
# 10 可視化比例
> 原文: [10 Visualizing proportions](https://serialmentor.com/dataviz/visualizing-proportions.html)
> 校驗:[飛龍](https://github.com/wizardforcel)
> 自豪地采用[谷歌翻譯](https://translate.google.cn/)
我們經常想要展示一些分組,實體或金額如何分解成單個部分,各自代表整體的一部分。常見的例子包括一群人中的男女比例,選舉中不同政黨投票的百分比,或公司的市場份額。這種可視化的原型是餅圖,在任何業務演示中無所不在,并且在數據科學家中備受詬病。正如我們將要看到的,可視化比例可能具有挑戰性,特別是當整體被分成許多不同的部分,或者我們希望看到不同部分隨時間或條件變化的時候。沒有一種理想的可視化方法始終有效。為了說明這個問題,我將討論一些不同的場景,每個場景都需要不同類型的可視化。
請記住:您始終需要選擇最適合您的特定數據集的可視化,并突出顯示您要顯示的關鍵數據特征。
## 10.1 餅圖的一個案例
從 1961 年到 1983 年,德國議院(稱為 Bundestag)由三個不同黨派的成員組成,CDU/CSU,SPD 和 FDP。在大部分時間里,CDU/CSU 和 SPD 的席位數量大致相當,而 FDP 通常只占一小部分席位。例如,在 1976 年至 1980 年的第 8 屆聯邦議會中,CDU/CSU 共有 243 個席位,SPD 有 214,FDP 有 39,共計 496 個。這種議會數據最常以餅圖可視化(圖 10.1)。
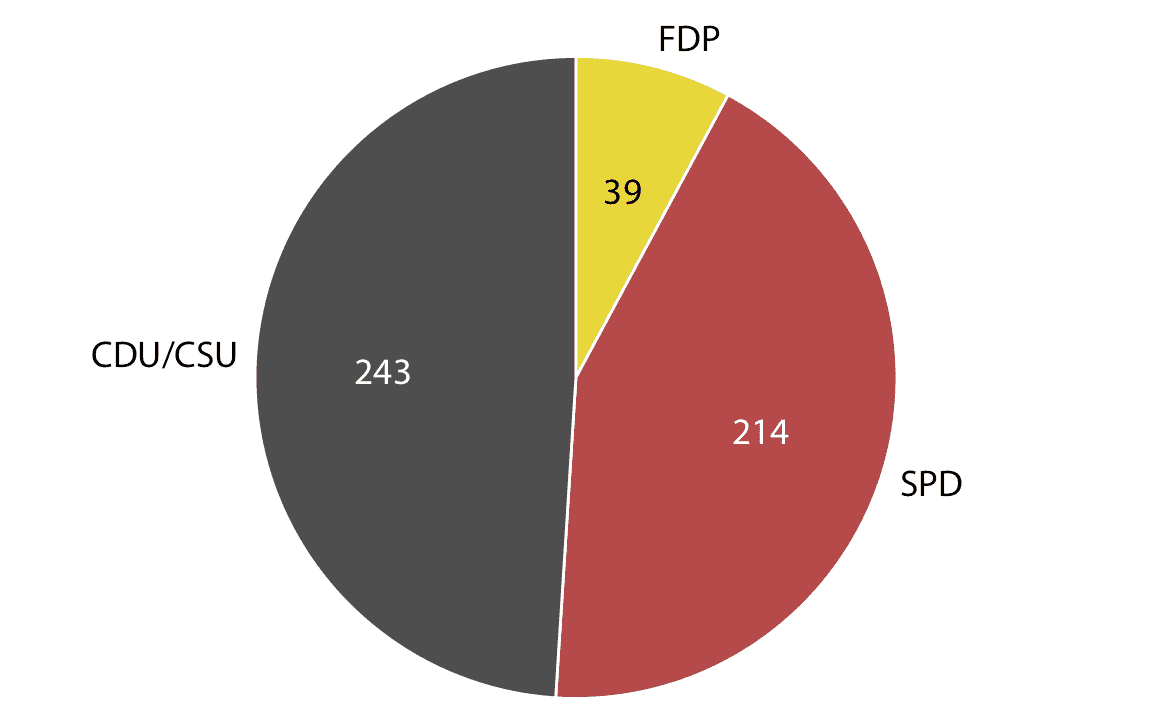
圖 10.1:1976 年至 1980 年第 8 屆德國聯邦議院的黨派組成,可視化為餅圖。這種可視化清楚地表明,SPD 和 FDP 的執政聯盟與反對派 CDU/CSU 相比多一小部分。
餅圖將圓圈分成切片,使得每個切片的面積與其表示的總體比例成正比。可以在矩形上執行相同的過程,結果是堆疊條形圖(圖 10.2 )。根據我們是垂直還是水平切割條形,我們獲得垂直堆疊的條形圖(圖 10.2 a)或水平堆疊的條形圖(圖 10.2 b)。

圖 10.2:1976 年至 1980 年第 8 屆德國聯邦議院的黨派組成,可視化為堆疊條形。 (a)垂直堆疊的條形。 (b)水平堆疊的條形。 SPD 和 FDP 共同擁有的席位并不比 CDU / CSU 更明顯。
我們也可以從圖 10.2a 中取出它們并將它們并排放置,而不是將它們堆疊在一起。這種可視化使得更容易直接比較三組,但它模糊了數據的其他方面(圖 10.3)。最重要的是,在并排條形圖中,每個條形與總數的關系在視覺上并不明顯。
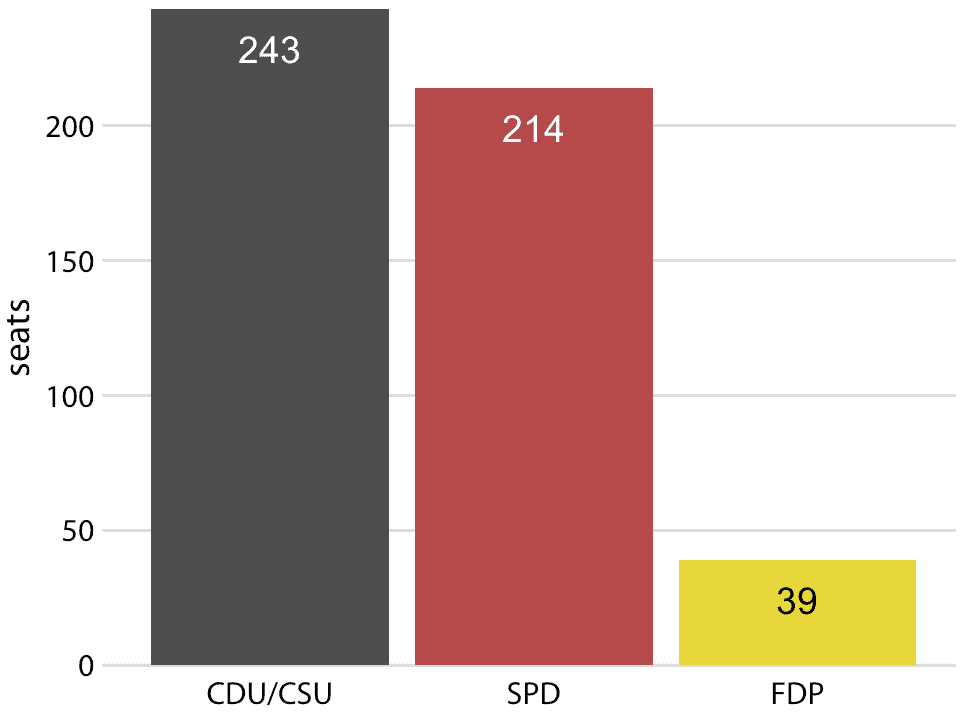
圖 10.3:1976 年至 1980 年第 8 屆德國聯邦議院的黨派組成,可視化為并排的條形。如圖 10.2 所示,SPD 和 FDP 共同擁有的席位并不比 CDU / CSU 更明顯。
許多作者斷然拒絕餅圖并贊成并排或堆疊條形圖。其他人則在某些應用中堅持使用餅圖。我個人認為,這些可視化中沒有一個比任何其他可視化都優越。根據數據集的特征和您想要講述的具體故事,您可能希望采用一種或另一種方法。在第 8 屆德國聯邦議院的情況下,我認為餅圖是最好的選擇。它清楚地表明,SPD 和 FDP 的共同執政聯盟比 CDU / CSU 多一小部分(圖 10.1)。在任何其他圖中,這一事實在視覺上并不明顯(圖 10.2 和 10.3)。
通常,當目標是強調簡單比例(例如,一半,三分之一或四分之一)時,餅圖效果很好。當我們有非常小的數據集時,它們也能工作得很好。單個餅圖,如圖 10.1 ,看起來很好,但是如圖 10.2a 中的單列堆疊條形看起來很尷尬。另一方面,堆疊條形可以用于多個條件或時間序列的并排比較,并且當我們想要直接比較各個部分時,并排條形是優選的。表 10.1 中提供了餅圖,堆疊條形和并排條形的各種優缺點的摘要。
表 10.1:可視化比例的常用方法的利弊:餅圖,堆疊條形圖和并排條形圖。
| | 餅圖 | 堆疊條形圖 | 并排條形圖 |
| --- | :-: | :-: | :-: |
| 將數據清楚地可視化為整體的比例 | ? | ? | ? |
| 可以輕松直觀地比較相對比例 | ? | ? | ? |
| 視覺上強調簡單的比例,例如 1/2, 1/3, 1/4 | ? | ? | ? |
| 即使對于非常小的數據集,看起來也很吸引人 | ? | ? | ? |
| 當整體被分成許多部分時效果很好 | ? | ? | ? |
| 適用于多組比例或時間序列比例的可視化 | ? | ? | ? |
## 10.2 并排條形的情況
我現在將演示餅圖失敗的情況。這個例子是在最初發布在維基百科(維基百科 2007)上的餅圖評論之后建模的。考慮五家公司 A,B,C,D 和 E 的假設情景,他們的市場份額大致相當于約 20%。我們的假設數據集連續三年列出了每家公司的市場份額。當我們使用餅圖可視化此數據集時,很難看到究竟發生了什么(圖 10.4)。似乎公司 A 的市場份額正在增長,而公司 E 的市場份額正在縮小,但這一觀察結果之外,我們無法分辨出正在發生的事情。特別是,目前尚不清楚不同公司的市場份額在每年內具體如何。
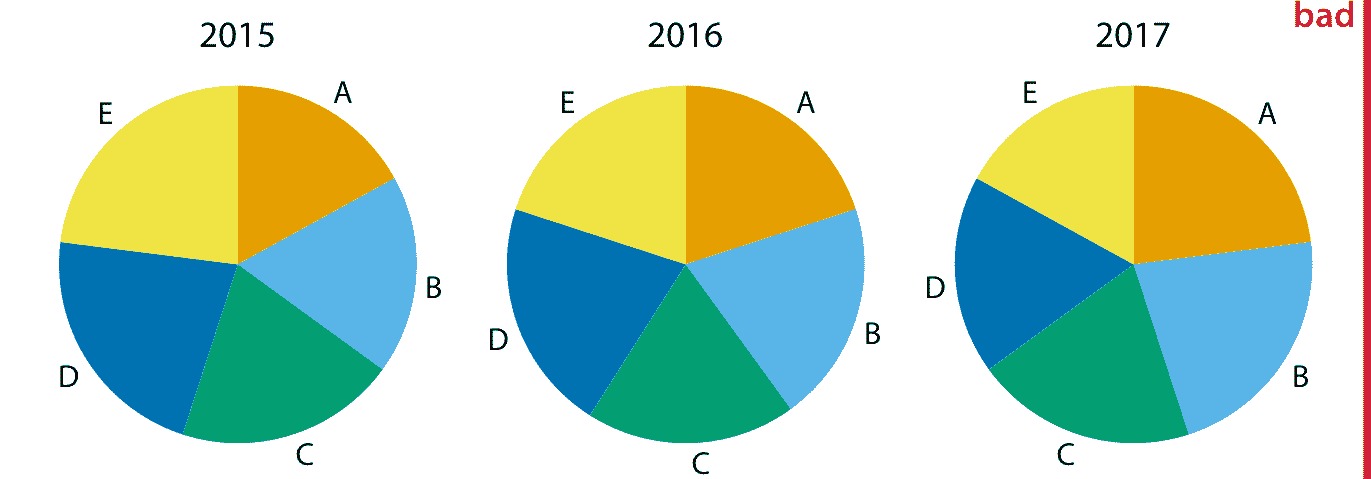
圖 10.4:2015 - 2017 年五個假設公司 A-E 的市場份額,可視化為餅圖。這種可視化有兩個主要問題:1、幾年內相對市場份額的比較幾乎是不可能的,2、很難看到多年來市場份額的變化。
當我們切換到堆疊條形圖時,圖像會變得更清晰(圖 10.5)。現在,A 公司不斷增長的市場份額和 E 公司萎縮的市場份額的趨勢清晰可見。但是,每年五家公司的相對市場份額仍難以比較。并且很難比較多年之內公司 B,C 和 D 的市場份額,因為這些條形在多年之內相對于彼此平移。這是堆疊條形圖的一般問題,也是我通常不推薦這種可視化的主要原因。

圖 10.5:2015-2017 年五家假設公司的市場份額,可視化為堆疊條形圖。這種可視化有兩個主要問題:1、難以比較多年內的相對市場份額,2、很難看到中間的公司 B,C 和 D 多年內市場份額的變化,因為金色條形的位置會隨著年份而變化。
對于這個假設數據集,并排條形是最佳選擇(圖 10.6 )。這種可視化突出顯示,公司 A 和 B 都在 2015 年至 2017 年間增加了市場份額,而公司 D 和 E 都減少了他們的市場份額。它還顯示 A 公司到 E 公司的 2015 年市場份額依次增加,2017 年同樣下降。
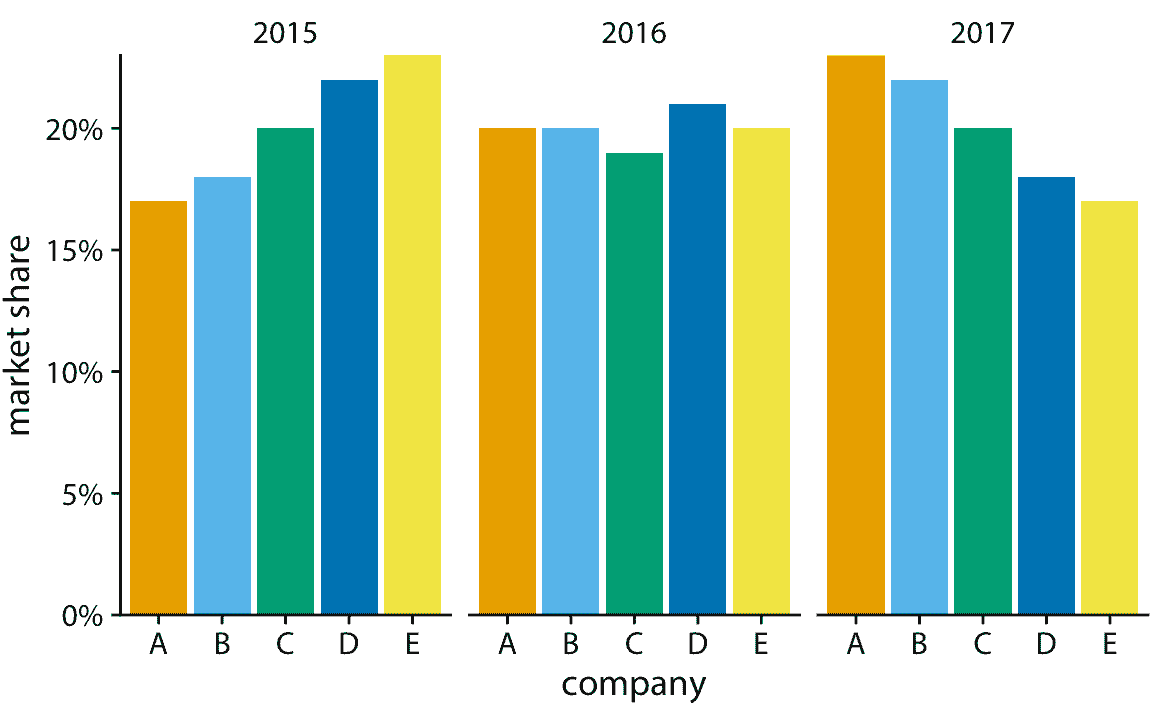
圖 10.6:2015-2017 年五家假設公司的市場份額,可視化為并排條形圖。
## 10.3 堆疊條和堆疊密度圖的情況
在 10.2 一節中,我寫道我通常不建議堆疊條形的序列,因為內部條形的位置沿著序列移動。但是,如果每個堆疊中只有兩個條形,則內部條形移動的問題就會消失,在這些情況下,所得到的可視化可以非常清晰。例如,考慮一個國家議會中婦女的比例。我們將特別關注非洲國家盧旺達,截至 2016 年,盧旺達是女議員比例最高的國家之一。自 2008 年以來,盧旺達女議員占多數,自 2013 年以來,議會中近三分之二的議員是女性議員。為了想象盧旺達議會中婦女的比例隨時間如何變化,我們可以繪制一系列堆疊的條形圖(圖 10.7)。該圖為隨時間變化的比例提供了直觀視覺表示。為了幫助讀者確切地看到大多數人變成女性的時間,我添加了 50% 的虛線水平線。沒有這條線,幾乎不可能確定從 2003 年到 2007 年,大部分是男性還是女性。我沒有在 25% 和 75% 添加類似的線條,以避免使圖形太雜亂。
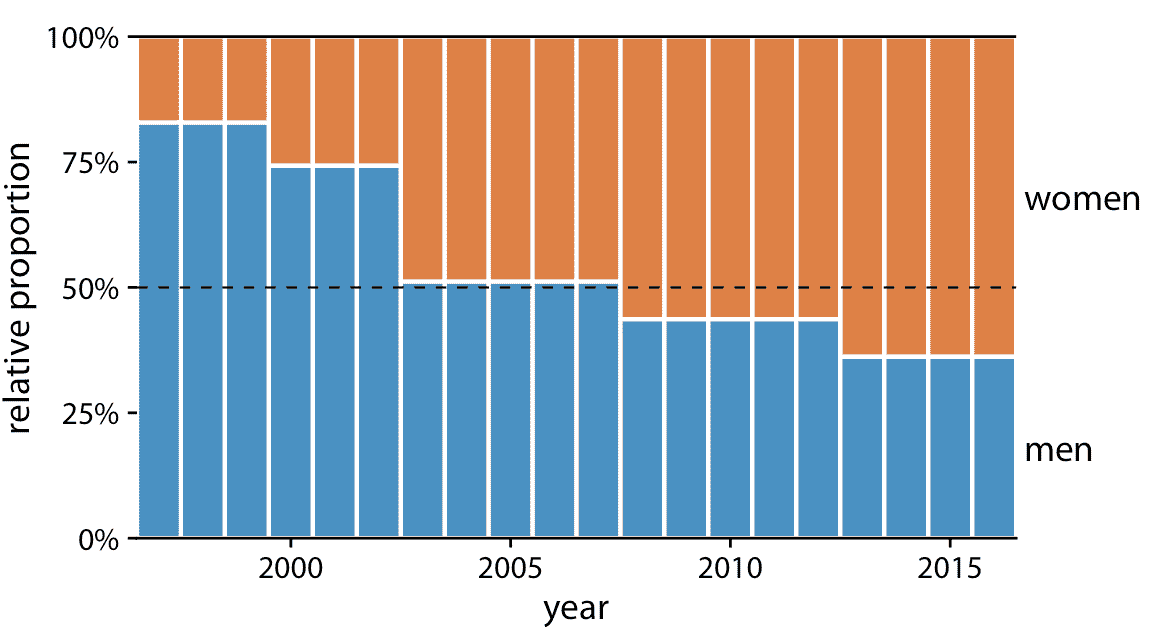
圖 10.7:1997 年至 2016 年盧旺達議會性別構成的變化。數據來源:各國議會聯盟(IPU),ipu.org。
如果我們希望想象比例如何變化來回應連續變量,我們可以從堆疊條形切換到堆疊密度。堆疊密度可以被認為是并排排列的無限多個無限小的堆疊條形的極限情況。堆疊密度圖中的密度通常從核密度估計中獲得,如第七章所述,我將向您推薦這一章,其中對該方法的優缺點進行了一般性討論。
舉一個堆疊密度可能合適的例子,考慮人的健康狀況隨年齡的變化。年齡可以被認為是一個連續變量,以這種方式可視化數據工作得相當好(圖 10.8)。雖然我們這里有四個健康類別,而且我通常不喜歡堆疊多個條件,如上所述,我認為在這種情況下這個圖形是可以接受的。我們可以清楚地看到,隨著人們年齡的增長,整體健康狀況會下降,我們也可以看到,盡管有這種趨勢,但超過一半的人口在年老之前仍保持良好或很棒的健康狀態。
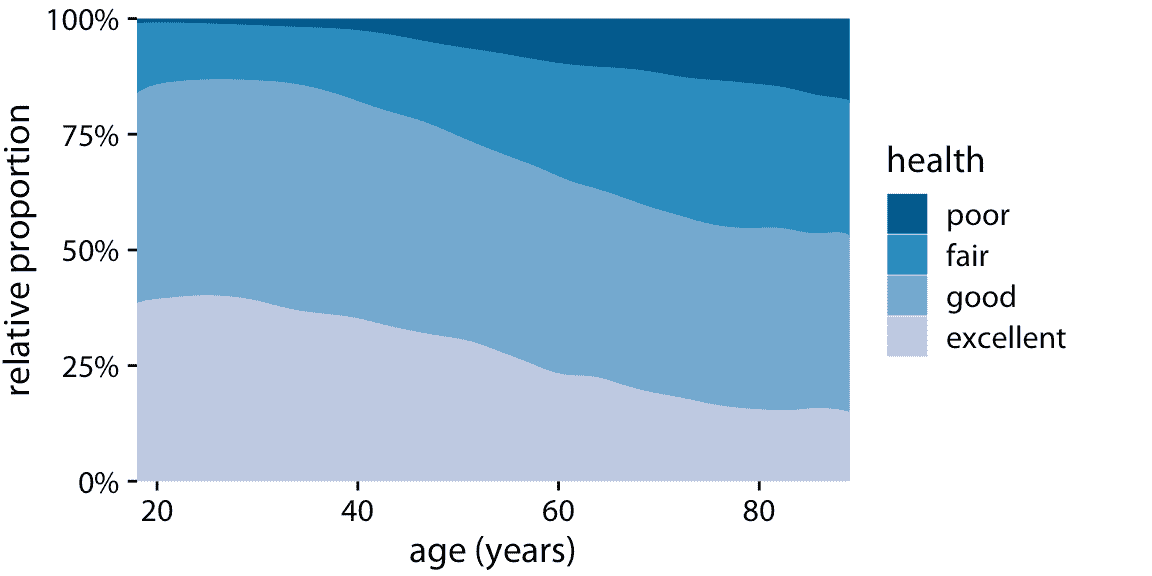
圖 10.8:一般社會調查(GSS)報告的不同年齡的健康狀況。
然而,這個圖形有一個主要的局限性:通過將四種健康狀況的比例可視化為總數的百分比,該圖形模糊了數據集中的年輕人比老年人多得多。因此,盡管報告健康的人的百分比在七十年的年齡段內大致保持不變,但健康狀況良好的人的絕對數量,隨著特定年齡的人口總數下降而下降。我將在下一節介紹這個問題的潛在解決方案。
## 10.4 將比例分別展示為總數的一部分
并排條形具有這樣的問題:它們不能清楚地展示各個部分相對于整體的大小,并且堆疊條形具有不能容易地比較不同的條形的問題,因為它們具有不同的基線。我們可以通過為每個部分制作單獨的圖,并且在每個圖中展示相對于整體的相應部分,來解決這兩個問題。對于圖 10.8 的健康數據集,該過程得到圖 10.9。數據集中的總體年齡分布顯示為灰色陰影區域,每個健康狀態的年齡分布顯示為藍色。這個圖形突出顯示,從絕對意義上講,健康狀況優秀或健康狀況良好的人數在 30-40 歲之間下降,而健康一般的人數在各個年齡段都保持不變。
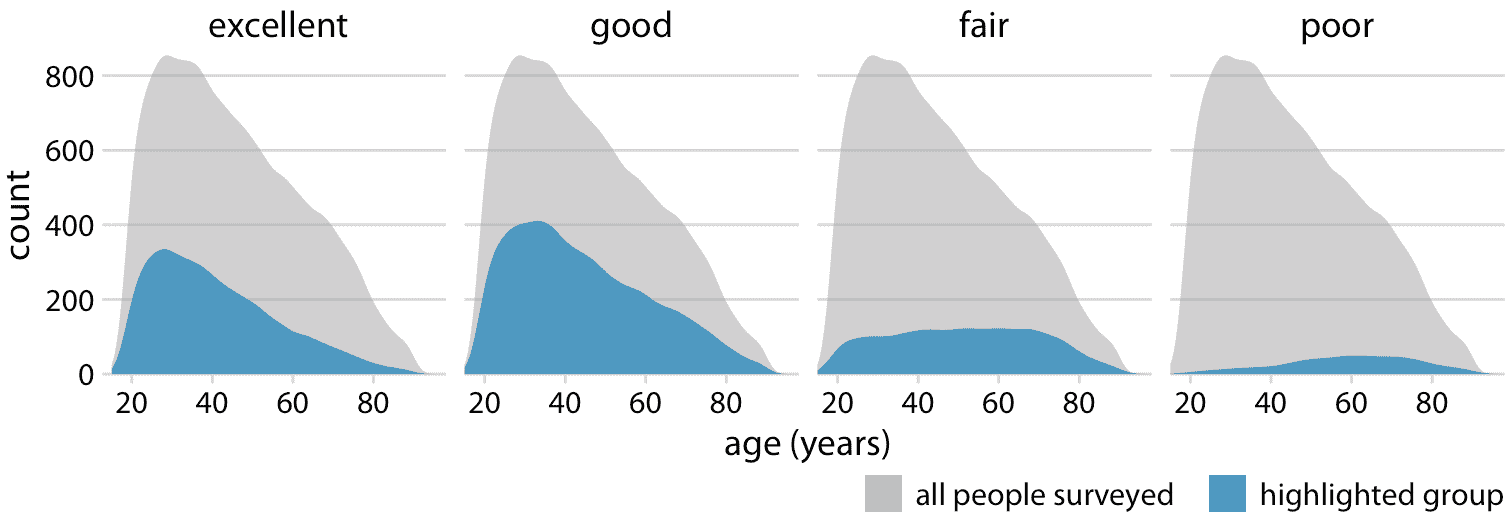
圖 10.9:不同年齡的健康狀況,顯示為調查中總人數的比例。彩色區域顯示具有相應健康狀況的人的年齡的密度估計,并且灰色區域顯示總體年齡分布。
為了提供第二個例子,讓我們考慮來自同一調查的不同變量:婚姻狀況。隨著年齡的增長,婚姻狀況的變化遠遠大于健康狀況,婚姻狀況與年齡的疊加密度圖并不十分可讀(圖 10.10)。
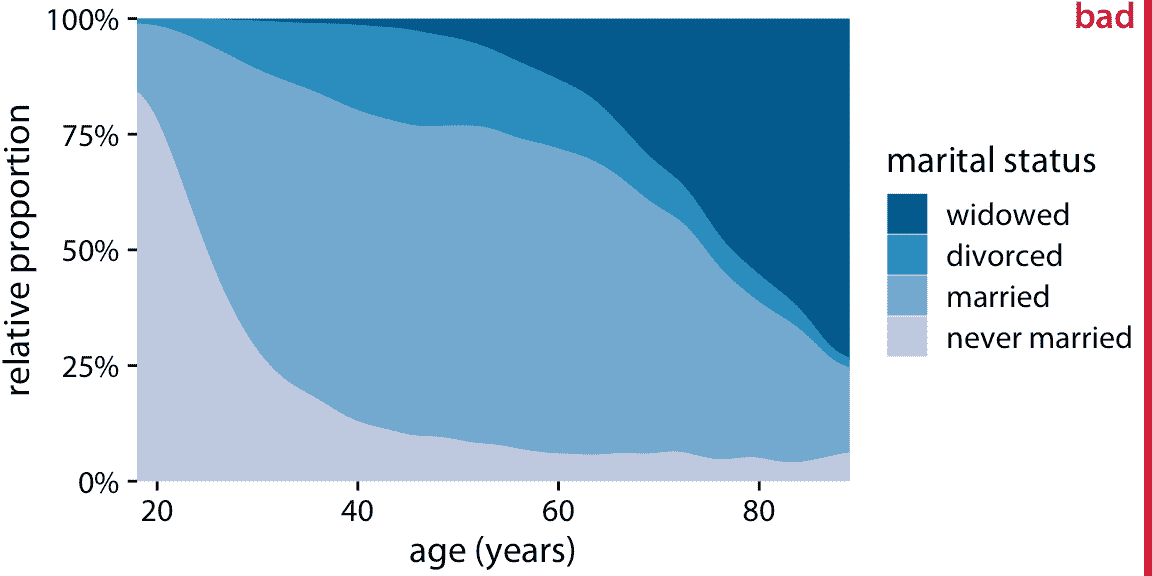
圖 10.10:一般社會調查(GSS)所報告的不同年齡的婚姻狀況。為了簡化圖形,我刪除了少數報告為分開的案例。我把這個圖形稱為“不亮”,因為從未結婚或喪偶的人的頻率隨著年齡的增長而變化非常大,以至于已婚和離婚的人的年齡分布高度扭曲且難以解釋。
可視化為部分密度的相同數據集更清晰(圖 10.11 )。特別是,我們看到已婚人口的比例在 30-40 歲末期達到峰值,離婚人口的比例在 40-50 歲初期達到峰值,而喪偶人口的比例在 70-80 歲中期達到峰值。

圖 10.11:不同年齡的婚姻狀況,顯示為調查中總人數的比例。彩色區域顯示具有相應婚姻狀況的人的年齡的密度估計,并且灰色區域顯示總體年齡分布。
然而,圖 10.11 的一個缺點是,這種表示不容易確定任何給定時間點的相對比例。例如,如果我們想知道在什么年齡超過 50% 的受訪者都已婚,我們不能輕易地從圖 10.11 中看出。為了回答這個問題,我們可以使用相同類型的顯示,但顯示相對比例而不是沿 *y* 軸的絕對計數(圖 10.12)。現在我們看到已婚人口在 20 多歲時開始占多數,而喪偶人口在 70-80 歲中期開始占多數。
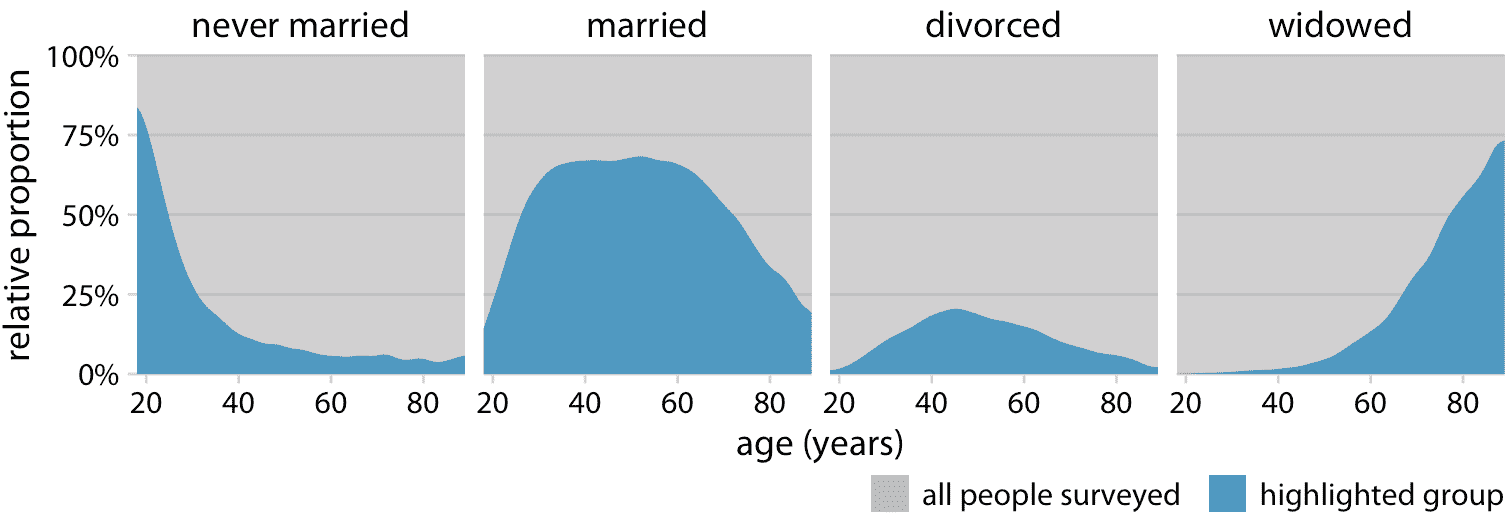
圖 10.12:不同年齡的婚姻狀況,顯示為調查中總人數的比例。藍色區域顯示給定年齡的具有相應的狀況的人口百分比,灰色區域顯示具有所有其他婚姻狀況的人口百分比。
### 參考
```
Wikipedia, User:Schutz. 2007. “File:Piecharts.svg.” https://en.wikipedia.org/wiki/File:Piecharts.svg.
```
- 數據可視化的基礎知識
- 歡迎
- 前言
- 1 簡介
- 2 可視化數據:將數據映射到美學上
- 3 坐標系和軸
- 4 顏色刻度
- 5 可視化的目錄
- 6 可視化數量
- 7 可視化分布:直方圖和密度圖
- 8 可視化分布:經驗累積分布函數和 q-q 圖
- 9 一次可視化多個分布
- 10 可視化比例
- 11 可視化嵌套比例
- 12 可視化兩個或多個定量變量之間的關聯
- 13 可視化自變量的時間序列和其他函數
- 14 可視化趨勢
- 15 可視化地理空間數據
- 16 可視化不確定性
- 17 比例墨水原理
- 18 處理重疊點
- 19 顏色使用的常見缺陷
- 20 冗余編碼
- 21 多面板圖形
- 22 標題,說明和表格
- 23 平衡數據和上下文
- 24 使用較大的軸標簽
- 25 避免線條圖
- 26 不要走向 3D
- 27 了解最常用的圖像文件格式
- 28 選擇合適的可視化軟件
- 29 講述一個故事并提出一個觀點
- 30 帶注解的參考書目
- 技術注解
- 參考