
# 使用 Pandas 快速和骯臟的數據分析
> 原文: [https://machinelearningmastery.com/quick-and-dirty-data-analysis-with-pandas/](https://machinelearningmastery.com/quick-and-dirty-data-analysis-with-pandas/)
在為建模選擇和準備數據之前,您需要了解您必須從哪開始。
如果您正在使用 Python 堆棧進行機器學習,那么可以用來更好地理解數據的庫是 Pandas。
在這篇文章中,您將發現一些快速而骯臟的 Pandas 秘籍,以提高您對數據結構,分布和關系的理解。
* **更新 March / 2018** :添加了備用鏈接以下載數據集,因為原始圖像已被刪除。
## 數據分析
[數據分析](http://machinelearningmastery.com/quick-and-dirty-data-analysis-for-your-machine-learning-problem/ "Quick and Dirty Data Analysis for your Machine Learning Problem")是關于詢問和回答有關您數據的問題。
作為機器學習從業者,您可能不熟悉您所在的領域。擁有主題專家是理想的,但這并不總是可行的。
當您使用標準機器學習數據集,咨詢或處理競爭數據集學習應用機器學習時,這些問題也適用。
您需要激發有關您可以追求的數據的問題。您需要更好地了解您擁有的數據。您可以通過匯總和可視化數據來實現。
### 熊貓
[Pandas Python 庫](http://machinelearningmastery.com/prepare-data-for-machine-learning-in-python-with-pandas/ "Prepare Data for Machine Learning in Python with Pandas")專為快速數據分析和操作而構建。如果您在其他平臺(如 R)上完成此任務,那么它既簡單又熟悉。
Pandas 的優勢似乎在數據處理方面,但它帶有非常方便易用的數據分析工具,為 [statsmodels](http://statsmodels.sourceforge.net/) 中的標準統計方法和 [matplotlib 中的圖形方法提供包裝器](http://matplotlib.org/)。
### 糖尿病的發病
我們需要一個小數據集,您可以使用它來探索使用 Pandas 的不同數據分析秘籍。
UIC 機器學習庫提供了大量不同的標準機器學習數據集,您可以使用它們來學習和實踐應用的機器學習。我最喜歡的是[皮馬印第安人糖尿病數據集](http://archive.ics.uci.edu/ml/datasets/Pima+Indians+Diabetes)。
該數據集使用其醫療記錄中的詳細信息描述了女性[皮馬印第安人](http://en.wikipedia.org/wiki/Pima_people)中糖尿病發病的發生或缺乏。 (更新:[從這里下載](https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv))。下載數據集并將其保存到當前工作目錄中,名稱為 _pima-indians-diabetes.data_ 。
## 總結數據
我們將從了解我們擁有的數據開始,通過查看它的結構。
### 加載數據
首先將 CSV 數據從文件作為數據幀加載到內存中。我們知道所提供數據的名稱,因此我們將在從文件加載數據時設置這些名稱。
Python
```
import pandas as pd
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = pd.read_csv('pima-indians-diabetes.data', names=names)
```
了解有關 [Pandas IO 功能](http://pandas.pydata.org/pandas-docs/stable/io.html)和 [read_csv 功能](http://pandas.pydata.org/pandas-docs/stable/io.html#io-read-csv-table)的更多信息。
### 描述數據
我們現在可以看一下數據的形狀。
我們可以通過直接打印數據框來查看前 60 行數據。
Python
```
print(data)
```
我們可以看到所有數據都是數字的,最后的類值是我們想要做出預測的因變量。
在數據轉儲結束時,我們可以看到數據框本身的描述為 768 行和 9 列。所以現在我們已經了解了數據的形狀。
接下來,我們可以通過查看摘要統計信息來了解每個屬性的分布情況。
Python
```
print(data.describe())
```
這將顯示數據框中每個屬性的詳細分布信息表。具體來說:計數,平均值,標準差,最小值,最大值,第 25 個,第 50 個(中位數),第 75 個百分點。
我們可以查看這些統計數據并開始注意有關我們問題的有趣事實。如平均懷孕次數為 3.8,最小年齡為 21 歲,有些人的體重指數為 0,這是不可能的,并且有跡象表明某些屬性值應標記為缺失。
了解有關 DataFrame 上[描述函數](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.describe.html)的更多信息。
## 可視化數據
圖表更能說明屬性的分布和關系。
然而,重要的是要花時間并首先審查統計數據。每當您以不同的方式查看數據時,您就會打開自己,注意到不同的方面,并可能對問題有不同的見解。
Pandas 使用 matplotlib 創建圖形并提供方便的功能。您可以[詳細了解 Pandas 中的數據可視化。](http://pandas.pydata.org/pandas-docs/stable/visualization.html)
### 特征分布
要審查的第一個簡單屬性是每個屬性的分布。
我們可以通過查看 box 和 whisker 圖來開始并查看每個屬性的傳播。
Python
```
import matplotlib.pyplot as plt
pd.options.display.mpl_style = 'default'
data.boxplot()
```
此片段將繪制圖形的樣式(通過 matplotlib)更改為默認樣式,該樣式看起來更好。
[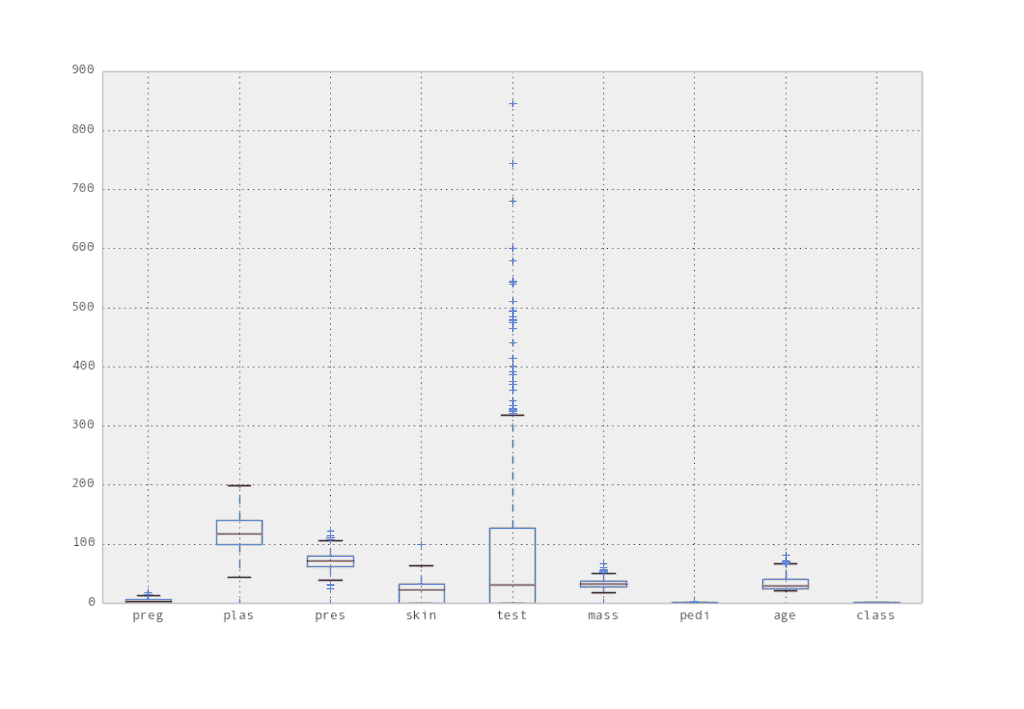](https://3qeqpr26caki16dnhd19sv6by6v-wpengine.netdna-ssl.com/wp-content/uploads/2014/06/boxplots.png)
屬性框和胡須圖
我們可以看到 test 屬性有很多異常值。我們還可以看到 plas 屬性似乎具有相對均勻的正態分布。我們還可以通過將值離散化為桶來查看每個屬性的分布,并將每個桶中的頻率作為直方圖進行檢查。
Python
```
data.hist()
```
這使您可以記錄屬性分布的有趣屬性,例如 pres 和 skin 等屬性的可能正態分布。
[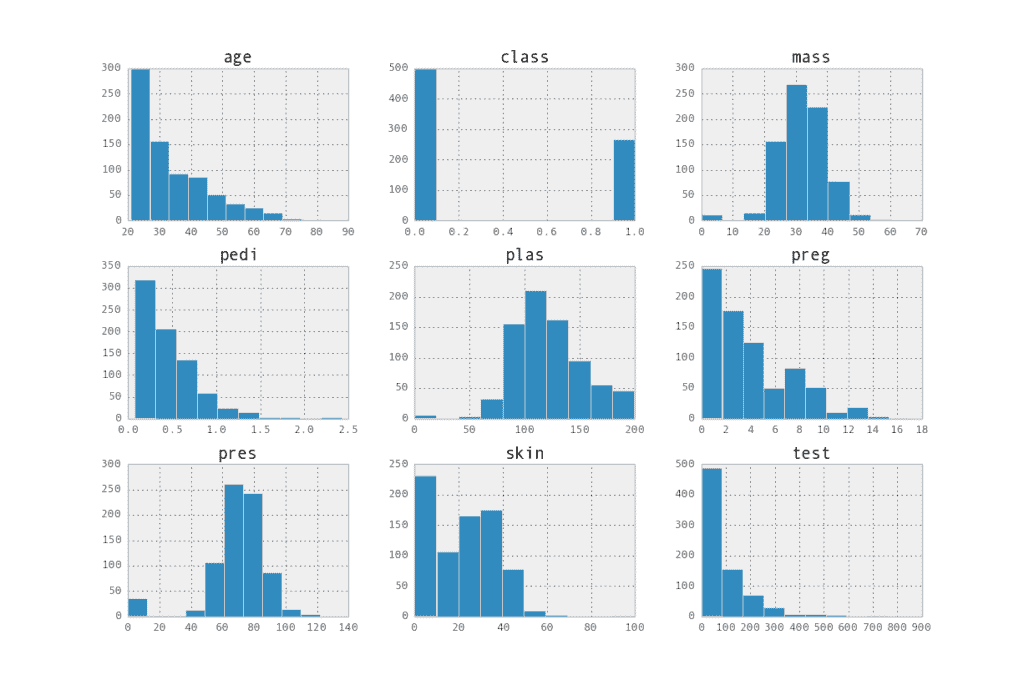](https://3qeqpr26caki16dnhd19sv6by6v-wpengine.netdna-ssl.com/wp-content/uploads/2014/06/histograms.png)
屬性直方圖矩陣
您可以在 DataFrame 上查看有關 [boxplot](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.boxplot.html#pandas.DataFrame.boxplot) 和 [hist 函數](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.hist.html#pandas.DataFrame.hist)的更多詳細信息
### 特征級關系
探索的下一個重要關系是 class 屬性的每個屬性。
一種方法是可視化每個類的數據實例的屬性分布以及注釋和差異。您可以為每個屬性生成直方圖矩陣,為每個類值生成一個直方圖矩陣,如下所示:
Python
```
data.groupby('class').hist()
```
數據按類屬性(兩組)分組,然后為每個組中的屬性創建直方圖矩陣。結果是兩個圖像。
[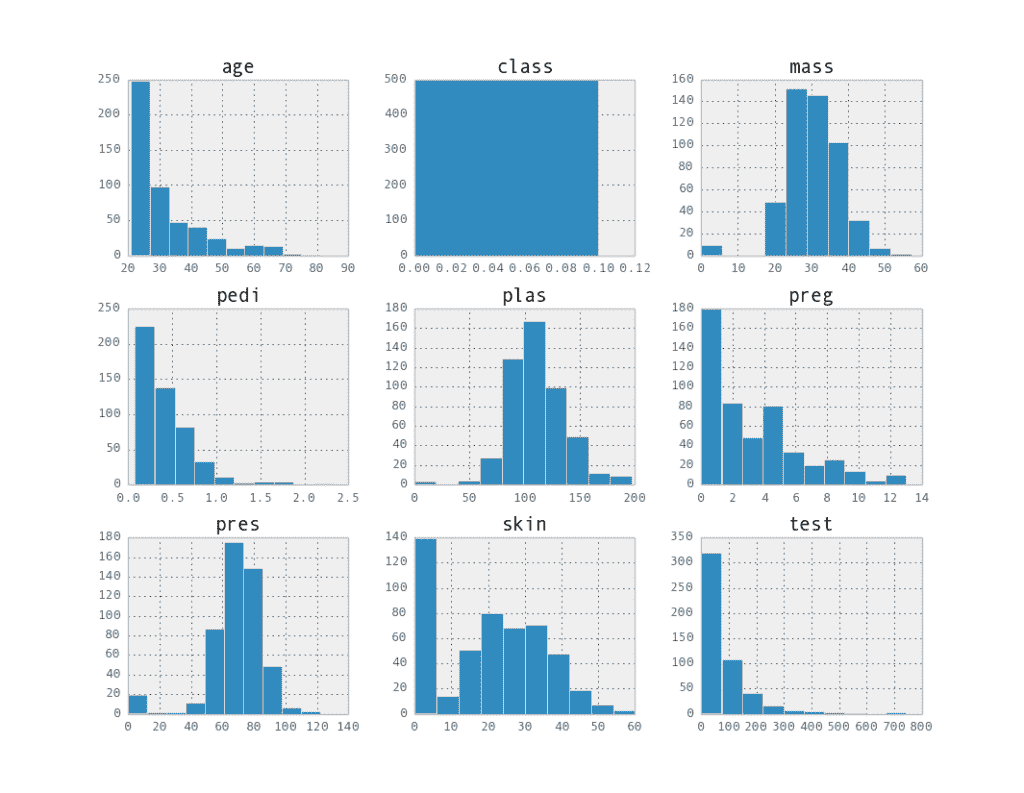](https://3qeqpr26caki16dnhd19sv6by6v-wpengine.netdna-ssl.com/wp-content/uploads/2014/06/histogram_class0.png)
0 類的屬性直方圖矩陣
[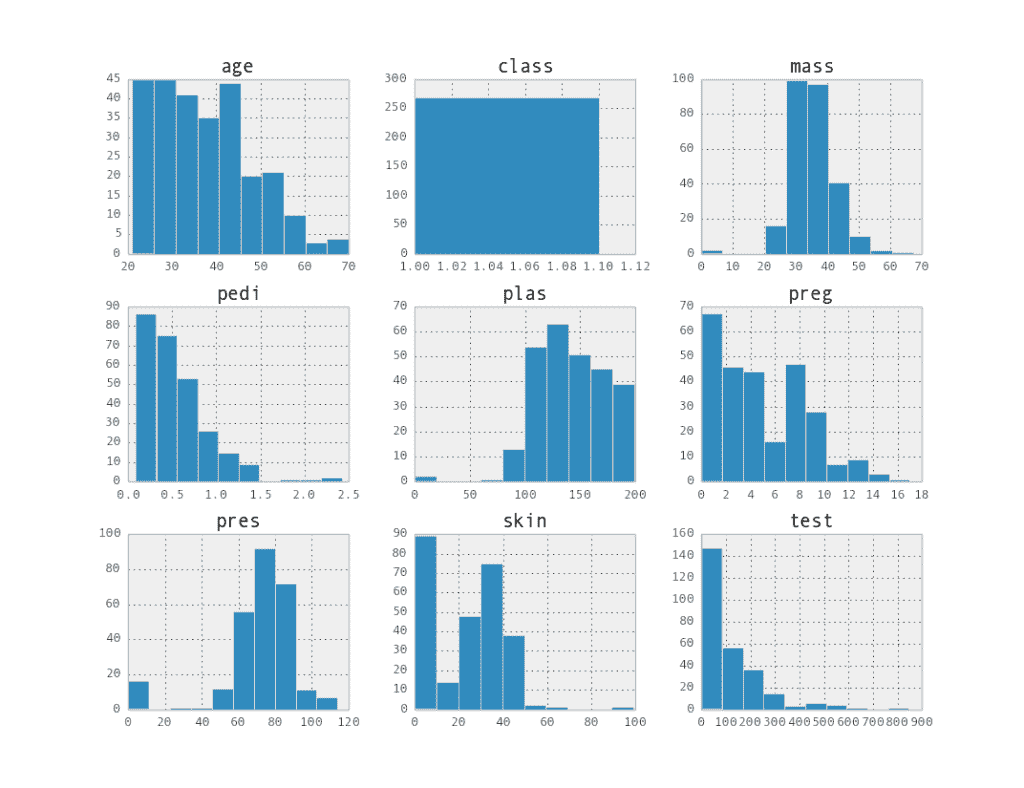](https://3qeqpr26caki16dnhd19sv6by6v-wpengine.netdna-ssl.com/wp-content/uploads/2014/06/histograpm_class1.png)
1 類屬性直方圖矩陣
這有助于指出類之間的分布差異,如 plas 屬性的分布。
您可以更好地對同一圖表中每個類的屬性值進行對比
```
data.groupby('class').plas.hist(alpha=0.4)
```
這將按類別對數據進行分組,僅繪制等離子體的直方圖,其中紅色的類值為 0,藍色的類值為 1。你可以看到一個類似形狀的正態分布,但是一個轉變。此屬性可能有助于區分類。
[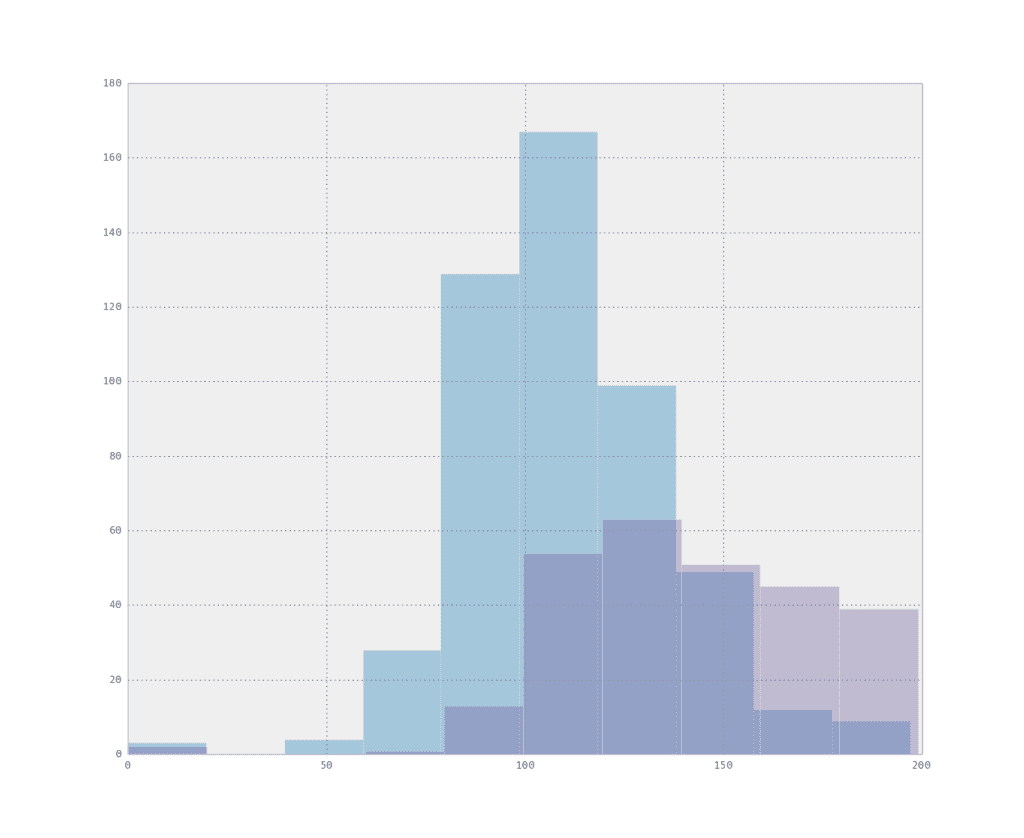](https://3qeqpr26caki16dnhd19sv6by6v-wpengine.netdna-ssl.com/wp-content/uploads/2014/06/histogram_overlapping.png)
每個類的重疊屬性直方圖
您可以在 DataFrame 上閱讀有關 [groupby 函數](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.groupby.html#pandas.DataFrame.groupby)的更多信息。
### 特征 - 特征關系
探索的最后一個重要關系是屬性之間的關系。
我們可以通過查看每對屬性的交互分布來查看屬性之間的關系。
Python
```
from pandas.plotting import scatter_matrix
scatter_matrix(data, alpha=0.2, figsize=(6, 6), diagonal='kde')
```
這使用構建函數來創建所有屬性與所有屬性的散點圖矩陣。每個屬性相對于自身繪制的對角線顯示了屬性的核密度估計。
[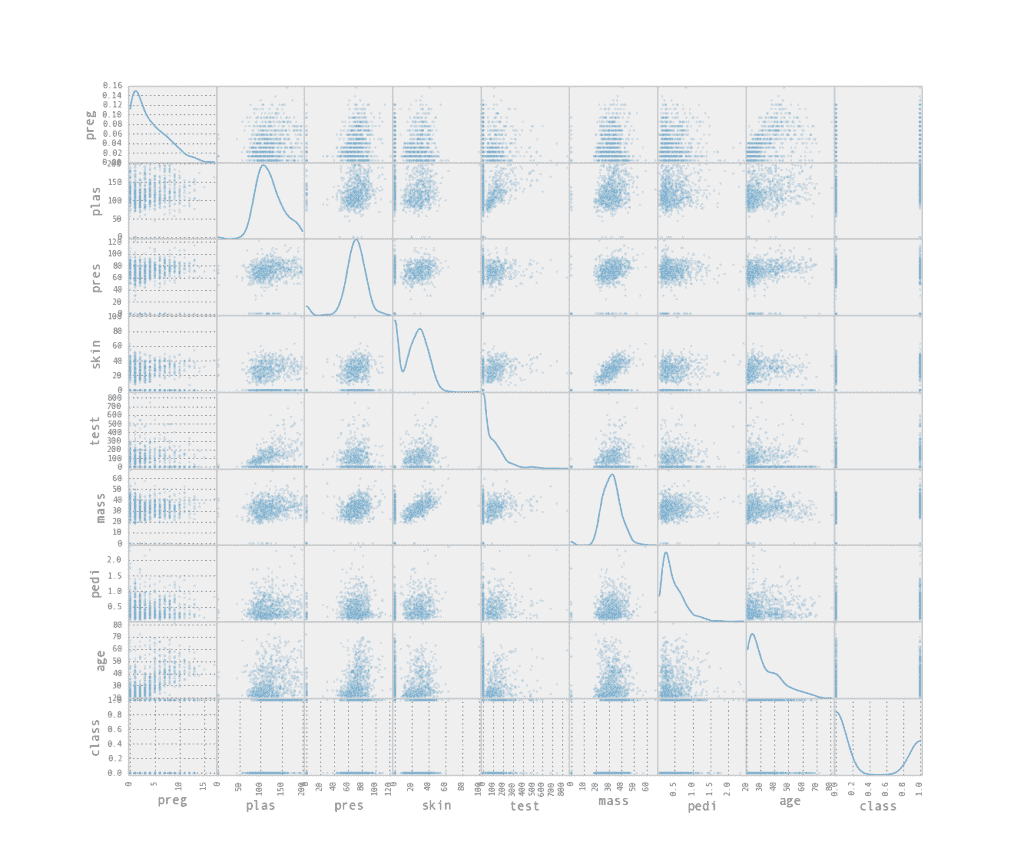](https://3qeqpr26caki16dnhd19sv6by6v-wpengine.netdna-ssl.com/wp-content/uploads/2014/06/scatterplots.png)
屬性散點圖矩陣
這是一個強大的情節,可以從中獲得關于數據的大量靈感。例如,我們可以看到年齡和 preg 之間可能的相關性以及皮膚和質量之間的另一種可能的關系。
## 摘要
我們在這篇文章中介紹了很多內容。
我們開始研究快速和臟的單行程序,以便以 CSV 格式加載我們的數據并使用匯總統計信息對其進行描述。
接下來,我們研究了繪制數據以揭示有趣結構的各種不同方法。我們查看了框中的數據分布以及晶須圖和直方圖,然后我們查看了與類屬性相比的屬性分布,最后查看了成對散點圖中屬性之間的關系。
- Machine Learning Mastery 應用機器學習教程
- 5競爭機器學習的好處
- 過度擬合的簡單直覺,或者為什么測試訓練數據是一個壞主意
- 特征選擇簡介
- 應用機器學習作為一個搜索問題的溫和介紹
- 為什么應用機器學習很難
- 為什么我的結果不如我想的那么好?你可能過度擬合了
- 用ROC曲線評估和比較分類器表現
- BigML評論:發現本機學習即服務平臺的聰明功能
- BigML教程:開發您的第一個決策樹并進行預測
- 構建生產機器學習基礎設施
- 分類準確性不夠:可以使用更多表現測量
- 一種預測模型的巧妙應用
- 機器學習項目中常見的陷阱
- 數據清理:將凌亂的數據轉換為整潔的數據
- 機器學習中的數據泄漏
- 數據,學習和建模
- 數據管理至關重要以及為什么需要認真對待它
- 將預測模型部署到生產中
- 參數和超參數之間有什么區別?
- 測試和驗證數據集之間有什么區別?
- 發現特征工程,如何設計特征以及如何獲得它
- 如何開始使用Kaggle
- 超越預測
- 如何在評估機器學習算法時選擇正確的測試選項
- 如何定義機器學習問題
- 如何評估機器學習算法
- 如何獲得基線結果及其重要性
- 如何充分利用機器學習數據
- 如何識別數據中的異常值
- 如何提高機器學習效果
- 如何在競爭機器學習中踢屁股
- 如何知道您的機器學習模型是否具有良好的表現
- 如何布局和管理您的機器學習項目
- 如何為機器學習準備數據
- 如何減少最終機器學習模型中的方差
- 如何使用機器學習結果
- 如何解決像數據科學家這樣的問題
- 通過數據預處理提高模型精度
- 處理機器學習的大數據文件的7種方法
- 建立機器學習系統的經驗教訓
- 如何使用機器學習清單可靠地獲得準確的預測(即使您是初學者)
- 機器學習模型運行期間要做什么
- 機器學習表現改進備忘單
- 來自世界級從業者的機器學習技巧:Phil Brierley
- 模型預測精度與機器學習中的解釋
- 競爭機器學習的模型選擇技巧
- 機器學習需要多少訓練數據?
- 如何系統地規劃和運行機器學習實驗
- 應用機器學習過程
- 默認情況下可重現的機器學習結果
- 10個實踐應用機器學習的標準數據集
- 簡單的三步法到最佳機器學習算法
- 打擊機器學習數據集中不平衡類的8種策略
- 模型表現不匹配問題(以及如何處理)
- 黑箱機器學習的誘惑陷阱
- 如何培養最終的機器學習模型
- 使用探索性數據分析了解您的問題并獲得更好的結果
- 什么是數據挖掘和KDD
- 為什么One-Hot在機器學習中編碼數據?
- 為什么你應該在你的機器學習問題上進行抽樣檢查算法
- 所以,你正在研究機器學習問題......
- Machine Learning Mastery Keras 深度學習教程
- Keras 中神經網絡模型的 5 步生命周期
- 在 Python 迷你課程中應用深度學習
- Keras 深度學習庫的二元分類教程
- 如何用 Keras 構建多層感知器神經網絡模型
- 如何在 Keras 中檢查深度學習模型
- 10 個用于 Amazon Web Services 深度學習的命令行秘籍
- 機器學習卷積神經網絡的速成課程
- 如何在 Python 中使用 Keras 進行深度學習的度量
- 深度學習書籍
- 深度學習課程
- 你所知道的深度學習是一種謊言
- 如何設置 Amazon AWS EC2 GPU 以訓練 Keras 深度學習模型(分步)
- 神經網絡中批量和迭代之間的區別是什么?
- 在 Keras 展示深度學習模型訓練歷史
- 基于 Keras 的深度學習模型中的dropout正則化
- 評估 Keras 中深度學習模型的表現
- 如何評價深度學習模型的技巧
- 小批量梯度下降的簡要介紹以及如何配置批量大小
- 在 Keras 中獲得深度學習幫助的 9 種方法
- 如何使用 Keras 在 Python 中網格搜索深度學習模型的超參數
- 用 Keras 在 Python 中使用卷積神經網絡進行手寫數字識別
- 如何用 Keras 進行預測
- 用 Keras 進行深度學習的圖像增強
- 8 個深度學習的鼓舞人心的應用
- Python 深度學習庫 Keras 簡介
- Python 深度學習庫 TensorFlow 簡介
- Python 深度學習庫 Theano 簡介
- 如何使用 Keras 函數式 API 進行深度學習
- Keras 深度學習庫的多類分類教程
- 多層感知器神經網絡速成課程
- 基于卷積神經網絡的 Keras 深度學習庫中的目標識別
- 流行的深度學習庫
- 用深度學習預測電影評論的情感
- Python 中的 Keras 深度學習庫的回歸教程
- 如何使用 Keras 獲得可重現的結果
- 如何在 Linux 服務器上運行深度學習實驗
- 保存并加載您的 Keras 深度學習模型
- 用 Keras 逐步開發 Python 中的第一個神經網絡
- 用 Keras 理解 Python 中的有狀態 LSTM 循環神經網絡
- 在 Python 中使用 Keras 深度學習模型和 Scikit-Learn
- 如何使用預訓練的 VGG 模型對照片中的物體進行分類
- 在 Python 和 Keras 中對深度學習模型使用學習率調度
- 如何在 Keras 中可視化深度學習神經網絡模型
- 什么是深度學習?
- 何時使用 MLP,CNN 和 RNN 神經網絡
- 為什么用隨機權重初始化神經網絡?
- Machine Learning Mastery 深度學習 NLP 教程
- 深度學習在自然語言處理中的 7 個應用
- 如何實現自然語言處理的波束搜索解碼器
- 深度學習文檔分類的最佳實踐
- 關于自然語言處理的熱門書籍
- 在 Python 中計算文本 BLEU 分數的溫和介紹
- 使用編碼器 - 解碼器模型的用于字幕生成的注入和合并架構
- 如何用 Python 清理機器學習的文本
- 如何配置神經機器翻譯的編碼器 - 解碼器模型
- 如何開始深度學習自然語言處理(7 天迷你課程)
- 自然語言處理的數據集
- 如何開發一種深度學習的詞袋模型來預測電影評論情感
- 深度學習字幕生成模型的溫和介紹
- 如何在 Keras 中定義神經機器翻譯的編碼器 - 解碼器序列 - 序列模型
- 如何利用小實驗在 Keras 中開發字幕生成模型
- 如何從頭開發深度學習圖片標題生成器
- 如何在 Keras 中開發基于字符的神經語言模型
- 如何開發用于情感分析的 N-gram 多通道卷積神經網絡
- 如何從零開始開發神經機器翻譯系統
- 如何在 Python 中用 Keras 開發基于單詞的神經語言模型
- 如何開發一種預測電影評論情感的詞嵌入模型
- 如何使用 Gensim 在 Python 中開發詞嵌入
- 用于文本摘要的編碼器 - 解碼器深度學習模型
- Keras 中文本摘要的編碼器 - 解碼器模型
- 用于神經機器翻譯的編碼器 - 解碼器循環神經網絡模型
- 淺談詞袋模型
- 文本摘要的溫和介紹
- 編碼器 - 解碼器循環神經網絡中的注意力如何工作
- 如何利用深度學習自動生成照片的文本描述
- 如何開發一個單詞級神經語言模型并用它來生成文本
- 淺談神經機器翻譯
- 什么是自然語言處理?
- 牛津自然語言處理深度學習課程
- 如何為機器翻譯準備法語到英語的數據集
- 如何為情感分析準備電影評論數據
- 如何為文本摘要準備新聞文章
- 如何準備照片標題數據集以訓練深度學習模型
- 如何使用 Keras 為深度學習準備文本數據
- 如何使用 scikit-learn 為機器學習準備文本數據
- 自然語言處理神經網絡模型入門
- 對自然語言處理的深度學習的承諾
- 在 Python 中用 Keras 進行 LSTM 循環神經網絡的序列分類
- 斯坦福自然語言處理深度學習課程評價
- 統計語言建模和神經語言模型的簡要介紹
- 使用 Keras 在 Python 中進行 LSTM 循環神經網絡的文本生成
- 淺談機器學習中的轉換
- 如何使用 Keras 將詞嵌入層用于深度學習
- 什么是用于文本的詞嵌入
- Machine Learning Mastery 深度學習時間序列教程
- 如何開發人類活動識別的一維卷積神經網絡模型
- 人類活動識別的深度學習模型
- 如何評估人類活動識別的機器學習算法
- 時間序列預測的多層感知器網絡探索性配置
- 比較經典和機器學習方法進行時間序列預測的結果
- 如何通過深度學習快速獲得時間序列預測的結果
- 如何利用 Python 處理序列預測問題中的缺失時間步長
- 如何建立預測大氣污染日的概率預測模型
- 如何開發一種熟練的機器學習時間序列預測模型
- 如何構建家庭用電自回歸預測模型
- 如何開發多步空氣污染時間序列預測的自回歸預測模型
- 如何制定多站點多元空氣污染時間序列預測的基線預測
- 如何開發時間序列預測的卷積神經網絡模型
- 如何開發卷積神經網絡用于多步時間序列預測
- 如何開發單變量時間序列預測的深度學習模型
- 如何開發 LSTM 模型用于家庭用電的多步時間序列預測
- 如何開發 LSTM 模型進行時間序列預測
- 如何開發多元多步空氣污染時間序列預測的機器學習模型
- 如何開發多層感知器模型進行時間序列預測
- 如何開發人類活動識別時間序列分類的 RNN 模型
- 如何開始深度學習的時間序列預測(7 天迷你課程)
- 如何網格搜索深度學習模型進行時間序列預測
- 如何對單變量時間序列預測的網格搜索樸素方法
- 如何在 Python 中搜索 SARIMA 模型超參數用于時間序列預測
- 如何在 Python 中進行時間序列預測的網格搜索三次指數平滑
- 一個標準的人類活動識別問題的溫和介紹
- 如何加載和探索家庭用電數據
- 如何加載,可視化和探索復雜的多變量多步時間序列預測數據集
- 如何從智能手機數據模擬人類活動
- 如何根據環境因素預測房間占用率
- 如何使用腦波預測人眼是開放還是閉合
- 如何在 Python 中擴展長短期內存網絡的數據
- 如何使用 TimeseriesGenerator 進行 Keras 中的時間序列預測
- 基于機器學習算法的室內運動時間序列分類
- 用于時間序列預測的狀態 LSTM 在線學習的不穩定性
- 用于罕見事件時間序列預測的 LSTM 模型體系結構
- 用于時間序列預測的 4 種通用機器學習數據變換
- Python 中長短期記憶網絡的多步時間序列預測
- 家庭用電機器學習的多步時間序列預測
- Keras 中 LSTM 的多變量時間序列預測
- 如何開發和評估樸素的家庭用電量預測方法
- 如何為長短期記憶網絡準備單變量時間序列數據
- 循環神經網絡在時間序列預測中的應用
- 如何在 Python 中使用差異變換刪除趨勢和季節性
- 如何在 LSTM 中種子狀態用于 Python 中的時間序列預測
- 使用 Python 進行時間序列預測的有狀態和無狀態 LSTM
- 長短時記憶網絡在時間序列預測中的適用性
- 時間序列預測問題的分類
- Python 中長短期記憶網絡的時間序列預測
- 基于 Keras 的 Python 中 LSTM 循環神經網絡的時間序列預測
- Keras 中深度學習的時間序列預測
- 如何用 Keras 調整 LSTM 超參數進行時間序列預測
- 如何在時間序列預測訓練期間更新 LSTM 網絡
- 如何使用 LSTM 網絡的 Dropout 進行時間序列預測
- 如何使用 LSTM 網絡中的特征進行時間序列預測
- 如何在 LSTM 網絡中使用時間序列進行時間序列預測
- 如何利用 LSTM 網絡進行權重正則化進行時間序列預測
- Machine Learning Mastery 線性代數教程
- 機器學習數學符號的基礎知識
- 用 NumPy 陣列輕松介紹廣播
- 如何從 Python 中的 Scratch 計算主成分分析(PCA)
- 用于編碼器審查的計算線性代數
- 10 機器學習中的線性代數示例
- 線性代數的溫和介紹
- 用 NumPy 輕松介紹 Python 中的 N 維數組
- 機器學習向量的溫和介紹
- 如何在 Python 中為機器學習索引,切片和重塑 NumPy 數組
- 機器學習的矩陣和矩陣算法簡介
- 溫和地介紹機器學習的特征分解,特征值和特征向量
- NumPy 對預期價值,方差和協方差的簡要介紹
- 機器學習矩陣分解的溫和介紹
- 用 NumPy 輕松介紹機器學習的張量
- 用于機器學習的線性代數中的矩陣類型簡介
- 用于機器學習的線性代數備忘單
- 線性代數的深度學習
- 用于機器學習的線性代數(7 天迷你課程)
- 機器學習的線性代數
- 機器學習矩陣運算的溫和介紹
- 線性代數評論沒有廢話指南
- 學習機器學習線性代數的主要資源
- 淺談機器學習的奇異值分解
- 如何用線性代數求解線性回歸
- 用于機器學習的稀疏矩陣的溫和介紹
- 機器學習中向量規范的溫和介紹
- 學習線性代數用于機器學習的 5 個理由
- Machine Learning Mastery LSTM 教程
- Keras中長短期記憶模型的5步生命周期
- 長短時記憶循環神經網絡的注意事項
- CNN長短期記憶網絡
- 逆向神經網絡中的深度學習速成課程
- 可變長度輸入序列的數據準備
- 如何用Keras開發用于Python序列分類的雙向LSTM
- 如何開發Keras序列到序列預測的編碼器 - 解碼器模型
- 如何診斷LSTM模型的過度擬合和欠擬合
- 如何開發一種編碼器 - 解碼器模型,注重Keras中的序列到序列預測
- 編碼器 - 解碼器長短期存儲器網絡
- 神經網絡中爆炸梯度的溫和介紹
- 對時間反向傳播的溫和介紹
- 生成長短期記憶網絡的溫和介紹
- 專家對長短期記憶網絡的簡要介紹
- 在序列預測問題上充分利用LSTM
- 編輯器 - 解碼器循環神經網絡全局注意的溫和介紹
- 如何利用長短時記憶循環神經網絡處理很長的序列
- 如何在Python中對一個熱編碼序列數據
- 如何使用編碼器 - 解碼器LSTM來回顯隨機整數序列
- 具有注意力的編碼器 - 解碼器RNN體系結構的實現模式
- 學習使用編碼器解碼器LSTM循環神經網絡添加數字
- 如何學習長短時記憶循環神經網絡回聲隨機整數
- 具有Keras的長短期記憶循環神經網絡的迷你課程
- LSTM自動編碼器的溫和介紹
- 如何用Keras中的長短期記憶模型進行預測
- 用Python中的長短期內存網絡演示內存
- 基于循環神經網絡的序列預測模型的簡要介紹
- 深度學習的循環神經網絡算法之旅
- 如何重塑Keras中長短期存儲網絡的輸入數據
- 了解Keras中LSTM的返回序列和返回狀態之間的差異
- RNN展開的溫和介紹
- 5學習LSTM循環神經網絡的簡單序列預測問題的例子
- 使用序列進行預測
- 堆疊長短期內存網絡
- 什么是教師強制循環神經網絡?
- 如何在Python中使用TimeDistributed Layer for Long Short-Term Memory Networks
- 如何準備Keras中截斷反向傳播的序列預測
- 如何在使用LSTM進行訓練和預測時使用不同的批量大小
- Machine Learning Mastery 機器學習算法教程
- 機器學習算法之旅
- 用于機器學習的裝袋和隨機森林集合算法
- 從頭開始實施機器學習算法的好處
- 更好的樸素貝葉斯:從樸素貝葉斯算法中獲取最多的12個技巧
- 機器學習的提升和AdaBoost
- 選擇機器學習算法:Microsoft Azure的經驗教訓
- 機器學習的分類和回歸樹
- 什么是機器學習中的混淆矩陣
- 如何使用Python從頭開始創建算法測試工具
- 通過創建機器學習算法的目標列表來控制
- 從頭開始停止編碼機器學習算法
- 在實現機器學習算法時,不要從開源代碼開始
- 不要使用隨機猜測作為基線分類器
- 淺談機器學習中的概念漂移
- 溫和介紹機器學習中的偏差 - 方差權衡
- 機器學習的梯度下降
- 機器學習算法如何工作(他們學習輸入到輸出的映射)
- 如何建立機器學習算法的直覺
- 如何實現機器學習算法
- 如何研究機器學習算法行為
- 如何學習機器學習算法
- 如何研究機器學習算法
- 如何研究機器學習算法
- 如何在Python中從頭開始實現反向傳播算法
- 如何用Python從頭開始實現Bagging
- 如何用Python從頭開始實現基線機器學習算法
- 如何在Python中從頭開始實現決策樹算法
- 如何用Python從頭開始實現學習向量量化
- 如何利用Python從頭開始隨機梯度下降實現線性回歸
- 如何利用Python從頭開始隨機梯度下降實現Logistic回歸
- 如何用Python從頭開始實現機器學習算法表現指標
- 如何在Python中從頭開始實現感知器算法
- 如何在Python中從零開始實現隨機森林
- 如何在Python中從頭開始實現重采樣方法
- 如何用Python從頭開始實現簡單線性回歸
- 如何用Python從頭開始實現堆棧泛化(Stacking)
- K-Nearest Neighbors for Machine Learning
- 學習機器學習的向量量化
- 機器學習的線性判別分析
- 機器學習的線性回歸
- 使用梯度下降進行機器學習的線性回歸教程
- 如何在Python中從頭開始加載機器學習數據
- 機器學習的Logistic回歸
- 機器學習的Logistic回歸教程
- 機器學習算法迷你課程
- 如何在Python中從頭開始實現樸素貝葉斯
- 樸素貝葉斯機器學習
- 樸素貝葉斯機器學習教程
- 機器學習算法的過擬合和欠擬合
- 參數化和非參數機器學習算法
- 理解任何機器學習算法的6個問題
- 在機器學習中擁抱隨機性
- 如何使用Python從頭開始擴展機器學習數據
- 機器學習的簡單線性回歸教程
- 有監督和無監督的機器學習算法
- 用于機器學習的支持向量機
- 在沒有數學背景的情況下理解機器學習算法的5種技術
- 最好的機器學習算法
- 教程從頭開始在Python中實現k-Nearest Neighbors
- 通過從零開始實現它們來理解機器學習算法(以及繞過壞代碼的策略)
- 使用隨機森林:在121個數據集上測試179個分類器
- 為什么從零開始實現機器學習算法
- Machine Learning Mastery 機器學習入門教程
- 機器學習入門的四個步驟:初學者入門與實踐的自上而下策略
- 你應該培養的 5 個機器學習領域
- 一種選擇機器學習算法的數據驅動方法
- 機器學習中的分析與數值解
- 應用機器學習是一種精英政治
- 機器學習的基本概念
- 如何成為數據科學家
- 初學者如何在機器學習中弄錯
- 機器學習的最佳編程語言
- 構建機器學習組合
- 機器學習中分類與回歸的區別
- 評估自己作為數據科學家并利用結果建立驚人的數據科學團隊
- 探索 Kaggle 大師的方法論和心態:對 Diogo Ferreira 的采訪
- 擴展機器學習工具并展示掌握
- 通過尋找地標開始機器學習
- 溫和地介紹預測建模
- 通過提供結果在機器學習中獲得夢想的工作
- 如何開始機器學習:自學藍圖
- 開始并在機器學習方面取得進展
- 應用機器學習的 Hello World
- 初學者如何使用小型項目開始機器學習并在 Kaggle 上進行競爭
- 我如何開始機器學習? (簡短版)
- 我是如何開始機器學習的
- 如何在機器學習中取得更好的成績
- 如何從在銀行工作到擔任 Target 的高級數據科學家
- 如何學習任何機器學習工具
- 使用小型目標項目深入了解機器學習工具
- 獲得付費申請機器學習
- 映射機器學習工具的景觀
- 機器學習開發環境
- 機器學習金錢
- 程序員的機器學習
- 機器學習很有意思
- 機器學習是 Kaggle 比賽
- 機器學習現在很受歡迎
- 機器學習掌握方法
- 機器學習很重要
- 機器學習 Q& A:概念漂移,更好的結果和學習更快
- 缺乏自學機器學習的路線圖
- 機器學習很重要
- 快速了解任何機器學習工具(即使您是初學者)
- 機器學習工具
- 找到你的機器學習部落
- 機器學習在一年
- 通過競爭一致的大師 Kaggle
- 5 程序員在機器學習中開始犯錯誤
- 哲學畢業生到機器學習從業者(Brian Thomas 采訪)
- 機器學習入門的實用建議
- 實用機器學習問題
- 使用來自 UCI 機器學習庫的數據集練習機器學習
- 使用秘籍的任何機器學習工具快速啟動
- 程序員可以進入機器學習
- 程序員應該進入機器學習
- 項目焦點:Shashank Singh 的人臉識別
- 項目焦點:使用 Mahout 和 Konstantin Slisenko 進行堆棧交換群集
- 機器學習自學指南
- 4 個自學機器學習項目
- álvaroLemos 如何在數據科學團隊中獲得機器學習實習
- 如何思考機器學習
- 現實世界機器學習問題之旅
- 有關機器學習的有用知識
- 如果我沒有學位怎么辦?
- 如果我不是一個優秀的程序員怎么辦?
- 如果我不擅長數學怎么辦?
- 為什么機器學習算法會處理以前從未見過的數據?
- 是什么阻礙了你的機器學習目標?
- 什么是機器學習?
- 機器學習適合哪里?
- 為什么要進入機器學習?
- 研究對您來說很重要的機器學習問題
- 你這樣做是錯的。為什么機器學習不必如此困難
- Machine Learning Mastery Sklearn 教程
- Scikit-Learn 的溫和介紹:Python 機器學習庫
- 使用 Python 管道和 scikit-learn 自動化機器學習工作流程
- 如何以及何時使用帶有 scikit-learn 的校準分類模型
- 如何比較 Python 中的機器學習算法與 scikit-learn
- 用于機器學習開發人員的 Python 崩潰課程
- 用 scikit-learn 在 Python 中集成機器學習算法
- 使用重采樣評估 Python 中機器學習算法的表現
- 使用 Scikit-Learn 在 Python 中進行特征選擇
- Python 中機器學習的特征選擇
- 如何使用 scikit-learn 在 Python 中生成測試數據集
- scikit-learn 中的機器學習算法秘籍
- 如何使用 Python 處理丟失的數據
- 如何開始使用 Python 進行機器學習
- 如何使用 Scikit-Learn 在 Python 中加載數據
- Python 中概率評分方法的簡要介紹
- 如何用 Scikit-Learn 調整算法參數
- 如何在 Mac OS X 上安裝 Python 3 環境以進行機器學習和深度學習
- 使用 scikit-learn 進行機器學習簡介
- 從 shell 到一本帶有 Fernando Perez 單一工具的書的 IPython
- 如何使用 Python 3 為機器學習開發創建 Linux 虛擬機
- 如何在 Python 中加載機器學習數據
- 您在 Python 中的第一個機器學習項目循序漸進
- 如何使用 scikit-learn 進行預測
- 用于評估 Python 中機器學習算法的度量標準
- 使用 Pandas 為 Python 中的機器學習準備數據
- 如何使用 Scikit-Learn 為 Python 機器學習準備數據
- 項目焦點:使用 Artem Yankov 在 Python 中進行事件推薦
- 用于機器學習的 Python 生態系統
- Python 是應用機器學習的成長平臺
- Python 機器學習書籍
- Python 機器學習迷你課程
- 使用 Pandas 快速和骯臟的數據分析
- 使用 Scikit-Learn 重新調整 Python 中的機器學習數據
- 如何以及何時使用 ROC 曲線和精確調用曲線進行 Python 分類
- 使用 scikit-learn 在 Python 中保存和加載機器學習模型
- scikit-learn Cookbook 書評
- 如何使用 Anaconda 為機器學習和深度學習設置 Python 環境
- 使用 scikit-learn 在 Python 中進行 Spot-Check 分類機器學習算法
- 如何在 Python 中開發可重復使用的抽樣檢查算法框架
- 使用 scikit-learn 在 Python 中進行 Spot-Check 回歸機器學習算法
- 使用 Python 中的描述性統計來了解您的機器學習數據
- 使用 OpenCV,Python 和模板匹配來播放“哪里是 Waldo?”
- 使用 Pandas 在 Python 中可視化機器學習數據
- Machine Learning Mastery 統計學教程
- 淺談計算正態匯總統計量
- 非參數統計的溫和介紹
- Python中常態測試的溫和介紹
- 淺談Bootstrap方法
- 淺談機器學習的中心極限定理
- 淺談機器學習中的大數定律
- 機器學習的所有統計數據
- 如何計算Python中機器學習結果的Bootstrap置信區間
- 淺談機器學習的Chi-Squared測試
- 機器學習的置信區間
- 隨機化在機器學習中解決混雜變量的作用
- 機器學習中的受控實驗
- 機器學習統計學速成班
- 統計假設檢驗的關鍵值以及如何在Python中計算它們
- 如何在機器學習中談論數據(統計學和計算機科學術語)
- Python中數據可視化方法的簡要介紹
- Python中效果大小度量的溫和介紹
- 估計隨機機器學習算法的實驗重復次數
- 機器學習評估統計的溫和介紹
- 如何計算Python中的非參數秩相關性
- 如何在Python中計算數據的5位數摘要
- 如何在Python中從頭開始編寫學生t檢驗
- 如何在Python中生成隨機數
- 如何轉換數據以更好地擬合正態分布
- 如何使用相關來理解變量之間的關系
- 如何使用統計信息識別數據中的異常值
- 用于Python機器學習的隨機數生成器簡介
- k-fold交叉驗證的溫和介紹
- 如何計算McNemar的比較兩種機器學習量詞的測試
- Python中非參數統計顯著性測試簡介
- 如何在Python中使用參數統計顯著性測試
- 機器學習的預測間隔
- 應用統計學與機器學習的密切關系
- 如何使用置信區間報告分類器表現
- 統計數據分布的簡要介紹
- 15 Python中的統計假設檢驗(備忘單)
- 統計假設檢驗的溫和介紹
- 10如何在機器學習項目中使用統計方法的示例
- Python中統計功效和功耗分析的簡要介紹
- 統計抽樣和重新抽樣的簡要介紹
- 比較機器學習算法的統計顯著性檢驗
- 機器學習中統計容差區間的溫和介紹
- 機器學習統計書籍
- 評估機器學習模型的統計數據
- 機器學習統計(7天迷你課程)
- 用于機器學習的簡明英語統計
- 如何使用統計顯著性檢驗來解釋機器學習結果
- 什么是統計(為什么它在機器學習中很重要)?
- Machine Learning Mastery 時間序列入門教程
- 如何在 Python 中為時間序列預測創建 ARIMA 模型
- 用 Python 進行時間序列預測的自回歸模型
- 如何回溯機器學習模型的時間序列預測
- Python 中基于時間序列數據的基本特征工程
- R 的時間序列預測熱門書籍
- 10 挑戰機器學習時間序列預測問題
- 如何將時間序列轉換為 Python 中的監督學習問題
- 如何將時間序列數據分解為趨勢和季節性
- 如何用 ARCH 和 GARCH 模擬波動率進行時間序列預測
- 如何將時間序列數據集與 Python 區分開來
- Python 中時間序列預測的指數平滑的溫和介紹
- 用 Python 進行時間序列預測的特征選擇
- 淺談自相關和部分自相關
- 時間序列預測的 Box-Jenkins 方法簡介
- 用 Python 簡要介紹時間序列的時間序列預測
- 如何使用 Python 網格搜索 ARIMA 模型超參數
- 如何在 Python 中加載和探索時間序列數據
- 如何使用 Python 對 ARIMA 模型進行手動預測
- 如何用 Python 進行時間序列預測的預測
- 如何使用 Python 中的 ARIMA 進行樣本外預測
- 如何利用 Python 模擬殘差錯誤來糾正時間序列預測
- 使用 Python 進行數據準備,特征工程和時間序列預測的移動平均平滑
- 多步時間序列預測的 4 種策略
- 如何在 Python 中規范化和標準化時間序列數據
- 如何利用 Python 進行時間序列預測的基線預測
- 如何使用 Python 對時間序列預測數據進行功率變換
- 用于時間序列預測的 Python 環境
- 如何重構時間序列預測問題
- 如何使用 Python 重新采樣和插值您的時間序列數據
- 用 Python 編寫 SARIMA 時間序列預測
- 如何在 Python 中保存 ARIMA 時間序列預測模型
- 使用 Python 進行季節性持久性預測
- 基于 ARIMA 的 Python 歷史規模敏感性預測技巧分析
- 簡單的時間序列預測模型進行測試,這樣你就不會欺騙自己
- 標準多變量,多步驟和多站點時間序列預測問題
- 如何使用 Python 檢查時間序列數據是否是固定的
- 使用 Python 進行時間序列數據可視化
- 7 個機器學習的時間序列數據集
- 時間序列預測案例研究與 Python:波士頓每月武裝搶劫案
- Python 的時間序列預測案例研究:巴爾的摩的年度用水量
- 使用 Python 進行時間序列預測研究:法國香檳的月銷售額
- 使用 Python 的置信區間理解時間序列預測不確定性
- 11 Python 中的經典時間序列預測方法(備忘單)
- 使用 Python 進行時間序列預測表現測量
- 使用 Python 7 天迷你課程進行時間序列預測
- 時間序列預測作為監督學習
- 什么是時間序列預測?
- 如何使用 Python 識別和刪除時間序列數據的季節性
- 如何在 Python 中使用和刪除時間序列數據中的趨勢信息
- 如何在 Python 中調整 ARIMA 參數
- 如何用 Python 可視化時間序列殘差預測錯誤
- 白噪聲時間序列與 Python
- 如何通過時間序列預測項目
- Machine Learning Mastery XGBoost 教程
- 通過在 Python 中使用 XGBoost 提前停止來避免過度擬合
- 如何在 Python 中調優 XGBoost 的多線程支持
- 如何配置梯度提升算法
- 在 Python 中使用 XGBoost 進行梯度提升的數據準備
- 如何使用 scikit-learn 在 Python 中開發您的第一個 XGBoost 模型
- 如何在 Python 中使用 XGBoost 評估梯度提升模型
- 在 Python 中使用 XGBoost 的特征重要性和特征選擇
- 淺談機器學習的梯度提升算法
- 應用機器學習的 XGBoost 簡介
- 如何在 macOS 上為 Python 安裝 XGBoost
- 如何在 Python 中使用 XGBoost 保存梯度提升模型
- 從梯度提升開始,比較 165 個數據集上的 13 種算法
- 在 Python 中使用 XGBoost 和 scikit-learn 進行隨機梯度提升
- 如何使用 Amazon Web Services 在云中訓練 XGBoost 模型
- 在 Python 中使用 XGBoost 調整梯度提升的學習率
- 如何在 Python 中使用 XGBoost 調整決策樹的數量和大小
- 如何在 Python 中使用 XGBoost 可視化梯度提升決策樹
- 在 Python 中開始使用 XGBoost 的 7 步迷你課程