
# Logistic 模型
> 原文:[https://www.bookbookmark.ds100.org/ch/17/classification_log_model.html](https://www.bookbookmark.ds100.org/ch/17/classification_log_model.html)
```
# HIDDEN
# Clear previously defined variables
%reset -f
# Set directory for data loading to work properly
import os
os.chdir(os.path.expanduser('~/notebooks/17'))
```
```
# HIDDEN
import warnings
# Ignore numpy dtype warnings. These warnings are caused by an interaction
# between numpy and Cython and can be safely ignored.
# Reference: https://stackoverflow.com/a/40846742
warnings.filterwarnings("ignore", message="numpy.dtype size changed")
warnings.filterwarnings("ignore", message="numpy.ufunc size changed")
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
%matplotlib inline
import ipywidgets as widgets
from ipywidgets import interact, interactive, fixed, interact_manual
import nbinteract as nbi
sns.set()
sns.set_context('talk')
np.set_printoptions(threshold=20, precision=2, suppress=True)
pd.options.display.max_rows = 7
pd.options.display.max_columns = 8
pd.set_option('precision', 2)
# This option stops scientific notation for pandas
# pd.set_option('display.float_format', '{:.2f}'.format)
```
```
# HIDDEN
def df_interact(df, nrows=7, ncols=7):
'''
Outputs sliders that show rows and columns of df
'''
def peek(row=0, col=0):
return df.iloc[row:row + nrows, col:col + ncols]
if len(df.columns) <= ncols:
interact(peek, row=(0, len(df) - nrows, nrows), col=fixed(0))
else:
interact(peek,
row=(0, len(df) - nrows, nrows),
col=(0, len(df.columns) - ncols))
print('({} rows, {} columns) total'.format(df.shape[0], df.shape[1]))
```
```
# HIDDEN
def jitter_df(df, x_col, y_col):
x_jittered = df[x_col] + np.random.normal(scale=0, size=len(df))
y_jittered = df[y_col] + np.random.normal(scale=0.05, size=len(df))
return df.assign(**{x_col: x_jittered, y_col: y_jittered})
```
```
# HIDDEN
lebron = pd.read_csv('lebron.csv')
```
在本節中,我們將介紹**邏輯模型**,這是一個用于預測概率的回歸模型。
回想一下,擬合一個模型需要三個部分:一個預測模型、一個損失函數和一個優化方法。對于目前熟悉的最小二乘線性回歸,我們選擇模型:
$$ \begin{aligned} f_\hat{\boldsymbol{\theta}} (\textbf{x}) &= \hat{\boldsymbol{\theta}} \cdot \textbf{x} \end{aligned} $$
損失函數:
$$ \begin{aligned} L(\boldsymbol{\theta}, \textbf{X}, \textbf{y}) &= \frac{1}{n} \sum_{i}(y_i - f_\boldsymbol{\theta} (\textbf{X}_i))^2\\ \end{aligned} $$
我們使用梯度下降作為優化方法。在上面的定義中,$\textbf x$表示$n \乘以 p$的數據矩陣($n$表示數據點的數目,$p$表示屬性的數目),$\textbf x$表示一行$\textbf x,$textbf y$表示觀察結果的向量。矢量$\BoldSymbol \Hat \Theta 包含最佳模型權重,而$\BoldSymbol \Theta 包含優化期間生成的中間權重值。
## 實數與概率
觀察到模型$f_ \hat \\\123\123\123; \123\\123\123\125\\\\125\\123\\\123\\\\\\\\\\\\\\\\.
當$x$是一個標量時,我們可以很容易地看到這一點。如果$\hat\theta=0.5$,我們的模型將變為$f \theta(\textbf x)=0.5 x$。它的預測值可以是從負無窮大到正無窮大的任意值:
```
# HIDDEN
xs = np.linspace(-100, 100, 100)
ys = 0.5 * xs
plt.plot(xs, ys)
plt.xlabel('$x$')
plt.ylabel(r'$f_\hat{\theta}(x)$')
plt.title(r'Model Predictions for $ \hat{\theta} = 0.5 $');
```
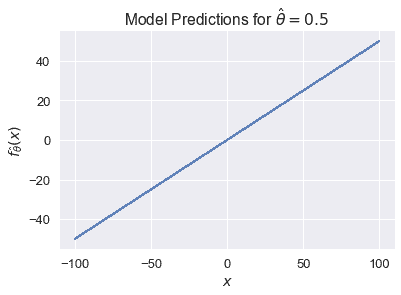
對于分類任務,我們希望限制$f_ \hat \boldSymbol \theta(\textbf x)$以便將其輸出解釋為概率。這意味著它只能輸出$[0,1]$范圍內的值。此外,我們希望$f_ux \boldsymbol \theta(\textbf x)$的大值對應于高概率,小值對應于低概率。
## Logistic 功能[?](#The-Logistic-Function)
為了實現這一點,我們引入了**邏輯函數**,通常稱為**乙狀結腸函數**:
$$ \begin{aligned} \sigma(t) = \frac{1}{1 + e^{-t}} \end{aligned} $$
為了便于閱讀,我們經常將$E^X$替換為$\text exp(x)$并寫下:
$$ \begin{aligned} \sigma (t) = \frac{1}{1 + \text{exp}(-t)} \end{aligned} $$
我們為下面的值$t\in[-10,10]$繪制 sigmoid 函數。
```
# HIDDEN
from scipy.special import expit
xs = np.linspace(-10, 10, 100)
ys = expit(xs)
plt.plot(xs, ys)
plt.title(r'Sigmoid Function')
plt.xlabel('$ t $')
plt.ylabel(r'$ \sigma(t) $');
```
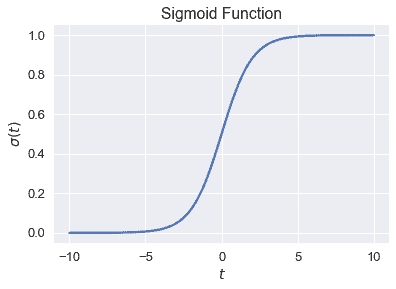
觀察 sigmoid 函數$\sigma(t)$接受任何實數$\mathbb r,只輸出 0 到 1 之間的數字。函數在其輸入$t$上單調遞增;根據需要,$t$的大值對應于接近 1 的值。這不是巧合,雖然我們省略了簡單性的推導,但 sigmoid 函數可以從概率的對數比中推導出來。
## Logistic 模型定義
我們現在可以將我們的線性模型$\hat \boldSymbol \theta \cdot\textbf x$作為 sigmoid 函數的輸入來創建**邏輯模型**:
$$ \begin{aligned} f_\hat{\boldsymbol{\theta}} (\textbf{x}) = \sigma(\hat{\boldsymbol{\theta}} \cdot \textbf{x}) \end{aligned} $$
換句話說,我們將線性回歸的輸出取為$\mathbb r 美元中的任意數字,并使用 sigmoid 函數將模型的最終輸出限制為介于 0 和 1 之間的有效概率。
為了對 Logistic 模型的行為產生一些直觀的認識,我們將$x$限制為一個標量,并將 Logistic 模型的輸出繪制為幾個值,即$hat \theta。
```
# HIDDEN
def flatten(li): return [item for sub in li for item in sub]
thetas = [-2, -1, -0.5, 2, 1, 0.5]
xs = np.linspace(-10, 10, 100)
fig, axes = plt.subplots(2, 3, sharex=True, sharey=True, figsize=(10, 6))
for ax, theta in zip(flatten(axes), thetas):
ys = expit(theta * xs)
ax.plot(xs, ys)
ax.set_title(r'$ \hat{\theta} = $' + str(theta))
# add a big axes, hide frame
fig.add_subplot(111, frameon=False)
# hide tick and tick label of the big axes
plt.tick_params(labelcolor='none', top='off', bottom='off',
left='off', right='off')
plt.grid(False)
plt.xlabel('$x$')
plt.ylabel(r'$ f_\hat{\theta}(x) $')
plt.tight_layout()
```
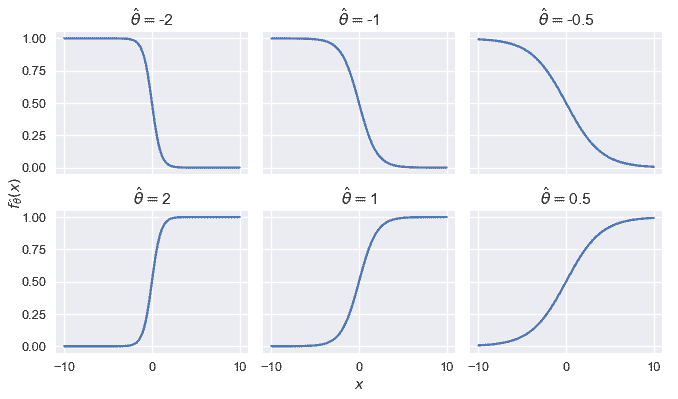
我們看到,改變\θ的幅度會改變曲線的銳度;距離 0$越遠,曲線的銳度就越高。翻轉$\hat \theta 的符號,同時保持大小不變,相當于反映 Y 軸上的曲線。
## 摘要[?](#Summary)
我們引入了邏輯模型,這是一個輸出概率的新預測函數。為了建立模型,我們使用線性回歸的輸出作為非線性邏輯函數的輸入。
- 一、數據科學的生命周期
- 二、數據生成
- 三、處理表格數據
- 四、數據清理
- 五、探索性數據分析
- 六、數據可視化
- Web 技術
- 超文本傳輸協議
- 處理文本
- python 字符串方法
- 正則表達式
- regex 和 python
- 關系數據庫和 SQL
- 關系模型
- SQL
- SQL 連接
- 建模與估計
- 模型
- 損失函數
- 絕對損失和 Huber 損失
- 梯度下降與數值優化
- 使用程序最小化損失
- 梯度下降
- 凸性
- 隨機梯度下降法
- 概率與泛化
- 隨機變量
- 期望和方差
- 風險
- 線性模型
- 預測小費金額
- 用梯度下降擬合線性模型
- 多元線性回歸
- 最小二乘-幾何透視
- 線性回歸案例研究
- 特征工程
- 沃爾瑪數據集
- 預測冰淇淋評級
- 偏方差權衡
- 風險和損失最小化
- 模型偏差和方差
- 交叉驗證
- 正規化
- 正則化直覺
- L2 正則化:嶺回歸
- L1 正則化:LASSO 回歸
- 分類
- 概率回歸
- Logistic 模型
- Logistic 模型的損失函數
- 使用邏輯回歸
- 經驗概率分布的近似
- 擬合 Logistic 模型
- 評估 Logistic 模型
- 多類分類
- 統計推斷
- 假設檢驗和置信區間
- 置換檢驗
- 線性回歸的自舉(真系數的推斷)
- 學生化自舉
- P-HACKING
- 向量空間回顧
- 參考表
- Pandas
- Seaborn
- Matplotlib
- Scikit Learn