
# 介紹
SVM 是二分類的方法。基本思想是在兩個類之間找到二維的線性分離線(或更多維度的超平面)。我們首先假設二進制類目標是-1 或 1,而不是先前的 0 或 1 目標。由于可能有許多行分隔兩個類,我們定義最佳線性分隔符,以最大化兩個類之間的距離:
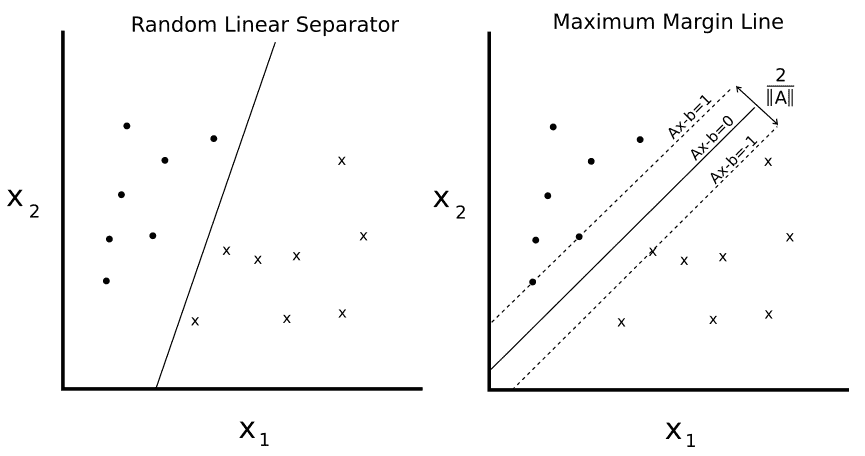
圖 1
給定兩個可分類`o`和`x`,我們希望找到兩者之間的線性分離器的等式。左側繪圖顯示有許多行將兩個類分開。右側繪圖顯示了唯一的最大邊際線。邊距寬度由`2 / ||A||`給出。通過最小化`A`的 L2 范數找到該線。
我們可以編寫如下超平面:
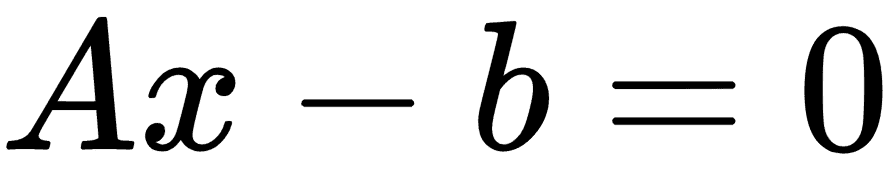
這里,`A`是我們部分斜率的向量,`x`是輸入向量。最大邊距的寬度可以顯示為 2 除以`A`的 L2 范數。這個事實有許多證明,但是對于幾何思想,求解從 2D 點到直線的垂直距離可以提供前進的動力。
對于線性可分的二進制類數據,為了最大化余量,我們最小化`A`,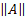的 L2 范數。我們還必須將此最小值置于以下約束條件下:
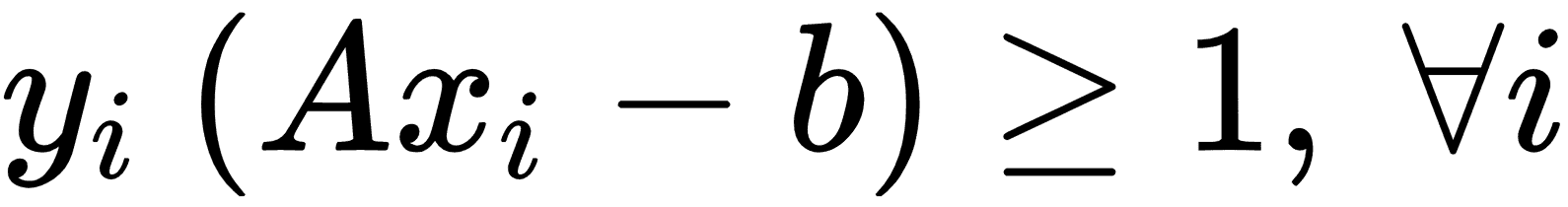
前面的約束確保我們來自相應類的所有點都在分離線的同一側。
由于并非所有數據集都是線性可分的,因此我們可以為跨越邊界線的點引入損失函數。對于`n`數據點,我們引入了所謂的軟邊際損失函數,如下所示:
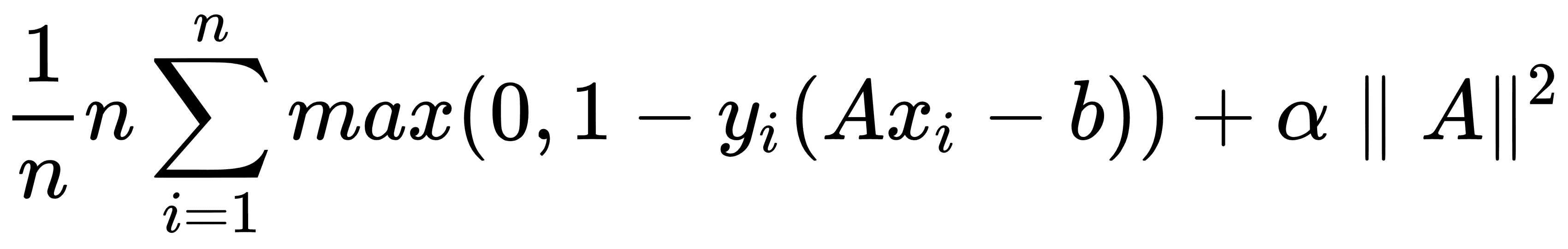
請注意,如果該點位于邊距的正確一側,則產品`y[i](Ax[i] - b)`始終大于 1。這使得損失函數的左手項等于 0,并且對損失函數的唯一影響是余量的大小。
前面的損失函數將尋找線性可分的線,但允許穿過邊緣線的點。根據`α`的值,這可以是硬度或軟度量。`α`的較大值導致更加強調邊距的擴大,而`α`的較小值導致模型更像是一個硬邊緣,同時允許數據點跨越邊距,如果需要的話。
在本章中,我們將建立一個軟邊界 SVM,并展示如何將其擴展到非線性情況和多個類。
- TensorFlow 入門
- 介紹
- TensorFlow 如何工作
- 聲明變量和張量
- 使用占位符和變量
- 使用矩陣
- 聲明操作符
- 實現激活函數
- 使用數據源
- 其他資源
- TensorFlow 的方式
- 介紹
- 計算圖中的操作
- 對嵌套操作分層
- 使用多個層
- 實現損失函數
- 實現反向傳播
- 使用批量和隨機訓練
- 把所有東西結合在一起
- 評估模型
- 線性回歸
- 介紹
- 使用矩陣逆方法
- 實現分解方法
- 學習 TensorFlow 線性回歸方法
- 理解線性回歸中的損失函數
- 實現 deming 回歸
- 實現套索和嶺回歸
- 實現彈性網絡回歸
- 實現邏輯回歸
- 支持向量機
- 介紹
- 使用線性 SVM
- 簡化為線性回歸
- 在 TensorFlow 中使用內核
- 實現非線性 SVM
- 實現多類 SVM
- 最近鄰方法
- 介紹
- 使用最近鄰
- 使用基于文本的距離
- 使用混合距離函數的計算
- 使用地址匹配的示例
- 使用最近鄰進行圖像識別
- 神經網絡
- 介紹
- 實現操作門
- 使用門和激活函數
- 實現單層神經網絡
- 實現不同的層
- 使用多層神經網絡
- 改進線性模型的預測
- 學習玩井字棋
- 自然語言處理
- 介紹
- 使用詞袋嵌入
- 實現 TF-IDF
- 使用 Skip-Gram 嵌入
- 使用 CBOW 嵌入
- 使用 word2vec 進行預測
- 使用 doc2vec 進行情緒分析
- 卷積神經網絡
- 介紹
- 實現簡單的 CNN
- 實現先進的 CNN
- 重新訓練現有的 CNN 模型
- 應用 StyleNet 和 NeuralStyle 項目
- 實現 DeepDream
- 循環神經網絡
- 介紹
- 為垃圾郵件預測實現 RNN
- 實現 LSTM 模型
- 堆疊多個 LSTM 層
- 創建序列到序列模型
- 訓練 Siamese RNN 相似性度量
- 將 TensorFlow 投入生產
- 介紹
- 實現單元測試
- 使用多個執行程序
- 并行化 TensorFlow
- 將 TensorFlow 投入生產
- 生產環境 TensorFlow 的一個例子
- 使用 TensorFlow 服務
- 更多 TensorFlow
- 介紹
- 可視化 TensorBoard 中的圖
- 使用遺傳算法
- 使用 k 均值聚類
- 求解常微分方程組
- 使用隨機森林
- 使用 TensorFlow 和 Keras