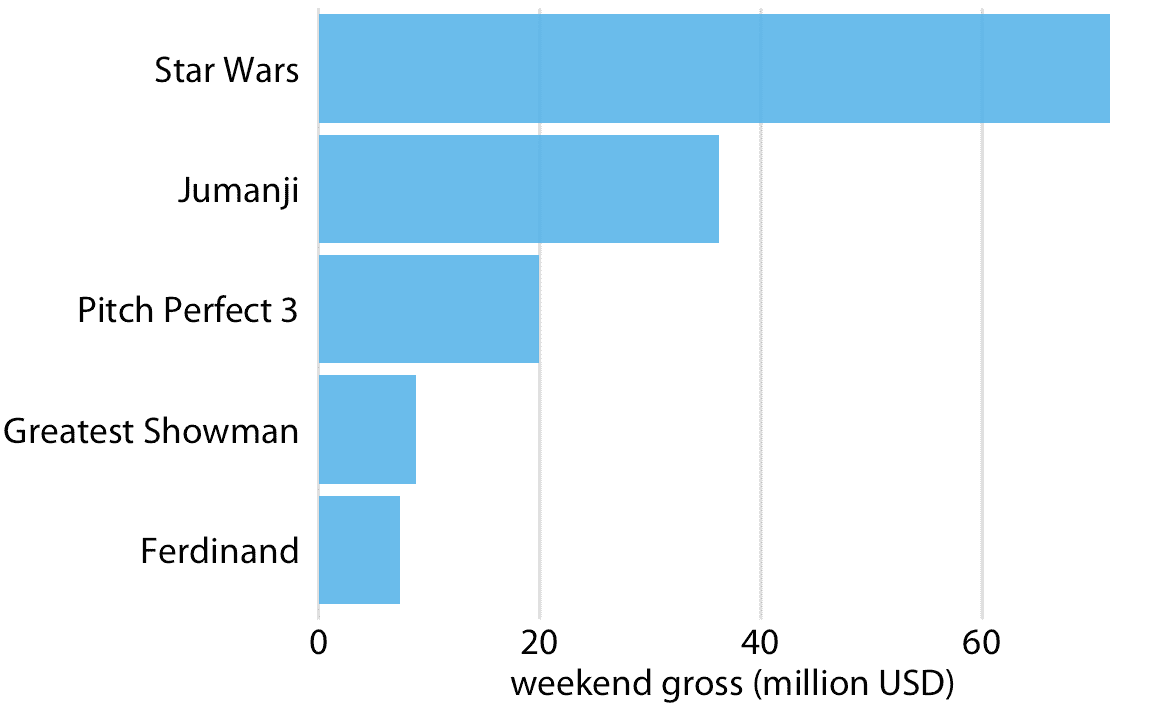
圖 6.3:2017 年 12 月 22 日至 24 日周末的最高票房電影,顯示為水平條形圖。數據來源:Box Office Mojo( [http://www.boxofficemojo.com/](http://www.boxofficemojo.com/) )。經許可使用
無論我們是垂直還是水平放置條形,我們都需要注意條形排列的順序。我經常看到條形圖,其中條形圖是任意排列的,或者是在圖形的上下文中沒有意義的某些標準。一些繪圖程序默認按標簽的字母順序排列條形圖,其他類似的任意排列也是可能的(圖 6.4 )。一般而言,所得到的數字比按其大小排列的條形圖更加混亂且不太直觀。
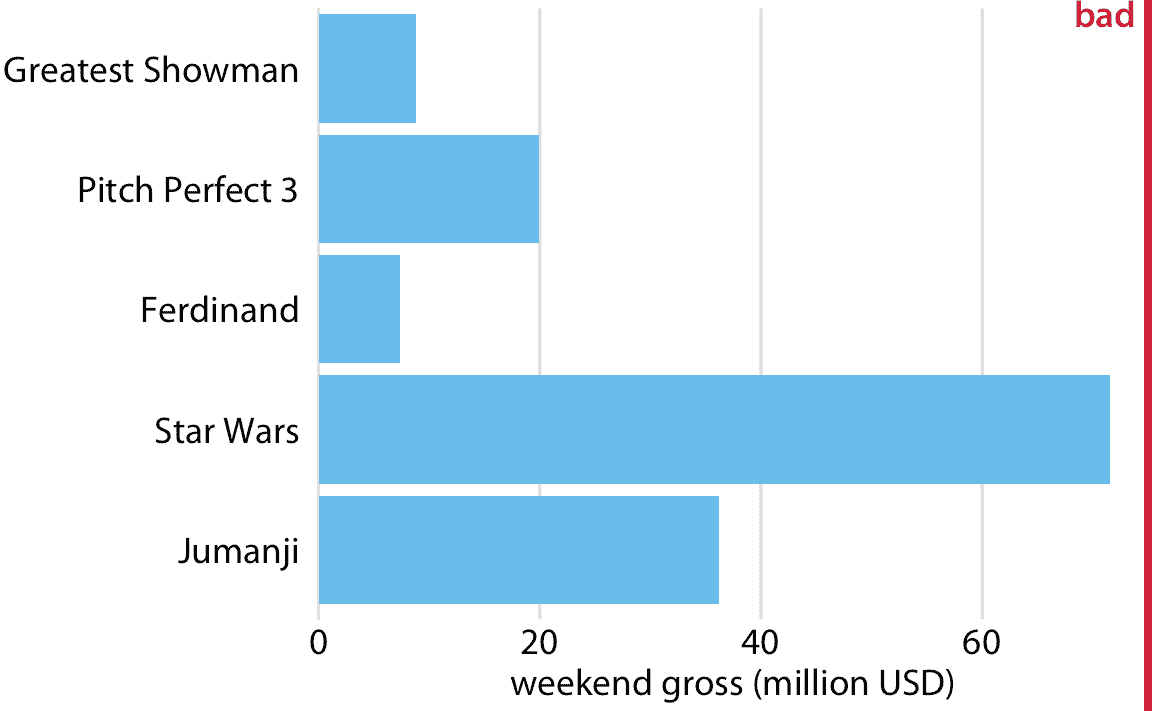
圖 6.4:2017 年 12 月 22 日至 24 日周末的最高票房電影,顯示為水平條形圖。這里,條形按照電影標題長度降序排列。這種條形排列是任意的,它沒有用于有意義的目的,并且它使得所得圖形比圖 6.3 更不直觀。數據來源:[Box Office Mojo](http://www.boxofficemojo.com/),經許可使用
然而,當條形表示的類別沒有自然排序時,我們應該僅僅重新排列條形。每當存在自然排序時(即,當我們的類別變量是有序因子時),我們應該在可視化中保留該排序。例如,圖 6.5 顯示了按年齡組劃分的美國年收入中位數。在這種情況下,條形應按年齡升序排列。按照條形高度排序同時改變年齡組是沒有意義的(圖 6.6)。
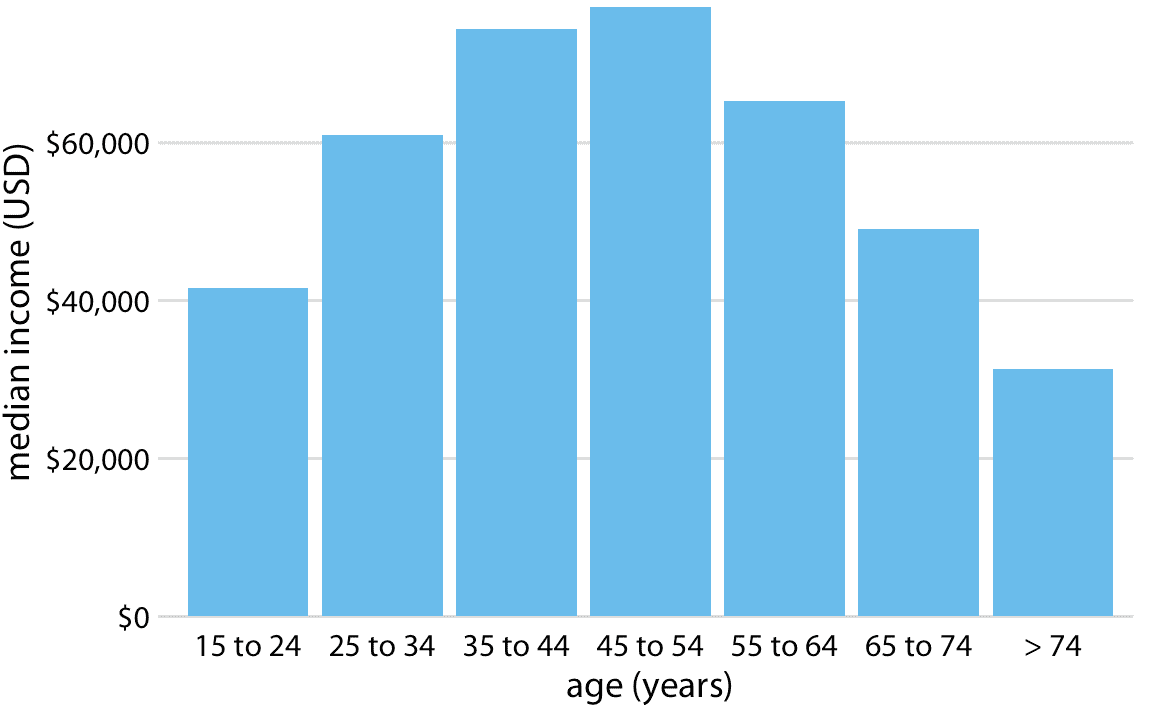
圖 6.5:2016 年美國家庭年收入中位數,按年齡組劃分。 45-54 歲年齡組的收入中位數最高。數據來源:美國人口普查局
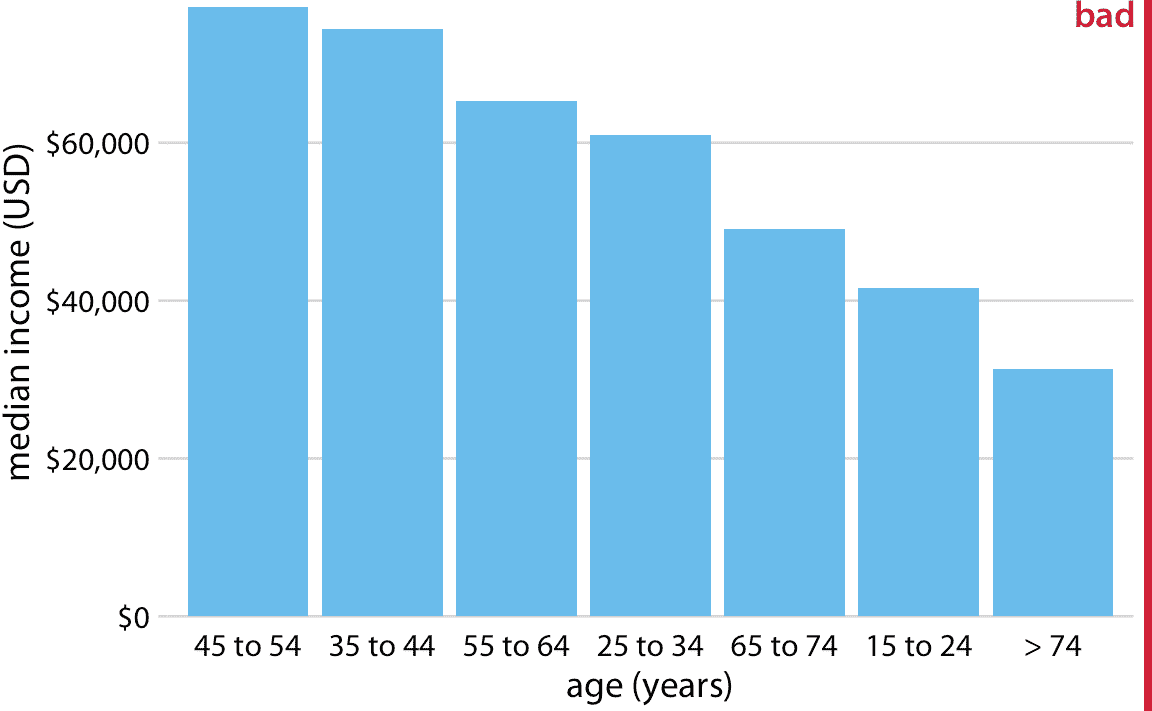
圖 6.6:2016 年美國家庭年收入中位數,按年齡組年齡組,按收入排序。雖然這種條形的順序看起來很有吸引力,但是年齡組的順序現在令人困惑。數據來源:美國人口普查局
注意條形順序。如果條形表示無序類別,則按照數據值的升序或降序對它們進行排序。
## 6.2 分組和堆疊條形
前一小節中的所有示例都顯示了定量數量如何根據一個類別變量而變化。然而,我們經常同時對兩個類別變量感興趣。例如,美國人口普查局提供按年齡和種族劃分的收入中位數。我們可以用分組條形圖(圖 6.7)可視化該數據集。在分組條形圖中,我們在 *x* 軸的每個位置繪制一組條形圖,由一個類別變量確定,然后我們根據另一個類別變量在每個組內繪制條形圖。
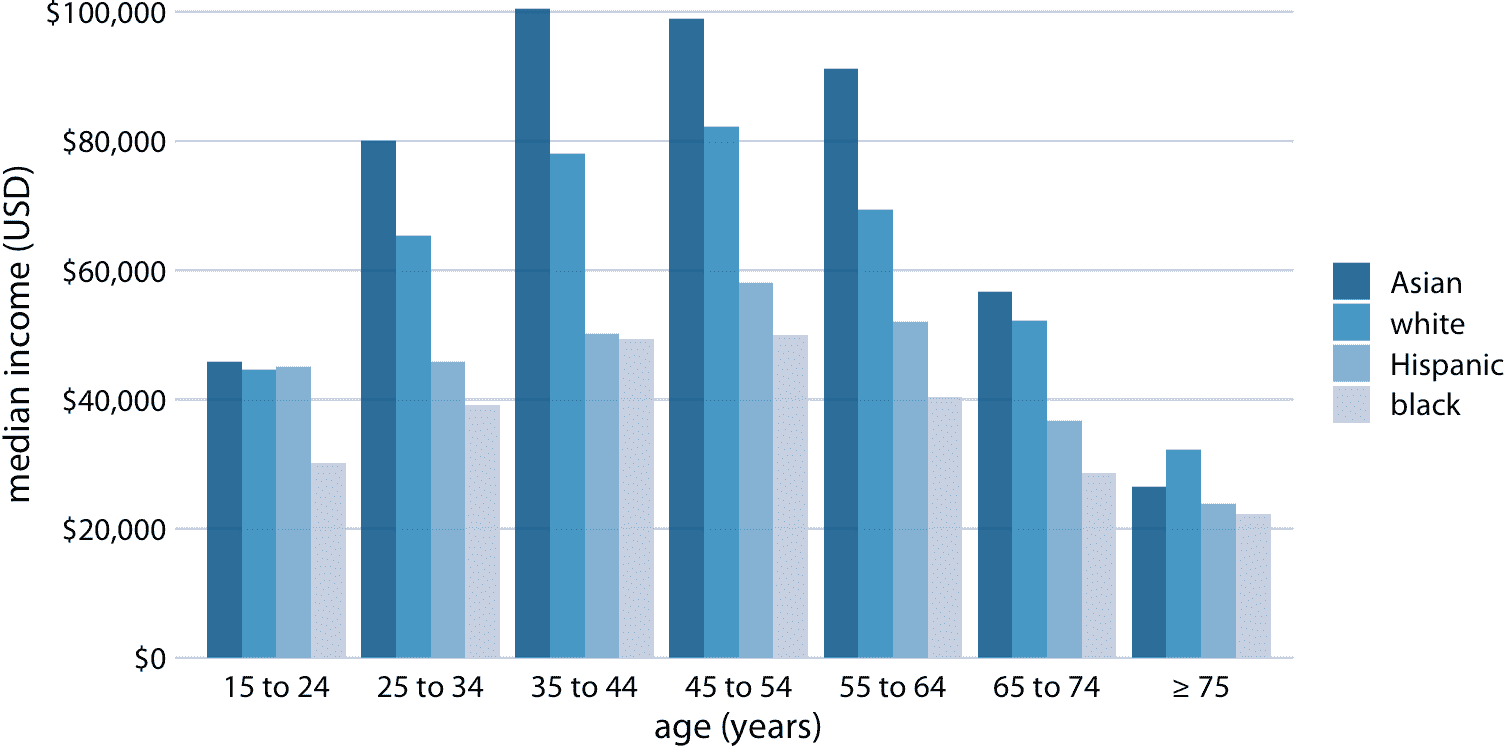
圖 6.7:2016 年美國家庭年收入中位數,按年齡組和種族劃分。年齡組沿著 *x* 軸顯示,并且對于每個年齡組,有四個條形,分別對應于亞洲人,白人,拉美人和黑人的收入中位數。數據來源:美國人口普查局
分組條形圖一次顯示大量信息,它們可能令人困惑。事實上,即使我沒有將圖 6.7 標記為壞或丑,我覺得很難閱讀。特別是,對于特定的種族分組,很難比較不同年齡組的收入中位數。因此,只有當我們主要關注種族分組的收入水平差異(分別針對特定年齡組)時,這個圖形才適用。如果我們更關心種族分組收入水平的總體模式,可能最好沿著 *x* 軸顯示種族,并在每個種族分組中顯示年齡為不同的條形圖(圖 6.8)。
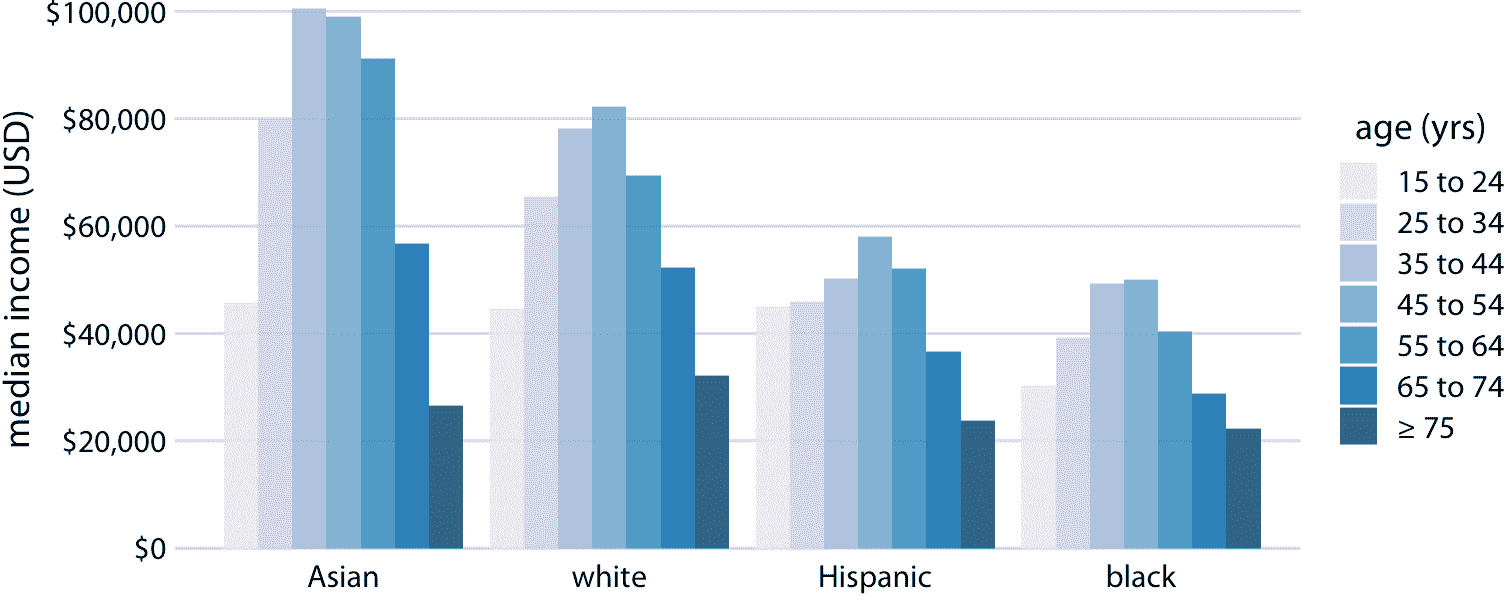
圖 6.8:2016 年美國家庭年收入中位數,按年齡組和種族劃分。與圖 6.7 相反,現在沿著 *x* 軸顯示種族,并且對于每個種族,我們根據七個年齡組顯示七個條形。數據來源:美國人口普查局
圖 6.7 和 6.8 均沿著 *x* 軸的位置編碼一個類別變量,另一個按條形顏色編碼。在這兩種情況下,按位置編碼都很容易閱讀,而按條顏色編碼則需要更多精力,因為我們必須在精神上匹配條形圖顏色與圖例中的顏色。我們可以通過顯示四個單獨的常規條形圖而不是一個分組條形圖來避免這種額外的心理負擔(圖 6.9)。我們選擇哪種不同的選擇最終是品味問題。我可能會選擇圖 6.9 ,因為它避免了不同條形顏色的需要。
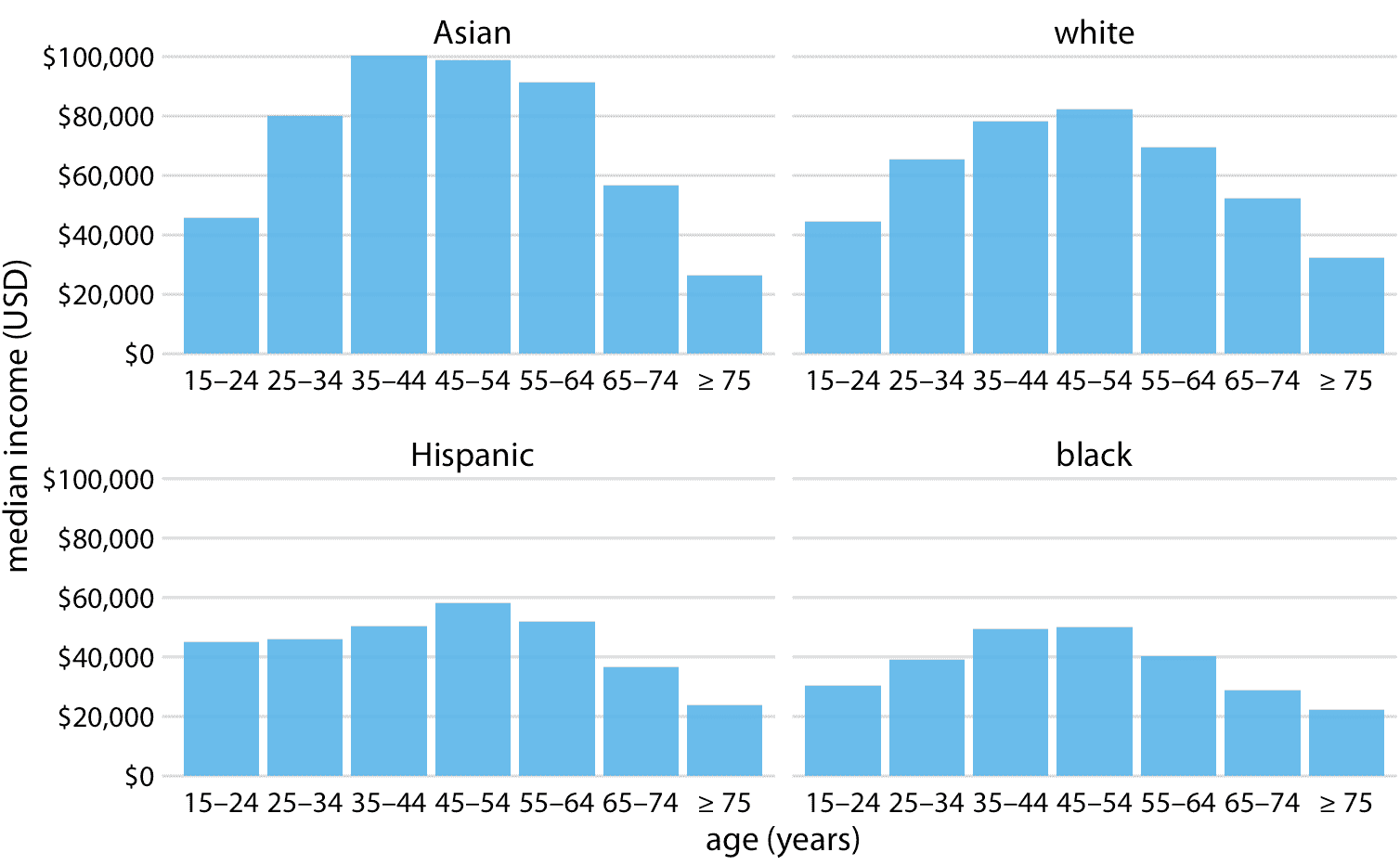
圖 6.9:2016 年美國家庭年收入中位數,按年齡組和種族劃分。我們現在將數據顯示為四個單獨的常規條形圖,而不是將這些數據顯示為分組條形圖,如圖 6.7 和 6.8 。這種選擇的優點是,我們不需要用條形顏色編碼類別變量。數據來源:美國人口普查局
比起并排繪制條組,有時最好將條形堆疊在一起。當各個堆疊條形表示的數量之和本身就是一個有意義的數量時,堆疊就很有用。因此,雖然堆疊圖 6.7 的中位收入值(兩個中位收入值的總和不是一個有意義的值)是沒有意義的,但堆疊圖 6.1 的周末總值可能是有意義的。 (兩部電影的周末總值之和是這兩部電影合計的總票數)。當單個條形表示計數時,堆疊也是合適的。例如,在人口數據集中,我們可以單獨統計男性或女性,也可以將它們統計在一起。如果我們在表示男性人數的條形圖上堆疊代表女性人數的條形圖,則組合條形的高度表示不論性別的人數。
我將使用 1912 年 4 月 15 日沉沒的跨大西洋遠洋輪船泰坦尼克號乘客的數據集來證明這一原則。船上約有 1300 名乘客,不包括船員。乘客在三個艙位(第一,第二或第三)中的一個旅行,并且船上的女性乘客幾乎是男性的兩倍。為了按艙位和性別可視化乘客的細分,我們可以為每個艙位和性別繪制單獨的條形圖,然后對于每個艙位,將代表男性的條形圖堆疊在代表女性的條形圖上(圖 6.10)。組合條形代表每個艙位的乘客總數。
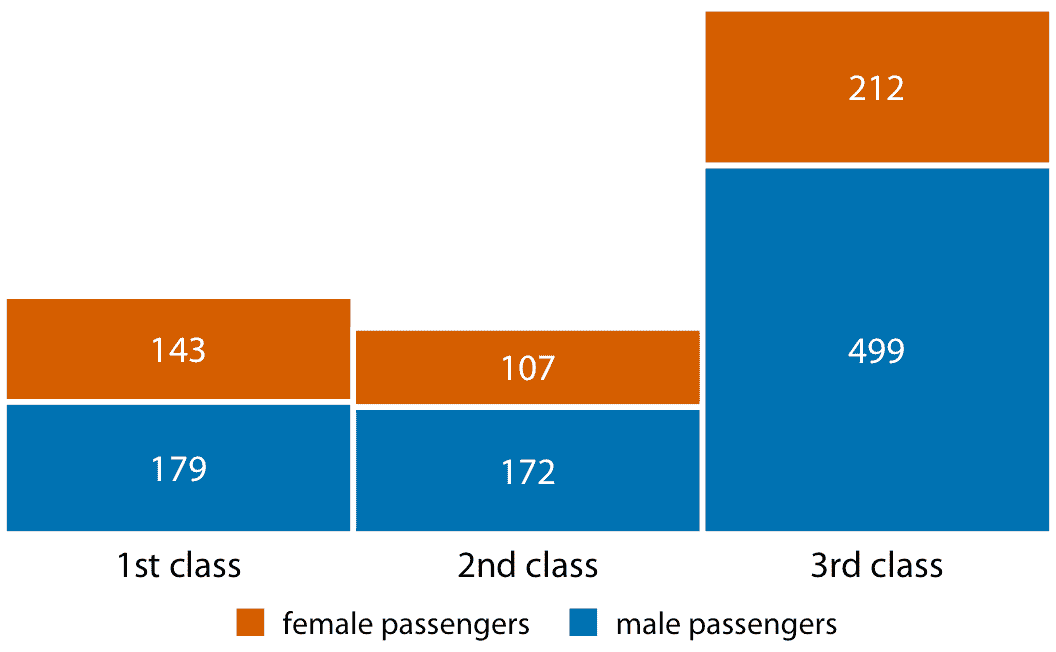
圖 6.10:泰坦尼克號的一,二,三等艙的男女乘客人數。
圖 6.10 與我之前顯示的條形圖的不同之處在于沒有明確的 *y* 軸。我已經顯示了每個條形代表的實際數值。每當繪圖僅顯示少量不同的值時,將實際數字添加到繪圖中是有意義的。這大大增加了繪圖傳達的信息量,而沒有增加太多的視覺噪聲,并且它消除了對顯式 *y* 軸的需要。
## 6.3 點圖和熱圖
條形圖不是可視化數量的唯一選項。條形的一個重要限制是它們需要從零開始,因此條形長度與所示數量成比例。對于某些數據集,這可能不切實際或可能會模糊關鍵特征。在這種情況下,我們可以通過在 *x* 或 *y* 軸的適當位置放置點來指示數量。
圖 6.11 展示了這種可視化方法,用于美洲 25 個國家的預期壽命數據集。這些國家的公民的預期壽命在 60 到 81 歲之間,每個人的預期壽命值在 *x* 軸的適當位置顯示為藍點。通過將軸范圍限制在 60 至 81 年的區間,該圖突出了該數據集的主要特征:加拿大在所有列出的國家中,具有最高的預期壽命,而玻利維亞和海地的預期壽命遠低于所有其他國家。如果我們使用了條形而不是點(圖 6.12),我們已經做了一個不太引人注目的圖形。因為這個圖中的條形很長,并且它們都具有幾乎相同的長度,所以眼睛被吸引到條形的中間而不是它們的端點,并且該圖形無法傳達其信息。

圖 6.11:2007 年美洲國家的預期壽命。數據來源:Gapminder 項目

圖 6.12:2007 年美洲國家的預期壽命,以條形圖形示。此數據集不適合用條形圖顯示。這些條形太長了,他們將注意力從數據的關鍵特征,不同國家的預期壽命差異中吸引過來。數據來源:Gapminder 項目
然而,無論我們使用條形還是圓形,我們都需要注意數據值的排序。在圖 6.11 和 6.12 中,各國按照預期壽命的降序排列。如果我們按字母順序對它們進行排序,我們最終會得到混亂的點云,這些點令人困惑并且無法傳達明確的信息(圖 6.13)。

圖 6.13:2007 年美洲國家的預期壽命。這里,按字母順序排列國家,這會導致點成無序的點云。這使得圖形難以閱讀,因此它應該被標記為“不好”。數據來源:Gapminder 項目
到目前為止,所有示例都沿位置刻度,按照地點表示數量,通過條形的終點或點的位置。對于非常大的數據集,這些選項都不合適,因為所得圖形會變得太密集。我們已經在圖 6.7 中看到,僅僅七組四個數據值可能會導致圖形復雜且不易閱讀。如果我們有 20 組 20 個數據值,那么類似的圖形可能會非常混亂。
作為通過條形或點將數據值映射到位置的替代方法,我們可以將數據值映射到顏色上。這樣的圖稱為熱圖。圖 6.14 使用這種方法顯示了 1994 年到 2016 年的 23 年中,20 個國家的互聯網用戶的百分比。雖然這種可視化使得更難確定所顯示的確切數據值(例如,2015 年美國互聯網用戶的確切百分比是多少?),它突出了更廣泛的趨勢。我們可以清楚地看到,哪些國家早期開始使用互聯網,哪些國家沒有,我們也可以清楚地看到,哪些國家在數據集覆蓋的最后一年(2016 年)具有較高的互聯網滲透率。
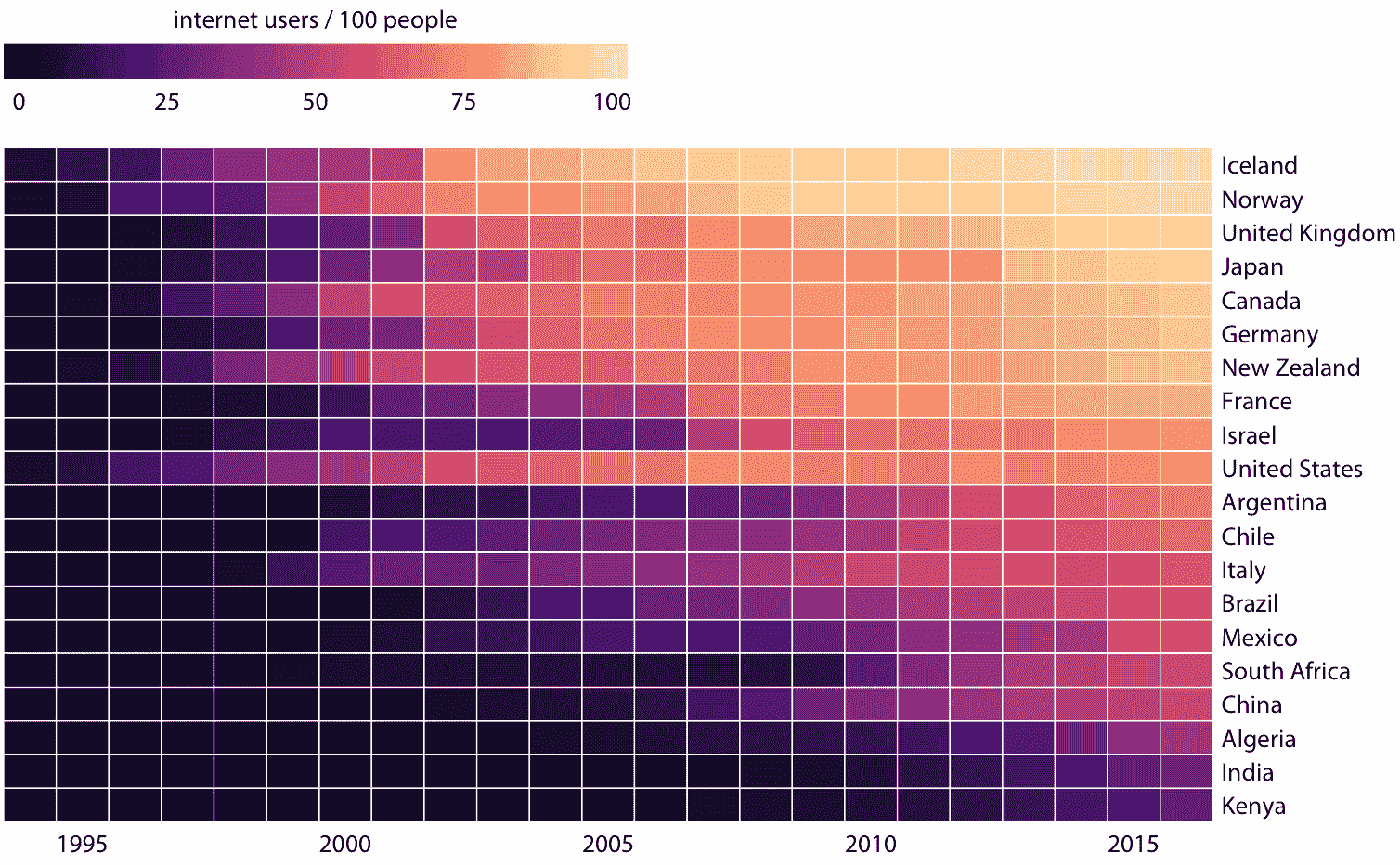
圖 6.14:部分國家/地區的互聯網使用情況。顏色表示相應國家/地區的互聯網用戶的百分比。國家按 2016 年的互聯網用戶百分比排序。數據來源:世界銀行
與本章討論的所有其他可視化方法一樣,我們需要在制作熱圖時,注意類別數據值的順序。在圖 6.14 中,各國按 2016 年互聯網使用的百分比排序。此順序將英國,日本,加拿大和德國置于美國之上,因為所有這些國家在 2016 年的互聯網普及率都比美國高,雖然美國在較早的時候具有大量的互聯網使用。或者,我們可以通過他們的互聯網使用的起始時間來排序國家。在圖 6.15 中,各國按照互聯網使用率首次上升至 20% 以上的年份進行排序。在這個圖形中,美國從頂部落到了第三位,與互聯網使用的起始時間相比,它突出了 2016 年的互聯網的相對較低的使用率。意大利也可以看到類似的模式。相比之下,以色列和法國起步較晚,但迅速取得了進展。
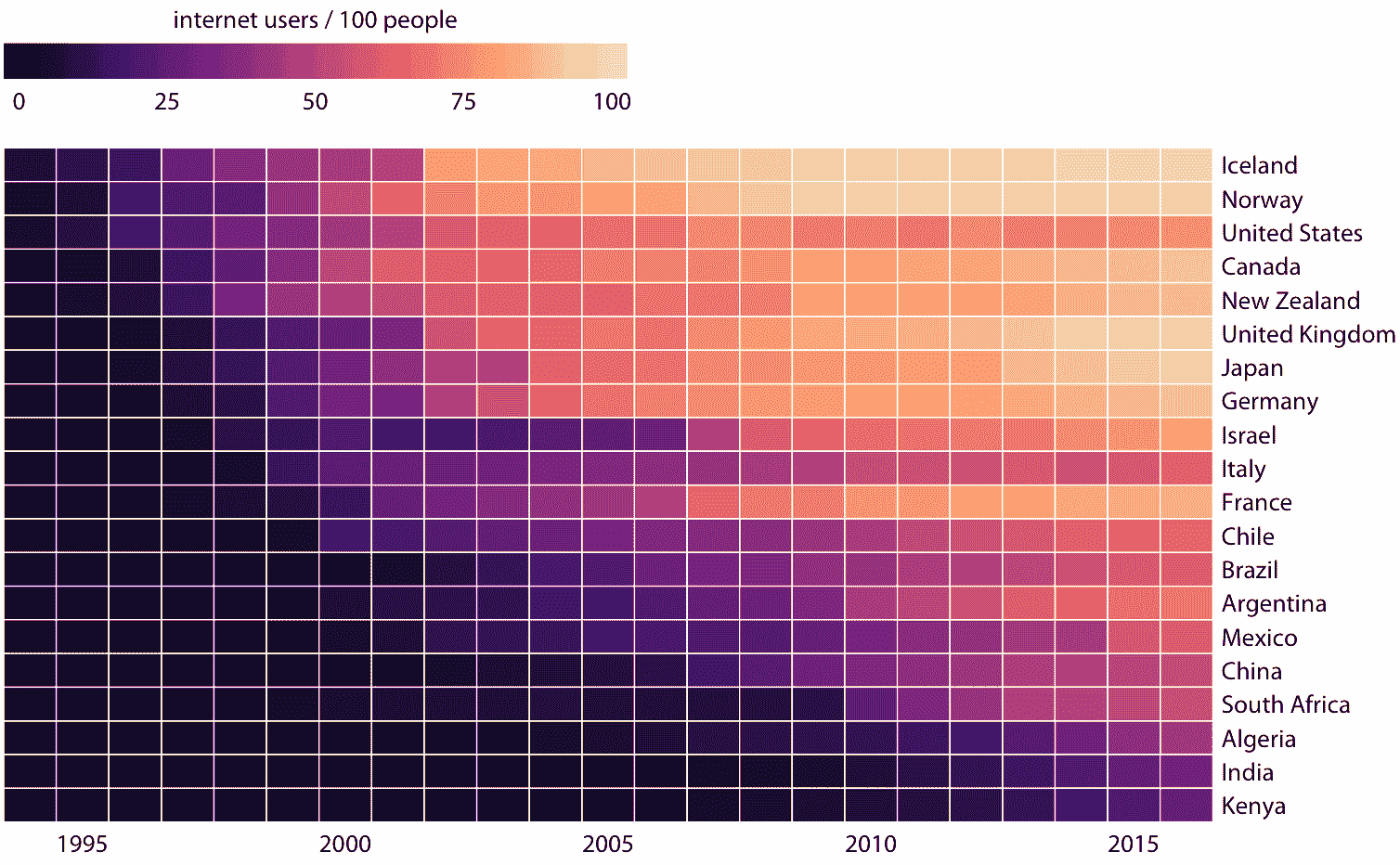
圖 6.15:針對特定國家/地區的互聯網使用情況。按照互聯網使用率首次超過 20% 的年份排序國家。數據來源:世界銀行
圖 6.14 和 6.15 都是數據的有效表示。哪一個是首選取決于我們想傳達的故事。如果我們的故事關于 2016 年的互聯網使用,那么圖形 6.14 可能是更好的選擇。但是,如果我們的故事是相對于當前的使用,互聯網使用的時間是早還是晚,那么圖 6.15 是優選的。
- 數據可視化的基礎知識
- 歡迎
- 前言
- 1 簡介
- 2 可視化數據:將數據映射到美學上
- 3 坐標系和軸
- 4 顏色刻度
- 5 可視化的目錄
- 6 可視化數量
- 7 可視化分布:直方圖和密度圖
- 8 可視化分布:經驗累積分布函數和 q-q 圖
- 9 一次可視化多個分布
- 10 可視化比例
- 11 可視化嵌套比例
- 12 可視化兩個或多個定量變量之間的關聯
- 13 可視化自變量的時間序列和其他函數
- 14 可視化趨勢
- 15 可視化地理空間數據
- 16 可視化不確定性
- 17 比例墨水原理
- 18 處理重疊點
- 19 顏色使用的常見缺陷
- 20 冗余編碼
- 21 多面板圖形
- 22 標題,說明和表格
- 23 平衡數據和上下文
- 24 使用較大的軸標簽
- 25 避免線條圖
- 26 不要走向 3D
- 27 了解最常用的圖像文件格式
- 28 選擇合適的可視化軟件
- 29 講述一個故事并提出一個觀點
- 30 帶注解的參考書目
- 技術注解
- 參考