
# 實現 TF-IDF
由于我們可以為每個單詞選擇嵌入,我們可能會決定更改某些單詞的加權。一種這樣的策略是增加有用的單詞和減輕過度常見或罕見單詞的權重。我們將在此秘籍中探索的嵌入是嘗試實現此目的。
## 做好準備
TF-IDF 是一個縮寫,代表文本頻率 - 反向文檔頻率。該術語基本上是每個單詞的文本頻率和反向文檔頻率的乘積。
在前面的秘籍中,我們介紹了詞袋方法,它為句子中每個單詞的出現賦值為 1。這可能并不理想,因為每個類別的句子(前一個秘籍中的垃圾郵件和火腿)很可能具有`the`,`and`和其他單詞的相同頻率,而諸如 V `iagra`和`sale`之類的單詞]可能應該更加重視查明文本是否是垃圾郵件。
首先,我們要考慮詞頻。在這里,我們考慮單個條目中單詞出現的頻率。這部分(TF)的目的是找到在每個條目中看起來很重要的術語。
但是`the`和`and`等詞可能會在每個條目中頻繁出現。我們希望減輕這些單詞的重要性,因此將前面的文本頻率(TF)乘以整個文檔頻率的倒數可能有助于找到重要的單詞。然而,由于文本集(語料庫)可能非常大,因此通常采用逆文檔頻率的對數。這為我們留下了每個文檔條目中每個單詞的 TF-IDF 的以下公式:
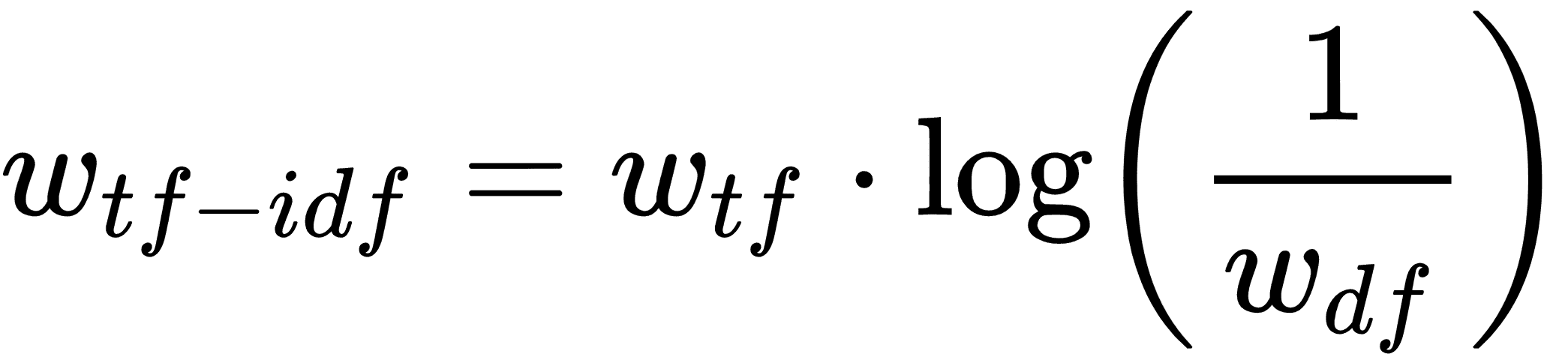
這里`w<sub>tf</sub>`是文檔中的單詞頻率,`w<sub>df</sub>` 是所有文檔中這些單詞的總頻率。有意義的是,TF-IDF 的高值可能表示在確定文檔內容時非常重要的單詞。
創建 TF-IDF 向量要求我們將所有文本加載到內存中,并在開始訓練模型之前計算每個單詞的出現次數。因此,它沒有在 TensorFlow 中完全實現,因此我們將使用 scikit-learn 來創建我們的 TF-IDF 嵌入,但是使用 TensorFlow 來適應邏輯模型。
## 操作步驟
我們將按如下方式處理秘籍:
1. 我們將從加載必要的庫開始。這次,我們正在為我們的文本加載 scikit-learn TF-IDF 預處理庫。使用以下代碼執行此操作:
```py
import tensorflow as tf
import matplotlib.pyplot as plt
import csv
import numpy as np
import os
import string
import requests
import io
import nltk
from zipfile import ZipFile
from sklearn.feature_extraction.text import TfidfVectorizer
```
1. 我們將開始一個圖會話,并為我們的詞匯表聲明我們的批量大小和最大特征尺寸:
```py
sess = tf.Session()
batch_size= 200
max_features = 1000
```
1. 接下來,我們將從 Web 或我們的`temp`數據文件夾中加載數據(如果我們之前已保存過)。使用以下代碼執行此操作:
```py
save_file_name = os.path.join('temp','temp_spam_data.csv')
if os.path.isfile(save_file_name):
text_data = []
with open(save_file_name, 'r') as temp_output_file:
reader = csv.reader(temp_output_file)
for row in reader:
text_data.append(row)
else:
zip_url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip'
r = requests.get(zip_url)
z = ZipFile(io.BytesIO(r.content))
file = z.read('SMSSpamCollection')
# Format Data
text_data = file.decode()
text_data = text_data.encode('ascii',errors='ignore')
text_data = text_data.decode().split('\n')
text_data = [x.split('\t') for x in text_data if len(x)>=1]
# And write to csv
with open(save_file_name, 'w') as temp_output_file:
writer = csv.writer(temp_output_file)
writer.writerows(text_data)
texts = [x[1] for x in text_data]
target = [x[0] for x in text_data]
# Relabel 'spam' as 1, 'ham' as 0
target = [1\. if x=='spam' else 0\. for x in target]
```
1. 就像前面的秘籍一樣,我們將通過將所有內容轉換為小寫,刪除標點符號并刪除數字來減少詞匯量:
```py
# Lower case
texts = [x.lower() for x in texts]
# Remove punctuation
texts = [''.join(c for c in x if c not in string.punctuation) for x in texts]
# Remove numbers
texts = [''.join(c for c in x if c not in '0123456789') for x in texts]
# Trim extra whitespace
texts = [' '.join(x.split()) for x in texts]
```
1. 為了使用 scikt-learn 的 TF-IDF 處理函數,我們必須告訴它如何標記我們的句子。通過這個,我們只是指如何將句子分解為相應的單詞。我們已經為我們構建了一個很好的標記器:`nltk`軟件包可以很好地將句子分解為相應的單詞:
```py
def tokenizer(text):
words = nltk.word_tokenize(text)
return words
# Create TF-IDF of texts
tfidf = TfidfVectorizer(tokenizer=tokenizer, stop_words='english', max_features=max_features)
sparse_tfidf_texts = tfidf.fit_transform(texts)
```
1. 接下來,我們將數據集分解為測試和訓練集。使用以下代碼執行此操作:
```py
train_indices = np.random.choice(sparse_tfidf_texts.shape[0], round(0.8*sparse_tfidf_texts.shape[0]), replace=False)
test_indices = np.array(list(set(range(sparse_tfidf_texts.shape[0])) - set(train_indices)))
texts_train = sparse_tfidf_texts[train_indices]
texts_test = sparse_tfidf_texts[test_indices]
target_train = np.array([x for ix, x in enumerate(target) if ix in train_indices])
target_test = np.array([x for ix, x in enumerate(target) if ix in test_indices])
```
1. 現在我們聲明我們的邏輯回歸模型變量和我們的數據占位符:
```py
A = tf.Variable(tf.random_normal(shape=[max_features,1]))
b = tf.Variable(tf.random_normal(shape=[1,1]))
# Initialize placeholders
x_data = tf.placeholder(shape=[None, max_features], dtype=tf.float32)
y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32)
```
1. 我們現在可以聲明模型操作和損失函數。請記住,邏輯回歸的 sigmoid 部分在我們的損失函數中。使用以下代碼執行此操作:
```py
model_output = tf.add(tf.matmul(x_data, A), b)
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=model_output, labels=y_target))
```
1. 我們將預測和精度函數添加到圖中,以便在我們的模型訓練時我們可以看到訓練和測試集的準確率:
```py
prediction = tf.round(tf.sigmoid(model_output))
predictions_correct = tf.cast(tf.equal(prediction, y_target), tf.float32)
accuracy = tf.reduce_mean(predictions_correct)
```
1. 然后我們將聲明一個優化器并初始化我們的圖變量:
```py
my_opt = tf.train.GradientDescentOptimizer(0.0025)
train_step = my_opt.minimize(loss)
# Intitialize Variables
init = tf.global_variables_initializer()
sess.run(init)
```
1. 我們現在將訓練我們的模型超過 10,000 代,并記錄每 100 代的測試/訓練損失和準確率,每 500 代打印一次。使用以下代碼執行此操作:
```py
train_loss = []
test_loss = []
train_acc = []
test_acc = []
i_data = []
for i in range(10000):
rand_index = np.random.choice(texts_train.shape[0], size=batch_size)
rand_x = texts_train[rand_index].todense()
rand_y = np.transpose([target_train[rand_index]])
sess.run(train_step, feed_dict={x_data: rand_x, y_target: rand_y})
# Only record loss and accuracy every 100 generations
if (i+1)%100==0:
i_data.append(i+1)
train_loss_temp = sess.run(loss, feed_dict={x_data: rand_x, y_target: rand_y})
train_loss.append(train_loss_temp)
test_loss_temp = sess.run(loss, feed_dict={x_data: texts_test.todense(), y_target: np.transpose([target_test])})
test_loss.append(test_loss_temp)
train_acc_temp = sess.run(accuracy, feed_dict={x_data: rand_x, y_target: rand_y})
train_acc.append(train_acc_temp)
test_acc_temp = sess.run(accuracy, feed_dict={x_data: texts_test.todense(), y_target: np.transpose([target_test])})
test_acc.append(test_acc_temp)
if (i+1)%500==0:
acc_and_loss = [i+1, train_loss_temp, test_loss_temp, train_acc_temp, test_acc_temp]
acc_and_loss = [np.round(x,2) for x in acc_and_loss]
print('Generation # {}. Train Loss (Test Loss): {:.2f} ({:.2f}). Train Acc (Test Acc): {:.2f} ({:.2f})'.format(*acc_and_loss))
```
1. 這導致以下輸出:
```py
Generation # 500\. Train Loss (Test Loss): 0.69 (0.73). Train Acc (Test Acc): 0.62 (0.57)
Generation # 1000\. Train Loss (Test Loss): 0.62 (0.63). Train Acc (Test Acc): 0.68 (0.66)
...
Generation # 9500\. Train Loss (Test Loss): 0.39 (0.45). Train Acc (Test Acc): 0.89 (0.85)
Generation # 10000\. Train Loss (Test Loss): 0.48 (0.45). Train Acc (Test Acc): 0.84 (0.85)
```
以下是繪制訓練和測試裝置的準確率和損耗的繪圖:
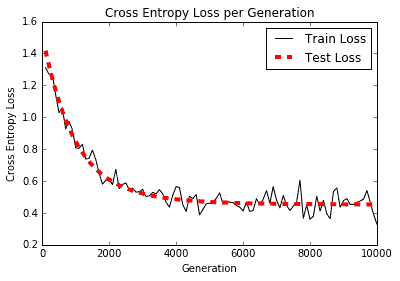
圖 2:根據 TF-IDF 值構建的物流垃圾郵件模型的交叉熵損失
訓練和測試精度圖如下:
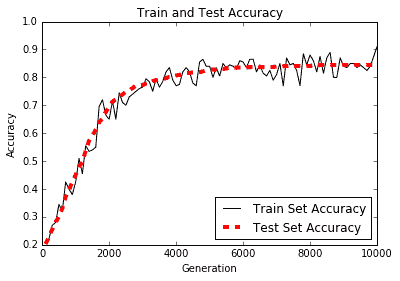
圖 3:根據 TF-IDF 值構建的邏輯垃圾郵件模型的訓練和測試集精度
## 工作原理
使用模型的 TF-IDF 值增加了我們對先前的詞袋模型的預測,從 80%的準確率到接近 90%的準確率。我們通過使用 scikit-learn 的 TF-IDF 詞匯處理函數并使用這些 TF-IDF 值進行邏輯回歸來實現這一目標。
## 更多
雖然我們可能已經解決了重要性這個問題,但我們還沒有解決字序問題。詞袋和 TF-IDF 都沒有考慮句子中的單詞的順序特征。我們將在接下來的幾節中嘗試解決這個問題,這將向我們介紹 word2vec 技術。
- TensorFlow 入門
- 介紹
- TensorFlow 如何工作
- 聲明變量和張量
- 使用占位符和變量
- 使用矩陣
- 聲明操作符
- 實現激活函數
- 使用數據源
- 其他資源
- TensorFlow 的方式
- 介紹
- 計算圖中的操作
- 對嵌套操作分層
- 使用多個層
- 實現損失函數
- 實現反向傳播
- 使用批量和隨機訓練
- 把所有東西結合在一起
- 評估模型
- 線性回歸
- 介紹
- 使用矩陣逆方法
- 實現分解方法
- 學習 TensorFlow 線性回歸方法
- 理解線性回歸中的損失函數
- 實現 deming 回歸
- 實現套索和嶺回歸
- 實現彈性網絡回歸
- 實現邏輯回歸
- 支持向量機
- 介紹
- 使用線性 SVM
- 簡化為線性回歸
- 在 TensorFlow 中使用內核
- 實現非線性 SVM
- 實現多類 SVM
- 最近鄰方法
- 介紹
- 使用最近鄰
- 使用基于文本的距離
- 使用混合距離函數的計算
- 使用地址匹配的示例
- 使用最近鄰進行圖像識別
- 神經網絡
- 介紹
- 實現操作門
- 使用門和激活函數
- 實現單層神經網絡
- 實現不同的層
- 使用多層神經網絡
- 改進線性模型的預測
- 學習玩井字棋
- 自然語言處理
- 介紹
- 使用詞袋嵌入
- 實現 TF-IDF
- 使用 Skip-Gram 嵌入
- 使用 CBOW 嵌入
- 使用 word2vec 進行預測
- 使用 doc2vec 進行情緒分析
- 卷積神經網絡
- 介紹
- 實現簡單的 CNN
- 實現先進的 CNN
- 重新訓練現有的 CNN 模型
- 應用 StyleNet 和 NeuralStyle 項目
- 實現 DeepDream
- 循環神經網絡
- 介紹
- 為垃圾郵件預測實現 RNN
- 實現 LSTM 模型
- 堆疊多個 LSTM 層
- 創建序列到序列模型
- 訓練 Siamese RNN 相似性度量
- 將 TensorFlow 投入生產
- 介紹
- 實現單元測試
- 使用多個執行程序
- 并行化 TensorFlow
- 將 TensorFlow 投入生產
- 生產環境 TensorFlow 的一個例子
- 使用 TensorFlow 服務
- 更多 TensorFlow
- 介紹
- 可視化 TensorBoard 中的圖
- 使用遺傳算法
- 使用 k 均值聚類
- 求解常微分方程組
- 使用隨機森林
- 使用 TensorFlow 和 Keras