
[TOC]
<br>
最近在整理JVM相關的PPT,把CMS算法又過了一遍,每次閱讀源碼都能多了解一點,繼續堅持。
什么是CMS
CMS全稱?ConcurrentMarkSweep,是一款并發的、使用標記-清除算法的垃圾回收器, 如果老年代使用CMS垃圾回收器,需要添加虛擬機參數-"XX:+UseConcMarkSweepGC"。
使用場景:
GC過程短暫停,適合對時延要求較高的服務,用戶線程不允許長時間的停頓。
缺點:
服務長時間運行,造成嚴重的內存碎片化。 另外,算法實現比較復雜(如果也算缺點的話)
實現機制
根據GC的觸發機制分為:周期性Old GC(被動)和主動Old GC,純屬個人理解,實在不知道怎么分才好。
周期性Old GC
周期性Old GC,執行的邏輯也叫?BackgroundCollect,對老年代進行回收,在GC日志中比較常見,由后臺線程ConcurrentMarkSweepThread循環判斷(默認2s)是否需要觸發。
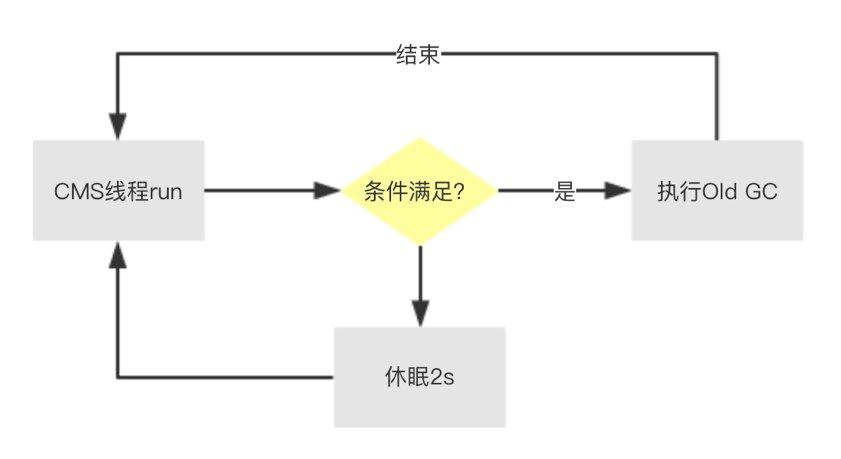
觸發條件
1. 如果沒有設置?UseCMSInitiatingOccupancyOnly,虛擬機會根據收集的數據決定是否觸發(線上環境建議帶上這個參數,不然會加大問題排查的難度)
2. 老年代使用率達到閾值?CMSInitiatingOccupancyFraction,默認92%
3. 永久代的使用率達到閾值?CMSInitiatingPermOccupancyFraction,默認92%,前提是開啟?CMSClassUnloadingEnabled
4. 新生代的晉升擔保失敗
晉升擔保失敗
老年代是否有足夠的空間來容納全部的新生代對象或歷史平均晉升到老年代的對象,如果不夠的話,就提早進行一次老年代的回收,防止下次進行YGC的時候發生晉升失敗。
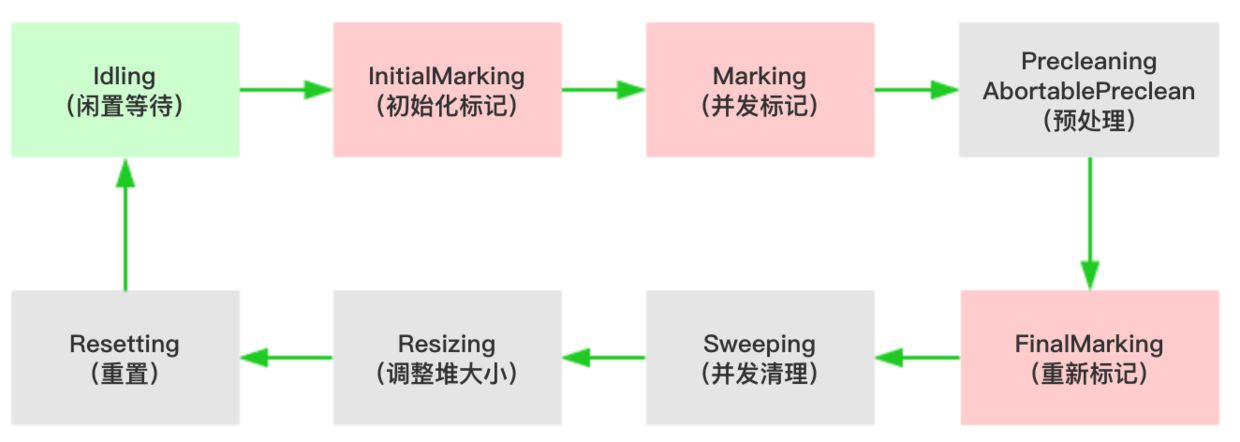
周期性Old GC過程
當條件滿足時,采用“標記-清理”算法對老年代進行回收,過程可以說很簡單,標記出存活對象,清理掉垃圾對象,但是為了實現整個過程的低延遲,實際算法遠遠沒這么簡單,整個過程分為如下幾個部分:
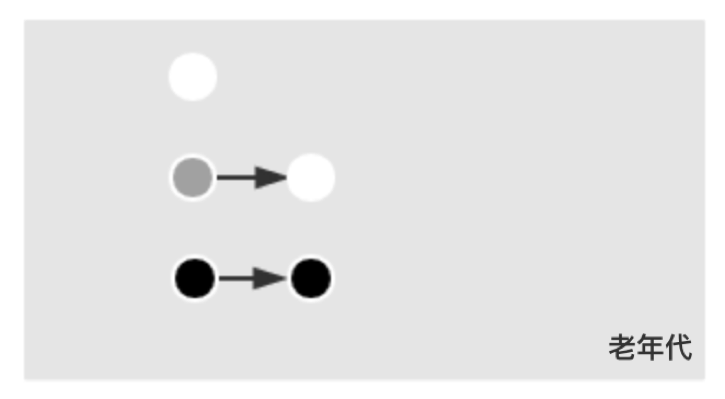
對象在標記過程中,根據標記情況,分成三類:
1. 白色對象,表示自身未被標記;
2. 灰色對象,表示自身被標記,但內部引用未被處理;
3. 黑色對象,表示自身被標記,內部引用都被處理;
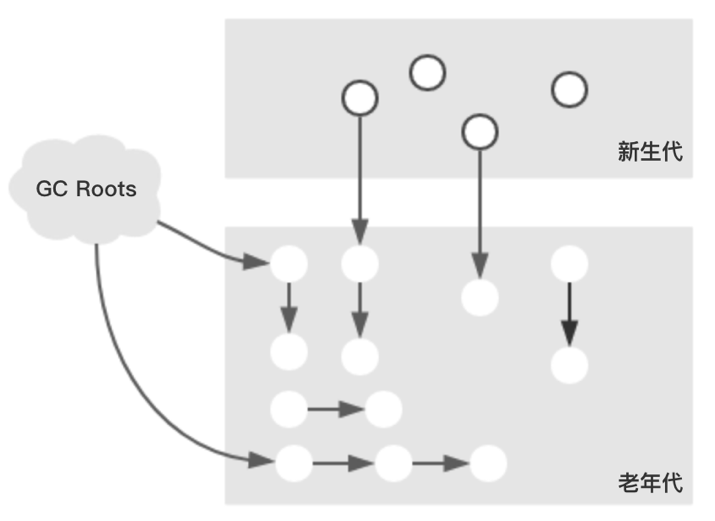
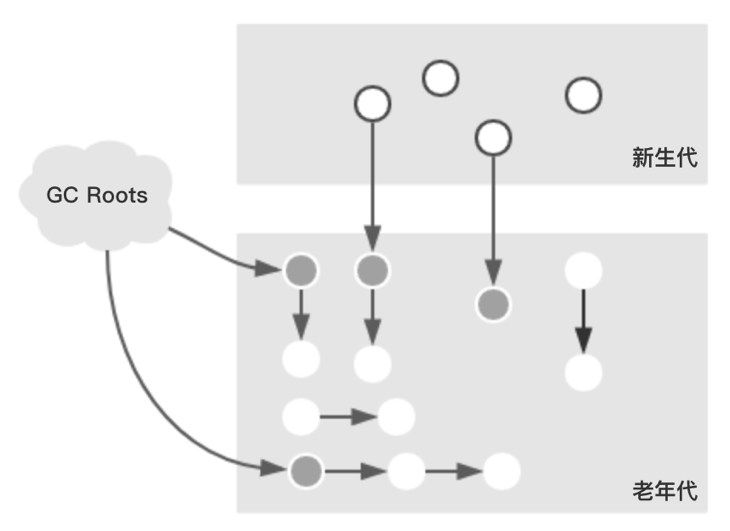
假設發生Background Collect時,Java堆的對象分布如下:
1、InitialMarking(初始化標記,整個過程STW)
該階段單線程執行,主要分分為兩步:
1. 標記GC Roots可達的老年代對象;
2. 遍歷新生代對象,標記可達的老年代對象;
該過程結束后,對象分布如下:
2、Marking(并發標記)
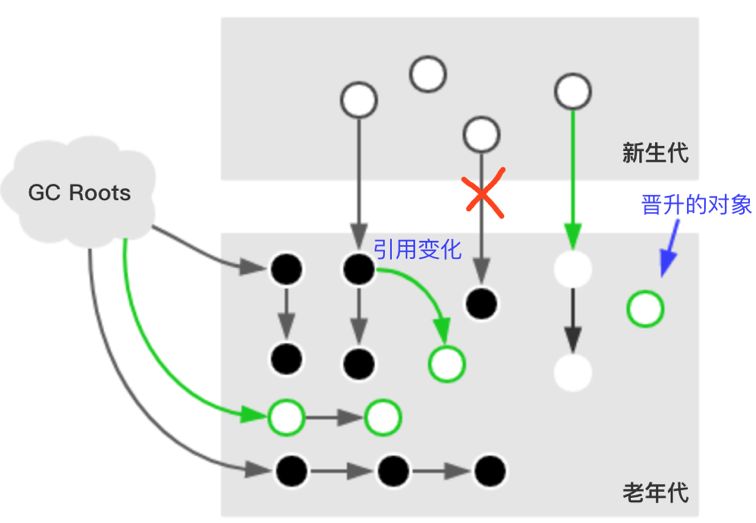
該階段GC線程和應用線程并發執行,遍歷InitialMarking階段標記出來的存活對象,然后繼續遞歸標記這些對象可達的對象。
因為該階段并發執行的,在運行期間可能發生新生代的對象晉升到老年代、或者是直接在老年代分配對象、或者更新老年代對象的引用關系等等,對于這些對象,都是需要進行重新標記的,否則有些對象就會被遺漏,發生漏標的情況。
為了提高重新標記的效率,該階段會把上述對象所在的Card標識為Dirty,后續只需掃描這些Dirty Card的對象,避免掃描整個老年代。
3、Precleaning(預清理)
通過參數?CMSPrecleaningEnabled選擇關閉該階段,默認啟用,主要做兩件事情:
1. 處理新生代已經發現的引用,比如在并發階段,在Eden區中分配了一個A對象,A對象引用了一個老年代對象B(這個B之前沒有被標記),在這個階段就會標記對象B為活躍對象。
2. 在并發標記階段,如果老年代中有對象內部引用發生變化,會把所在的Card標記為Dirty(其實這里并非使用CardTable,而是一個類似的數據結構,叫ModUnionTalble),通過掃描這些Table,重新標記那些在并發標記階段引用被更新的對象(晉升到老年代的對象、原本就在老年代的對象)
4、AbortablePreclean(可中斷的預清理)
該階段發生的前提是,新生代Eden區的內存使用量大于參數CMSScheduleRemarkEdenSizeThreshold默認是2M,如果新生代的對象太少,就沒有必要執行該階段,直接執行重新標記階段。
為什么需要這個階段,存在的價值是什么?
因為CMS GC的終極目標是降低垃圾回收時的暫停時間,所以在該階段要盡最大的努力去處理那些在并發階段被應用線程更新的老年代對象,這樣在暫停的重新標記階段就可以少處理一些,暫停時間也會相應的降低。
在該階段,主要循環的做兩件事:
1. 處理 From 和 To 區的對象,標記可達的老年代對象
2. 和上一個階段一樣,掃描處理Dirty Card中的對象
當然了,這個邏輯不會一直循環下去,打斷這個循環的條件有三個:
1. 可以設置最多循環的次數?CMSMaxAbortablePrecleanLoops,默認是0,表示沒有循環次數的限制。
2. 如果執行這個邏輯的時間達到了閾值?CMSMaxAbortablePrecleanTime,默認是5s,會退出循環。
3. 如果新生代Eden區的內存使用率達到了閾值?CMSScheduleRemarkEdenPenetration,默認50%,會退出循環。(這個條件能夠成立的前提是,在進行Precleaning時,Eden區的使用率小于十分之一)
如果在循環退出之前,發生了一次YGC,對于后面的Remark階段來說,大大減輕了掃描年輕代的負擔,但是發生YGC并非人為控制,所以只能祈禱這5s內可以來一次YGC。
1. ...
2. 1678.150:\[CMS-concurrent-preclean-start\]
3. 1678.186:\[CMS-concurrent-preclean:0.044/0.055secs\]
4. 1678.186:\[CMS-concurrent-abortable-preclean-start\]
5. 1678.365:\[GC?1678.465:\[ParNew:2080530K->1464K(2044544K),0.0127340secs\]
6. 1389293K->306572K(2093120K),
7. 0.0167509secs\]
8. 1680.093:\[CMS-concurrent-abortable-preclean:1.052/1.907secs\]
9. ....
在上面GC日志中,1678.186啟動了AbortablePreclean階段,在隨后不到2s就發生了一次YGC。
5、FinalMarking(并發重新標記,STW過程)
該階段并發執行,在之前的并行階段(GC線程和應用線程同時執行,好比你媽在打掃房間,你還在扔紙屑),可能產生新的引用關系如下:
1. 老年代的新對象被GC Roots引用
2. 老年代的未標記對象被新生代對象引用
3. 老年代已標記的對象增加新引用指向老年代其它對象
4. 新生代對象指向老年代引用被刪除
5. 也許還有其它情況..
上述對象中可能有一些已經在Precleaning階段和AbortablePreclean階段被處理過,但總存在沒來得及處理的,所以還有進行如下的處理:
1. 遍歷新生代對象,重新標記
2. 根據GC Roots,重新標記
3. 遍歷老年代的Dirty Card,重新標記,這里的Dirty Card大部分已經在clean階段處理過
在第一步驟中,需要遍歷新生代的全部對象,如果新生代的使用率很高,需要遍歷處理的對象也很多,這對于這個階段的總耗時來說,是個災難(因為可能大量的對象是暫時存活的,而且這些對象也可能引用大量的老年代對象,造成很多應該回收的老年代對象而沒有被回收,遍歷遞歸的次數也增加不少),如果在AbortablePreclean階段中能夠恰好的發生一次YGC,這樣就可以避免掃描無效的對象。
如果在AbortablePreclean階段沒來得及執行一次YGC,怎么辦?
CMS算法中提供了一個參數:?CMSScavengeBeforeRemark,默認并沒有開啟,如果開啟該參數,在執行該階段之前,會強制觸發一次YGC,可以減少新生代對象的遍歷時間,回收的也更徹底一點。
不過,這種參數有利有弊,利是降低了Remark階段的停頓時間,弊的是在新生代對象很少的情況下也多了一次YGC,最可憐的是在AbortablePreclean階段已經發生了一次YGC,然后在該階段又傻傻的觸發一次。
所以利弊需要把握。
主動Old GC
這個主動Old GC的過程,觸發條件比較苛刻:
1. YGC過程發生Promotion Failed,進而對老年代進行回收
2. System.gc(),前提是添加了-XX:+ExplicitGCInvokesConcurrent參數
如果觸發了主動Old GC,這時周期性Old GC正在執行,那么會奪過周期性Old GC的執行權(同一個時刻只能有一種在Old GC在運行),并記錄 concurrent mode failure 或者 concurrent mode interrupted。
主動GC開始時,需要判斷本次GC是否要對老年代的空間進行Compact(因為長時間的周期性GC會造成大量的碎片空間),判斷邏輯實現如下:
1. \*should\_compact?=
2. UseCMSCompactAtFullCollection&&
3. ((\_full\_gcs\_since\_conc\_gc?>=CMSFullGCsBeforeCompaction)||
4. GCCause::is\_user\_requested\_gc(gch->gc\_cause())||
5. gch->incremental\_collection\_will\_fail(true/\* consult\_young \*/));
在三種情況下會進行壓縮:
1. 其中參數?UseCMSCompactAtFullCollection(默認true)和CMSFullGCsBeforeCompaction(默認0),所以默認每次的主動GC都會對老年代的內存空間進行壓縮,就是把對象移動到內存的最左邊。
2. 當然了,比如執行了?System.gc(),也會進行壓縮。
3. 如果新生代的晉升擔保會失敗。
帶壓縮動作的算法,稱為MSC,標記-清理-壓縮,采用單線程,全暫停的方式進行垃圾收集,暫停時間很長很長...
那不帶壓縮動作的算法是什么樣的呢?
不帶壓縮動作的執行邏輯叫?ForegroundCollect,整個過程相對周期性Old GC來說,少了Precleaning和AbortablePreclean兩個階段,其它過程都差不多。
--轉至:http://www.cnblogs.com/aspirant/p/8663911.html
- 一.JVM
- 1.1 java代碼是怎么運行的
- 1.2 JVM的內存區域
- 1.3 JVM運行時內存
- 1.4 JVM內存分配策略
- 1.5 JVM類加載機制與對象的生命周期
- 1.6 常用的垃圾回收算法
- 1.7 JVM垃圾收集器
- 1.8 CMS垃圾收集器
- 1.9 G1垃圾收集器
- 2.面試相關文章
- 2.1 可能是把Java內存區域講得最清楚的一篇文章
- 2.0 GC調優參數
- 2.1GC排查系列
- 2.2 內存泄漏和內存溢出
- 2.2.3 深入理解JVM-hotspot虛擬機對象探秘
- 1.10 并發的可達性分析相關問題
- 二.Java集合架構
- 1.ArrayList深入源碼分析
- 2.Vector深入源碼分析
- 3.LinkedList深入源碼分析
- 4.HashMap深入源碼分析
- 5.ConcurrentHashMap深入源碼分析
- 6.HashSet,LinkedHashSet 和 LinkedHashMap
- 7.容器中的設計模式
- 8.集合架構之面試指南
- 9.TreeSet和TreeMap
- 三.Java基礎
- 1.基礎概念
- 1.1 Java程序初始化的順序是怎么樣的
- 1.2 Java和C++的區別
- 1.3 反射
- 1.4 注解
- 1.5 泛型
- 1.6 字節與字符的區別以及訪問修飾符
- 1.7 深拷貝與淺拷貝
- 1.8 字符串常量池
- 2.面向對象
- 3.關鍵字
- 4.基本數據類型與運算
- 5.字符串與數組
- 6.異常處理
- 7.Object 通用方法
- 8.Java8
- 8.1 Java 8 Tutorial
- 8.2 Java 8 數據流(Stream)
- 8.3 Java 8 并發教程:線程和執行器
- 8.4 Java 8 并發教程:同步和鎖
- 8.5 Java 8 并發教程:原子變量和 ConcurrentMap
- 8.6 Java 8 API 示例:字符串、數值、算術和文件
- 8.7 在 Java 8 中避免 Null 檢查
- 8.8 使用 Intellij IDEA 解決 Java 8 的數據流問題
- 四.Java 并發編程
- 1.線程的實現/創建
- 2.線程生命周期/狀態轉換
- 3.線程池
- 4.線程中的協作、中斷
- 5.Java鎖
- 5.1 樂觀鎖、悲觀鎖和自旋鎖
- 5.2 Synchronized
- 5.3 ReentrantLock
- 5.4 公平鎖和非公平鎖
- 5.3.1 說說ReentrantLock的實現原理,以及ReentrantLock的核心源碼是如何實現的?
- 5.5 鎖優化和升級
- 6.多線程的上下文切換
- 7.死鎖的產生和解決
- 8.J.U.C(java.util.concurrent)
- 0.簡化版(快速復習用)
- 9.鎖優化
- 10.Java 內存模型(JMM)
- 11.ThreadLocal詳解
- 12 CAS
- 13.AQS
- 0.ArrayBlockingQueue和LinkedBlockingQueue的實現原理
- 1.DelayQueue的實現原理
- 14.Thread.join()實現原理
- 15.PriorityQueue 的特性和原理
- 16.CyclicBarrier的實際使用場景
- 五.Java I/O NIO
- 1.I/O模型簡述
- 2.Java NIO之緩沖區
- 3.JAVA NIO之文件通道
- 4.Java NIO之套接字通道
- 5.Java NIO之選擇器
- 6.基于 Java NIO 實現簡單的 HTTP 服務器
- 7.BIO-NIO-AIO
- 8.netty(一)
- 9.NIO面試題
- 六.Java設計模式
- 1.單例模式
- 2.策略模式
- 3.模板方法
- 4.適配器模式
- 5.簡單工廠
- 6.門面模式
- 7.代理模式
- 七.數據結構和算法
- 1.什么是紅黑樹
- 2.二叉樹
- 2.1 二叉樹的前序、中序、后序遍歷
- 3.排序算法匯總
- 4.java實現鏈表及鏈表的重用操作
- 4.1算法題-鏈表反轉
- 5.圖的概述
- 6.常見的幾道字符串算法題
- 7.幾道常見的鏈表算法題
- 8.leetcode常見算法題1
- 9.LRU緩存策略
- 10.二進制及位運算
- 10.1.二進制和十進制轉換
- 10.2.位運算
- 11.常見鏈表算法題
- 12.算法好文推薦
- 13.跳表
- 八.Spring 全家桶
- 1.Spring IOC
- 2.Spring AOP
- 3.Spring 事務管理
- 4.SpringMVC 運行流程和手動實現
- 0.Spring 核心技術
- 5.spring如何解決循環依賴問題
- 6.springboot自動裝配原理
- 7.Spring中的循環依賴解決機制中,為什么要三級緩存,用二級緩存不夠嗎
- 8.beanFactory和factoryBean有什么區別
- 九.數據庫
- 1.mybatis
- 1.1 MyBatis-# 與 $ 區別以及 sql 預編譯
- Mybatis系列1-Configuration
- Mybatis系列2-SQL執行過程
- Mybatis系列3-之SqlSession
- Mybatis系列4-之Executor
- Mybatis系列5-StatementHandler
- Mybatis系列6-MappedStatement
- Mybatis系列7-參數設置揭秘(ParameterHandler)
- Mybatis系列8-緩存機制
- 2.淺談聚簇索引和非聚簇索引的區別
- 3.mysql 證明為什么用limit時,offset很大會影響性能
- 4.MySQL中的索引
- 5.數據庫索引2
- 6.面試題收集
- 7.MySQL行鎖、表鎖、間隙鎖詳解
- 8.數據庫MVCC詳解
- 9.一條SQL查詢語句是如何執行的
- 10.MySQL 的 crash-safe 原理解析
- 11.MySQL 性能優化神器 Explain 使用分析
- 12.mysql中,一條update語句執行的過程是怎么樣的?期間用到了mysql的哪些log,分別有什么作用
- 十.Redis
- 0.快速復習回顧Redis
- 1.通俗易懂的Redis數據結構基礎教程
- 2.分布式鎖(一)
- 3.分布式鎖(二)
- 4.延時隊列
- 5.位圖Bitmaps
- 6.Bitmaps(位圖)的使用
- 7.Scan
- 8.redis緩存雪崩、緩存擊穿、緩存穿透
- 9.Redis為什么是單線程、及高并發快的3大原因詳解
- 10.布隆過濾器你值得擁有的開發利器
- 11.Redis哨兵、復制、集群的設計原理與區別
- 12.redis的IO多路復用
- 13.相關redis面試題
- 14.redis集群
- 十一.中間件
- 1.RabbitMQ
- 1.1 RabbitMQ實戰,hello world
- 1.2 RabbitMQ 實戰,工作隊列
- 1.3 RabbitMQ 實戰, 發布訂閱
- 1.4 RabbitMQ 實戰,路由
- 1.5 RabbitMQ 實戰,主題
- 1.6 Spring AMQP 的 AMQP 抽象
- 1.7 Spring AMQP 實戰 – 整合 RabbitMQ 發送郵件
- 1.8 RabbitMQ 的消息持久化與 Spring AMQP 的實現剖析
- 1.9 RabbitMQ必備核心知識
- 2.RocketMQ 的幾個簡單問題與答案
- 2.Kafka
- 2.1 kafka 基礎概念和術語
- 2.2 Kafka的重平衡(Rebalance)
- 2.3.kafka日志機制
- 2.4 kafka是pull還是push的方式傳遞消息的?
- 2.5 Kafka的數據處理流程
- 2.6 Kafka的腦裂預防和處理機制
- 2.7 Kafka中partition副本的Leader選舉機制
- 2.8 如果Leader掛了的時候,follower沒來得及同步,是否會出現數據不一致
- 2.9 kafka的partition副本是否會出現腦裂情況
- 十二.Zookeeper
- 0.什么是Zookeeper(漫畫)
- 1.使用docker安裝Zookeeper偽集群
- 3.ZooKeeper-Plus
- 4.zk實現分布式鎖
- 5.ZooKeeper之Watcher機制
- 6.Zookeeper之選舉及數據一致性
- 十三.計算機網絡
- 1.進制轉換:二進制、八進制、十六進制、十進制之間的轉換
- 2.位運算
- 3.計算機網絡面試題匯總1
- 十四.Docker
- 100.面試題收集合集
- 1.美團面試常見問題總結
- 2.b站部分面試題
- 3.比心面試題
- 4.騰訊面試題
- 5.哈羅部分面試
- 6.筆記
- 十五.Storm
- 1.Storm和流處理簡介
- 2.Storm 核心概念詳解
- 3.Storm 單機版本環境搭建
- 4.Storm 集群環境搭建
- 5.Storm 編程模型詳解
- 6.Storm 項目三種打包方式對比分析
- 7.Storm 集成 Redis 詳解
- 8.Storm 集成 HDFS 和 HBase
- 9.Storm 集成 Kafka
- 十六.Elasticsearch
- 1.初識ElasticSearch
- 2.文檔基本CRUD、集群健康檢查
- 3.shard&replica
- 4.document核心元數據解析及ES的并發控制
- 5.document的批量操作及數據路由原理
- 6.倒排索引
- 十七.分布式相關
- 1.分布式事務解決方案一網打盡
- 2.關于xxx怎么保證高可用的問題
- 3.一致性hash原理與實現
- 4.微服務注冊中心 Nacos 比 Eureka的優勢
- 5.Raft 協議算法
- 6.為什么微服務架構中需要網關
- 0.CAP與BASE理論
- 十八.Dubbo
- 1.快速掌握Dubbo常規應用
- 2.Dubbo應用進階
- 3.Dubbo調用模塊詳解
- 4.Dubbo調用模塊源碼分析
- 6.Dubbo協議模塊