
# 五、探索性數據分析
> 原文:[DS-100/textbook/notebooks/ch05](https://nbviewer.jupyter.org/github/DS-100/textbook/tree/master/notebooks/ch05/)
>
> 校驗:[飛龍](https://github.com/wizardforcel)
>
> 自豪地采用[谷歌翻譯](https://translate.google.cn/)
> 探索性數據分析是一種態度,一種靈活的狀態,一種尋找那些我們認為不存在和存在的東西的心愿。
>
> [John Tukey](https://en.wikipedia.org/wiki/John_Tukey)
在探索性數據分析(EDA),也就是數據科學生命周期的第三步中,我們總結,展示和轉換數據,以便更深入地理解它。 特別是,通過 EDA,我們發現數據中的潛在問題,并發現可用于進一步分析的趨勢。
我們試圖了解我們數據的以下屬性:
結構:我們數據文件的格式。
粒度:每行和每列的精細程度。
范圍:我們的數據有多么完整或不完整。
時間性:數據是不是當時的情況。
忠實度:數據捕捉“現實”有多好。
盡管我們分別介紹了數據清理和 EDA 來有助于組織本書,但在實踐中,你經常會在兩者之間切換。 例如,列的可視化可能會向你展示,應使用數據清理技術進行處理的格式錯誤的值。 考慮到這一點,我們回顧伯克利警察局的數據集來進行探索。
## 結構和連接
### 結構
數據集的結構指的是數據文件的“形狀”。 基本上,這指的是輸入數據的格式。例如,我們看到呼叫數據集是 CSV(逗號分隔值)文件:
```
!head data/Berkeley_PD_-_Calls_for_Service.csv
CASENO,OFFENSE,EVENTDT,EVENTTM,CVLEGEND,CVDOW,InDbDate,Block_Location,BLKADDR,City,State
17091420,BURGLARY AUTO,07/23/2017 12:00:00 AM,06:00,BURGLARY - VEHICLE,0,08/29/2017 08:28:05 AM,"2500 LE CONTE AVE
Berkeley, CA
(37.876965, -122.260544)",2500 LE CONTE AVE,Berkeley,CA
17020462,THEFT FROM PERSON,04/13/2017 12:00:00 AM,08:45,LARCENY,4,08/29/2017 08:28:00 AM,"2200 SHATTUCK AVE
Berkeley, CA
(37.869363, -122.268028)",2200 SHATTUCK AVE,Berkeley,CA
17050275,BURGLARY AUTO,08/24/2017 12:00:00 AM,18:30,BURGLARY - VEHICLE,4,08/29/2017 08:28:06 AM,"200 UNIVERSITY AVE
Berkeley, CA
(37.865491, -122.310065)",200 UNIVERSITY AVE,Berkeley,CA
```
另一方面,截停數據集是 JSON(JavaScript 對象表示法)文件。
```
# Show first and last 5 lines of file
!head -n 5 data/stops.json
!echo '...'
!tail -n 5 data/stops.json
{
"meta" : {
"view" : {
"id" : "6e9j-pj9p",
"name" : "Berkeley PD - Stop Data",
...
, [ 31079, "C2B606ED-7872-4B0B-BC9B-4EF45149F34B", 31079, 1496269085, "932858", 1496269085, "932858", null, "2017-00024245", "2017-04-30T22:59:26", " UNIVERSITY AVE/6TH ST", "T", "BM2TWN; ", null, null ]
, [ 31080, "8FADF18D-7FE9-441D-8709-7BFEABDACA7A", 31080, 1496269085, "932858", 1496269085, "932858", null, "2017-00024250", "2017-04-30T23:19:27", " UNIVERSITY AVE / WEST ST", "T", "HM4TCS; ", "37.8698757000001", "-122.286550846" ]
, [ 31081, "F60BD2A4-8C47-4BE7-B1C6-4934BE9DF838", 31081, 1496269085, "932858", 1496269085, "932858", null, "2017-00024254", "2017-04-30T23:38:34", " CHANNING WAY / BOWDITCH ST", "1194", "AR; ", "37.867207539", "-122.256529377" ]
]
}
```
當然,還有很多其他類型的數據格式。 以下是最常見格式的列表:
+ 逗號分隔值(CSV)和制表符分隔值(TSV)。 這些文件包含由逗號(CSV)或制表符(`\t`,TSV)分隔的表格數據。 這些文件通常很容易處理,因為數據的輸入格式與`DataFrame`類似。
+ JavaScript 對象表示法(JSON)。 這些文件包含嵌套字典格式的數據。 通常我們必須將整個文件讀為 Python 字典,然后弄清楚如何從字典中為`DataFrame`提取字段。
+ 可擴展標記語言(XML)或超文本標記語言(HTML)。 這些文件也包含嵌套格式的數據,例如:
```xml
<?xml version="1.0" encoding="UTF-8"?>
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note>
```
在后面的章節中,我們將使用 XPath 從這些類型的文件中提取數據。
+ 日志數據。許多應用在運行時會以非結構化文本格式輸出一些數據,例如:
```
2005-03-23 23:47:11,663 - sa - INFO - creating an instance of aux_module.Aux
2005-03-23 23:47:11,665 - sa.aux.Aux - INFO - creating an instance of Aux
2005-03-23 23:47:11,665 - sa - INFO - created an instance of aux_module.Aux
2005-03-23 23:47:11,668 - sa - INFO - calling aux_module.Aux.do_something
2005-03-23 23:47:11,668 - sa.aux.Aux - INFO - doing something
```
在后面的章節中,我們將使用正則表達式從這些類型的文件中提取數據。
### 連接(Join)
數據通常會分成多個表格。 例如,一張表可能描述一些人的個人信息,而另一張表可能包含他們的電子郵件:
```py
personal information while another will contain their emails:
people = pd.DataFrame(
[["Joey", "blue", 42, "M"],
["Weiwei", "blue", 50, "F"],
["Joey", "green", 8, "M"],
["Karina", "green", 7, "F"],
["Nhi", "blue", 3, "F"],
["Sam", "pink", -42, "M"]],
columns = ["Name", "Color", "Number", "Sex"])
people
```
| | Name | Color | Number | Sex |
| --- | --- | --- | --- | --- |
| 0 | Joey | blue | 42 | M |
| 1 | Weiwei | blue | 50 | F |
| 2 | Joey | green | 8 | M |
| 3 | Karina | green | 7 | F |
| 4 | Fernando | pink | -9 | M |
| 5 | Nhi | blue | 3 | F |
| 6 | Sam | pink | -42 | M |
```py
email = pd.DataFrame(
[["Deb", "deborah_nolan@berkeley.edu"],
["Sam", "samlau95@berkeley.edu"],
["John", "doe@nope.com"],
["Joey", "jegonzal@cs.berkeley.edu"],
["Weiwei", "weiwzhang@berkeley.edu"],
["Weiwei", "weiwzhang+123@berkeley.edu"],
["Karina", "kgoot@berkeley.edu"]],
columns = ["User Name", "Email"])
email
```
| | User Name | Email |
| --- | --- | --- |
| 0 | Deb | deborah_nolan@berkeley.edu |
| 1 | Sam | samlau95@berkeley.edu |
| 2 | John | doe@nope.com |
| 3 | Joey | jegonzal@cs.berkeley.edu |
| 4 | Weiwei | weiwzhang@berkeley.edu |
| 5 | Weiwei | weiwzhang+123@berkeley.edu |
| 6 | Karina | kgoot@berkeley.edu |
為了使每個人匹配他或她的電子郵件,我們可以在包含用戶名的列上連接兩個表。 然后,我們必須決定,如何處理出現在一張表上而沒有在另一張表上的人。 例如,`Fernando`出現在`people`表中,但不出現在`email`表中。 我們有幾種類型的連接,用于每個匹配缺失值的策略。 最常見的連接之一是內連接,其中任何不匹配的行都不放入最終結果中:
```py
# Fernando, Nhi, Deb, and John don't appear
people.merge(email, how='inner', left_on='Name', right_on='User Name')
```
| | Name | Color | Number | Sex | User Name | Email |
| --- | --- | --- | --- | --- | --- | --- |
| 0 | Joey | blue | 42 | M | Joey | jegonzal@cs.berkeley.edu |
| 1 | Joey | green | 8 | M | Joey | jegonzal@cs.berkeley.edu |
| 2 | Weiwei | blue | 50 | F | Weiwei | weiwzhang@berkeley.edu |
| 3 | Weiwei | blue | 50 | F | Weiwei | weiwzhang+123@berkeley.edu |
| 4 | Karina | green | 7 | F | Karina | kgoot@berkeley.edu |
| 5 | Sam | pink | -42 | M | Sam | samlau95@berkeley.edu |
這是我們經常使用的四個基本連接:內連接,全連接(有時稱為“外連接”),左連接和右連接。 以下是個圖表,展示了這些類型的連接之間的區別。
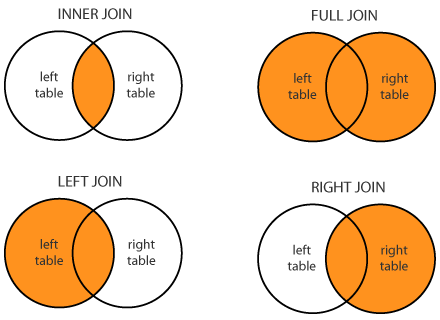
運行下面的代碼,并使用生成的下拉菜單,來展示`people`和`email `表格的四種不同的連接的結果。 注意對于外,左和右連接,哪些行包含了`NaN`值。
```py
# HIDDEN
def join_demo(join_type):
display(HTML('people and email tables:'))
display_two(people, email)
display(HTML('<br>'))
display(HTML('Joined table:'))
display(people.merge(email, how=join_type,
left_on='Name', right_on='User Name'))
interact(join_demo, join_type=['inner', 'outer', 'left', 'right']);
```
### 結構檢查清單
查看數據集的結構之后,你應該回答以下問題。我們將根據呼叫和截停數據集回答它們。
數據是標準格式還是編碼過的?
標準格式包括:
表格數據:CSV,TSV,Excel,SQL
嵌套數據:JSON,XML
呼叫數據集采用 CSV 格式,而截停數據集采用 JSON 格式。
數據是組織為記錄形式(例如行)的嗎?如果不是,我們可以通過解析數據來定義記錄嗎?
呼叫數據集按行出現;我們從截停數據集中提取記錄。
數據是否嵌套?如果是這樣,我們是否可以適當地提取非嵌套的數據?
呼叫數據集不是嵌套的;我們不必過于費力從截停數據集中獲取非嵌套的數據。
數據是否引用了其他數據?如果是這樣,我們可以連接數據嗎?
呼叫數據集引用了星期表。連接這兩張表讓我們知道數據集中每個事件的星期。截取數據集沒有明顯的引用。
每個記錄中的字段(例如,列)是什么?每列的類型是什么?
呼叫和截停數據集的字段,在每個數據集的“數據清理”一節中介紹。
## 粒度
數據的粒度是數據中每條記錄代表什么。 例如,在呼叫數據集中,每條記錄代表一次警務呼叫。
```py
# HIDDEN
calls = pd.read_csv('data/calls.csv')
calls.head()
```
| | CASENO | OFFENSE | CVLEGEND | BLKADDR | EVENTDTTM | Latitude | Longitude | Day |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | 17091420 | BURGLARY AUTO | BURGLARY - VEHICLE | 2500 LE CONTE AVE | 2017-07-23 06:00:00 | 37.876965 | -122.260544 | Sunday |
| 1 | 17038302 | BURGLARY AUTO | BURGLARY - VEHICLE | BOWDITCH STREET & CHANNING WAY | 2017-07-02 22:00:00 | 37.867209 | -122.256554 | Sunday |
| 2 | 17049346 | THEFT MISD. (UNDER $950) | LARCENY | 2900 CHANNING WAY | 2017-08-20 23:20:00 | 37.867948 | -122.250664 | Sunday |
| 3 | 17091319 | THEFT MISD. (UNDER $950) | LARCENY | 2100 RUSSELL ST | 2017-07-09 04:15:00 | 37.856719 | -122.266672 | Sunday |
| 4 | 17044238 | DISTURBANCE | DISORDERLY CONDUCT | TELEGRAPH AVENUE & DURANT AVE | 2017-07-30 01:16:00 | 37.867816 | -122.258994 | Sunday |
在截停數據集中,每條記錄代表一次警務截停事件。
```py
# HIDDEN
stops = pd.read_csv('data/stops.csv', parse_dates=[1], infer_datetime_format=True)
stops.head()
```
| | Incident Number | Call Date/Time | Location | Incident Type | Dispositions | Location - Latitude | Location - Longitude |
| --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | 2015-00004825 | 2015-01-26 00:10:00 | SAN PABLO AVE / MARIN AVE | T | M | NaN | NaN |
| 1 | 2015-00004829 | 2015-01-26 00:50:00 | SAN PABLO AVE / CHANNING WAY | T | M | NaN | NaN |
| 2 | 2015-00004831 | 2015-01-26 01:03:00 | UNIVERSITY AVE / NINTH ST | T | M | NaN | NaN |
| 3 | 2015-00004848 | 2015-01-26 07:16:00 | 2000 BLOCK BERKELEY WAY | 1194 | BM4ICN | NaN | NaN |
| 4 | 2015-00004849 | 2015-01-26 07:43:00 | 1700 BLOCK SAN PABLO AVE | 1194 | BM4ICN | NaN | NaN |
另一方面,我們可能以下列格式收到接受數據:
```py
# HIDDEN
(stops
.groupby(stops['Call Date/Time'].dt.date)
.size()
.rename('Num Incidents')
.to_frame()
)
```
| | Num Incidents |
| --- | --- |
| Call Date/Time | |
| 2015-01-26 | 46 |
| 2015-01-27 | 57 |
| 2015-01-28 | 56 |
| ... | ... |
| 2017-04-28 | 82 |
| 2017-04-29 | 86 |
| 2017-04-30 | 59 |
825 rows × 1 columns
在這種情況下,表格中的每個記錄對應于單個日期而不是單個事件。 我們會將此表描述為,它具有比上述更粗的粒度。 了解數據的粒度非常重要,因為它決定了你可以執行哪種分析。 一般來說,細粒度由于粗粒度;雖然我們可以使用分組和旋轉將細粒度變為粗粒度,但我們沒有幾個工具可以由粗到精。
### 粒度檢查清單
查看數據集的粒度后,你應該回答以下問題。我們將根據呼叫和截停數據集回答他們。
一條記錄代表了什么?
在呼叫數據集中,每條記錄代表一次警務呼叫。在截停數據集中,每條記錄代表一次警務截停事件。
所有記錄的粒度是否在同一級別? (有時一個表格將包含匯總行。)
是的,對于呼叫和截停數據集是如此。
如果數據是聚合的,聚合是如何進行的?采樣和平均是常見的聚合。
就有印象記住,在兩個數據集中,位置都是輸入為街區,而不是特定的地址。
我們可以對數據執行什么類型的聚合?
例如,隨著時間的推移,將個體聚合為人口統計分組,或個體事件聚合為總數。
在這種情況下,我們可以聚合為不同的日期或時間粒度。例如,我們可以使用聚合,找到事件最常見的一天的某個小時。我們也可能能夠按照事件地點聚合,來發現事件最多的伯克利地區。
## 范圍
數據集的范圍是指數據集的覆蓋面,與我們有興趣分析的東西相關。我們試圖回答我們數據范圍的以下問題:
數據是否涵蓋了感興趣的話題?
例如,呼叫和截停數據集包含在伯克利發生的呼叫和截停事件。然而,如果我們對加利福尼亞州的犯罪事件感興趣,那么這些數據集的范圍將會過于有限。
一般來說,較大的范圍比較小的范圍更有用,因為我們可以將較大的范圍過濾為較小的范圍,但通常不能從較小的范圍轉到較大的范圍。例如,如果我們有美國的警務截停數據集,我們可以取數據集的子集,來調查伯克利。
請記住,范圍是一個廣義術語,并不總是用于描述地理位置。例如,它也可以指時間覆蓋面 - 呼叫數據集僅包含 180 天的數據。
在調查數據生成的過程中,我們經常會處理數據集的范圍,并在 EDA 期間確認數據集的范圍。讓我們來確認呼叫數據集的地理和時間范圍。
```py
calls
```
| | CASENO | OFFENSE | CVLEGEND | BLKADDR | EVENTDTTM | Latitude | Longitude | Day |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | 17091420 | BURGLARY AUTO | BURGLARY - VEHICLE | 2500 LE CONTE AVE | 2017-07-23 06:00:00 | 37.876965 | -122.260544 | Sunday |
| 1 | 17038302 | BURGLARY AUTO | BURGLARY - VEHICLE | BOWDITCH STREET & CHANNING WAY | 2017-07-02 22:00:00 | 37.867209 | -122.256554 | Sunday |
| 2 | 17049346 | THEFT MISD. (UNDER $950) | LARCENY | 2900 CHANNING WAY | 2017-08-20 23:20:00 | 37.867948 | -122.250664 | Sunday |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 5505 | 17021604 | IDENTITY THEFT | FRAUD | 100 MONTROSE RD | 2017-03-31 00:00:00 | 37.896218 | -122.270671 | Friday |
| 5506 | 17033201 | DISTURBANCE | DISORDERLY CONDUCT | 2300 COLLEGE AVE | 2017-06-09 22:34:00 | 37.868957 | -122.254552 | Friday |
| 5507 | 17047247 | BURGLARY AUTO | BURGLARY - VEHICLE | UNIVERSITY AVENUE & CHESTNUT ST | 2017-08-11 20:00:00 | 37.869679 | -122.288038 | Friday |
5508 rows × 8 columns
```py
# Shows earliest and latest dates in calls
calls['EVENTDTTM'].dt.date.sort_values()
'''
1384 2017-03-02
1264 2017-03-02
1408 2017-03-02
...
3516 2017-08-28
3409 2017-08-28
3631 2017-08-28
Name: EVENTDTTM, Length: 5508, dtype: object
'''
```
```py
calls['EVENTDTTM'].dt.date.max() - calls['EVENTDTTM'].dt.date.min()
# datetime.timedelta(179)
```
該表格包含 179 天的時間段的數據,該時間段足夠接近數據描述中的 180 天,我們可以假設 2017 年 4 月 14 日或 2017 年 8 月 29 日沒有呼叫。
為了檢查地理范圍,我們可以使用地圖:
```py
import folium # Use the Folium Javascript Map Library
import folium.plugins
SF_COORDINATES = (37.87, -122.28)
sf_map = folium.Map(location=SF_COORDINATES, zoom_start=13)
locs = calls[['Latitude', 'Longitude']].astype('float').dropna().as_matrix()
heatmap = folium.plugins.HeatMap(locs.tolist(), radius = 10)
sf_map.add_child(heatmap)
```
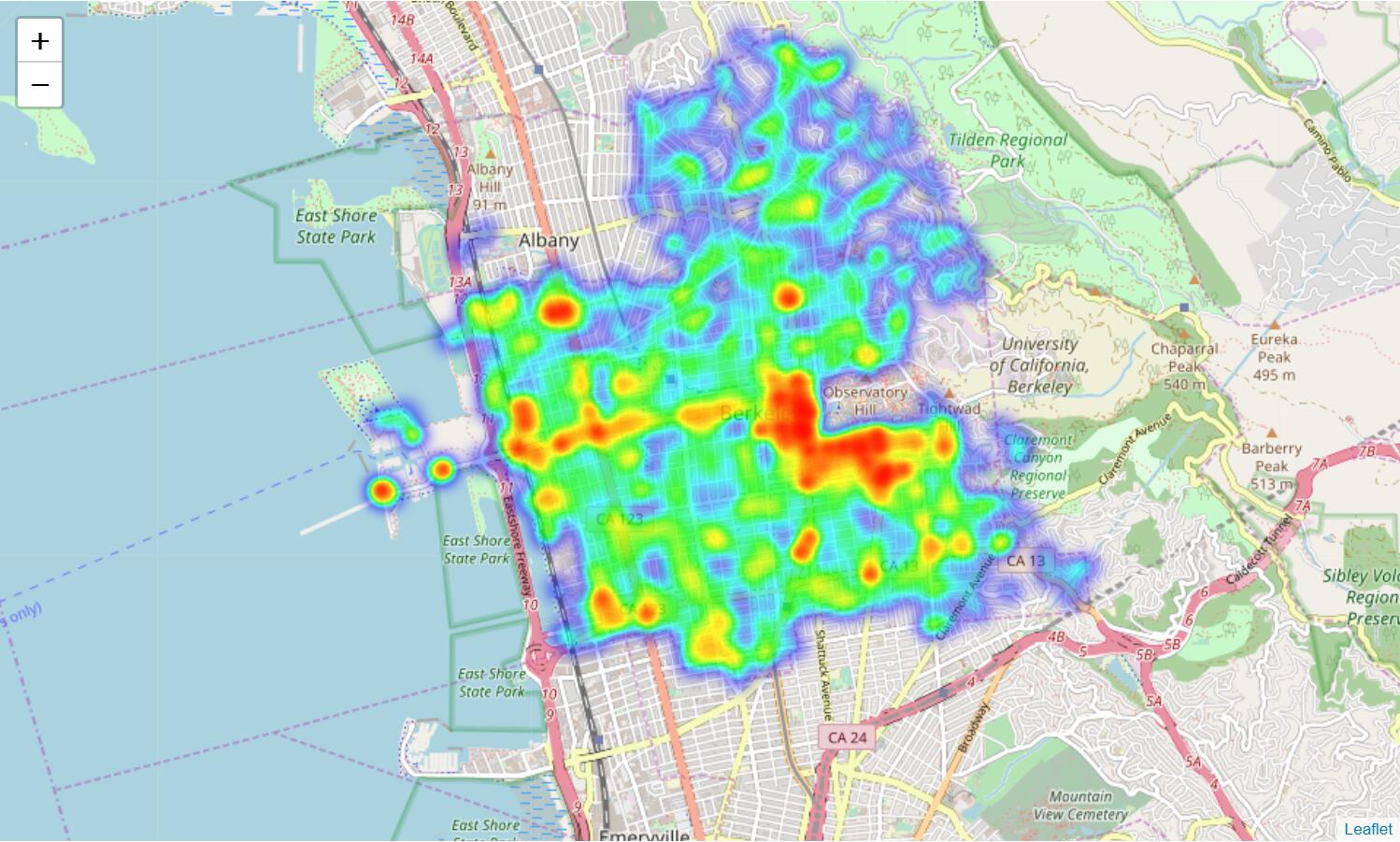
除少數例外情況外,呼叫數據集覆蓋了伯克利地區。 我們可以看到,大多數警務呼叫發生在伯克利市中心和 UCB 校區的南部。
現在我們來確認截停數據集的時間和地理范圍:
```py
stops
```
| | Incident Number | Call Date/Time | Location | Incident Type | Dispositions | Location - Latitude | Location - Longitude |
| --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | 2015-00004825 | 2015-01-26 00:10:00 | SAN PABLO AVE / MARIN AVE | T | M | NaN | NaN |
| 1 | 2015-00004829 | 2015-01-26 00:50:00 | SAN PABLO AVE / CHANNING WAY | T | M | NaN | NaN |
| 2 | 2015-00004831 | 2015-01-26 01:03:00 | UNIVERSITY AVE / NINTH ST | T | M | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 29205 | 2017-00024245 | 2017-04-30 22:59:26 | UNIVERSITY AVE/6TH ST | T | BM2TWN | NaN | NaN |
| 29206 | 2017-00024250 | 2017-04-30 23:19:27 | UNIVERSITY AVE / WEST ST | T | HM4TCS | 37.869876 | -122.286551 |
| 29207 | 2017-00024254 | 2017-04-30 23:38:34 | CHANNING WAY / BOWDITCH ST | 1194 | AR | 37.867208 | -122.256529 |
29208 rows × 7 columns
```py
stops['Call Date/Time'].dt.date.sort_values()
'''
0 2015-01-26
25 2015-01-26
26 2015-01-26
...
29175 2017-04-30
29177 2017-04-30
29207 2017-04-30
Name: Call Date/Time, Length: 29208, dtype: object
'''
```
如承諾的那樣,數據收集工作從 2015 年 1 月 26 日開始。因為它在 2017 年 4 月 30 日起停止,數據似乎在 2017 年 5 月初左右下載。讓我們繪制地圖來查看地理數據:
```py
SF_COORDINATES = (37.87, -122.28)
sf_map = folium.Map(location=SF_COORDINATES, zoom_start=13)
locs = stops[['Location - Latitude', 'Location - Longitude']].astype('float').dropna().as_matrix()
heatmap = folium.plugins.HeatMap(locs.tolist(), radius = 10)
sf_map.add_child(heatmap)
```
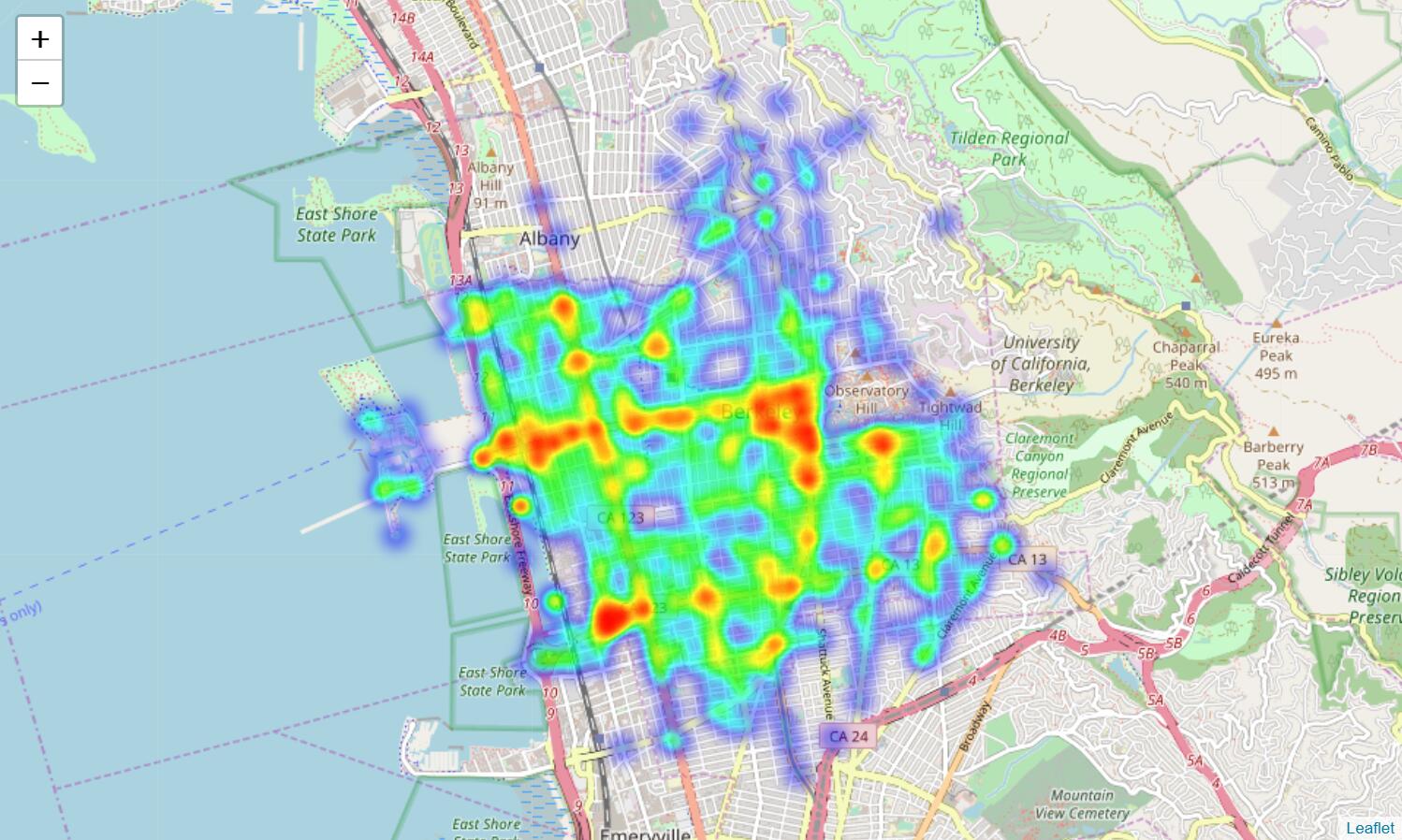
我們可以證實,數據集中在伯克利發生的警務截停,以及大多數警務呼叫,都發生在伯克利市中心和伯克利西部地區。
## 時間性
時間性是指數據在時間上如何表示,特別是數據集中的日期和時間字段。我們試圖通過這些字段來了解以下特征:
數據集中日期和時間字段的含義是什么?
在呼叫和截停數據集中,日期時間字段表示警務呼叫或截停的時間。然而,截停數據集最初還有一個日期時間字段,記錄案件什么時候輸入到數據庫,我們在數據清理過程中將其移除,因為我們認為它不適用于分析。
另外,我們應該注意日期時間字段的時區和夏令時,特別是在處理來自多個位置的數據的時候。
日期和時間字段在數據中有什么表示形式?
雖然美國使用`MM/DD/YYYY`格式,但許多其他國家使用`DD/MM/YYYY`格式。仍有更多格式在世界各地使用,分析數據時認識到這些差異非常重要。
在呼叫和截停數據集中,日期顯示為`MM/DD/YYYY`格式。
是否有奇怪的時間戳,它可能代表空值?
某些程序使用占位符而不是空值。例如,Excel 的默認日期是 1990 年 1 月 1 日,而 Mac 上的 Excel 則是 1904 年 1 月 1 日。許多應用將生成 1970 年 1 月 1 日 12:00 或 1969 年 12 月 31 日 11:59 pm 的默認日期時間,因為這是用于時間戳的 Unix 紀元。如果你在數據中注意到這些時間戳的多個實例,則應該謹慎并仔細檢查數據源。 呼叫或截停數據集都不包含任何這些可疑值。
## 忠實度
如果我們相信它能準確捕捉現實,我們將數據集描述為“忠實的”。通常,不可信的數據集包含:
不切實際或不正確的值
例如,未來的日期,不存在的位置,負數或較大離群值。
明顯違反的依賴關系
例如,個人的年齡和生日不匹配。
手動輸入的數據
我們看到,這些通常充滿了拼寫錯誤和不一致。
明顯的數據偽造跡象
例如,重復的名稱,偽造的電子郵件地址,或重復使用不常見的名稱或字段。
注意與數據清理的許多相似之處。 我們提到,我們經常在數據清理和 EDA 之間來回切換,特別是在確定數據忠實度的時候。 例如,可視化經常幫助我們識別數據中的奇怪條目。
```py
calls = pd.read_csv('data/calls.csv')
calls.head()
```
| | CASENO | OFFENSE | EVENTDT | EVENTTM | ... | BLKADDR | Latitude | Longitude | Day |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | 17091420 | BURGLARY AUTO | 07/23/2017 12:00:00 AM | 06:00 | ... | 2500 LE CONTE AVE | 37.876965 | -122.260544 | Sunday |
| 1 | 17038302 | BURGLARY AUTO | 07/02/2017 12:00:00 AM | 22:00 | ... | BOWDITCH STREET & CHANNING WAY | 37.867209 | -122.256554 | Sunday |
| 2 | 17049346 | THEFT MISD. (UNDER $950) | 08/20/2017 12:00:00 AM | 23:20 | ... | 2900 CHANNING WAY | 37.867948 | -122.250664 | Sunday |
| 3 | 17091319 | THEFT MISD. (UNDER $950) | 07/09/2017 12:00:00 AM | 04:15 | ... | 2100 RUSSELL ST | 37.856719 | -122.266672 | Sunday |
| 4 | 17044238 | DISTURBANCE | 07/30/2017 12:00:00 AM | 01:16 | ... | TELEGRAPH AVENUE & DURANT AVE | 37.867816 | -122.258994 | Sunday |
5 rows × 9 columns
```py
calls['CASENO'].plot.hist(bins=30)
# <matplotlib.axes._subplots.AxesSubplot at 0x1a1ebb2898>
```
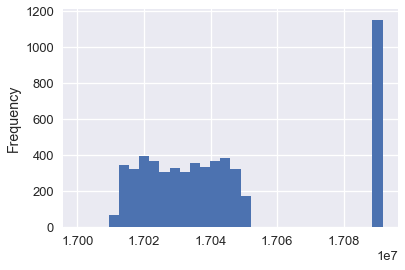
請注意`17030000`和`17090000`處的非預期的簇。通過繪制案例編號的分布,我們可以很快查看數據中的異常。 在這種情況下,我們可能會猜測,兩個不同的警察團隊為他們的呼叫使用不同的案件編號。
數據探索通常會發現異常情況;如果可以修復,我們可以使用數據清理技術。
- 一、數據科學的生命周期
- 二、數據生成
- 三、處理表格數據
- 四、數據清理
- 五、探索性數據分析
- 六、數據可視化
- Web 技術
- 超文本傳輸協議
- 處理文本
- python 字符串方法
- 正則表達式
- regex 和 python
- 關系數據庫和 SQL
- 關系模型
- SQL
- SQL 連接
- 建模與估計
- 模型
- 損失函數
- 絕對損失和 Huber 損失
- 梯度下降與數值優化
- 使用程序最小化損失
- 梯度下降
- 凸性
- 隨機梯度下降法
- 概率與泛化
- 隨機變量
- 期望和方差
- 風險
- 線性模型
- 預測小費金額
- 用梯度下降擬合線性模型
- 多元線性回歸
- 最小二乘-幾何透視
- 線性回歸案例研究
- 特征工程
- 沃爾瑪數據集
- 預測冰淇淋評級
- 偏方差權衡
- 風險和損失最小化
- 模型偏差和方差
- 交叉驗證
- 正規化
- 正則化直覺
- L2 正則化:嶺回歸
- L1 正則化:LASSO 回歸
- 分類
- 概率回歸
- Logistic 模型
- Logistic 模型的損失函數
- 使用邏輯回歸
- 經驗概率分布的近似
- 擬合 Logistic 模型
- 評估 Logistic 模型
- 多類分類
- 統計推斷
- 假設檢驗和置信區間
- 置換檢驗
- 線性回歸的自舉(真系數的推斷)
- 學生化自舉
- P-HACKING
- 向量空間回顧
- 參考表
- Pandas
- Seaborn
- Matplotlib
- Scikit Learn