
# 三、處理表格數據
> 原文:[DS-100/textbook/notebooks/ch03](https://nbviewer.jupyter.org/github/DS-100/textbook/tree/master/notebooks/ch03/)
>
> 校驗:[飛龍](https://github.com/wizardforcel)
>
> 自豪地采用[谷歌翻譯](https://translate.google.cn/)
## 索引、切片和排序
### 起步
在本章的每一節中,我們將使用第一章中的嬰兒名稱數據集。我們將提出一個問題,將問題分解為大體步驟,然后使用`pandas DataFrame`將每個步驟轉換為 Python 代碼。 我們從導入`pandas`開始:
```py
# pd is a common shorthand for pandas
import pandas as pd
```
現在我們可以使用[`pd.read_csv`](https://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_csv.html)讀取數據。
```py
baby = pd.read_csv('babynames.csv')
baby
```
| | Name | Sex | Count | Year |
| --- | --- | --- | --- | --- |
| 0 | Mary | F | 9217 | 1884 |
| 1 | Anna | F | 3860 | 1884 |
| 2 | Emma | F | 2587 | 1884 |
| ... | ... | ... | ... | ... |
| 1891891 | Verna | M | 5 | 1883 |
| 1891892 | Winnie | M | 5 | 1883 |
| 1891893 | Winthrop | M | 5 | 1883 |
1891894 行 × 4 列
請注意,為了使上述代碼正常工作,`babynames.csv`文件必須位于這個筆記本的相同目錄中。 通過在筆記本單元格中運行`ls`,我們可以檢查當前文件夾中的文件:
```
ls
# babynames.csv indexes_slicing_sorting.ipynb
```
當我們使用熊貓來讀取數據時,我們得到一個`DataFrame`。 `DataFrame`是一個表格數據結構,其中每列都有標簽(這里是`'Name', 'Sex', 'Count', 'Year'`),并且每一行都有標簽(這里是`0,1,2, ..., 1891893`)。 然而,Data8 中引入的表格僅包含列標簽。
`DataFrame`的標簽稱為`DataFrame`的索引,并使許多數據操作更容易。
### 索引、切片和排序
讓我們使用`pandas`來回答以下問題:
2016 年的五個最受歡迎的嬰兒名字是?
#### 拆分問題
我們可以將這個問題分解成以下更簡單的表格操作:
+ 分割出 2016 年的行。
+ 按照計數對行降序排序。
現在,我們可以在`pandas`中表達這些步驟。
#### 使用`.loc`切片
為了選擇`DataFrame`的子集,我們使用`.loc`切片語法。 第一個參數是行標簽,第二個參數是列標簽:
```py
baby
```
| | Name | Sex | Count | Year |
| --- | --- | --- | --- | --- |
| 0 | Mary | F | 9217 | 1884 |
| 1 | Anna | F | 3860 | 1884 |
| 2 | Emma | F | 2587 | 1884 |
| ... | ... | ... | ... | ... |
| 1891891 | Verna | M | 5 | 1883 |
| 1891892 | Winnie | M | 5 | 1883 |
| 1891893 | Winthrop | M | 5 | 1883 |
1891894 行 × 4 列
```py
baby.loc[1, 'Name'] # Row labeled 1, Column labeled 'Name'
# 'Anna'
```
要分割出多行或多列,我們可以使用`:`。 請注意`.loc`切片是包容性的,與 Python 的切片不同。
```py
# Get rows 1 through 5, columns Name through Count inclusive
baby.loc[1:5, 'Name':'Count']
```
| | Name | Sex | Count |
| --- | --- | --- | --- |
| 1 | Anna | F | 3860 |
| 2 | Emma | F | 2587 |
| 3 | Elizabeth | F | 2549 |
| 4 | Minnie | F | 2243 |
| 5 | Margaret | F | 2142 |
我們通常需要`DataFrame`中的單個列:
```py
baby.loc[:, 'Year']
'''
0 1884
1 1884
2 1884
...
1891891 1883
1891892 1883
1891893 1883
Name: Year, Length: 1891894, dtype: int64
'''
```
請注意,當我們選擇一列時,我們會得到一個`pandas`序列。 序列就像一維 NumPy 數組,因為我們可以一次在所有元素上執行算術運算。
```py
baby.loc[:, 'Year'] * 2
'''
0 3768
1 3768
2 3768
...
1891891 3766
1891892 3766
1891893 3766
Name: Year, Length: 1891894, dtype: int64
'''
```
為了選擇特定的列,我們可以將列表傳遞給`.loc`切片:
```py
# This is a DataFrame again
baby.loc[:, ['Name', 'Year']]
```
| | Name | Year |
| --- | --- | --- |
| 0 | Mary | 1884 |
| 1 | Anna | 1884 |
| 2 | Emma | 1884 |
| ... | ... | ... |
| 1891891 | Verna | 1883 |
| 1891892 | Winnie | 1883 |
| 1891893 | Winthrop | 1883 |
1891894 行 × 2 列
選擇列很常見,所以存在簡寫。
```py
# Shorthand for baby.loc[:, 'Name']
baby['Name']
'''
0 Mary
1 Anna
2 Emma
...
1891891 Verna
1891892 Winnie
1891893 Winthrop
Name: Name, Length: 1891894, dtype: object
'''
```
```py
# Shorthand for baby.loc[:, ['Name', 'Count']]
baby[['Name', 'Count']]
```
| | Name | Count |
| --- | --- | --- |
| 0 | Mary | 9217 |
| 1 | Anna | 3860 |
| 2 | Emma | 2587 |
| ... | ... | ... |
| 1891891 | Verna | 5 |
| 1891892 | Winnie | 5 |
| 1891893 | Winthrop | 5 |
1891894 行 × 2 列
**使用謂詞對行切片**
為了分割出 2016 年的行,我們將首先創建一個序列,其中每個想要保留的行為`True`,每個想要刪除的行為`False`。 這很簡單,因為序列上的數學和布爾運算符,應用于序列中的每個元素。
```py
# Series of years
baby['Year']
'''
0 1884
1 1884
2 1884
...
1891891 1883
1891892 1883
1891893 1883
Name: Year, Length: 1891894, dtype: int64
'''
```
```py
# Compare each year with 2016
baby['Year'] == 2016
'''
0 False
1 False
2 False
...
1891891 False
1891892 False
1891893 False
Name: Year, Length: 1891894, dtype: bool
'''
```
一旦我們有了這個`True`和`False`的序列,我們就可以將它傳遞給`.loc`。
```py
# We are slicing rows, so the boolean Series goes in the first
# argument to .loc
baby_2016 = baby.loc[baby['Year'] == 2016, :]
baby_2016
```
| | Name | Sex | Count | Year |
| --- | --- | --- | --- | --- |
| 1850880 | Emma | F | 19414 | 2016 |
| 1850881 | Olivia | F | 19246 | 2016 |
| 1850882 | Ava | F | 16237 | 2016 |
| ... | ... | ... | ... | ... |
| 1883745 | Zyahir | M | 5 | 2016 |
| 1883746 | Zyel | M | 5 | 2016 |
| 1883747 | Zylyn | M | 5 | 2016 |
32868 行 × 4 列
### 對行排序
下一步是按`'Count'`對行降序排序。 我們可以使用`sort_values()`函數。
```py
sorted_2016 = baby_2016.sort_values('Count', ascending=False)
sorted_2016
```
| | Name | Sex | Count | Year |
| --- | --- | --- | --- | --- |
| 1850880 | Emma | F | 19414 | 2016 |
| 1850881 | Olivia | F | 19246 | 2016 |
| 1869637 | Noah | M | 19015 | 2016 |
| ... | ... | ... | ... | ... |
| 1868752 | Mikaelyn | F | 5 | 2016 |
| 1868751 | Miette | F | 5 | 2016 |
| 1883747 | Zylyn | M | 5 | 2016 |
32868 行 × 4 列
最后,我們將使用`.iloc`分割出`DataFrame`的前五行。 `.iloc`的工作方式類似`.loc`,但接受數字索引而不是標簽。 它的切片中沒有包含右邊界,就像 Python 的列表切片。
```py
# Get the value in the zeroth row, zeroth column
sorted_2016.iloc[0, 0]
# Get the first five rows
sorted_2016.iloc[0:5]
```
| | Name | Sex | Count | Year |
| --- | --- | --- | --- | --- |
| 1850880 | Emma | F | 19414 | 2016 |
| 1850881 | Olivia | F | 19246 | 2016 |
| 1869637 | Noah | M | 19015 | 2016 |
| 1869638 | Liam | M | 18138 | 2016 |
| 1850882 | Ava | F | 16237 | 2016 |
### 總結
我們現在擁有了 2016 年的五個最受歡迎的嬰兒名稱,并且學會了在`pandas`中表達以下操作:
| 操作 | `pandas` |
| --- | --- |
| 讀取 CSV 文件 | `pd.read_csv()` |
| 使用標簽或索引來切片 | `.loc`和`.iloc` |
| 使用謂詞對行切片 | 在`.loc`中使用布爾值的序列 |
| 對行排序 | `.sort_values()` |
## 分組和透視
在本節中,我們將回答這個問題:
每年最受歡迎的男性和女性名稱是什么?
這里再次展示了嬰兒名稱數據集:
```py
baby = pd.read_csv('babynames.csv')
baby.head()
# the .head() method outputs the first five rows of the DataFrame
```
| | Name | Sex | Count | Year |
| --- | --- | --- | --- | --- |
| 0 | Mary | F | 9217 | 1884 |
| 1 | Anna | F | 3860 | 1884 |
| 2 | Emma | F | 2587 | 1884 |
| 3 | Elizabeth | F | 2549 | 1884 |
| 4 | Minnie | F | 2243 | 1884 |
### 拆分問題
我們應該首先注意到,上一節中的問題與這個問題有相似之處;上一節中的問題將名稱限制為 2016 年出生的嬰兒,而這個問題要求所有年份的名稱。
我們再次將這個問題分解成更簡單的表格操作。
+ 將`baby`表按`'Year'`和`'Sex'`分組。
+ 對于每一組,計算最流行的名稱。
認識到每個問題需要哪種操作,有時很棘手。通常,一系列復雜的步驟會告訴你,可能有更簡單的方式來表達你想要的東西。例如,如果我們沒有立即意識到需要分組,我們可能會編寫如下步驟:
+ 遍歷每個特定的年份。
+ 對于每一年,遍歷每個特定的性別。
+ 對于每一個特定年份和性別,找到最常見的名字。
幾乎總是有一種更好的替代方法,用于遍歷`pandas DataFrame`。特別是,遍歷`DataFrame`的特定值,通常應該替換為分組。
#### 分組
為了在`pandas`中進行分組。 我們使用`.groupby()`方法。
```py
baby.groupby('Year')
# <pandas.core.groupby.DataFrameGroupBy object at 0x1a14e21f60>
```
`.groupby()`返回一個奇怪的`DataFrameGroupBy`對象。 我們可以使用聚合函數,在該對象上調用`.agg()`來獲得熟悉的輸出:
```py
# The aggregation function takes in a series of values for each group
# and outputs a single value
def length(series):
return len(series)
# Count up number of values for each year. This is equivalent to
# counting the number of rows where each year appears.
baby.groupby('Year').agg(length)
```
| | Name | Sex | Count |
| --- | --- | --- | --- |
| Year | | | |
| 1880 | 2000 | 2000 | 2000 |
| 1881 | 1935 | 1935 | 1935 |
| 1882 | 2127 | 2127 | 2127 |
| ... | ... | ... | ... |
| 2014 | 33206 | 33206 | 33206 |
| 2015 | 33063 | 33063 | 33063 |
| 2016 | 32868 | 32868 | 32868 |
137 行 × 3 列
你可能會注意到`length`函數只是簡單調用了`len`函數,所以我們可以簡化上面的代碼。
```py
baby.groupby('Year').agg(len)
```
| Name | Sex | Count |
| --- | --- | --- | --- |
| Year | | | |
| 1880 | 2000 | 2000 | 2000 |
| 1881 | 1935 | 1935 | 1935 |
| 1882 | 2127 | 2127 | 2127 |
| ... | ... | ... | ... |
| 2014 | 33206 | 33206 | 33206 |
| 2015 | 33063 | 33063 | 33063 |
| 2016 | 32868 | 32868 | 32868 |
137 行 × 3 列
聚合應用于`DataFrame`的每一列,從而產生冗余信息。 我們可以在分組之前使用切片限制輸出列。
```py
year_rows = baby[['Year', 'Count']].groupby('Year').agg(len)
year_rows
# A further shorthand to accomplish the same result:
#
# year_counts = baby[['Year', 'Count']].groupby('Year').count()
#
# pandas has shorthands for common aggregation functions, including
# count, sum, and mean.
```
| | Count |
| --- | --- |
| Year | |
| 1880 | 2000 |
| 1881 | 1935 |
| 1882 | 2127 |
| ... | ... |
| 2014 | 33206 |
| 2015 | 33063 |
| 2016 | 32868 |
137 行 × 1 列
請注意,生成的`DataFrame`的索引現在包含特定年份,因此我們可以像以前一樣,使用`.loc`分割出年份的子集:
```py
# Every twentieth year starting at 1880
year_rows.loc[1880:2016:20, :]
```
| | Count |
| --- | --- |
| Year | |
| 1880 | 2000 |
| 1900 | 3730 |
| 1920 | 10755 |
| 1940 | 8961 |
| 1960 | 11924 |
| 1980 | 19440 |
| 2000 | 29764 |
### 多個列的分組
我們在 Data8 中看到,我們可以按照多個列分組,基于唯一值來獲取分組。 為此,請將列標簽列表傳遞到`.groupby()`。
```py
grouped_counts = baby.groupby(['Year', 'Sex']).sum()
grouped_counts
```
| | | Count |
| --- | --- | --- |
| Year | Sex | |
| 1880 | F | 90992 |
| M | 110491 |
| 1881 | F | 91953 |
| ... | ... | ... |
| 2015 | M | 1907211 |
| 2016 | F | 1756647 |
| M | 1880674 |
274 行 × 1 列
上面的代碼計算每年每個性別出生的嬰兒總數。 現在讓我們使用多列分組,來計算每年和每個性別的最流行的名稱。 由于數據已按照年和性別的遞減順序排序,因此我們可以定義一個聚合函數,該函數返回每個序列中的第一個值。 (如果數據沒有排序,我們可以先調用`sort_values()`。)
```py
# The most popular name is simply the first one that appears in the series
def most_popular(series):
return series.iloc[0]
baby_pop = baby.groupby(['Year', 'Sex']).agg(most_popular)
baby_pop
```
| | | Name | Count |
| --- | --- | --- | --- |
| Year | Sex | | |
| 1880 | F | Mary | 7065 |
| M | John | 9655 |
| 1881 | F | Mary | 6919 |
| ... | ... | ... | ... |
| 2015 | M | Noah | 19594 |
| 2016 | F | Emma | 19414 |
| M | Noah | 19015 |
274 行 × 2 列
注意,多列分組會導致每行有多個標簽。 這被稱為“多級索引”,并且很難處理。 需要知道的重要事情是,`.loc`接受行索引的元組,而不是單個值:
```py
baby_pop.loc[(2000, 'F'), 'Name']
# 'Emily'
```
但`.iloc`的行為與往常一樣,因為它使用索引而不是標簽:
```py
baby_pop.iloc[10:15, :]
```
| | | Name | Count |
| --- | --- | --- | --- |
| Year | Sex | | |
| 1885 | F | Mary | 9128 |
| M | John | 8756 |
| 1886 | F | Mary | 9889 |
| M | John | 9026 |
| 1887 | F | Mary | 9888 |
#### 透視
如果按兩列分組,則通常可以使用數據透視表,以更方便的格式顯示數據。 數據透視表可以使用一組分組標簽,作為結果表的列。
為了透視,使用`pd.pivot_table()`函數。
```py
pd.pivot_table(baby,
index='Year', # Index for rows
columns='Sex', # Columns
values='Name', # Values in table
aggfunc=most_popular) # Aggregation function
```
| Sex | F | M |
| --- | --- | --- |
| Year | | |
| 1880 | Mary | John |
| 1881 | Mary | John |
| 1882 | Mary | John |
| ... | ... | ... |
| 2014 | Emma | Noah |
| 2015 | Emma | Noah |
| 2016 | Emma | Noah |
137 行 × 2 列
將此結果與我們使用`.groupby()`計算的`baby_pop`表進行比較。 我們可以看到`baby_pop`中的`Sex`索引成為了數據透視表的列。
```py
baby_pop
```
| | | Name | Count |
| --- | --- | --- | --- |
| Year | Sex | | |
| 1880 | F | Mary | 7065 |
| M | John | 9655 |
| 1881 | F | Mary | 6919 |
| ... | ... | ... | ... |
| 2015 | M | Noah | 19594 |
| 2016 | F | Emma | 19414 |
| M | Noah | 19015 |
274 行 × 2 列
### 總結
我們現在有了數據集中每個性別和年份的最受歡迎的嬰兒名稱,并學會了在`pandas`中表達以下操作:
| 操作 | `pandas` |
| --- | --- |
| 分組 | `df.groupby(label)` |
| 多列分組 | `df.groupby([label1, label2])` |
| 分組和聚合 | `df.groupby(label).agg(func)` |
| 透視 | `pd.pivot_table()` |
## 應用、字符串和繪圖
在本節中,我們將回答這個問題:
我們可以用名字的最后一個字母來預測嬰兒的性別嗎?
這里再次展示了嬰兒名稱數據集:
```py
baby = pd.read_csv('babynames.csv')
baby.head()
# the .head() method outputs the first five rows of the DataFrame
```
| | Name | Sex | Count | Year |
| --- | --- | --- | --- | --- |
| 0 | Mary | F | 9217 | 1884 |
| 1 | Anna | F | 3860 | 1884 |
| 2 | Emma | F | 2587 | 1884 |
| 3 | Elizabeth | F | 2549 | 1884 |
| 4 | Minnie | F | 2243 | 1884 |
### 拆解問題
雖然有很多方法可以預測是否可能,但我們將在本節中使用繪圖。 我們可以將這個問題分解為兩個步驟:
+ 計算每個名稱的最后一個字母。
+ 按照最后一個字母和性別分組,使用計數來聚合。
+ 繪制每個性別和字母的計數。
### 應用
`pandas`序列包含`.apply()`方法,它接受一個函數并將其應用于序列中的每個值。
```py
names = baby['Name']
names.apply(len)
'''
0 4
1 4
2 4
..
1891891 5
1891892 6
1891893 8
Name: Name, Length: 1891894, dtype: int64
'''
```
為了提取每個名字的最后一個字母,我們可以定義我們自己的函數來傳入`.apply()`:
```py
def last_letter(string):
return string[-1]
names.apply(last_letter)
'''
0 y
1 a
2 a
..
1891891 a
1891892 e
1891893 p
Name: Name, Length: 1891894, dtype: object
'''
```
### 字符串操作
雖然`.apply()`是靈活的,但在處理文本數據時,在使用`pandas`內置的字符串操作函數通常會更快。
`pandas`通過序列的`.str`屬性,提供字符串操作函數。
```py
names = baby['Name']
names.str.len()
'''
0 4
1 4
2 4
..
1891891 5
1891892 6
1891893 8
Name: Name, Length: 1891894, dtype: int64
'''
```
我們可以用類似的方式,直接分離出每個名字的最后一個字母。
```py
names.str[-1]
'''
0 y
1 a
2 a
..
1891891 a
1891892 e
1891893 p
Name: Name, Length: 1891894, dtype: object
'''
```
我們建議查看文檔來獲取[字符串方法的完整列表](https://pandas.pydata.org/pandas-docs/stable/text.html)。
我們現在可以將最后一個字母的這一列添加到我們的嬰兒數據幀中。
```py
baby['Last'] = names.str[-1]
baby
```
| | Name | Sex | Count | Year | Last |
| --- | --- | --- | --- | --- | --- |
| 0 | Mary | F | 9217 | 1884 | y |
| 1 | Anna | F | 3860 | 1884 | a |
| 2 | Emma | F | 2587 | 1884 | a |
| ... | ... | ... | ... | ... | ... |
| 1891891 | Verna | M | 5 | 1883 | a |
| 1891892 | Winnie | M | 5 | 1883 | e |
| 1891893 | Winthrop | M | 5 | 1883 | p |
1891894 行 × 5 列
### 分組
為了計算每個最后一個字母的性別分布,我們需要按`Last`和`Sex`分組。
```py
# Shorthand for baby.groupby(['Last', 'Sex']).agg(np.sum)
baby.groupby(['Last', 'Sex']).sum()
```
| | | Count | Year |
| --- | --- | --- | --- |
| Last | Sex | | |
| a | F | 58079486 | 915565667 |
| M | 1931630 | 53566324 |
| b | F | 17376 | 1092953 |
| ... | ... | ... | ... |
| y | M | 18569388 | 114394474 |
| z | F | 142023 | 4268028 |
| M | 120123 | 9649274 |
52 行 × 2 列
請注意,因為每個沒有用于分組的列都傳遞到聚合函數中,所以也求和了年份。 為避免這種情況,我們可以在調用`.groupby()`之前選擇所需的列。
```py
# When lines get long, you can wrap the entire expression in parentheses
# and insert newlines before each method call
letter_dist = (
baby[['Last', 'Sex', 'Count']]
.groupby(['Last', 'Sex'])
.sum()
)
letter_dist
```
| | | Count |
| --- | --- | --- |
| Last | Sex | |
| a | F | 58079486 |
| M | 1931630 |
| b | F | 17376 |
| ... | ... | ... |
| y | M | 18569388 |
| z | F | 142023 |
| M | 120123 |
52 行 × 1 列
### 繪圖
`pandas`為大多數基本繪圖提供了內置的繪圖函數,包括條形圖,直方圖,折線圖和散點圖。 為了從`DataFrame`中繪制圖形,請使用`.plot`屬性:
```py
# We use the figsize option to make the plot larger
letter_dist.plot.barh(figsize=(10, 10))
# <matplotlib.axes._subplots.AxesSubplot at 0x1a17af4780>
```
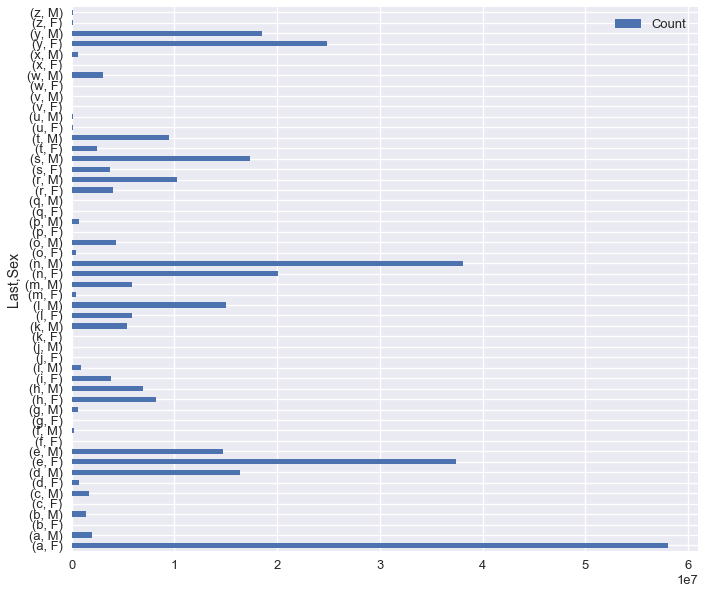
雖然這個繪圖顯示了字母和性別的分布,但是男性和女性的條形很難分開。 通過在`pandas`文檔中查看[繪圖](https://pandas.pydata.org/pandas-docs/stable/visualization.html),我們了解到`pandas`將`DataFrame`的一行中的列繪制為一組條形,并將每列顯示為不同顏色的條形。 這意味著`letter_dist`表的透視版本將具有正確的格式。
```py
letter_pivot = pd.pivot_table(
baby, index='Last', columns='Sex', values='Count', aggfunc='sum'
)
letter_pivot
```
| | Sex | F | M |
| --- | --- | --- | --- |
| Last | | |
| a | 58079486 | 1931630 |
| b | 17376 | 1435939 |
| c | 30262 | 1672407 |
| ... | ... | ... |
| x | 37381 | 644092 |
| y | 24877638 | 18569388 |
| z | 142023 | 120123 |
26 行 × 2 列
```py
letter_pivot.plot.barh(figsize=(10, 10))
# <matplotlib.axes._subplots.AxesSubplot at 0x1a17c36978>
```
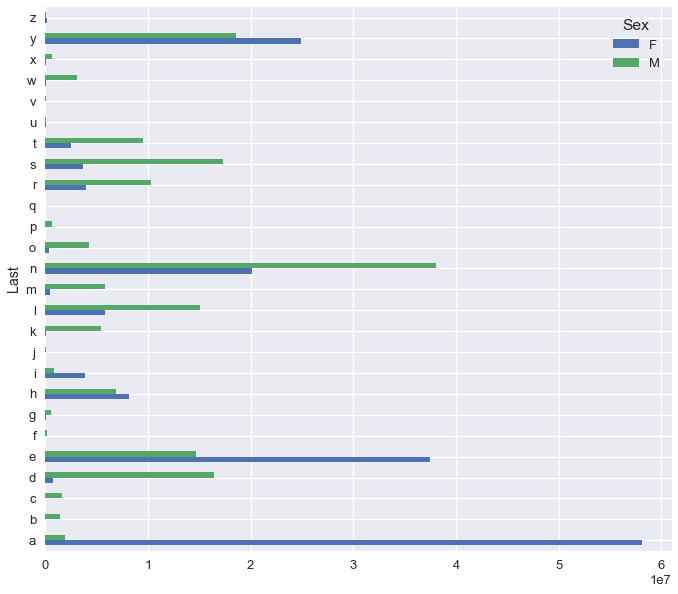
請注意,`pandas`為我們生成了圖例,這很方便 但是,這仍然難以解釋。 我們為每個字母和性別繪制了計數,這些計數會導致一些條形看起來很長,而另一些幾乎看不見。 相反,我們應該繪制每個最后一個字母的男性和女性的比例。
```py
total_for_each_letter = letter_pivot['F'] + letter_pivot['M']
letter_pivot['F prop'] = letter_pivot['F'] / total_for_each_letter
letter_pivot['M prop'] = letter_pivot['M'] / total_for_each_letter
letter_pivot
```
| Sex | F | M | F prop | M prop |
| --- | --- | --- | --- | --- |
| Last | | | | |
| a | 58079486 | 1931630 | 0.967812 | 0.032188 |
| b | 17376 | 1435939 | 0.011956 | 0.988044 |
| c | 30262 | 1672407 | 0.017773 | 0.982227 |
| ... | ... | ... | ... | ... |
| x | 37381 | 644092 | 0.054853 | 0.945147 |
| y | 24877638 | 18569388 | 0.572597 | 0.427403 |
| z | 142023 | 120123 | 0.541771 | 0.458229 |
26 行 × 4 列
```py
(letter_pivot[['F prop', 'M prop']]
.sort_values('M prop') # Sorting orders the plotted bars
.plot.barh(figsize=(10, 10))
)
# <matplotlib.axes._subplots.AxesSubplot at 0x1a18194b70>
```
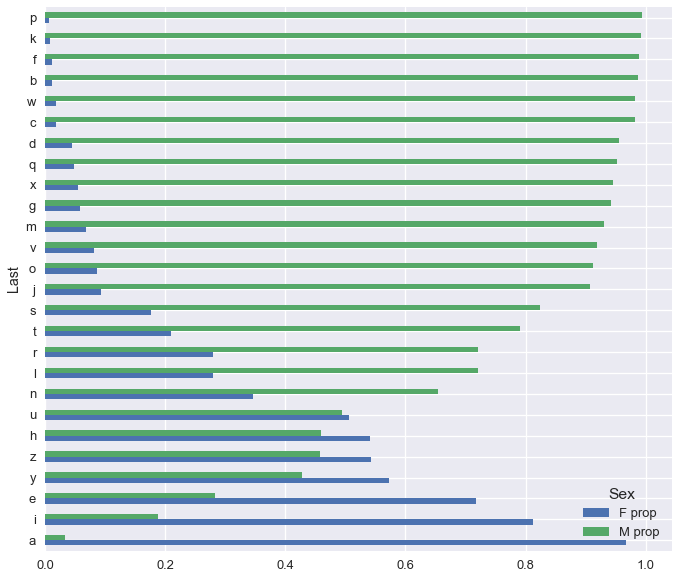
### 總結
我們可以看到幾乎所有以`'p'`結尾的名字都是男性,以`'a'`結尾的名字都是女性! 一般來說,許多字母的條形長度之間的差異意味著,如果我們只知道他們的名字的最后一個字母,我們往往可以準確猜測一個人的性別。
我們已經學會在`pandas`中表達以下操作:
| 操作 | `pandas` |
| --- | --- |
| 逐元素應用函數 | `series.apply(func)` |
| 字符串操作 | `series.str.func()` |
| 繪圖 | `df.plot.func()` |
- 一、數據科學的生命周期
- 二、數據生成
- 三、處理表格數據
- 四、數據清理
- 五、探索性數據分析
- 六、數據可視化
- Web 技術
- 超文本傳輸協議
- 處理文本
- python 字符串方法
- 正則表達式
- regex 和 python
- 關系數據庫和 SQL
- 關系模型
- SQL
- SQL 連接
- 建模與估計
- 模型
- 損失函數
- 絕對損失和 Huber 損失
- 梯度下降與數值優化
- 使用程序最小化損失
- 梯度下降
- 凸性
- 隨機梯度下降法
- 概率與泛化
- 隨機變量
- 期望和方差
- 風險
- 線性模型
- 預測小費金額
- 用梯度下降擬合線性模型
- 多元線性回歸
- 最小二乘-幾何透視
- 線性回歸案例研究
- 特征工程
- 沃爾瑪數據集
- 預測冰淇淋評級
- 偏方差權衡
- 風險和損失最小化
- 模型偏差和方差
- 交叉驗證
- 正規化
- 正則化直覺
- L2 正則化:嶺回歸
- L1 正則化:LASSO 回歸
- 分類
- 概率回歸
- Logistic 模型
- Logistic 模型的損失函數
- 使用邏輯回歸
- 經驗概率分布的近似
- 擬合 Logistic 模型
- 評估 Logistic 模型
- 多類分類
- 統計推斷
- 假設檢驗和置信區間
- 置換檢驗
- 線性回歸的自舉(真系數的推斷)
- 學生化自舉
- P-HACKING
- 向量空間回顧
- 參考表
- Pandas
- Seaborn
- Matplotlib
- Scikit Learn