
# 實現先進的 CNN
能夠擴展 CNN 模型以進行圖像識別非常重要,這樣我們才能理解如何增加網絡的深度。如果我們有足夠的數據,這可能會提高我們預測的準確率。擴展 CNN 網絡的深度是以標準方式完成的:我們只是重復卷積,最大池和 ReLU,直到我們對深度感到滿意為止。許多更精確的圖像識別網絡以這種方式操作。
## 做好準備
在本文中,我們將實現一種更先進的讀取圖像數據的方法,并使用更大的 CNN 在 CIFAR10 數據集上進行圖像識別( [https://www.cs.toronto.edu/~kriz/cifar.html](https://www.cs.toronto.edu/~kriz/cifar.html) )。該數據集具有 60,000 個`32x32`圖像,這些圖像恰好屬于十個可能類別中的一個。圖像的潛在類別是飛機,汽車,鳥,貓,鹿,狗,青蛙,馬,船和卡車。另請參閱“另請參閱”部分中的第一個要點。
大多數圖像數據集太大而無法放入內存中。我們可以使用 TensorFlow 設置一個圖像管道,一次從一個文件中一次讀取。我們通過設置圖像閱讀器,然后創建在圖像閱讀器上運行的批量隊列來完成此操作。
此外,對于圖像識別數據,通常在將圖像發送之前隨機擾動圖像以進行訓練。在這里,我們將隨機裁剪,翻轉和更改亮度。
此秘籍是官方 TensorFlow CIFAR-10 教程的改編版本,可在本章末尾的“另請參閱”部分中找到。我們將教程濃縮為一個腳本,我們將逐行完成并解釋所有必要的代碼。我們還將一些常量和參數恢復為原始引用的紙張值;我們將在適當的步驟中標記這一點。
## 操作步驟
執行以下步驟:
1. 首先,我們加載必要的庫并啟動圖會話:
```py
import os
import sys
import tarfile
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from six.moves import urllib
sess = tf.Session()
```
1. 現在我們將聲明一些模型參數。我們的批量大小為 128(用于訓練和測試)。我們將每 50 代輸出一次狀態,總共運行 20,000 代。每 500 代,我們將評估一批測試數據。然后我們將聲明一些圖像參數,高度和寬度,以及隨機裁剪圖像的大小。有三個通道(紅色,綠色和藍色),我們有十個不同的目標。然后我們將聲明我們將從隊列中存儲數據和圖像批次的位置:
```py
batch_size = 128
output_every = 50
generations = 20000
eval_every = 500
image_height = 32
image_width = 32
crop_height = 24
crop_width = 24
num_channels = 3
num_targets = 10
data_dir = 'temp'
extract_folder = 'cifar-10-batches-bin'
```
1. 建議您在我們向好的模型邁進時降低學習率,因此我們將以指數方式降低學習率:初始學習率將設置為 0.1,并且我們將以 250%的指數方式將其降低 10%代。確切的公式將由`0.1 · 0.9^(x / 250)`給出,其中`x`是當前世代號。默認情況下,此值會持續降低,但 TensorFlow 會接受僅更新學習率的階梯參數。這里我們設置一些參數供將來使用:
```py
learning_rate = 0.1
lr_decay = 0.9
num_gens_to_wait = 250\.
```
1. 現在我們將設置參數,以便我們可以讀取二進制 CIFAR-10 圖像:
```py
image_vec_length = image_height * image_width * num_channels
record_length = 1 + image_vec_length
```
1. 接下來,我們將設置數據目錄和 URL 以下載 CIFAR-10 圖像,如果我們還沒有它們:
```py
data_dir = 'temp'
if not os.path.exists(data_dir):
os.makedirs(data_dir)
cifar10_url = 'http://www.cs.toronto.edu/~kriz/cifar-10-binary.tar.gz'
data_file = os.path.join(data_dir, 'cifar-10-binary.tar.gz')
if not os.path.isfile(data_file):
# Download file
filepath, _ = urllib.request.urlretrieve(cifar10_url, data_file)
# Extract file
tarfile.open(filepath, 'r:gz').extractall(data_dir)
```
1. 我們將設置記錄閱讀器并使用以下`read_cifar_files()`函數返回隨機失真的圖像。首先,我們需要聲明一個讀取固定字節長度的記錄讀取器對象。在我們讀取圖像隊列之后,我們將圖像和標簽分開。最后,我們將使用 TensorFlow 的內置圖像修改函數隨機扭曲圖像:
```py
def read_cifar_files(filename_queue, distort_images = True):
reader = tf.FixedLengthRecordReader(record_bytes=record_length)
key, record_string = reader.read(filename_queue)
record_bytes = tf.decode_raw(record_string, tf.uint8)
# Extract label
image_label = tf.cast(tf.slice(record_bytes, [0], [1]), tf.int32)
# Extract image
image_extracted = tf.reshape(tf.slice(record_bytes, [1], [image_vec_length]), [num_channels, image_height, image_width])
# Reshape image
image_uint8image = tf.transpose(image_extracted, [1, 2, 0])
reshaped_image = tf.cast(image_uint8image, tf.float32)
# Randomly Crop image
final_image = tf.image.resize_image_with_crop_or_pad(reshaped_image, crop_width, crop_height)
if distort_images:
# Randomly flip the image horizontally, change the brightness and contrast
final_image = tf.image.random_flip_left_right(final_image)
final_image = tf.image.random_brightness(final_image,max_delta=63)
final_image = tf.image.random_contrast(final_image,lower=0.2, upper=1.8)
# Normalize whitening
final_image = tf.image.per_image_standardization(final_image)
return final_image, image_label
```
1. 現在我們將聲明一個函數,它將填充我們的圖像管道以供批量器使用。我們首先需要設置一個我們想要讀取的圖像文件列表,并定義如何使用通過預構建的 TensorFlow 函數創建的輸入生成器對象來讀取它們。輸入生成器可以傳遞給我們在上一步中創建的讀取函數:`read_cifar_files()`。然后我們將在隊列中設置批量閱讀器:`shuffle_batch()`:
```py
def input_pipeline(batch_size, train_logical=True):
if train_logical:
files = [os.path.join(data_dir, extract_folder, 'data_batch_{}.bin'.format(i)) for i in range(1,6)]
else:
files = [os.path.join(data_dir, extract_folder, 'test_batch.bin')]
filename_queue = tf.train.string_input_producer(files)
image, label = read_cifar_files(filename_queue)
min_after_dequeue = 1000
capacity = min_after_dequeue + 3 * batch_size
example_batch, label_batch = tf.train.shuffle_batch([image, label], batch_size, capacity, min_after_dequeue)
return example_batch, label_batch
```
> 正確設置`min_after_dequeue`很重要。此參數負責設置用于采樣的圖像緩沖區的最小大小。官方 TensorFlow 文檔建議將其設置為`(#threads + error margin)*batch_size`。請注意,將其設置為更大的大小會導致更均勻的混洗,因為它正在從隊列中的更大數據集進行混洗,但是在此過程中也將使用更多內存。
1. 接下來,我們可以聲明我們的模型函數。我們將使用的模型有兩個卷積層,后面是三個完全連接的層。為了使變量聲明更容易,我們首先聲明兩個變量函數。兩個卷積層將分別創建 64 個特征。第一個完全連接的層將第二個卷積層與 384 個隱藏節點連接起來。第二個完全連接的操作將這 384 個隱藏節點連接到 192 個隱藏節點。最后的隱藏層操作將 192 個節點連接到我們試圖預測的 10 個輸出類。請參閱以下`#`前面的內聯注釋:
```py
def cifar_cnn_model(input_images, batch_size, train_logical=True):
def truncated_normal_var(name, shape, dtype):
return tf.get_variable(name=name, shape=shape, dtype=dtype, initializer=tf.truncated_normal_initializer(stddev=0.05))
def zero_var(name, shape, dtype):
return tf.get_variable(name=name, shape=shape, dtype=dtype, initializer=tf.constant_initializer(0.0))
# First Convolutional Layer
with tf.variable_scope('conv1') as scope:
# Conv_kernel is 5x5 for all 3 colors and we will create 64 features
conv1_kernel = truncated_normal_var(name='conv_kernel1', shape=[5, 5, 3, 64], dtype=tf.float32)
# We convolve across the image with a stride size of 1
conv1 = tf.nn.conv2d(input_images, conv1_kernel, [1, 1, 1, 1], padding='SAME')
# Initialize and add the bias term
conv1_bias = zero_var(name='conv_bias1', shape=[64], dtype=tf.float32)
conv1_add_bias = tf.nn.bias_add(conv1, conv1_bias)
# ReLU element wise
relu_conv1 = tf.nn.relu(conv1_add_bias)
# Max Pooling
pool1 = tf.nn.max_pool(relu_conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],padding='SAME', name='pool_layer1')
# Local Response Normalization
norm1 = tf.nn.lrn(pool1, depth_radius=5, bias=2.0, alpha=1e-3, beta=0.75, name='norm1')
# Second Convolutional Layer
with tf.variable_scope('conv2') as scope:
# Conv kernel is 5x5, across all prior 64 features and we create 64 more features
conv2_kernel = truncated_normal_var(name='conv_kernel2', shape=[5, 5, 64, 64], dtype=tf.float32)
# Convolve filter across prior output with stride size of 1
conv2 = tf.nn.conv2d(norm1, conv2_kernel, [1, 1, 1, 1], padding='SAME')
# Initialize and add the bias
conv2_bias = zero_var(name='conv_bias2', shape=[64], dtype=tf.float32)
conv2_add_bias = tf.nn.bias_add(conv2, conv2_bias)
# ReLU element wise
relu_conv2 = tf.nn.relu(conv2_add_bias)
# Max Pooling
pool2 = tf.nn.max_pool(relu_conv2, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='SAME', name='pool_layer2')
# Local Response Normalization (parameters from paper)
norm2 = tf.nn.lrn(pool2, depth_radius=5, bias=2.0, alpha=1e-3, beta=0.75, name='norm2')
# Reshape output into a single matrix for multiplication for the fully connected layers
reshaped_output = tf.reshape(norm2, [batch_size, -1])
reshaped_dim = reshaped_output.get_shape()[1].value
# First Fully Connected Layer
with tf.variable_scope('full1') as scope:
# Fully connected layer will have 384 outputs.
full_weight1 = truncated_normal_var(name='full_mult1', shape=[reshaped_dim, 384], dtype=tf.float32)
full_bias1 = zero_var(name='full_bias1', shape=[384], dtype=tf.float32)
full_layer1 = tf.nn.relu(tf.add(tf.matmul(reshaped_output, full_weight1), full_bias1))
# Second Fully Connected Layer
with tf.variable_scope('full2') as scope:
# Second fully connected layer has 192 outputs.
full_weight2 = truncated_normal_var(name='full_mult2', shape=[384, 192], dtype=tf.float32)
full_bias2 = zero_var(name='full_bias2', shape=[192], dtype=tf.float32)
full_layer2 = tf.nn.relu(tf.add(tf.matmul(full_layer1, full_weight2), full_bias2))
# Final Fully Connected Layer -> 10 categories for output (num_targets)
with tf.variable_scope('full3') as scope:
# Final fully connected layer has 10 (num_targets) outputs.
full_weight3 = truncated_normal_var(name='full_mult3', shape=[192, num_targets], dtype=tf.float32)
full_bias3 = zero_var(name='full_bias3', shape=[num_targets], dtype=tf.float32)
final_output = tf.add(tf.matmul(full_layer2, full_weight3), full_bias3)
return final_output
```
> 我們的本地響應標準化參數取自本文,并在本文的“另請參見”部分中引用。
1. 現在我們將創建損失函數。我們將使用 softmax 函數,因為圖片只能占用一個類別,因此輸出應該是十個目標的概率分布:
```py
def cifar_loss(logits, targets):
# Get rid of extra dimensions and cast targets into integers
targets = tf.squeeze(tf.cast(targets, tf.int32))
# Calculate cross entropy from logits and targets
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=targets)
# Take the average loss across batch size
cross_entropy_mean = tf.reduce_mean(cross_entropy)
return cross_entropy_mean
```
1. 接下來,我們宣布我們的訓練步驟。學習率將以指數階躍函數降低:
```py
def train_step(loss_value, generation_num):
# Our learning rate is an exponential decay (stepped down)
model_learning_rate = tf.train.exponential_decay(learning_rate, generation_num, num_gens_to_wait, lr_decay, staircase=True)
# Create optimizer
my_optimizer = tf.train.GradientDescentOptimizer(model_learning_rate)
# Initialize train step
train_step = my_optimizer.minimize(loss_value)
return train_step
```
1. 我們還必須具有精確度函數,以計算一批圖像的準確率。我們將輸入 logits 和目標向量,并輸出平均精度。然后我們可以將它用于訓練和測試批次:
```py
def accuracy_of_batch(logits, targets):
# Make sure targets are integers and drop extra dimensions
targets = tf.squeeze(tf.cast(targets, tf.int32))
# Get predicted values by finding which logit is the greatest
batch_predictions = tf.cast(tf.argmax(logits, 1), tf.int32)
# Check if they are equal across the batch
predicted_correctly = tf.equal(batch_predictions, targets)
# Average the 1's and 0's (True's and False's) across the batch size
accuracy = tf.reduce_mean(tf.cast(predicted_correctly, tf.float32))
return accuracy
```
1. 現在我們有了一個圖像管道函數,我們可以初始化訓練圖像管道和測試圖像管道:
```py
images, targets = input_pipeline(batch_size, train_logical=True)
test_images, test_targets = input_pipeline(batch_size, train_logical=False)
```
1. 接下來,我們將初始化訓練輸出和測試輸出的模型。值得注意的是,我們必須在創建訓練模型后聲明`scope.reuse_variables()`,這樣,當我們為測試網絡聲明模型時,它將使用相同的模型參數:
```py
with tf.variable_scope('model_definition') as scope:
# Declare the training network model
model_output = cifar_cnn_model(images, batch_size)
# Use same variables within scope
scope.reuse_variables()
# Declare test model output
test_output = cifar_cnn_model(test_images, batch_size)
```
1. 我們現在可以初始化我們的損耗和測試精度函數。然后我們將聲明`generation`變量。此變量需要聲明為不可訓練,并傳遞給我們的訓練函數,該函數在學習率指數衰減計算中使用它:
```py
loss = cifar_loss(model_output, targets)
accuracy = accuracy_of_batch(test_output, test_targets)
generation_num = tf.Variable(0, trainable=False)
train_op = train_step(loss, generation_num)
```
1. 我們現在將初始化所有模型的變量,然后通過運行 TensorFlow 函數`start_queue_runners()`來啟動圖像管道。當我們開始訓練或測試模型輸出時,管道將輸入一批圖像來代替飼料字典:
```py
init = tf.global_variables_initializer()
sess.run(init)
tf.train.start_queue_runners(sess=sess)
```
1. 我們現在循環訓練我們的訓練,節省訓練損失和測試準確率:
```py
train_loss = []
test_accuracy = []
for i in range(generations):
_, loss_value = sess.run([train_op, loss])
if (i+1) % output_every == 0:
train_loss.append(loss_value)
output = 'Generation {}: Loss = {:.5f}'.format((i+1), loss_value)
print(output)
if (i+1) % eval_every == 0:
[temp_accuracy] = sess.run([accuracy])
test_accuracy.append(temp_accuracy)
acc_output = ' --- Test Accuracy= {:.2f}%.'.format(100\. * temp_accuracy)
print(acc_output)
```
1. 這導致以下輸出:
```py
...
Generation 19500: Loss = 0.04461
--- Test Accuracy = 80.47%.
Generation 19550: Loss = 0.01171
Generation 19600: Loss = 0.06911
Generation 19650: Loss = 0.08629
Generation 19700: Loss = 0.05296
Generation 19750: Loss = 0.03462
Generation 19800: Loss = 0.03182
Generation 19850: Loss = 0.07092
Generation 19900: Loss = 0.11342
Generation 19950: Loss = 0.08751
Generation 20000: Loss = 0.02228
--- Test Accuracy = 83.59%.
```
1. 最后,這里有一些`matplotlib`代碼將繪制在訓練過程中的損失和測試準確率:
```py
eval_indices = range(0, generations, eval_every)
output_indices = range(0, generations, output_every)
# Plot loss over time
plt.plot(output_indices, train_loss, 'k-')
plt.title('Softmax Loss per Generation')
plt.xlabel('Generation')
plt.ylabel('Softmax Loss')
plt.show()
# Plot accuracy over time
plt.plot(eval_indices, test_accuracy, 'k-')
plt.title('Test Accuracy')
plt.xlabel('Generation')
plt.ylabel('Accuracy')
plt.show()
```
我們得到以下秘籍的以下繪圖:
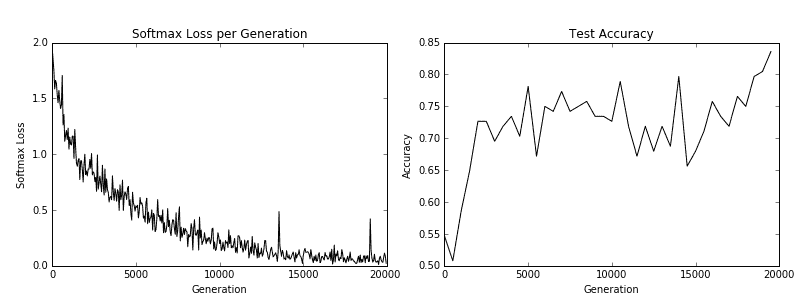
圖 5:訓練損失在左側,測試精度在右側。對于 CIFAR-10 圖像識別 CNN,我們能夠實現在測試集上達到約 75%準確率的模型
## 工作原理
在我們下載了 CIFAR-10 數據之后,我們建立了一個圖像管道而不是使用源字典。有關圖像管道的更多信息,請參閱官方 TensorFlow CIFAR-10 教程。我們使用此訓練和測試管道來嘗試預測圖像的正確類別。最后,該模型在測試集上達到了約 75%的準確率。
## 另見
* 有關 CIFAR-10 數據集的更多信息,請參閱學習 Tiny Images 的多個特征層,Alex Krizhevsky,2009: [https://www.cs.toronto.edu/~kriz/learning-features-2009- TR.pdf](https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf)
* 要查看原始的 TensorFlow 代碼,請參閱: [https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10](https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10)
* 有關局部響應歸一化的更多信息,請參閱使用深度卷積神經網絡的 ImageNet 分類,Krizhevsky,A。等。人。 2012: [http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks](http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks)
- TensorFlow 入門
- 介紹
- TensorFlow 如何工作
- 聲明變量和張量
- 使用占位符和變量
- 使用矩陣
- 聲明操作符
- 實現激活函數
- 使用數據源
- 其他資源
- TensorFlow 的方式
- 介紹
- 計算圖中的操作
- 對嵌套操作分層
- 使用多個層
- 實現損失函數
- 實現反向傳播
- 使用批量和隨機訓練
- 把所有東西結合在一起
- 評估模型
- 線性回歸
- 介紹
- 使用矩陣逆方法
- 實現分解方法
- 學習 TensorFlow 線性回歸方法
- 理解線性回歸中的損失函數
- 實現 deming 回歸
- 實現套索和嶺回歸
- 實現彈性網絡回歸
- 實現邏輯回歸
- 支持向量機
- 介紹
- 使用線性 SVM
- 簡化為線性回歸
- 在 TensorFlow 中使用內核
- 實現非線性 SVM
- 實現多類 SVM
- 最近鄰方法
- 介紹
- 使用最近鄰
- 使用基于文本的距離
- 使用混合距離函數的計算
- 使用地址匹配的示例
- 使用最近鄰進行圖像識別
- 神經網絡
- 介紹
- 實現操作門
- 使用門和激活函數
- 實現單層神經網絡
- 實現不同的層
- 使用多層神經網絡
- 改進線性模型的預測
- 學習玩井字棋
- 自然語言處理
- 介紹
- 使用詞袋嵌入
- 實現 TF-IDF
- 使用 Skip-Gram 嵌入
- 使用 CBOW 嵌入
- 使用 word2vec 進行預測
- 使用 doc2vec 進行情緒分析
- 卷積神經網絡
- 介紹
- 實現簡單的 CNN
- 實現先進的 CNN
- 重新訓練現有的 CNN 模型
- 應用 StyleNet 和 NeuralStyle 項目
- 實現 DeepDream
- 循環神經網絡
- 介紹
- 為垃圾郵件預測實現 RNN
- 實現 LSTM 模型
- 堆疊多個 LSTM 層
- 創建序列到序列模型
- 訓練 Siamese RNN 相似性度量
- 將 TensorFlow 投入生產
- 介紹
- 實現單元測試
- 使用多個執行程序
- 并行化 TensorFlow
- 將 TensorFlow 投入生產
- 生產環境 TensorFlow 的一個例子
- 使用 TensorFlow 服務
- 更多 TensorFlow
- 介紹
- 可視化 TensorBoard 中的圖
- 使用遺傳算法
- 使用 k 均值聚類
- 求解常微分方程組
- 使用隨機森林
- 使用 TensorFlow 和 Keras