
# 使用最近鄰
我們將通過實現最近鄰來預測住房價值來開始本章。這是從最近鄰居開始的好方法,因為我們將處理數字特征和連續目標。
## 做好準備
為了說明如何在 TensorFlow 中使用最近鄰居進行預測,我們將使用波士頓住房數據集。在這里,我們將預測鄰域住房價值中位數作為幾個特征的函數。
由于我們考慮訓練集訓練模型,我們將找到預測點的 k-NN,并將計算目標值的加權平均值。
## 操作步驟
我們按如下方式處理秘籍:
1. 我們將從加載所需的庫并開始圖會話開始。我們將使用`requests`模塊從 UCI 機器學習庫加載必要的波士頓住房數據:
```py
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import requests
sess = tf.Session()
```
1. 接下來,我們將使用`requests`模塊加載數據:
```py
housing_url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data'
housing_header = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
cols_used = ['CRIM', 'INDUS', 'NOX', 'RM', 'AGE', 'DIS', 'TAX', 'PTRATIO', 'B', 'LSTAT']
num_features = len(cols_used)
# Request data
housing_file = requests.get(housing_url)
# Parse Data
housing_data = [[float(x) for x in y.split(' ') if len(x)>=1] for y in housing_file.text.split('n') if len(y)>=1]
```
1. 接下來,我們將數據分為依賴和獨立的特征。我們將預測最后一個變量`MEDV`,這是房屋組的中值。我們也不會使用`ZN`,`CHAS`和`RAD`特征,因為它們沒有信息或二元性質:
```py
y_vals = np.transpose([np.array([y[13] for y in housing_data])])
x_vals = np.array([[x for i,x in enumerate(y) if housing_header[i] in cols_used] for y in housing_data])
x_vals = (x_vals - x_vals.min(0)) / x_vals.ptp(0)
```
1. 現在,我們將`x`和`y`值分成訓練和測試集。我們將通過隨機選擇大約 80%的行來創建訓練集,并將剩下的 20%留給測試集:
```py
train_indices = np.random.choice(len(x_vals), round(len(x_vals)*0.8), replace=False)
test_indices = np.array(list(set(range(len(x_vals))) - set(train_indices)))
x_vals_train = x_vals[train_indices]
x_vals_test = x_vals[test_indices]
y_vals_train = y_vals[train_indices]
y_vals_test = y_vals[test_indices]
```
1. 接下來,我們將聲明`k`值和批量大小:
```py
k = 4
batch_size=len(x_vals_test)
```
1. 我們接下來會申報占位符。請記住,沒有模型變量需要訓練,因為模型完全由我們的訓練集確定:
```py
x_data_train = tf.placeholder(shape=[None, num_features], dtype=tf.float32)
x_data_test = tf.placeholder(shape=[None, num_features], dtype=tf.float32)
y_target_train = tf.placeholder(shape=[None, 1], dtype=tf.float32)
y_target_test = tf.placeholder(shape=[None, 1], dtype=tf.float32)
```
1. 接下來,我們將為一批測試點創建距離函數。在這里,我們將說明 L1 距離的使用:
```py
distance = tf.reduce_sum(tf.abs(tf.subtract(x_data_train, tf.expand_dims(x_data_test,1))), reduction_indices=2)
```
> 注意,也可以使用 L2 距離函數。我們將距離公式改為`distance = tf.sqrt(tf.reduce_sum(tf.square(tf.subtract(x_data_train, tf.expand_dims(x_data_test,1))), reduction_indices=1))`。
1. 現在,我們將創建我們的預測函數。為此,我們將使用`top_k()`函數,該函數返回張量中最大值的值和索引。由于我們想要最小距離的指數,我們將找到`k` - 最大負距離。我們還將聲明目標值的預測和均方誤差(MSE):
```py
top_k_xvals, top_k_indices = tf.nn.top_k(tf.negative(distance), k=k)
x_sums = tf.expand_dims(tf.reduce_sum(top_k_xvals, 1),1)
x_sums_repeated = tf.matmul(x_sums,tf.ones([1, k], tf.float32))
x_val_weights = tf.expand_dims(tf.divide(top_k_xvals,x_sums_repeated), 1)
top_k_yvals = tf.gather(y_target_train, top_k_indices)
prediction = tf.squeeze(tf.batch_matmul(x_val_weights,top_k_yvals), squeeze_dims=[1])
mse = tf.divide(tf.reduce_sum(tf.square(tf.subtract(prediction, y_target_test))), batch_size)
```
1. 現在,我們將遍歷測試數據并存儲預測和準確率值:
```py
num_loops = int(np.ceil(len(x_vals_test)/batch_size))
for i in range(num_loops):
min_index = i*batch_size
max_index = min((i+1)*batch_size,len(x_vals_train))
x_batch = x_vals_test[min_index:max_index]
y_batch = y_vals_test[min_index:max_index]
predictions = sess.run(prediction, feed_dict={x_data_train: x_vals_train, x_data_test: x_batch, y_target_train: y_vals_train, y_target_test: y_batch})
batch_mse = sess.run(mse, feed_dict={x_data_train: x_vals_train, x_data_test: x_batch, y_target_train: y_vals_train, y_target_test: y_batch})
print('Batch #' + str(i+1) + ' MSE: ' + str(np.round(batch_mse,3)))
Batch #1 MSE: 23.153
```
1. 另外,我們可以查看實際目標值與預測值的直方圖。看待這一點的一個原因是要注意這樣一個事實:使用平均方法,我們無法預測目標的極端:
```py
bins = np.linspace(5, 50, 45)
plt.hist(predictions, bins, alpha=0.5, label='Prediction')
plt.hist(y_batch, bins, alpha=0.5, label='Actual')
plt.title('Histogram of Predicted and Actual Values')
plt.xlabel('Med Home Value in $1,000s')
plt.ylabel('Frequency')
plt.legend(loc='upper right')
plt.show()
```
然后我們將獲得直方圖,如下所示:
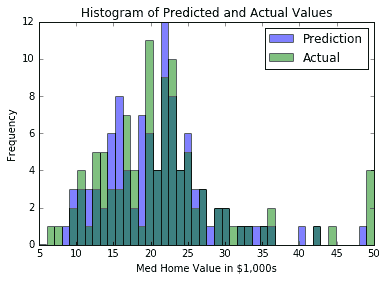
圖 1:k-NN 的預測值和實際目標值的直方圖(其中`k=4`)
一個難以確定的是`k`的最佳價值。對于上圖和預測,我們將`k=4`用于我們的模型。我們之所以選擇這個,是因為它給了我們最低的 MSE。這通過交叉驗證來驗證。如果我們在`k`的多個值上使用交叉驗證,我們將看到`k=4`給我們一個最小的 MSE。我們在下圖中說明了這一點。繪制預測值的方差也是值得的,以表明它會隨著我們平均的鄰居越多而減少:
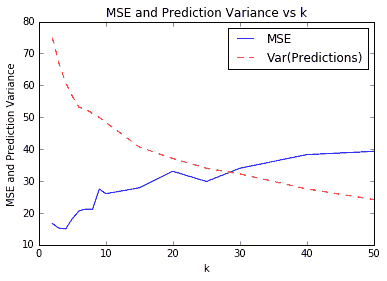
圖 2:各種`k`值的 k-NN 預測的 MSE。我們還繪制了測試集上預測值的方差。請注意,隨著`k`的增加,方差會減小。
## 工作原理
使用最近鄰算法,模型是訓練集。因此,我們不必在模型中訓練任何變量。唯一的參數`k`是通過交叉驗證確定的,以最大限度地減少我們的 MSE。
## 更多
對于 k-NN 的加權,我們選擇直接按距離加權。還有其他選擇我們也可以考慮。另一種常見方法是通過反平方距離加權。
- TensorFlow 入門
- 介紹
- TensorFlow 如何工作
- 聲明變量和張量
- 使用占位符和變量
- 使用矩陣
- 聲明操作符
- 實現激活函數
- 使用數據源
- 其他資源
- TensorFlow 的方式
- 介紹
- 計算圖中的操作
- 對嵌套操作分層
- 使用多個層
- 實現損失函數
- 實現反向傳播
- 使用批量和隨機訓練
- 把所有東西結合在一起
- 評估模型
- 線性回歸
- 介紹
- 使用矩陣逆方法
- 實現分解方法
- 學習 TensorFlow 線性回歸方法
- 理解線性回歸中的損失函數
- 實現 deming 回歸
- 實現套索和嶺回歸
- 實現彈性網絡回歸
- 實現邏輯回歸
- 支持向量機
- 介紹
- 使用線性 SVM
- 簡化為線性回歸
- 在 TensorFlow 中使用內核
- 實現非線性 SVM
- 實現多類 SVM
- 最近鄰方法
- 介紹
- 使用最近鄰
- 使用基于文本的距離
- 使用混合距離函數的計算
- 使用地址匹配的示例
- 使用最近鄰進行圖像識別
- 神經網絡
- 介紹
- 實現操作門
- 使用門和激活函數
- 實現單層神經網絡
- 實現不同的層
- 使用多層神經網絡
- 改進線性模型的預測
- 學習玩井字棋
- 自然語言處理
- 介紹
- 使用詞袋嵌入
- 實現 TF-IDF
- 使用 Skip-Gram 嵌入
- 使用 CBOW 嵌入
- 使用 word2vec 進行預測
- 使用 doc2vec 進行情緒分析
- 卷積神經網絡
- 介紹
- 實現簡單的 CNN
- 實現先進的 CNN
- 重新訓練現有的 CNN 模型
- 應用 StyleNet 和 NeuralStyle 項目
- 實現 DeepDream
- 循環神經網絡
- 介紹
- 為垃圾郵件預測實現 RNN
- 實現 LSTM 模型
- 堆疊多個 LSTM 層
- 創建序列到序列模型
- 訓練 Siamese RNN 相似性度量
- 將 TensorFlow 投入生產
- 介紹
- 實現單元測試
- 使用多個執行程序
- 并行化 TensorFlow
- 將 TensorFlow 投入生產
- 生產環境 TensorFlow 的一個例子
- 使用 TensorFlow 服務
- 更多 TensorFlow
- 介紹
- 可視化 TensorBoard 中的圖
- 使用遺傳算法
- 使用 k 均值聚類
- 求解常微分方程組
- 使用隨機森林
- 使用 TensorFlow 和 Keras