
自動拆分有以下策略。
**1. ConstantSizeRegionSplitPolicy**(了解即可)
在 0.94 版本的時候 HBase 只有一種拆分策略。這個策略非常簡單,從名字上就可以看出這個策略就是按照固定大小來拆分 Region。控制它的參數是:
| hbase.hregion.max.filesize | Region 的最大大小。默認是 10GB|
| --- | --- |
當單個 Region 大小超過了 10GB,就會被 HBase 拆分成為 2 個 Region。采用這種策略后的集群中的 Region大小很平均,理想情況下都是5GB。由于這種策略太簡單了,所以不再詳細解釋了。<br/>
**2. IncreasingToUpperBoundRegionSplitPolicy**(0.94 版本后默認,需要掌握理解)。
0.94 版本之后,有了 IncreasingToUpperBoundRegionSplitPolicy 策略。這種策略從名字上就可以看出是限制不斷增長的文件尺寸的策略。依賴以下公式來計算文件尺寸的上限增長:
```[math]
Math.min(tableRegionsCounts^3 * initialSize,defaultRegionMaxFileSize)
```
`tableRegionCount`:表在所有 RegionServer 上所擁有的 Region 數量總和。
`initialSize`:如果定義了 hbase.increasing.policy.initial.size,則使用這個數值;如果沒有定義,就用 memstore 的刷寫大小的2倍 ,hbase.hregion.memstore.flush.size * 2。
`defaultRegionMaxFileSize` : ConstantSizeRegionSplitPolicy 所用到的hbase.hregion.max.filesize,即 Region 最大大小。
<br/>
假如 hbase.hregion.memstore.flush.size 定義為 128MB,那么文件尺寸的上限增長將是這樣:
( 1 ) 剛 開 始 只 有 一 個 region 的 時 候 , 上 限 是 256MB ,因為 `$ 1^3 *128*2=256MB $`。
(2)當有 2 個 region 的時候,上限是 2GB,因為 `$ 2^3 * 128*2=2048MB $`。
(3)當有 3 個文件的時候,上限是 6.75GB,因為 `$ 3^3 * 128 * 2=6912MB $`。
(4)以此類推,直到計算出來的上限達到 hbase.hregion.max.filesize 所定義region 的 默認的10GB。
走勢圖如下圖:
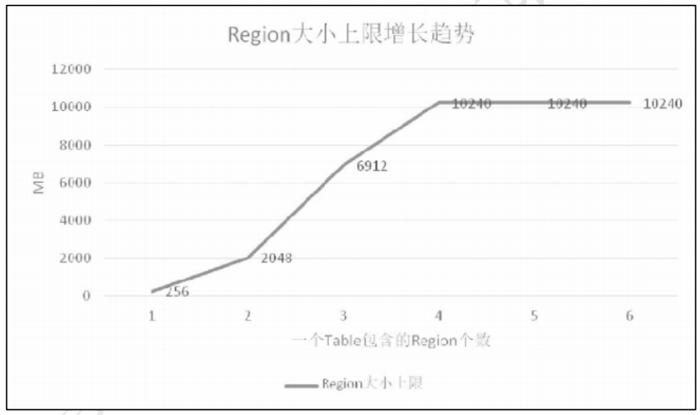
當 Region 個數達到 4 個的時候由于計算出來的上限已經達到了 16GB,已經大于 10GB 了,所以后面當 Region 數量再增加的時候文件大小上限已經不會增加了。在最新的版本里 IncreasingToUpperBoundRegionSplitPolicy 是默認的配置。
<br/>
**3. KeyPrefixRegionSplitPolicy**(擴展內容)
除了簡單粗暴地根據大小來拆分,我們還可以自己定義拆分點。KeyPrefixRegionSplitPolicy 是 IncreasingToUpperBoundRegionSplitPolicy 的子類,在前者的基礎上,增加了對拆分點(splitPoint,拆分點就是 Region 被拆分處的rowkey)的定義。它保證了有相同前綴的 rowkey 不會被拆分到兩個不同的 Region 里面。這個策略用到的參數如下:
| `KeyPrefixRegionSplitPolicy.prefix_length` | rowkey 的前綴長度 |
| --- | --- |
該策略會根據 KeyPrefixRegionSplitPolicy.prefix_length 所定義的長度來截取rowkey 作為分組的依據,同一個組的數據不會被劃分到不同的 Region 上。比如rowKey 都是 16 位的,指定前 5 位是前綴,那么前 5 位相同的 rowKey 在進行 region split 的時候會分到相同的 region 中。用默認策略拆分跟用KeyPrefixRegionSplitPolicy 拆分的區別如下:
:-: 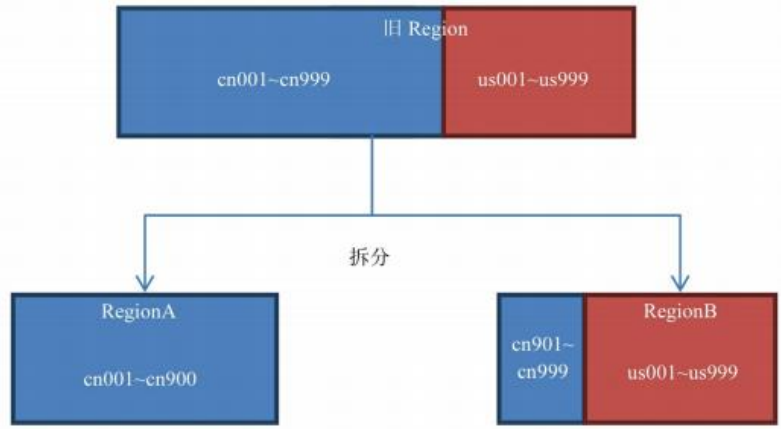
默認策略拆分結果圖
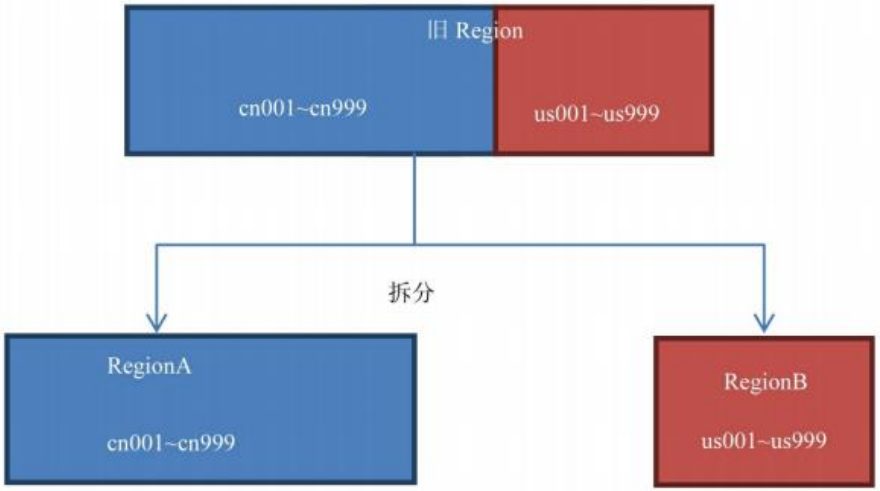
KeyPrefixRegionSplitPolicy(前 2 位)拆分結果圖
<br/>
如果你的所有數據都只有一兩個前綴,那么 KeyPrefixRegionSplitPolicy 就無效了,此時采用默認的策略較好。如果你的前綴劃分的比較細,你的查詢就比較容易發生跨 Region 查詢的情況,此時采用 KeyPrefixRegionSplitPolicy 較好。<br/>
所以這個策略適用的場景是:數據有多種前綴。查詢多是針對前綴,比較少跨越多個前綴來查詢數據。
<br/>
**4. DelimitedKeyPrefixRegionSplitPolicy**(擴展內容)
該策略也是繼承自 IncreasingToUpperBoundRegionSplitPolicy,它也是根據你的 rowkey 前綴來進行切分的。唯一的不同就是:KeyPrefixRegionSplitPolicy 是根據 rowkey 的固定前幾位字符來進行判斷,而DelimitedKeyPrefixRegionSplitPolicy是根據分隔符來判斷的。有時候 rowkey 的前綴可能不一定都是定長的,比如你拿服務器的名字來當前綴,有的服務器叫 host12 有的叫 host1。這些場景下嚴格地要求所有前綴都定長可能比較難,而且這個定長如果未來想改也不容易。
DelimitedKeyPrefixRegionSplitPolicy 就給了你一個定義長度字符前綴的自由。使用這個策略需要在表定義中加入以下屬性:
```
DelimitedKeyPrefixRegionSplitPolicy.delimiter:前綴分隔符
```
比如你定義了前綴分隔符為`_`,那么 host1_001 和 host12_999 的前綴就分別是 host1 和 host12。
<br/>
**5. BusyRegionSplitPolicy**(擴展內容)
此前的拆分策略都沒有考慮熱點問題。所謂熱點問題就是數據庫中的Region 被訪問的頻率并不一樣,某些 Region 在短時間內被訪問的很頻繁,承載了很大的壓力,這些 Region 就是熱點 Region。BusyRegionSplitPolicy 就是為了解決這種場景而產生的。它是如何判斷哪個 Region 是熱點的呢,首先先要介紹它用到的參數:
**`hbase.busy.policy.blockedRequests`**:請求阻塞率,即請求被阻塞的嚴重程度。取值范圍是 0.0~1.0,默認是 0.2,即 20%的請求被阻塞的意思。
**`hbase.busy.policy.minAge`**:拆分最小年齡,當 Region 的年齡比這個小的時候不拆分,這是為了防止在判斷是否要拆分的時候出現了短時間的訪問頻率波峰,結果沒必要拆分的 Region 被拆分了,因為短時間的波峰會很快地降回到正常水平。單位毫秒,默認值是 600000,即 10 分鐘。
**`hbase.busy.policy.aggWindow`**:計算是否繁忙的時間窗口,單位毫秒,默認值是 300000,即 5 分鐘。用以控制計算的頻率。計算該 Region 是否繁忙的計算
方法如下:
```
如果"當前時間–上次檢測時間>=hbase.busy.policy.aggWindow",則進行如下計算:
這段時間被阻塞的請求/這段時間的總請求=請求的被阻塞率(aggBlockedRate)
如果"aggBlockedRate > hbase.busy.policy.blockedRequests",則判斷該 Region為繁忙。
```
如果你的系統常常會出現熱點 Region,而你對性能有很高的追求,那么這種策略可能會比較適合你。它會通過拆分熱點 Region 來緩解熱點 Region 的壓力,但是根據熱點來拆分 Region 也會帶來很多不確定性因素,因為你也不知道下一個被拆分的 Region 是哪個。
<br/>
**6. DisabledRegionSplitPolicy**
這種策略其實不是一種策略。如果你看這個策略的源碼會發現就一個方法shouldSplit,并且永遠返回 false。所以設置成這種策略就是 Region 永不自動拆分。<br/>
如果使用 DisabledRegionSplitPolicy 讓 Region 永不自動拆分之后,你依然可以通過手動拆分來拆分 Region。<br/>
這個策略有什么用?無論你設置了哪種拆分策略,一開始數據進入 Hbase的時候都只會往一個 Region 塞數據。必須要等到一個 Region 的大小膨脹到某個閥值的時候才會根據拆分策略來進行拆分。但是當大量的數據涌入的時候,可能會出現一邊拆分一邊寫入大量數據的情況,由于拆分要占用大量 IO,有可能對數據庫造成一定的壓力。如果你事先就知道這個 Table 應該按怎樣的策略來拆分Region 的話,你也可以事先定義拆分點(SplitPoint)。所謂拆分點就是拆分處的rowkey,比如你可以按 26 個字母來定義 25 個拆分點,這樣數據一到 HBase 就會被分配到各自所屬的 Region 里面。這時候我們就可以把自動拆分關掉,只用手動拆分。
- Hadoop
- hadoop是什么?
- Hadoop組成
- hadoop官網
- hadoop安裝
- hadoop配置
- 本地運行模式配置
- 偽分布運行模式配置
- 完全分布運行模式配置
- HDFS分布式文件系統
- HDFS架構
- HDFS設計思想
- HDFS組成架構
- HDFS文件塊大小
- HDFS優缺點
- HDFS Shell操作
- HDFS JavaAPI
- 基本使用
- HDFS的I/O 流操作
- 在SpringBoot項目中的API
- HDFS讀寫流程
- HDFS寫流程
- HDFS讀流程
- NN和SNN關系
- NN和SNN工作機制
- Fsimage和 Edits解析
- checkpoint時間設置
- NameNode故障處理
- 集群安全模式
- DataNode工作機制
- 支持的文件格式
- MapReduce分布式計算模型
- MapReduce是什么?
- MapReduce設計思想
- MapReduce優缺點
- MapReduce基本使用
- MapReduce編程規范
- WordCount案例
- MapReduce任務進程
- Hadoop序列化對象
- 為什么要序列化
- 常用數據序列化類型
- 自定義序列化對象
- MapReduce框架原理
- MapReduce工作流程
- MapReduce核心類
- MapTask工作機制
- Shuffle機制
- Partition分區
- Combiner合并
- ReduceTask工作機制
- OutputFormat
- 使用MapReduce實現SQL Join操作
- Reduce join
- Reduce join 代碼實現
- Map join
- Map join 案例實操
- MapReduce 開發總結
- Hadoop 優化
- MapReduce 優化需要考慮的點
- MapReduce 優化方法
- 分布式資源調度框架 Yarn
- Yarn 基本架構
- ResourceManager(RM)
- NodeManager(NM)
- ApplicationMaster
- Container
- 作業提交全過程
- JobHistoryServer 使用
- 資源調度器
- 先進先出調度器(FIFO)
- 容量調度器(Capacity Scheduler)
- 公平調度器(Fair Scheduler)
- Yarn 常用命令
- Zookeeper
- zookeeper是什么?
- zookeeper完全分布式搭建
- Zookeeper特點
- Zookeeper數據結構
- Zookeeper 內部原理
- 選舉機制
- stat 信息中字段解釋
- 選擇機制中的概念
- 選舉消息內容
- 監聽器原理
- Hadoop 高可用集群搭建
- Zookeeper 應用
- Zookeeper Shell操作
- Zookeeper Java應用
- Hive
- Hive是什么?
- Hive的優缺點
- Hive架構
- Hive元數據存儲模式
- 內嵌模式
- 本地模式
- 遠程模式
- Hive環境搭建
- 偽分布式環境搭建
- Hive命令工具
- 命令行模式
- 交互模式
- Hive數據類型
- Hive數據結構
- 參數配置方式
- Hive數據庫
- 數據庫存儲位置
- 數據庫操作
- 表的創建
- 建表基本語法
- 內部表
- 外部表
- 臨時表
- 建表高階語句
- 表的刪除與修改
- 分區表
- 靜態分區
- 動態分區
- 分桶表
- 創建分桶表
- 分桶抽樣
- Hive視圖
- 視圖的創建
- 側視圖Lateral View
- Hive數據導入導出
- 導入數據
- 導出數據
- 查詢表數據量
- Hive事務
- 事務是什么?
- Hive事務的局限性和特點
- Hive事務的開啟和設置
- Hive PLSQL
- Hive高階查詢
- 查詢基本語法
- 基本查詢
- distinct去重
- where語句
- 列正則表達式
- 虛擬列
- CTE查詢
- 嵌套查詢
- join語句
- 內連接
- 左連接
- 右連接
- 全連接
- 多表連接
- 笛卡爾積
- left semi join
- group by分組
- having刷選
- union與union all
- 排序
- order by
- sort by
- distribute by
- cluster by
- 聚合運算
- 基本聚合
- 高級聚合
- 窗口函數
- 序列窗口函數
- 聚合窗口函數
- 分析窗口函數
- 窗口函數練習
- 窗口子句
- Hive函數
- Hive函數分類
- 字符串函數
- 類型轉換函數
- 數學函數
- 日期函數
- 集合函數
- 條件函數
- 聚合函數
- 表生成函數
- 自定義Hive函數
- 自定義函數分類
- 自定義Hive函數流程
- 添加JAR包的方式
- 自定義臨時函數
- 自定義永久函數
- Hive優化
- Hive性能調優工具
- EXPLAIN
- ANALYZE
- Fetch抓取
- 本地模式
- 表的優化
- 小表 join 大表
- 大表 join 大表
- 開啟Map Join
- group by
- count(distinct)
- 笛卡爾積
- 行列過濾
- 動態分區調整
- 分區分桶表
- 數據傾斜
- 數據傾斜原因
- 調整Map數
- 調整Reduce數
- 產生數據傾斜的場景
- 并行執行
- 嚴格模式
- JVM重用
- 推測執行
- 啟用CBO
- 啟動矢量化
- 使用Tez引擎
- 壓縮算法和文件格式
- 文件格式
- 壓縮算法
- Zeppelin
- Zeppelin是什么?
- Zeppelin安裝
- 配置Hive解釋器
- Hbase
- Hbase是什么?
- Hbase環境搭建
- Hbase分布式環境搭建
- Hbase偽分布式環境搭建
- Hbase架構
- Hbase架構組件
- Hbase數據存儲結構
- Hbase原理
- Hbase Shell
- 基本操作
- 表操作
- namespace
- Hbase Java Api
- Phoenix集成Hbase
- Phoenix是什么?
- 安裝Phoenix
- Phoenix數據類型
- Phoenix Shell
- HBase與Hive集成
- HBase與Hive的對比
- HBase與Hive集成使用
- Hbase與Hive集成原理
- HBase優化
- RowKey設計
- 內存優化
- 基礎優化
- Hbase管理
- 權限管理
- Region管理
- Region的自動拆分
- Region的預拆分
- 到底采用哪種拆分策略?
- Region的合并
- HFile的合并
- 為什么要有HFile的合并
- HFile合并方式
- Compaction執行時間
- Compaction相關控制參數
- 演示示例
- Sqoop
- Sqoop是什么?
- Sqoop環境搭建
- RDBMS導入到HDFS
- RDBMS導入到Hive
- RDBMS導入到Hbase
- HDFS導出到RDBMS
- 使用sqoop腳本
- Sqoop常用命令
- Hadoop數據模型
- TextFile
- SequenceFile
- Avro
- Parquet
- RC&ORC
- 文件存儲格式比較
- Spark
- Spark是什么?
- Spark優勢
- Spark與MapReduce比較
- Spark技術棧
- Spark安裝
- Spark Shell
- Spark架構
- Spark編程入口
- 編程入口API
- SparkContext
- SparkSession
- Spark的maven依賴
- Spark RDD編程
- Spark核心數據結構-RDD
- RDD 概念
- RDD 特性
- RDD編程
- RDD編程流程
- pom依賴
- 創建算子
- 轉換算子
- 動作算子
- 持久化算子
- RDD 與閉包
- csv/json數據源
- Spark分布式計算原理
- RDD依賴
- RDD轉換
- RDD依賴
- DAG工作原理
- Spark Shuffle原理
- Shuffle的作用
- ShuffleManager組件
- Shuffle實踐
- RDD持久化
- 緩存機制
- 檢查點
- 檢查點與緩存的區別
- RDD共享變量
- 廣播變量
- 累計器
- RDD分區設計
- 數據傾斜
- 數據傾斜的根本原因
- 定位導致的數據傾斜
- 常見數據傾斜解決方案
- Spark SQL
- SQL on Hadoop
- Spark SQL是什么
- Spark SQL特點
- Spark SQL架構
- Spark SQL運行原理
- Spark SQL編程
- Spark SQL編程入口
- 創建Dataset
- Dataset是什么
- SparkSession創建Dataset
- 樣例類創建Dataset
- 創建DataFrame
- DataFrame是什么
- 結構化數據文件創建DataFrame
- RDD創建DataFrame
- Hive表創建DataFrame
- JDBC創建DataFrame
- SparkSession創建
- RDD、DataFrame、Dataset
- 三者對比
- 三者相互轉換
- RDD轉換為DataFrame
- DataFrame轉換為RDD
- DataFrame API
- DataFrame API分類
- Action 操作
- 基礎 Dataset 函數
- 強類型轉換
- 弱類型轉換
- Spark SQL外部數據源
- Parquet文件
- Hive表
- RDBMS表
- JSON/CSV
- Spark SQL函數
- Spark SQL內置函數
- 自定SparkSQL函數
- Spark SQL CLI
- Spark SQL性能優化
- Spark GraphX圖形數據分析
- 為什么需要圖計算
- 圖的概念
- 圖的術語
- 圖的經典表示法
- Spark Graphix簡介
- Graphx核心抽象
- Graphx Scala API
- 核心組件
- 屬性圖應用示例1
- 屬性圖應用示例2
- 查看圖信息
- 圖的算子
- 連通分量
- PageRank算法
- Pregel分布式計算框架
- Flume日志收集
- Flume是什么?
- Flume官方文檔
- Flume架構
- Flume安裝
- Flume使用過程
- Flume組件
- Flume工作流程
- Flume事務
- Source、Channel、Sink文檔
- Source文檔
- Channel文檔
- Sink文檔
- Flume攔截器
- Flume攔截器概念
- 配置攔截器
- 自定義攔截器
- Flume可靠性保證
- 故障轉移
- 負載均衡
- 多層代理
- 多路復用
- Kafka
- 消息中間件MQ
- Kafka是什么?
- Kafka安裝
- Kafka本地單機部署
- Kafka基本命令使用
- Topic的生產與消費
- 基本命令
- 查看kafka目錄
- Kafka架構
- Kafka Topic
- Kafka Producer
- Kafka Consumer
- Kafka Partition
- Kafka Message
- Kafka Broker
- 存儲策略
- ZooKeeper在Kafka中的作用
- 副本同步
- 容災
- 高吞吐
- Leader均衡機制
- Kafka Scala API
- Producer API
- Consumer API
- Kafka優化
- 消費者參數優化
- 生產者參數優化
- Spark Streaming
- 什么是流?
- 批處理和流處理
- Spark Streaming簡介
- 流數據處理架構
- 內部工作流程
- StreamingContext組件
- SparkStreaming的編程入口
- WordCount案例
- DStream
- DStream是什么?
- Input DStream與Receivers接收器
- DStream API
- 轉換操作
- 輸出操作
- 數據源
- 數據源分類
- Socket數據源
- 統計HDFS文件的詞頻
- 處理狀態數據
- SparkStreaming整合SparkSQL
- SparkStreaming整合Flume
- SparkStreaming整合Kafka
- 自定義數據源
- Spark Streaming優化策略
- 優化運行時間
- 優化內存使用
- 數據倉庫
- 數據倉庫是什么?
- 數據倉庫的意義
- 數據倉庫和數據庫的區別
- OLTP和OLAP的區別
- OLTP的特點
- OLAP的特點
- OLTP與OLAP對比
- 數據倉庫架構
- Inmon架構
- Kimball架構
- 混合型架構
- 數據倉庫的解決方案
- 數據ETL
- 數據倉庫建模流程
- 維度模型
- 星型模式
- 雪花模型
- 星座模型
- 數據ETL處理
- 數倉分層術語
- 數據抽取方式
- CDC抽取方案
- 數據轉換
- 常見的ETL工具