
# 實現單層神經網絡
我們擁有實現對真實數據進行操作的神經網絡所需的所有工具,因此在本節中我們將創建一個神經網絡,其中一個層在`Iris`數據集上運行。
## 做好準備
在本節中,我們將實現一個具有一個隱藏層的神經網絡。重要的是要理解完全連接的神經網絡主要基于矩陣乘法。因此,重要的是數據和矩陣的尺寸正確排列。
由于這是一個回歸問題,我們將使用均方誤差作為損失函數。
## 操作步驟
我們按如下方式處理秘籍:
1. 要創建計算圖,我們首先加載以下必要的庫:
```py
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from sklearn import datasets
```
1. 現在我們將加載`Iris`數據并將長度存儲為目標值。然后我們將使用以下代碼啟動圖會話:
```py
iris = datasets.load_iris()
x_vals = np.array([x[0:3] for x in iris.data])
y_vals = np.array([x[3] for x in iris.data])
sess = tf.Session()
```
1. 由于數據集較小,我們需要設置種子以使結果可重現,如下所示:
```py
seed = 2
tf.set_random_seed(seed)
np.random.seed(seed)
```
1. 為了準備數據,我們將創建一個 80-20 訓練測試分割,并通過最小 - 最大縮放將 x 特征標準化為 0 到 1 之間,如下所示:
```py
train_indices = np.random.choice(len(x_vals), round(len(x_vals)*0.8), replace=False)
test_indices = np.array(list(set(range(len(x_vals))) - set(train_indices)))
x_vals_train = x_vals[train_indices]
x_vals_test = x_vals[test_indices]
y_vals_train = y_vals[train_indices]
y_vals_test = y_vals[test_indices]
def normalize_cols(m):
col_max = m.max(axis=0)
col_min = m.min(axis=0)
return (m-col_min) / (col_max - col_min)
x_vals_train = np.nan_to_num(normalize_cols(x_vals_train))
x_vals_test = np.nan_to_num(normalize_cols(x_vals_test))
```
1. 現在,我們將使用以下代碼聲明數據和目標的批量大小和占位符:
```py
batch_size = 50
x_data = tf.placeholder(shape=[None, 3], dtype=tf.float32)
y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32)
```
1. 重要的是要用適當的形狀聲明我們的模型變量。我們可以將隱藏層的大小聲明為我們希望的任何大小;在下面的代碼塊中,我們將其設置為有五個隱藏節點:
```py
hidden_layer_nodes = 5
A1 = tf.Variable(tf.random_normal(shape=[3,hidden_layer_nodes]))
b1 = tf.Variable(tf.random_normal(shape=[hidden_layer_nodes]))
A2 = tf.Variable(tf.random_normal(shape=[hidden_layer_nodes,1]))
b2 = tf.Variable(tf.random_normal(shape=[1]))
```
1. 我們現在分兩步宣布我們的模型。第一步是創建隱藏層輸出,第二步是創建模型的`final_output`,如下所示:
> 請注意,我們的模型從三個輸入特征到五個隱藏節點,最后到一個輸出值。
```py
hidden_output = tf.nn.relu(tf.add(tf.matmul(x_data, A1), b1))
final_output = tf.nn.relu(tf.add(tf.matmul(hidden_output, A2), b2))
```
1. 我們作為`loss`函數的均方誤差如下:
```py
loss = tf.reduce_mean(tf.square(y_target - final_output))
```
1. 現在我們將聲明我們的優化算法并使用以下代碼初始化我們的變量:
```py
my_opt = tf.train.GradientDescentOptimizer(0.005)
train_step = my_opt.minimize(loss)
init = tf.global_variables_initializer()
sess.run(init)
```
1. 接下來,我們循環我們的訓練迭代。我們還將初始化兩個列表,我們可以存儲我們的訓練和`test_loss`函數。在每個循環中,我們還希望從訓練數據中隨機選擇一個批量以適合模型,如下所示:
```py
# First we initialize the loss vectors for storage.
loss_vec = []
test_loss = []
for i in range(500):
# We select a random set of indices for the batch.
rand_index = np.random.choice(len(x_vals_train), size=batch_size)
# We then select the training values
rand_x = x_vals_train[rand_index]
rand_y = np.transpose([y_vals_train[rand_index]])
# Now we run the training step
sess.run(train_step, feed_dict={x_data: rand_x, y_target: rand_y})
# We save the training loss
temp_loss = sess.run(loss, feed_dict={x_data: rand_x, y_target: rand_y})
loss_vec.append(np.sqrt(temp_loss))
# Finally, we run the test-set loss and save it.
test_temp_loss = sess.run(loss, feed_dict={x_data: x_vals_test, y_target: np.transpose([y_vals_test])})
test_loss.append(np.sqrt(test_temp_loss))
if (i+1)%50==0:
print('Generation: ' + str(i+1) + '. Loss = ' + str(temp_loss))
```
1. 我們可以用`matplotlib`和以下代碼繪制損失:
```py
plt.plot(loss_vec, 'k-', label='Train Loss')
plt.plot(test_loss, 'r--', label='Test Loss')
plt.title('Loss (MSE) per Generation')
plt.xlabel('Generation')
plt.ylabel('Loss')
plt.legend(loc='upper right')
plt.show()
```
我們通過繪制下圖來繼續秘籍:
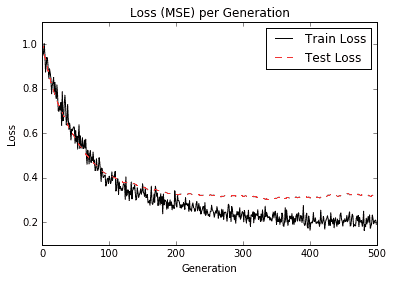
圖 4:我們繪制了訓練和測試裝置的損失(MSE)。請注意,我們在 200 代之后略微過擬合模型,因為測試 MSE 不會進一步下降,但訓練 MSE 確實
## 工作原理
我們的模型現已可視化為神經網絡圖,如下圖所示:
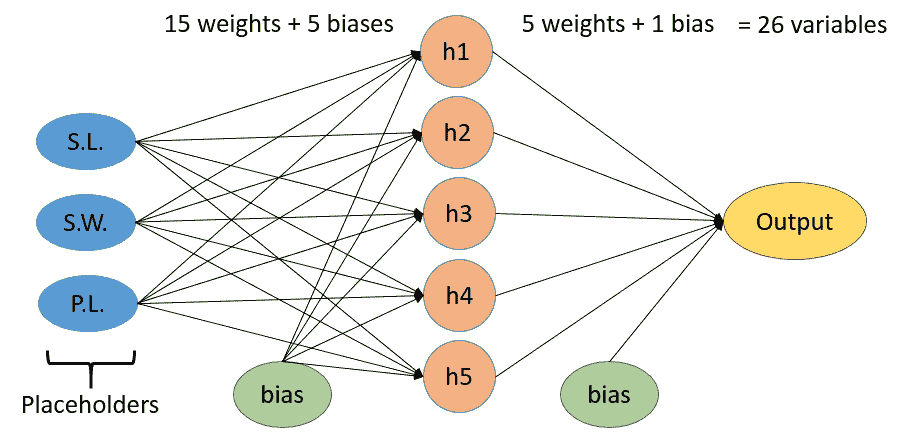
圖 5:上圖是我們的神經網絡的可視化,在隱藏層中有五個節點。我們喂養三個值:萼片長度(S.L),萼片寬度(S.W.)和花瓣長度(P.L.)。目標將是花瓣寬度。總的來說,模型中總共有 26 個變量
## 更多
請注意,通過查看測試和訓練集上的`loss`函數,我們可以確定模型何時開始過擬合訓練數據。我們還可以看到訓練損失并不像測試裝置那樣平穩。這是因為有兩個原因:第一個原因是我們使用的批量小于測試集,盡管不是很多;第二個原因是由于我們正在訓練訓練組,而測試裝置不會影響模型的變量。
- TensorFlow 入門
- 介紹
- TensorFlow 如何工作
- 聲明變量和張量
- 使用占位符和變量
- 使用矩陣
- 聲明操作符
- 實現激活函數
- 使用數據源
- 其他資源
- TensorFlow 的方式
- 介紹
- 計算圖中的操作
- 對嵌套操作分層
- 使用多個層
- 實現損失函數
- 實現反向傳播
- 使用批量和隨機訓練
- 把所有東西結合在一起
- 評估模型
- 線性回歸
- 介紹
- 使用矩陣逆方法
- 實現分解方法
- 學習 TensorFlow 線性回歸方法
- 理解線性回歸中的損失函數
- 實現 deming 回歸
- 實現套索和嶺回歸
- 實現彈性網絡回歸
- 實現邏輯回歸
- 支持向量機
- 介紹
- 使用線性 SVM
- 簡化為線性回歸
- 在 TensorFlow 中使用內核
- 實現非線性 SVM
- 實現多類 SVM
- 最近鄰方法
- 介紹
- 使用最近鄰
- 使用基于文本的距離
- 使用混合距離函數的計算
- 使用地址匹配的示例
- 使用最近鄰進行圖像識別
- 神經網絡
- 介紹
- 實現操作門
- 使用門和激活函數
- 實現單層神經網絡
- 實現不同的層
- 使用多層神經網絡
- 改進線性模型的預測
- 學習玩井字棋
- 自然語言處理
- 介紹
- 使用詞袋嵌入
- 實現 TF-IDF
- 使用 Skip-Gram 嵌入
- 使用 CBOW 嵌入
- 使用 word2vec 進行預測
- 使用 doc2vec 進行情緒分析
- 卷積神經網絡
- 介紹
- 實現簡單的 CNN
- 實現先進的 CNN
- 重新訓練現有的 CNN 模型
- 應用 StyleNet 和 NeuralStyle 項目
- 實現 DeepDream
- 循環神經網絡
- 介紹
- 為垃圾郵件預測實現 RNN
- 實現 LSTM 模型
- 堆疊多個 LSTM 層
- 創建序列到序列模型
- 訓練 Siamese RNN 相似性度量
- 將 TensorFlow 投入生產
- 介紹
- 實現單元測試
- 使用多個執行程序
- 并行化 TensorFlow
- 將 TensorFlow 投入生產
- 生產環境 TensorFlow 的一個例子
- 使用 TensorFlow 服務
- 更多 TensorFlow
- 介紹
- 可視化 TensorBoard 中的圖
- 使用遺傳算法
- 使用 k 均值聚類
- 求解常微分方程組
- 使用隨機森林
- 使用 TensorFlow 和 Keras