
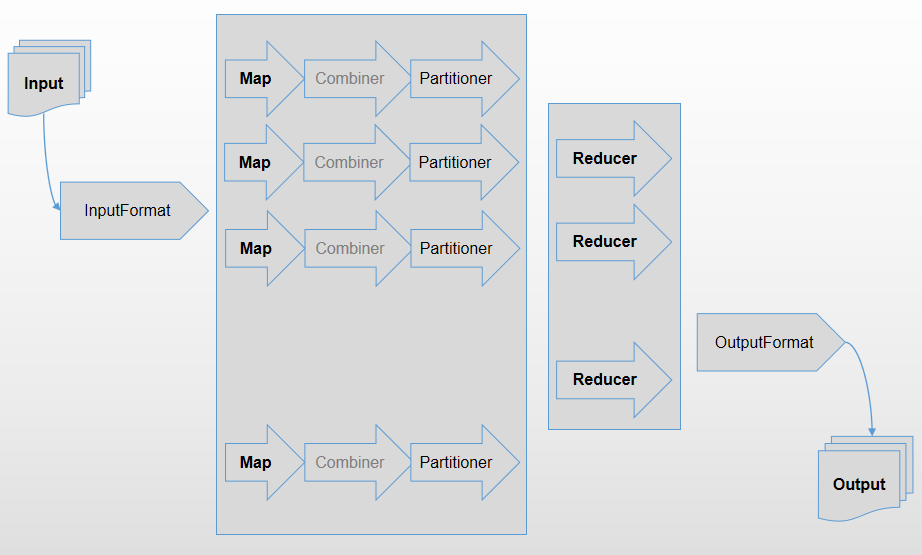
[TOC]
# 1. InputFormat
InputFormat 的主要功能就是確定每一個 map 任務需要讀取哪些數據以及如何讀取數據的問題,<ins>每一個 map 讀取哪些數據由 InputSplit(數據切片)決定,如何讀取數據由 RecordReader 來決定</ins>。InputFormat 中就有獲取 InputSplit 和RecordReader 的方法。

**InputSplit:**
在map之前,根據輸入文件InputSplit會被創建。
* 每個InputSplit對應一個Mapper任務
* 輸入分片存儲的是分片長度和記錄數據位置的數組
**block和split的區別:**
* block是數據的物理表示、split是塊中數據的邏輯表示
* split劃分是在記錄的邊界處
* split的數量應不大于block的數量(一般相等)
<br/>
# 2. InputFormat 接口實現類

InputFormat實現類有很多,但是我們開發比較常用應該是文件類型(FileInputFormat)和數據庫類型(DBInputFormat)。課程中還是以FileInputFormat為主。DBInputFormat 只是知道有這個功能即可。
1. **FileInputFormat 源碼解析**(該部分內容可參照 FileInputFormat 源碼)

(1)找到輸入數據存儲的目錄。
(2)開始遍歷處理(規劃切片)目錄下的每一個文件。
(3)遍歷第一個文件 hello.txt。
a)獲取文件大小 fs.sizeOf(hello.txt)。
b)計算切片大小
<ins>computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M</ins>。
c)<ins>默認情況下,切片大小=blocksize</ins>。
d)開始切,形成第 1 個切片:hello.txt—0:128M ,第 2 個切片 hello.txt—128:256M ,第 3 個切片 hello.txt—256M:300M(<ins>每次切片時,都要判斷切完剩下的部分是否大于塊的 1.1 倍,不大于 1.1 倍就劃分一塊切片</ins>)。
e)將切片信息寫到一個切片規劃文件中。
f)整個切片的核心過程在 FileInputFormat 類中的 getSplit()方法中完成,可以去查看源碼。
g)<ins>數據切片只是在邏輯上對輸入數據進行分片,并不會在磁盤上將其切分成分片進行存儲</ins>。InputSplit 只記錄了分片的元數據信息,比如起始位置、長度以及所在的節點列表等。
h)注意:<ins>block 是 HDFS 物理上存儲的數據,切片是對數據邏輯上的劃分</ins>。
(4)提交切片規劃文件到 Yarn 上,Yarn 上的 MrAppMaster 就可以根據切片規劃文件計算開啟 maptask 個數。
2. **FileInputFormat 切片大小的參數配置**
通過分析源碼 , 在 FileInputFormat 中 , 計算切片大小的邏輯:<ins>Math.max(minSize, Math.min(maxSize, blockSize))</ins>;
切片主要由這幾個值來運算決定:
```
mapreduce.input.fileinputformat.split.minsize=1 默認值為 1
mapreduce.input.fileinputformat.split.maxsize=Long.MAXValue 默認值Long.MAXValue
```
因此,默認情況下,切片大小=blocksize。
```
maxsize(切片最大值):參數如果調得比 blocksize 小,則會讓切片變小,而且就等于配置的這個參數的值。
minsize(切片最小值):參數調的比 blockSize 大,則可以讓切片變得比blocksize 還大。
```
3. **獲取切片信息 API,可以使用 MapTask 上下文對象獲取切片信息**
```java
// 根據文件類型獲取切片信息
FileSplit inputSplit = (FileSplit) context.getInputSplit();
// 獲取切片的文件名稱
String name = inputSplit.getPath().getName();
```
4. **總結**
FileInputFormat 默認切片規則
(1)簡單地按照文件的內容長度進行切片
(2)切片大小,默認等于 block 大小
(3)切片時不考慮數據集整體,而是逐個針對每一個文件單獨切片
<br/>
# 3. FileInputFormat 實現類
FileInputFormat 其實是一個抽象類 , 它有很多實現類 。 默認的是TextInputFormat。
1. **TextInputFormat**
TextInputFormat 是默認的 InputFormat。每條記錄是一行輸入。<ins>鍵是LongWritable 類型,存儲該行在整個文件中的字節偏移量。值是這行的內容,不包括任何行終止符(換行符和回車符)</ins>。
以下是一個示例,比如,一個分片包含了如下 4 條文本記錄。
```txt
Rich learning form
Intelligent learning engine
Learning more convenient
From the real demand for more close to the enterprise
```
每條記錄表示為以下鍵/值對。
```txt
(0,Rich learning form)
(19,Intelligent learning engine)
(47,Learning more convenient)
(72,From the real demand for more close to the enterprise)
```
很明顯,鍵并不是行號。一般情況下,很難取得行號,因為文件按字節而不是按行切分為分片。
2. **KeyValueTextInputFormat**(擴展內容)
每一行均為一條記錄,被分隔符分割為 key,value。可以通過在驅動類中設置 conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, " ");來設定分隔符。
默認分隔符是 tab(\t)。<br/>
以下是一個示例,輸入是一個包含 4 條記錄的分片。其中——>表示一個(水平方向的)制表符。
```
line1 ——>Rich learning form
line2 ——>Intelligent learning engine
line3 ——>Learning more convenient
line4 ——>From the real demand for more close to the enterprise
```
每條記錄表示為以下鍵/值對。
```
(line1,Rich learning form)
(line2,Intelligent learning engine)
(line3,Learning more convenient)
(line4,From the real demand for more close to the enterprise)
```
此時的鍵是每行排在制表符之前的 Text 序列。
3. **NLineInputFormat**(擴展內容)
如果使用NlineInputFormat,代表每個map 進程處理的InputSplit不再按block塊去劃分,而是按 NlineInputFormat 指定的行數 N 來劃分。即`輸入文件的總行數/N=切片數`,如果不整除,`切片數=商+1`。
以下是一個示例,仍然以上面的 4 行輸入為例。
```
Rich learning form
Intelligent learning engine
Learning more convenient
From the real demand for more close to the enterprise
```
例如,如果 N 是 2,則每個輸入分片包含兩行。開啟 2 個 maptask。
```
(0,Rich learning form)
(19,Intelligent learning engine)
```
另一個 mapper 則收到后兩行:
```
(47,Learning more convenient)
(72,From the real demand for more close to the enterprise)
```
這里的鍵和值與 TextInputFormat 生成的一樣。
- Hadoop
- hadoop是什么?
- Hadoop組成
- hadoop官網
- hadoop安裝
- hadoop配置
- 本地運行模式配置
- 偽分布運行模式配置
- 完全分布運行模式配置
- HDFS分布式文件系統
- HDFS架構
- HDFS設計思想
- HDFS組成架構
- HDFS文件塊大小
- HDFS優缺點
- HDFS Shell操作
- HDFS JavaAPI
- 基本使用
- HDFS的I/O 流操作
- 在SpringBoot項目中的API
- HDFS讀寫流程
- HDFS寫流程
- HDFS讀流程
- NN和SNN關系
- NN和SNN工作機制
- Fsimage和 Edits解析
- checkpoint時間設置
- NameNode故障處理
- 集群安全模式
- DataNode工作機制
- 支持的文件格式
- MapReduce分布式計算模型
- MapReduce是什么?
- MapReduce設計思想
- MapReduce優缺點
- MapReduce基本使用
- MapReduce編程規范
- WordCount案例
- MapReduce任務進程
- Hadoop序列化對象
- 為什么要序列化
- 常用數據序列化類型
- 自定義序列化對象
- MapReduce框架原理
- MapReduce工作流程
- MapReduce核心類
- MapTask工作機制
- Shuffle機制
- Partition分區
- Combiner合并
- ReduceTask工作機制
- OutputFormat
- 使用MapReduce實現SQL Join操作
- Reduce join
- Reduce join 代碼實現
- Map join
- Map join 案例實操
- MapReduce 開發總結
- Hadoop 優化
- MapReduce 優化需要考慮的點
- MapReduce 優化方法
- 分布式資源調度框架 Yarn
- Yarn 基本架構
- ResourceManager(RM)
- NodeManager(NM)
- ApplicationMaster
- Container
- 作業提交全過程
- JobHistoryServer 使用
- 資源調度器
- 先進先出調度器(FIFO)
- 容量調度器(Capacity Scheduler)
- 公平調度器(Fair Scheduler)
- Yarn 常用命令
- Zookeeper
- zookeeper是什么?
- zookeeper完全分布式搭建
- Zookeeper特點
- Zookeeper數據結構
- Zookeeper 內部原理
- 選舉機制
- stat 信息中字段解釋
- 選擇機制中的概念
- 選舉消息內容
- 監聽器原理
- Hadoop 高可用集群搭建
- Zookeeper 應用
- Zookeeper Shell操作
- Zookeeper Java應用
- Hive
- Hive是什么?
- Hive的優缺點
- Hive架構
- Hive元數據存儲模式
- 內嵌模式
- 本地模式
- 遠程模式
- Hive環境搭建
- 偽分布式環境搭建
- Hive命令工具
- 命令行模式
- 交互模式
- Hive數據類型
- Hive數據結構
- 參數配置方式
- Hive數據庫
- 數據庫存儲位置
- 數據庫操作
- 表的創建
- 建表基本語法
- 內部表
- 外部表
- 臨時表
- 建表高階語句
- 表的刪除與修改
- 分區表
- 靜態分區
- 動態分區
- 分桶表
- 創建分桶表
- 分桶抽樣
- Hive視圖
- 視圖的創建
- 側視圖Lateral View
- Hive數據導入導出
- 導入數據
- 導出數據
- 查詢表數據量
- Hive事務
- 事務是什么?
- Hive事務的局限性和特點
- Hive事務的開啟和設置
- Hive PLSQL
- Hive高階查詢
- 查詢基本語法
- 基本查詢
- distinct去重
- where語句
- 列正則表達式
- 虛擬列
- CTE查詢
- 嵌套查詢
- join語句
- 內連接
- 左連接
- 右連接
- 全連接
- 多表連接
- 笛卡爾積
- left semi join
- group by分組
- having刷選
- union與union all
- 排序
- order by
- sort by
- distribute by
- cluster by
- 聚合運算
- 基本聚合
- 高級聚合
- 窗口函數
- 序列窗口函數
- 聚合窗口函數
- 分析窗口函數
- 窗口函數練習
- 窗口子句
- Hive函數
- Hive函數分類
- 字符串函數
- 類型轉換函數
- 數學函數
- 日期函數
- 集合函數
- 條件函數
- 聚合函數
- 表生成函數
- 自定義Hive函數
- 自定義函數分類
- 自定義Hive函數流程
- 添加JAR包的方式
- 自定義臨時函數
- 自定義永久函數
- Hive優化
- Hive性能調優工具
- EXPLAIN
- ANALYZE
- Fetch抓取
- 本地模式
- 表的優化
- 小表 join 大表
- 大表 join 大表
- 開啟Map Join
- group by
- count(distinct)
- 笛卡爾積
- 行列過濾
- 動態分區調整
- 分區分桶表
- 數據傾斜
- 數據傾斜原因
- 調整Map數
- 調整Reduce數
- 產生數據傾斜的場景
- 并行執行
- 嚴格模式
- JVM重用
- 推測執行
- 啟用CBO
- 啟動矢量化
- 使用Tez引擎
- 壓縮算法和文件格式
- 文件格式
- 壓縮算法
- Zeppelin
- Zeppelin是什么?
- Zeppelin安裝
- 配置Hive解釋器
- Hbase
- Hbase是什么?
- Hbase環境搭建
- Hbase分布式環境搭建
- Hbase偽分布式環境搭建
- Hbase架構
- Hbase架構組件
- Hbase數據存儲結構
- Hbase原理
- Hbase Shell
- 基本操作
- 表操作
- namespace
- Hbase Java Api
- Phoenix集成Hbase
- Phoenix是什么?
- 安裝Phoenix
- Phoenix數據類型
- Phoenix Shell
- HBase與Hive集成
- HBase與Hive的對比
- HBase與Hive集成使用
- Hbase與Hive集成原理
- HBase優化
- RowKey設計
- 內存優化
- 基礎優化
- Hbase管理
- 權限管理
- Region管理
- Region的自動拆分
- Region的預拆分
- 到底采用哪種拆分策略?
- Region的合并
- HFile的合并
- 為什么要有HFile的合并
- HFile合并方式
- Compaction執行時間
- Compaction相關控制參數
- 演示示例
- Sqoop
- Sqoop是什么?
- Sqoop環境搭建
- RDBMS導入到HDFS
- RDBMS導入到Hive
- RDBMS導入到Hbase
- HDFS導出到RDBMS
- 使用sqoop腳本
- Sqoop常用命令
- Hadoop數據模型
- TextFile
- SequenceFile
- Avro
- Parquet
- RC&ORC
- 文件存儲格式比較
- Spark
- Spark是什么?
- Spark優勢
- Spark與MapReduce比較
- Spark技術棧
- Spark安裝
- Spark Shell
- Spark架構
- Spark編程入口
- 編程入口API
- SparkContext
- SparkSession
- Spark的maven依賴
- Spark RDD編程
- Spark核心數據結構-RDD
- RDD 概念
- RDD 特性
- RDD編程
- RDD編程流程
- pom依賴
- 創建算子
- 轉換算子
- 動作算子
- 持久化算子
- RDD 與閉包
- csv/json數據源
- Spark分布式計算原理
- RDD依賴
- RDD轉換
- RDD依賴
- DAG工作原理
- Spark Shuffle原理
- Shuffle的作用
- ShuffleManager組件
- Shuffle實踐
- RDD持久化
- 緩存機制
- 檢查點
- 檢查點與緩存的區別
- RDD共享變量
- 廣播變量
- 累計器
- RDD分區設計
- 數據傾斜
- 數據傾斜的根本原因
- 定位導致的數據傾斜
- 常見數據傾斜解決方案
- Spark SQL
- SQL on Hadoop
- Spark SQL是什么
- Spark SQL特點
- Spark SQL架構
- Spark SQL運行原理
- Spark SQL編程
- Spark SQL編程入口
- 創建Dataset
- Dataset是什么
- SparkSession創建Dataset
- 樣例類創建Dataset
- 創建DataFrame
- DataFrame是什么
- 結構化數據文件創建DataFrame
- RDD創建DataFrame
- Hive表創建DataFrame
- JDBC創建DataFrame
- SparkSession創建
- RDD、DataFrame、Dataset
- 三者對比
- 三者相互轉換
- RDD轉換為DataFrame
- DataFrame轉換為RDD
- DataFrame API
- DataFrame API分類
- Action 操作
- 基礎 Dataset 函數
- 強類型轉換
- 弱類型轉換
- Spark SQL外部數據源
- Parquet文件
- Hive表
- RDBMS表
- JSON/CSV
- Spark SQL函數
- Spark SQL內置函數
- 自定SparkSQL函數
- Spark SQL CLI
- Spark SQL性能優化
- Spark GraphX圖形數據分析
- 為什么需要圖計算
- 圖的概念
- 圖的術語
- 圖的經典表示法
- Spark Graphix簡介
- Graphx核心抽象
- Graphx Scala API
- 核心組件
- 屬性圖應用示例1
- 屬性圖應用示例2
- 查看圖信息
- 圖的算子
- 連通分量
- PageRank算法
- Pregel分布式計算框架
- Flume日志收集
- Flume是什么?
- Flume官方文檔
- Flume架構
- Flume安裝
- Flume使用過程
- Flume組件
- Flume工作流程
- Flume事務
- Source、Channel、Sink文檔
- Source文檔
- Channel文檔
- Sink文檔
- Flume攔截器
- Flume攔截器概念
- 配置攔截器
- 自定義攔截器
- Flume可靠性保證
- 故障轉移
- 負載均衡
- 多層代理
- 多路復用
- Kafka
- 消息中間件MQ
- Kafka是什么?
- Kafka安裝
- Kafka本地單機部署
- Kafka基本命令使用
- Topic的生產與消費
- 基本命令
- 查看kafka目錄
- Kafka架構
- Kafka Topic
- Kafka Producer
- Kafka Consumer
- Kafka Partition
- Kafka Message
- Kafka Broker
- 存儲策略
- ZooKeeper在Kafka中的作用
- 副本同步
- 容災
- 高吞吐
- Leader均衡機制
- Kafka Scala API
- Producer API
- Consumer API
- Kafka優化
- 消費者參數優化
- 生產者參數優化
- Spark Streaming
- 什么是流?
- 批處理和流處理
- Spark Streaming簡介
- 流數據處理架構
- 內部工作流程
- StreamingContext組件
- SparkStreaming的編程入口
- WordCount案例
- DStream
- DStream是什么?
- Input DStream與Receivers接收器
- DStream API
- 轉換操作
- 輸出操作
- 數據源
- 數據源分類
- Socket數據源
- 統計HDFS文件的詞頻
- 處理狀態數據
- SparkStreaming整合SparkSQL
- SparkStreaming整合Flume
- SparkStreaming整合Kafka
- 自定義數據源
- Spark Streaming優化策略
- 優化運行時間
- 優化內存使用
- 數據倉庫
- 數據倉庫是什么?
- 數據倉庫的意義
- 數據倉庫和數據庫的區別
- OLTP和OLAP的區別
- OLTP的特點
- OLAP的特點
- OLTP與OLAP對比
- 數據倉庫架構
- Inmon架構
- Kimball架構
- 混合型架構
- 數據倉庫的解決方案
- 數據ETL
- 數據倉庫建模流程
- 維度模型
- 星型模式
- 雪花模型
- 星座模型
- 數據ETL處理
- 數倉分層術語
- 數據抽取方式
- CDC抽取方案
- 數據轉換
- 常見的ETL工具