
#### 數組
數組:一塊連續的,大小固定并且里面的數據類型一致的內存空間,
如何聲明一個數組:
```
數據類型 數組名稱[長度];
```
數組只聲明也不行啊,看一下數組是如何初始化的。說到初始化,C語言中的數組初始化是有三種形式的,分別是:
* 1、 數據類型 數組名稱[長度n] = {元素1,元素2…元素n};
* 2、 數據類型 數組名稱[] = {元素1,元素2…元素n};
* 3、 數據類型 數組名稱[長度n]; 數組名稱[0] = 元素1; 數組名稱[1] = 元素2; 數組名稱[n] = 元素n+1;
我們將數據放到數組中之后又如何獲取數組中的元素呢?
```
獲取數組元素時: 數組名稱[元素所對應下標];
```
如:初始化一個數組 int arr[3] = {1,2,3}; 那么arr[0]就是元素1。
**注意:**
* **1、數組的下標均以0開始;**
* **2、數組在初始化的時候,數組內元素的個數不能大于聲明的數組長度;**
* **3、如果采用第一種初始化方式,元素個數小于數組的長度時,多余的數組元素初始化為0;**
* **4、在聲明數組后沒有進行初始化的時候,靜態(static)和外部(extern)類型的數組元素初始化元素為0,自動(auto)類型的數組的元素初始化值不確定。**
* **5、定義數組時,注意\[]不能放在數組名稱前面,這和Java是不一樣的**
#### 數組的遍歷
數組就可以**采用循環的方式將每個元素遍歷出來**,而不用人為的每次獲取指定某個位置上的元素,例如我們用for循環遍歷一個數組:
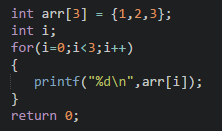
數組遍歷時要注意以下幾點:
**1、最好避免出現數組越界訪問,循環變量最好不要超出數組的長度**,比如:
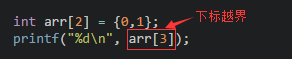
**2、C語言的數組長度一經聲明,長度就是固定,無法改變,并且C語言并不提供計算數組長度的方法。**
**3、如果 將int型變量定義在for循環內部,在C語言不同的編譯器如code blocks會報錯,然而在java中或者vs2015不報錯如下代碼所示**
```
#include <stdio.h>
int main()
{
int arr[] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
//補全代碼實現對數組arr的遍歷
//可以采用你自己喜歡的循環結果
//int i;
for(int i=0;i<10;i++)
{
printf("%d\n",arr[i]);
}
return 0;
}
```
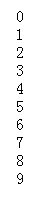
而在java中不報錯

> **由于C語言是沒有檢查數組長度改變或者數組越界的這個機制,可能會在編輯器中編譯并通過,但是結果就不能肯定了,因此還是不要越界或者改變數組的長度**
#### 數組作為函數參數 ####
前面我們學過,變量可以當作參數是吧!這里數組也是可以當做函數的參數滴,啊?什么?你問數組咋當參數?請看下面知識。
**數組可以由整個數組當作函數的參數,也可以由數組中的某個元素當作函數的參數:**
1、**整個數組當作函數參數**,即把數組名稱傳入函數中,例如:
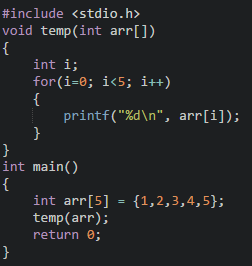
2、數組中的元素當作函數參數,即**把數組中的參數傳入函數**中,例如:
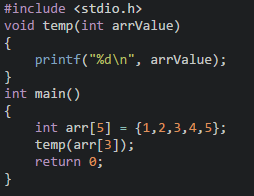
**數組作為函數參數時注意以下事項:**
**1、數組名作為函數實參傳遞時,函數定義處作為接收參數的數組類型形參既可以指定長度也可以不指定長度。**
**2、數組元素作為函數實參傳遞時,數組元素類型必須與形參數據類型一致。**
#### 數組的應用(一)
數組咋排序?
排序的方法呢有很多,這里小編給大家介紹一種比較經典且比較容易掌握的排序方法:冒泡排序。
以升序排序為例**冒泡排序的思想:相鄰元素兩兩比較,將較大的數字放在后面,直到將所有數字全部排序**。就像小學排隊時按大小個排一樣,將一個同學拉出來和后面的比比,如果高就放后面,一直把隊伍排好。
班級成績中,老師把前十名的挑出來了,用冒泡排序把分數排了一下
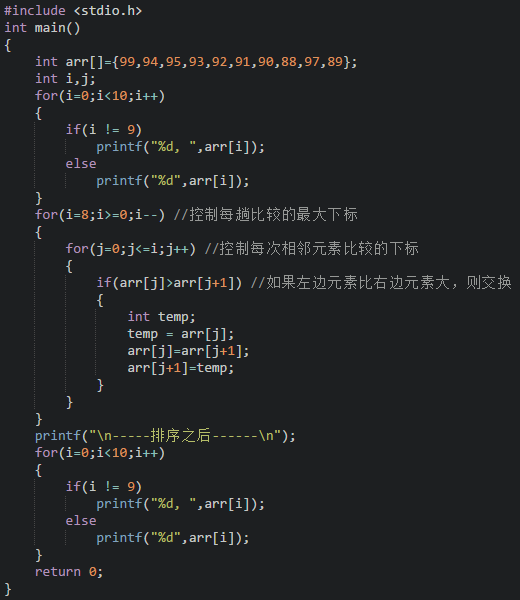
運行結果為

#### 數組的應用(二) ####
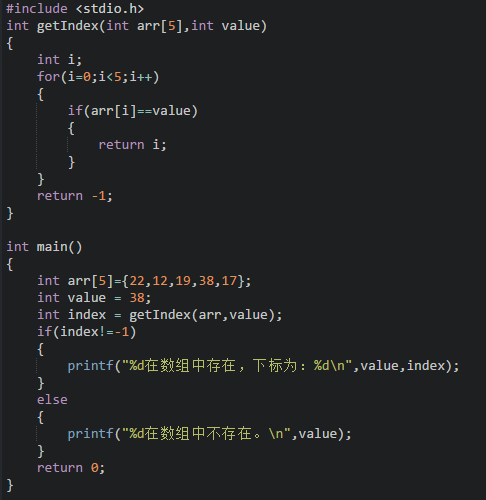
用數組查找功能,看看是否存在該數據,如果存在并返回該元素的下標。數組元素的查找也有很多查找方式,但是我們這里可以最簡單的方式,通過遍歷實現數組元素的查找。
比如以下程序實現在指定數組中查找指定元素的功能,如果找到該元素返回該元素的下標,否則返回-1:
#### 字符串與數組 ####
字符串是神馬?字符串就是由多個字符組合而成的一段話。
在C語言中,是沒有辦法直接定義字符串數據類型的,但是我們可以使用數組來定義我們所要的字符串。一般有以下兩種格式:
**1、char 字符串名稱[長度] = "字符串值";**
**2、char 字符串名稱[長度] = {'字符1','字符2',...,'字符n','\0'};**
注意:
* 1、[]中的長度是可以省略不寫的;
* 2、采用第2種方式的時候最后一個元素必須是'\0','\0'表示字符串的結束標志;
* 3、采用第2種方式的時候在數組中不能寫中文。
在輸出字符串的時候要使用:`printf(“%s”,字符數組名字);`或者`puts(字符數組名字);`。例如:

運行結果為

#### 字符串函數
常用的字符串函數如下:

使用字符串函數注意以下事項:
**1、strlen()獲取字符串的長度,在字符串長度中是不包括‘\0’而且漢字和字母的長度是不一樣的**。比如:

**2、strcmp()在比較的時候會把字符串先轉換成ASCII碼再進行比較,返回的結果為0表示s1和s2的ASCII碼相等,返回結果為1表示s1比s2的ASCII碼大,返回結果為-1表示s1比s2的ASCII碼小,**例如:
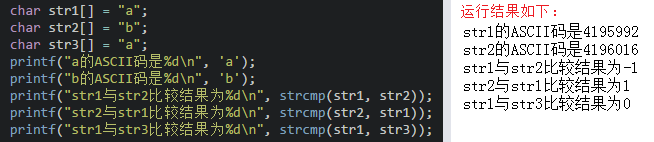
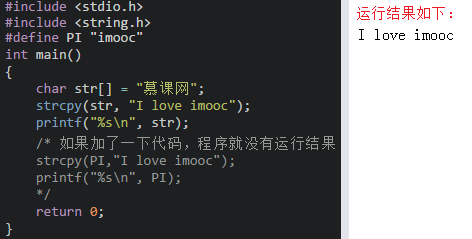
**3、strcpy()拷貝之后會覆蓋原來字符串且不能對字符串常量進行拷貝**,比如:
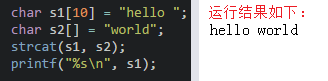
**4、strcat在使用時s1與s2指的內存空間不能重疊,且s1要有足夠的空間來容納要復制的字符串,即在是是s1后面拼接s2**,如:
#### 多維數組
多維數組就好比去超市買東西,用購物袋把所買商品分類存放,然后將所有的購物袋放到一個大的購物袋中,這樣就形成了一個多維數組了。
**多維數組的定義格式**是:
```
數據類型 數組名稱[常量表達式1][常量表達式2]...[常量表達式n];
```
例如:

這樣定義了一個名稱為num,數據類型為int的二維數組。其中第一個[3]表示第一維下標的長度,就像購物時分類存放的購物;第二個[3]表示第二維下標的長度,就像每個購物袋中的元素。
我們可以把上面的數組看作一個3×3的矩陣,如下圖:

多維數組的初始化與一維數組的初始化類似也是分兩種:
* 1、`數據類型 數組名稱[常量表達式1][常量表達式2]...[常量表達式n] = {{值1,..,值n},{值1,..,值n},...,{值1,..,值n}};`
* 2、`數據類型 數組名稱[常量表達式1][常量表達式2]...[常量表達式n]; 數組名稱[下標1][下標2]...[下標n] = 值;`
**多維數組初始化要注意以下事項:**
* **1、采用第一種始化時數組聲明必須指定列的維數。因為系統會根據數組中元素的總個數來分配空間,當知道元素總個數以及列的維數后,會直接計算出行的維數;**
* **2、采用第二種初始化時數組聲明必須同時指定行和列的維數。**
#### 多維數組的遍歷 ####
多維數組也是存在遍歷的,和一維數組遍歷一樣,也是需要用到循環。**不一樣的就是多維數組需要采用嵌套循環**,如:遍歷輸出int num[3][3] = {{1,2,3},{4,5,6},{7,8,9}};

**注意:多維數組的每一維下標均不能越界**
### 內存地址的概念
* 聲明一個變量,就會立即為這個變量申請內存,一定會有一個對應的內存地址
* 沒有地址的內存是無法使用的
* 內存的每一個字節都有一個對應的地址
* 內存地址用一個16進制數來表示
* 32位操作系統最大可以支持4G內存
* 32位系統的地址總線為32位,也就是說系統有2^32個數字可以分配給內存作為地址使用
- 前言
- JNI基礎知識
- C語言知識點總結
- ①基本語法
- ②數據類型
- 枚舉類型
- 自定義類型(類型定義)
- ③格式化輸入輸出
- printf函數
- scanf函數
- 編程規范
- ④變量和常量
- 局部變量和外部變量
- ⑤類型轉換
- ⑥運算符
- ⑦結構語句
- 1、分支結構(選擇語句)
- 2、循環結構
- 退出循環
- break語句
- continue語句
- goto語句
- ⑧函數
- 函數的定義和調用
- 參數
- 函數的返回值
- 遞歸函數
- 零起點學通C語言摘要
- 內部函數和外部函數
- 變量存儲類別
- ⑨數組
- 指針
- 結構體
- 聯合體(共用體)
- 預處理器
- 預處理器的工作原理
- 預處理指令
- 宏定義
- 簡單的宏
- 帶參數的宏
- 預定義宏
- 文件包含
- 條件編譯
- 內存中的數據
- C語言讀文件和寫文件
- JNI知識點總結
- 前情回顧
- JNI規范
- jni開發
- jni開發中常見的錯誤
- JNI實戰演練
- C++(CPP)在Android開發中的應用
- 掘金網友總結的音視頻開發知識
- 音視頻學習一、C 語言入門
- 1.程序結構
- 2. 基本語法
- 3. 數據類型
- 4. 變量
- 5. 常量
- 6. 存儲類型關鍵字
- 7. 運算符
- 8. 判斷
- 9. 循環
- 10. 函數
- 11. 作用域規則
- 12. 數組
- 13. 枚舉
- 14. 指針
- 15. 函數指針與回調函數
- 16. 字符串
- 17. 結構體
- 18. 共用體
- 19. typedef
- 20. 輸入 & 輸出
- 21.文件讀寫
- 22. 預處理器
- 23.頭文件
- 24. 強制類型轉換
- 25. 錯誤處理
- 26. 遞歸
- 27. 可變參數
- 28. 內存管理
- 29. 命令行參數
- 總結
- 音視頻學習二 、C++ 語言入門
- 1. 基本語法
- 2. C++ 關鍵字
- 3. 數據類型
- 4. 變量類型
- 5. 變量作用域
- 6. 常量
- 7. 修飾符類型
- 8. 存儲類
- 9. 運算符
- 10. 循環
- 11. 判斷
- 12. 函數
- 13. 數學運算
- 14. 數組
- 15. 字符串
- 16. 指針
- 17. 引用
- 18. 日期 & 時間
- 19. 輸入輸出
- 20. 數據結構
- 21. 類 & 對象
- 22. 繼承
- 23. 重載運算符和重載函數
- 24. 多態
- 25. 數據封裝
- 26. 接口(抽象類)
- 27. 文件和流
- 28. 異常處理
- 29. 動態內存
- 30. 命名空間
- 31. 預處理器
- 32. 多線程
- 總結
- 音視頻學習 (三) JNI 從入門到掌握
- 音視頻學習 (四) 交叉編譯動態庫、靜態庫的入門學習
- 音視頻學習 (五) Shell 腳本入門
- 音視頻學習 (六) 一鍵編譯 32/64 位 FFmpeg 4.2.2
- 音視頻學習 (七) 掌握音頻基礎知識并使用 AudioTrack、OpenSL ES 渲染 PCM 數據
- 音視頻學習 (八) 掌握視頻基礎知識并使用 OpenGL ES 2.0 渲染 YUV 數據
- 音視頻學習 (九) 從 0 ~ 1 開發一款 Android 端播放器(支持多協議網絡拉流/本地文件)
- 音視頻學習 (十) 基于 Nginx 搭建(rtmp、http)直播服務器
- 音視頻學習 (十一) Android 端實現 rtmp 推流
- 音視頻學習 (十二) 基于 FFmpeg + OpenSLES 實現音頻萬能播放器
- 音視頻學習 (十三) Android 中通過 FFmpeg 命令對音視頻編輯處理(已開源)