
# 實現 deming 回歸
在這個秘籍中,我們將實現 deming 回歸,這意味著我們需要一種不同的方法來測量模型線和數據點之間的距離。
> 戴明回歸有幾個名字。它也稱為總回歸,正交距離回歸(ODR)和最短距離回歸。
## 做好準備
如果最小二乘線性回歸最小化到線的垂直距離,則 deming 回歸最小化到線的總距離。這種類型的回歸可以最小化`y`和`x`值的誤差。
請參閱下圖進行比較:
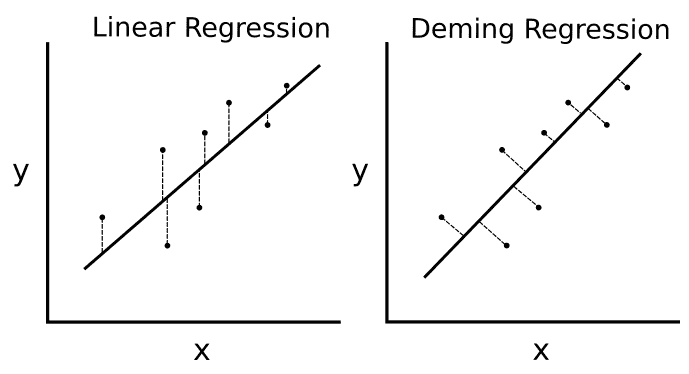
圖 8:常規線性回歸和 deming 回歸之間的差異;左邊的線性回歸最小化了到線的垂直距離,右邊的變形回歸最小化了到線的總距離
要實現 deming 回歸,我們必須修改損失函數。常規線性回歸中的損失函數使垂直距離最小化。在這里,我們希望最小化總距離。給定線的斜率和截距,到點的垂直距離是已知的幾何公式??。我們只需要替換此公式并告訴 TensorFlow 將其最小化。
## 操作步驟
我們按如下方式處理秘籍:
1. 代碼與之前的秘籍非常相似,除非我們進入損失函數。我們首先加載庫;開始一個會議;加載數據;聲明批量大小;并創建占位符,變量和模型輸出,如下所示:
```py
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from sklearn import datasets
sess = tf.Session()
iris = datasets.load_iris()
x_vals = np.array([x[3] for x in iris.data])
y_vals = np.array([y[0] for y in iris.data])
batch_size = 50
x_data = tf.placeholder(shape=[None, 1], dtype=tf.float32)
y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32)
A = tf.Variable(tf.random_normal(shape=[1,1]))
b = tf.Variable(tf.random_normal(shape=[1,1]))
model_output = tf.add(tf.matmul(x_data, A), b)
```
1. 損失函數是由分子和分母組成的幾何公式??。為清楚起見,我們將分別編寫這些內容。給定一條線`y = mx + b`和一個點`(x0, y0)`,兩者之間的垂直距離可以寫成如下:
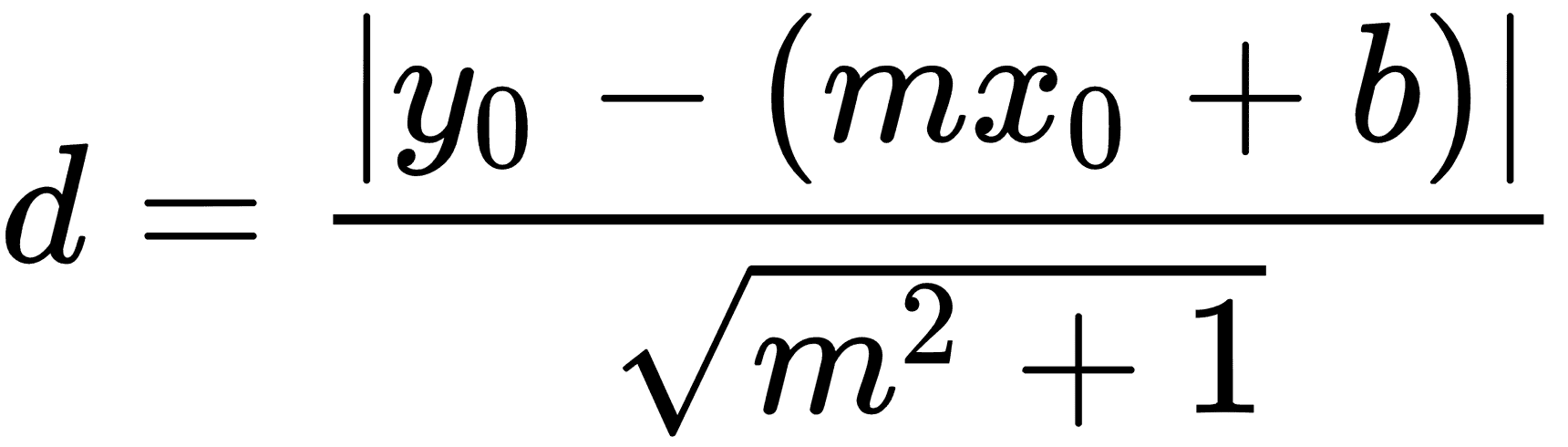
```py
deming_numerator = tf.abs(tf.sub(y_target, tf.add(tf.matmul(x_data, A), b)))
deming_denominator = tf.sqrt(tf.add(tf.square(A),1))
loss = tf.reduce_mean(tf.truediv(deming_numerator, deming_denominator))
```
1. 我們現在初始化變量,聲明我們的優化器,并循環遍歷訓練集以獲得我們的參數,如下所示:
```py
init = tf.global_variables_initializer()
sess.run(init)
my_opt = tf.train.GradientDescentOptimizer(0.1)
train_step = my_opt.minimize(loss)
loss_vec = []
for i in range(250):
rand_index = np.random.choice(len(x_vals), size=batch_size)
rand_x = np.transpose([x_vals[rand_index]])
rand_y = np.transpose([y_vals[rand_index]])
sess.run(train_step, feed_dict={x_data: rand_x, y_target: rand_y})
temp_loss = sess.run(loss, feed_dict={x_data: rand_x, y_target: rand_y})
loss_vec.append(temp_loss)
if (i+1)%50==0:
print('Step #' + str(i+1) + ' A = ' + str(sess.run(A)) + ' b = ' + str(sess.run(b)))
print('Loss = ' + str(temp_loss))
```
1. 我們可以使用以下代碼繪制輸出:
```py
[slope] = sess.run(A)
[y_intercept] = sess.run(b)
best_fit = []
for i in x_vals:
best_fit.append(slope*i+y_intercept)
plt.plot(x_vals, y_vals, 'o', label='Data Points')
plt.plot(x_vals, best_fit, 'r-', label='Best fit line', linewidth=3)
plt.legend(loc='upper left')
plt.title('Sepal Length vs petal Width')
plt.xlabel('petal Width')
plt.ylabel('Sepal Length')
plt.show()
```
我們得到上面代碼的以下圖:
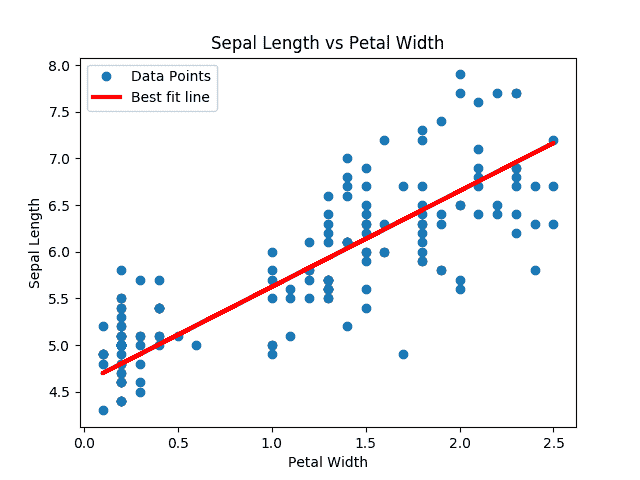
圖 9:對虹膜數據集進行 deming 回歸的解決方案
## 工作原理
deming 回歸的方法幾乎與常規線性回歸相同。關鍵的區別在于我們如何衡量預測和數據點之間的損失。而不是垂直損失,我們對`y`和`x`值有垂直損失(或總損失)。
> 當我們假設`x`和`y`值中的誤差相似時,使用這種類型的回歸。根據我們的假設,我們還可以根據誤差的差異在距離計算中縮放`x`和`y`軸。
- TensorFlow 入門
- 介紹
- TensorFlow 如何工作
- 聲明變量和張量
- 使用占位符和變量
- 使用矩陣
- 聲明操作符
- 實現激活函數
- 使用數據源
- 其他資源
- TensorFlow 的方式
- 介紹
- 計算圖中的操作
- 對嵌套操作分層
- 使用多個層
- 實現損失函數
- 實現反向傳播
- 使用批量和隨機訓練
- 把所有東西結合在一起
- 評估模型
- 線性回歸
- 介紹
- 使用矩陣逆方法
- 實現分解方法
- 學習 TensorFlow 線性回歸方法
- 理解線性回歸中的損失函數
- 實現 deming 回歸
- 實現套索和嶺回歸
- 實現彈性網絡回歸
- 實現邏輯回歸
- 支持向量機
- 介紹
- 使用線性 SVM
- 簡化為線性回歸
- 在 TensorFlow 中使用內核
- 實現非線性 SVM
- 實現多類 SVM
- 最近鄰方法
- 介紹
- 使用最近鄰
- 使用基于文本的距離
- 使用混合距離函數的計算
- 使用地址匹配的示例
- 使用最近鄰進行圖像識別
- 神經網絡
- 介紹
- 實現操作門
- 使用門和激活函數
- 實現單層神經網絡
- 實現不同的層
- 使用多層神經網絡
- 改進線性模型的預測
- 學習玩井字棋
- 自然語言處理
- 介紹
- 使用詞袋嵌入
- 實現 TF-IDF
- 使用 Skip-Gram 嵌入
- 使用 CBOW 嵌入
- 使用 word2vec 進行預測
- 使用 doc2vec 進行情緒分析
- 卷積神經網絡
- 介紹
- 實現簡單的 CNN
- 實現先進的 CNN
- 重新訓練現有的 CNN 模型
- 應用 StyleNet 和 NeuralStyle 項目
- 實現 DeepDream
- 循環神經網絡
- 介紹
- 為垃圾郵件預測實現 RNN
- 實現 LSTM 模型
- 堆疊多個 LSTM 層
- 創建序列到序列模型
- 訓練 Siamese RNN 相似性度量
- 將 TensorFlow 投入生產
- 介紹
- 實現單元測試
- 使用多個執行程序
- 并行化 TensorFlow
- 將 TensorFlow 投入生產
- 生產環境 TensorFlow 的一個例子
- 使用 TensorFlow 服務
- 更多 TensorFlow
- 介紹
- 可視化 TensorBoard 中的圖
- 使用遺傳算法
- 使用 k 均值聚類
- 求解常微分方程組
- 使用隨機森林
- 使用 TensorFlow 和 Keras