
**1. 對數據進行 ETL 預處理**
使用場景:
(1)hive 中文件大小不均勻,有的大有的小。spark在讀取大文件時會對大文件按照block快進行切分,小文件不會切分。如果不進行預處理,那么小文件處理速度快,大文件處理慢、資源沒有得到充分利用,可以先對hive數據進行清洗、去重、重新分區等操作來將原本不均勻的數據重新均勻的存放在多個文件中。以簡化后面依賴此數據源的任務。
(2)hive 中 key分布不均勻,可以將shuffle類操作先進行處理。處理完畢之后,spark應用不必進行重復的shuffle,直接用處理后的結果就可以。在頻繁調用 spark 作業并且有實效要求的場景中,如果今天作業要用到昨天數據的聚合數據,可以每天進行一次預處理,將數據聚合好,從而保證今天作業的實效要求。
<br/>
**2. 過濾少數導致傾斜的 key**
使用場景:
(1)傾斜 key 沒有意義時,比如存在很多 key是`-`(`-`在我們系統代表空)的記錄,那么就可以直接filter掉來解決`-`帶來的數據傾斜。
(2)傾斜 key 是有意義的,那么就需要單獨拎出來進行單獨處理。
<br/>
**3. 提高 shuffle 操作的并行度**
使用場景:同一個 task 被分配了多個傾斜的 key。試圖增加 shuffle read task的數量,可以讓原本分配給一個 task 的多個 key 分配給多個 task,從而讓每個 task處理比原來更少的數據。實現起來比較簡單,可以有效緩解和減輕數據傾斜的影響,原理如下圖
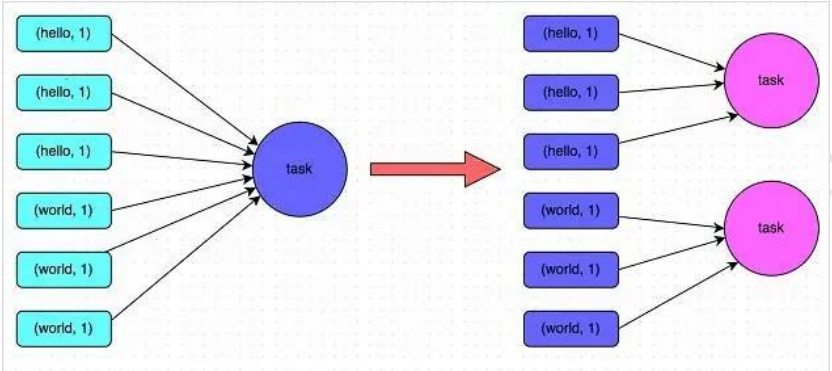
具體操作是將shuffle算子,比如groupByKey、countByKey、reduceByKey。在調用的時候傳入進去一個參數,一個數字。那個數字就代表了那個 shuffle 操作的 reduce 端的并行度。那么在進行 shuffle 操作的時候,就會對應著創建指定數量的 reduce task。
<br/>
**4. 兩階段聚合(局部聚合+全局聚合)**
使用場景:對 RDD 執行 reduceByKey 等聚合類 shuffle 算子或者在 Spark SQL中使用group by語句進行分組聚合時,比較適用這種方案。如果是join類的shuffle操作,還得用其他的解決方案。
<br/>
實現方式:將原本相同的key通過附加隨機前綴的方式,變成多個不同的key,就可以讓原本被一個 task 處理的數據分散到多個 task 上去做局部聚合,進而解決單個 task 處理數據量過多的問題。接著去除掉隨機前綴,再次進行全局聚合,就可以得到最終的結果。如下圖所示。
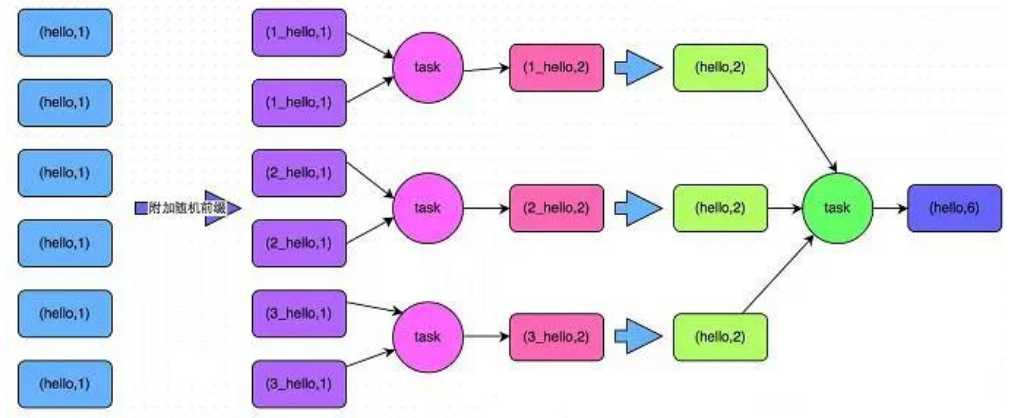
<br/>
**5. 將 reduce join 轉為 map join**
使用場景:join 類操作,存在小表 join 大表的場景。可以將小表進行廣播從而避免shuffle。
<br/>
**6. 采樣傾斜 key 并分拆 join 操作**
使用場景:適用于 join 類操作中,由于相同 key 過大占內存,不能使用第 5個方案,但傾斜 key 的種數不是很多的場景。<br/>
實現方式:
第(1)步:對包含少數幾個數據量過大的key的那個RDD,通過sample算子采樣出一份樣本來,然后統計一下每個key的數量,計算出來數據量最大的是哪幾個 key。
第(2)步:將這幾個key對應的數據從原來的RDD中拆分出來,形成一個單獨的RDD,并給每個key都打上n以內的隨機數作為前綴,而不會導致傾斜的大部分 key 形成另外一個 RDD。
第(3)步:接著將需要 join 的另一個 RDD,也過濾出來那幾個傾斜 key 對應的數據并形成一個單獨的 RDD,將每條數據膨脹成 n條數據,這 n 條數據都按順序附加一個 0~n 的前綴,不會導致傾斜的大部分 key 也形成另外一個 RDD。
第(4)步:再將附加了隨機前綴的獨立 RDD 與另一個膨脹 n 倍的獨立 RDD 進行 join,此時就可以將原先相同的 key打散成n份,分散到多個 task 中去進行 join了。
第(5)步:而另外兩個普通的 RDD 就照常 join 即可。最后將兩次 join 的結果使用 union 算子合并起來即可,就是最終的 join 結果。
<br/>
具體原理見下圖:
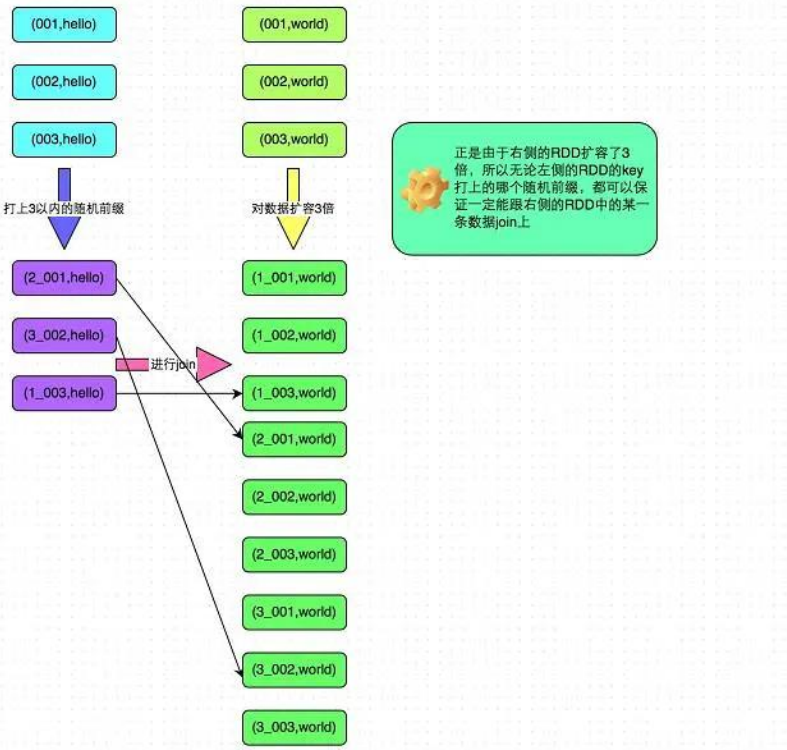
<br/>
**7. 使用隨機前綴和擴容 RDD 進行 join**
使用場景:如果在進行 join 操作時,RDD 中有大量的 key 導致數據傾斜。同第 6 個方案,不同的是它不需要對原先 rdd 進行傾斜 key 過濾,將原來 rdd形成含傾斜 key的rdd,與不含傾斜key的rdd。直接對整個原本的rdd的key一邊進行加隨機數,另一邊進行相應倍數的擴容。而這一種方案是針對有大量傾斜 key的情況,沒法將部分key拆分出來進行單獨處理,因此只能對整個RDD進行數據擴容,對內存資源要求很高。
- Hadoop
- hadoop是什么?
- Hadoop組成
- hadoop官網
- hadoop安裝
- hadoop配置
- 本地運行模式配置
- 偽分布運行模式配置
- 完全分布運行模式配置
- HDFS分布式文件系統
- HDFS架構
- HDFS設計思想
- HDFS組成架構
- HDFS文件塊大小
- HDFS優缺點
- HDFS Shell操作
- HDFS JavaAPI
- 基本使用
- HDFS的I/O 流操作
- 在SpringBoot項目中的API
- HDFS讀寫流程
- HDFS寫流程
- HDFS讀流程
- NN和SNN關系
- NN和SNN工作機制
- Fsimage和 Edits解析
- checkpoint時間設置
- NameNode故障處理
- 集群安全模式
- DataNode工作機制
- 支持的文件格式
- MapReduce分布式計算模型
- MapReduce是什么?
- MapReduce設計思想
- MapReduce優缺點
- MapReduce基本使用
- MapReduce編程規范
- WordCount案例
- MapReduce任務進程
- Hadoop序列化對象
- 為什么要序列化
- 常用數據序列化類型
- 自定義序列化對象
- MapReduce框架原理
- MapReduce工作流程
- MapReduce核心類
- MapTask工作機制
- Shuffle機制
- Partition分區
- Combiner合并
- ReduceTask工作機制
- OutputFormat
- 使用MapReduce實現SQL Join操作
- Reduce join
- Reduce join 代碼實現
- Map join
- Map join 案例實操
- MapReduce 開發總結
- Hadoop 優化
- MapReduce 優化需要考慮的點
- MapReduce 優化方法
- 分布式資源調度框架 Yarn
- Yarn 基本架構
- ResourceManager(RM)
- NodeManager(NM)
- ApplicationMaster
- Container
- 作業提交全過程
- JobHistoryServer 使用
- 資源調度器
- 先進先出調度器(FIFO)
- 容量調度器(Capacity Scheduler)
- 公平調度器(Fair Scheduler)
- Yarn 常用命令
- Zookeeper
- zookeeper是什么?
- zookeeper完全分布式搭建
- Zookeeper特點
- Zookeeper數據結構
- Zookeeper 內部原理
- 選舉機制
- stat 信息中字段解釋
- 選擇機制中的概念
- 選舉消息內容
- 監聽器原理
- Hadoop 高可用集群搭建
- Zookeeper 應用
- Zookeeper Shell操作
- Zookeeper Java應用
- Hive
- Hive是什么?
- Hive的優缺點
- Hive架構
- Hive元數據存儲模式
- 內嵌模式
- 本地模式
- 遠程模式
- Hive環境搭建
- 偽分布式環境搭建
- Hive命令工具
- 命令行模式
- 交互模式
- Hive數據類型
- Hive數據結構
- 參數配置方式
- Hive數據庫
- 數據庫存儲位置
- 數據庫操作
- 表的創建
- 建表基本語法
- 內部表
- 外部表
- 臨時表
- 建表高階語句
- 表的刪除與修改
- 分區表
- 靜態分區
- 動態分區
- 分桶表
- 創建分桶表
- 分桶抽樣
- Hive視圖
- 視圖的創建
- 側視圖Lateral View
- Hive數據導入導出
- 導入數據
- 導出數據
- 查詢表數據量
- Hive事務
- 事務是什么?
- Hive事務的局限性和特點
- Hive事務的開啟和設置
- Hive PLSQL
- Hive高階查詢
- 查詢基本語法
- 基本查詢
- distinct去重
- where語句
- 列正則表達式
- 虛擬列
- CTE查詢
- 嵌套查詢
- join語句
- 內連接
- 左連接
- 右連接
- 全連接
- 多表連接
- 笛卡爾積
- left semi join
- group by分組
- having刷選
- union與union all
- 排序
- order by
- sort by
- distribute by
- cluster by
- 聚合運算
- 基本聚合
- 高級聚合
- 窗口函數
- 序列窗口函數
- 聚合窗口函數
- 分析窗口函數
- 窗口函數練習
- 窗口子句
- Hive函數
- Hive函數分類
- 字符串函數
- 類型轉換函數
- 數學函數
- 日期函數
- 集合函數
- 條件函數
- 聚合函數
- 表生成函數
- 自定義Hive函數
- 自定義函數分類
- 自定義Hive函數流程
- 添加JAR包的方式
- 自定義臨時函數
- 自定義永久函數
- Hive優化
- Hive性能調優工具
- EXPLAIN
- ANALYZE
- Fetch抓取
- 本地模式
- 表的優化
- 小表 join 大表
- 大表 join 大表
- 開啟Map Join
- group by
- count(distinct)
- 笛卡爾積
- 行列過濾
- 動態分區調整
- 分區分桶表
- 數據傾斜
- 數據傾斜原因
- 調整Map數
- 調整Reduce數
- 產生數據傾斜的場景
- 并行執行
- 嚴格模式
- JVM重用
- 推測執行
- 啟用CBO
- 啟動矢量化
- 使用Tez引擎
- 壓縮算法和文件格式
- 文件格式
- 壓縮算法
- Zeppelin
- Zeppelin是什么?
- Zeppelin安裝
- 配置Hive解釋器
- Hbase
- Hbase是什么?
- Hbase環境搭建
- Hbase分布式環境搭建
- Hbase偽分布式環境搭建
- Hbase架構
- Hbase架構組件
- Hbase數據存儲結構
- Hbase原理
- Hbase Shell
- 基本操作
- 表操作
- namespace
- Hbase Java Api
- Phoenix集成Hbase
- Phoenix是什么?
- 安裝Phoenix
- Phoenix數據類型
- Phoenix Shell
- HBase與Hive集成
- HBase與Hive的對比
- HBase與Hive集成使用
- Hbase與Hive集成原理
- HBase優化
- RowKey設計
- 內存優化
- 基礎優化
- Hbase管理
- 權限管理
- Region管理
- Region的自動拆分
- Region的預拆分
- 到底采用哪種拆分策略?
- Region的合并
- HFile的合并
- 為什么要有HFile的合并
- HFile合并方式
- Compaction執行時間
- Compaction相關控制參數
- 演示示例
- Sqoop
- Sqoop是什么?
- Sqoop環境搭建
- RDBMS導入到HDFS
- RDBMS導入到Hive
- RDBMS導入到Hbase
- HDFS導出到RDBMS
- 使用sqoop腳本
- Sqoop常用命令
- Hadoop數據模型
- TextFile
- SequenceFile
- Avro
- Parquet
- RC&ORC
- 文件存儲格式比較
- Spark
- Spark是什么?
- Spark優勢
- Spark與MapReduce比較
- Spark技術棧
- Spark安裝
- Spark Shell
- Spark架構
- Spark編程入口
- 編程入口API
- SparkContext
- SparkSession
- Spark的maven依賴
- Spark RDD編程
- Spark核心數據結構-RDD
- RDD 概念
- RDD 特性
- RDD編程
- RDD編程流程
- pom依賴
- 創建算子
- 轉換算子
- 動作算子
- 持久化算子
- RDD 與閉包
- csv/json數據源
- Spark分布式計算原理
- RDD依賴
- RDD轉換
- RDD依賴
- DAG工作原理
- Spark Shuffle原理
- Shuffle的作用
- ShuffleManager組件
- Shuffle實踐
- RDD持久化
- 緩存機制
- 檢查點
- 檢查點與緩存的區別
- RDD共享變量
- 廣播變量
- 累計器
- RDD分區設計
- 數據傾斜
- 數據傾斜的根本原因
- 定位導致的數據傾斜
- 常見數據傾斜解決方案
- Spark SQL
- SQL on Hadoop
- Spark SQL是什么
- Spark SQL特點
- Spark SQL架構
- Spark SQL運行原理
- Spark SQL編程
- Spark SQL編程入口
- 創建Dataset
- Dataset是什么
- SparkSession創建Dataset
- 樣例類創建Dataset
- 創建DataFrame
- DataFrame是什么
- 結構化數據文件創建DataFrame
- RDD創建DataFrame
- Hive表創建DataFrame
- JDBC創建DataFrame
- SparkSession創建
- RDD、DataFrame、Dataset
- 三者對比
- 三者相互轉換
- RDD轉換為DataFrame
- DataFrame轉換為RDD
- DataFrame API
- DataFrame API分類
- Action 操作
- 基礎 Dataset 函數
- 強類型轉換
- 弱類型轉換
- Spark SQL外部數據源
- Parquet文件
- Hive表
- RDBMS表
- JSON/CSV
- Spark SQL函數
- Spark SQL內置函數
- 自定SparkSQL函數
- Spark SQL CLI
- Spark SQL性能優化
- Spark GraphX圖形數據分析
- 為什么需要圖計算
- 圖的概念
- 圖的術語
- 圖的經典表示法
- Spark Graphix簡介
- Graphx核心抽象
- Graphx Scala API
- 核心組件
- 屬性圖應用示例1
- 屬性圖應用示例2
- 查看圖信息
- 圖的算子
- 連通分量
- PageRank算法
- Pregel分布式計算框架
- Flume日志收集
- Flume是什么?
- Flume官方文檔
- Flume架構
- Flume安裝
- Flume使用過程
- Flume組件
- Flume工作流程
- Flume事務
- Source、Channel、Sink文檔
- Source文檔
- Channel文檔
- Sink文檔
- Flume攔截器
- Flume攔截器概念
- 配置攔截器
- 自定義攔截器
- Flume可靠性保證
- 故障轉移
- 負載均衡
- 多層代理
- 多路復用
- Kafka
- 消息中間件MQ
- Kafka是什么?
- Kafka安裝
- Kafka本地單機部署
- Kafka基本命令使用
- Topic的生產與消費
- 基本命令
- 查看kafka目錄
- Kafka架構
- Kafka Topic
- Kafka Producer
- Kafka Consumer
- Kafka Partition
- Kafka Message
- Kafka Broker
- 存儲策略
- ZooKeeper在Kafka中的作用
- 副本同步
- 容災
- 高吞吐
- Leader均衡機制
- Kafka Scala API
- Producer API
- Consumer API
- Kafka優化
- 消費者參數優化
- 生產者參數優化
- Spark Streaming
- 什么是流?
- 批處理和流處理
- Spark Streaming簡介
- 流數據處理架構
- 內部工作流程
- StreamingContext組件
- SparkStreaming的編程入口
- WordCount案例
- DStream
- DStream是什么?
- Input DStream與Receivers接收器
- DStream API
- 轉換操作
- 輸出操作
- 數據源
- 數據源分類
- Socket數據源
- 統計HDFS文件的詞頻
- 處理狀態數據
- SparkStreaming整合SparkSQL
- SparkStreaming整合Flume
- SparkStreaming整合Kafka
- 自定義數據源
- Spark Streaming優化策略
- 優化運行時間
- 優化內存使用
- 數據倉庫
- 數據倉庫是什么?
- 數據倉庫的意義
- 數據倉庫和數據庫的區別
- OLTP和OLAP的區別
- OLTP的特點
- OLAP的特點
- OLTP與OLAP對比
- 數據倉庫架構
- Inmon架構
- Kimball架構
- 混合型架構
- 數據倉庫的解決方案
- 數據ETL
- 數據倉庫建模流程
- 維度模型
- 星型模式
- 雪花模型
- 星座模型
- 數據ETL處理
- 數倉分層術語
- 數據抽取方式
- CDC抽取方案
- 數據轉換
- 常見的ETL工具