
mybatis 中使用 sqlMap 進行 sql 查詢時,經常需要動態傳遞參數,例如我們需要根據用戶的姓名來篩選用戶時,sql 如下:
~~~
select?*?from?user?where?name =?"ruhua";
~~~
上述 sql 中,我們希望 name 后的參數 "ruhua" 是動態可變的,即不同的時刻根據不同的姓名來查詢用戶。在 sqlMap 的 xml 文件中使用如下的 sql 可以實現動態傳遞參數 name:
~~~
select * from user where name = #{name};
~~~
或者
~~~
select * from user where name = '${name}';
~~~
對于上述這種查詢情況來說,使用 #{ } 和${ } 的結果是相同的,但是在某些情況下,我們只能使用二者其一。
## '#' 與 '$'
### 區別
**動態 SQL**是 mybatis 的強大特性之一,也是它優于其他 ORM 框架的一個重要原因。mybatis 在對 sql 語句進行預編譯之前,會對 sql 進行動態解析,解析為一個 BoundSql 對象,也是在此處對動態 SQL 進行處理的。
在動態 SQL 解析階段, #{ } 和${ } 會有不同的表現:
> **#{ } 解析為一個 JDBC 預編譯語句(prepared statement)的參數標記符。**
例如,sqlMap 中如下的 sql 語句
~~~
select?*?from?user?where?name?= #{name};
~~~
解析為:
~~~
select?*?from?user?where?name = ?;
~~~
一個 #{ } 被解析為一個參數占位符`?`。
而,
> **${ } 僅僅為一個純碎的 string 替換,在動態 SQL 解析階段將會進行變量替換**
例如,sqlMap 中如下的 sql
~~~
select?*?from?user?where?name =?'${name}';
~~~
當我們傳遞的參數為 "ruhua" 時,上述 sql 的解析為:
~~~
select?*?from?user?where?name =?"ruhua";
~~~
預編譯之前的 SQL 語句已經不包含變量 name 了。
綜上所得,${ } 的變量的替換階段是在動態 SQL 解析階段,而 #{ }的變量的替換是在 DBMS 中。
### 用法 tips
> 1、能使用 #{ } 的地方就用 #{ }
首先這是為了性能考慮的,相同的預編譯 sql 可以重復利用。
其次,**${ } 在預編譯之前已經被變量替換了,這會存在 sql 注入問題**。例如,如下的 sql,
~~~
select?*?from?${tableName}?where?name?= #{name}
~~~
假如,我們的參數 tableName 為`user; delete user; --`,那么 SQL 動態解析階段之后,預編譯之前的 sql 將變為
~~~
select?*?from?user;?delete?user; -- where name = ?;
~~~
`--`之后的語句將作為注釋,不起作用,因此本來的一條查詢語句偷偷的包含了一個刪除表數據的 SQL!
> 2、表名作為變量時,必須使用${ }
這是因為,表名是字符串,使用 sql 占位符替換字符串時會帶上單引號`''`,這會導致 sql 語法錯誤,例如:
~~~
select?*?from?#{tableName}?where?name?= #{name};
~~~
預編譯之后的sql 變為:
~~~
select?*?from???where?name = ?;
~~~
假設我們傳入的參數為 tableName = "user" , name = "ruhua",那么在占位符進行變量替換后,sql 語句變為
~~~
select?*?from?'user'?where?name='ruhua';
~~~
上述 sql 語句是存在語法錯誤的,表名不能加單引號`''`(注意,反引號 ``是可以的)。
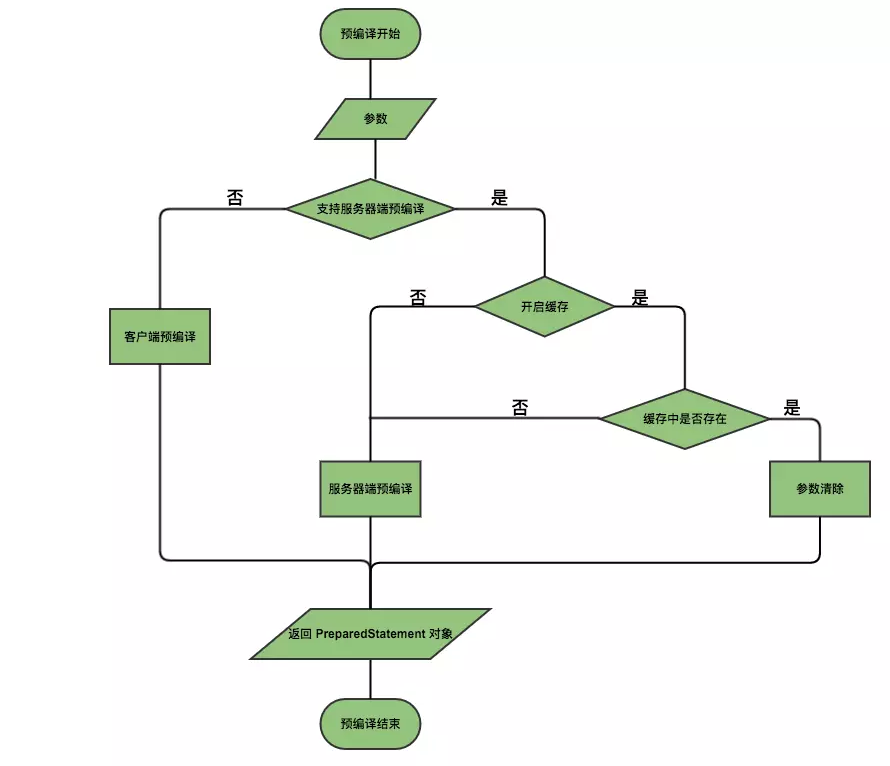
## sql預編譯
### 定義
> sql 預編譯指的是數據庫驅動在發送 sql 語句和參數給 DBMS 之前對 sql 語句進行編譯,這樣 DBMS 執行 sql 時,就不需要重新編譯。
### 為什么需要預編譯
JDBC 中使用對象 PreparedStatement 來抽象預編譯語句,使用預編譯
1. **預編譯階段可以優化 sql 的執行**。
預編譯之后的 sql 多數情況下可以直接執行,DBMS 不需要再次編譯,越復雜的sql,編譯的復雜度將越大,預編譯階段可以合并多次操作為一個操作。
2. **預編譯語句對象可以重復利用**。
把一個 sql 預編譯后產生的 PreparedStatement 對象緩存下來,下次對于同一個sql,可以直接使用這個緩存的 PreparedState 對象。
mybatis 默認情況下,將對所有的 sql 進行預編譯。
### mysql預編譯源碼解析
mysql 的預編譯源碼在`com.mysql.jdbc.ConnectionImpl`類中,如下:
~~~
public synchronized java.sql.PreparedStatement prepareStatement(String sql,
int resultSetType, int resultSetConcurrency) throws SQLException {
checkClosed();
//
// FIXME: Create warnings if can't create results of the given
// type or concurrency
//
PreparedStatement pStmt = null;
boolean canServerPrepare = true;
// 不同的數據庫系統對sql進行語法轉換
String nativeSql = getProcessEscapeCodesForPrepStmts() ? nativeSQL(sql): sql;
// 判斷是否可以進行服務器端預編譯
if (this.useServerPreparedStmts && getEmulateUnsupportedPstmts()) {
canServerPrepare = canHandleAsServerPreparedStatement(nativeSql);
}
// 如果可以進行服務器端預編譯
if (this.useServerPreparedStmts && canServerPrepare) {
// 是否緩存了PreparedStatement對象
if (this.getCachePreparedStatements()) {
synchronized (this.serverSideStatementCache) {
// 從緩存中獲取緩存的PreparedStatement對象
pStmt = (com.mysql.jdbc.ServerPreparedStatement)this.serverSideStatementCache.remove(sql);
if (pStmt != null) {
// 緩存中存在對象時對原 sqlStatement 進行參數清空等
((com.mysql.jdbc.ServerPreparedStatement)pStmt).setClosed(false);
pStmt.clearParameters();
}
if (pStmt == null) {
try {
// 如果緩存中不存在,則調用服務器端(數據庫)進行預編譯
pStmt = ServerPreparedStatement.getInstance(getLoadBalanceSafeProxy(), nativeSql,
this.database, resultSetType, resultSetConcurrency);
if (sql.length() < getPreparedStatementCacheSqlLimit()) {
((com.mysql.jdbc.ServerPreparedStatement)pStmt).isCached = true;
}
// 設置返回類型以及并發類型
pStmt.setResultSetType(resultSetType);
pStmt.setResultSetConcurrency(resultSetConcurrency);
} catch (SQLException sqlEx) {
// Punt, if necessary
if (getEmulateUnsupportedPstmts()) {
pStmt = (PreparedStatement) clientPrepareStatement(nativeSql, resultSetType, resultSetConcurrency, false);
if (sql.length() < getPreparedStatementCacheSqlLimit()) {
this.serverSideStatementCheckCache.put(sql, Boolean.FALSE);
}
} else {
throw sqlEx;
}
}
}
}
} else {
// 未啟用緩存時,直接調用服務器端進行預編譯
try {
pStmt = ServerPreparedStatement.getInstance(getLoadBalanceSafeProxy(), nativeSql,
this.database, resultSetType, resultSetConcurrency);
pStmt.setResultSetType(resultSetType);
pStmt.setResultSetConcurrency(resultSetConcurrency);
} catch (SQLException sqlEx) {
// Punt, if necessary
if (getEmulateUnsupportedPstmts()) {
pStmt = (PreparedStatement) clientPrepareStatement(nativeSql, resultSetType, resultSetConcurrency, false);
} else {
throw sqlEx;
}
}
}
} else {
// 不支持服務器端預編譯時調用客戶端預編譯(不需要數據庫 connection )
pStmt = (PreparedStatement) clientPrepareStatement(nativeSql, resultSetType, resultSetConcurrency, false);
}
return pStmt;
}
~~~
流程圖如下所示:
## mybatis之sql動態解析以及預編譯源碼
### mybatis sql 動態解析
mybatis 在調用 connection 進行 sql 預編譯之前,會對sql語句進行動態解析,動態解析主要包含如下的功能:
* 占位符的處理
* 動態sql的處理
* 參數類型校驗
mybatis強大的動態SQL功能的具體實現就在此
- 一.JVM
- 1.1 java代碼是怎么運行的
- 1.2 JVM的內存區域
- 1.3 JVM運行時內存
- 1.4 JVM內存分配策略
- 1.5 JVM類加載機制與對象的生命周期
- 1.6 常用的垃圾回收算法
- 1.7 JVM垃圾收集器
- 1.8 CMS垃圾收集器
- 1.9 G1垃圾收集器
- 2.面試相關文章
- 2.1 可能是把Java內存區域講得最清楚的一篇文章
- 2.0 GC調優參數
- 2.1GC排查系列
- 2.2 內存泄漏和內存溢出
- 2.2.3 深入理解JVM-hotspot虛擬機對象探秘
- 1.10 并發的可達性分析相關問題
- 二.Java集合架構
- 1.ArrayList深入源碼分析
- 2.Vector深入源碼分析
- 3.LinkedList深入源碼分析
- 4.HashMap深入源碼分析
- 5.ConcurrentHashMap深入源碼分析
- 6.HashSet,LinkedHashSet 和 LinkedHashMap
- 7.容器中的設計模式
- 8.集合架構之面試指南
- 9.TreeSet和TreeMap
- 三.Java基礎
- 1.基礎概念
- 1.1 Java程序初始化的順序是怎么樣的
- 1.2 Java和C++的區別
- 1.3 反射
- 1.4 注解
- 1.5 泛型
- 1.6 字節與字符的區別以及訪問修飾符
- 1.7 深拷貝與淺拷貝
- 1.8 字符串常量池
- 2.面向對象
- 3.關鍵字
- 4.基本數據類型與運算
- 5.字符串與數組
- 6.異常處理
- 7.Object 通用方法
- 8.Java8
- 8.1 Java 8 Tutorial
- 8.2 Java 8 數據流(Stream)
- 8.3 Java 8 并發教程:線程和執行器
- 8.4 Java 8 并發教程:同步和鎖
- 8.5 Java 8 并發教程:原子變量和 ConcurrentMap
- 8.6 Java 8 API 示例:字符串、數值、算術和文件
- 8.7 在 Java 8 中避免 Null 檢查
- 8.8 使用 Intellij IDEA 解決 Java 8 的數據流問題
- 四.Java 并發編程
- 1.線程的實現/創建
- 2.線程生命周期/狀態轉換
- 3.線程池
- 4.線程中的協作、中斷
- 5.Java鎖
- 5.1 樂觀鎖、悲觀鎖和自旋鎖
- 5.2 Synchronized
- 5.3 ReentrantLock
- 5.4 公平鎖和非公平鎖
- 5.3.1 說說ReentrantLock的實現原理,以及ReentrantLock的核心源碼是如何實現的?
- 5.5 鎖優化和升級
- 6.多線程的上下文切換
- 7.死鎖的產生和解決
- 8.J.U.C(java.util.concurrent)
- 0.簡化版(快速復習用)
- 9.鎖優化
- 10.Java 內存模型(JMM)
- 11.ThreadLocal詳解
- 12 CAS
- 13.AQS
- 0.ArrayBlockingQueue和LinkedBlockingQueue的實現原理
- 1.DelayQueue的實現原理
- 14.Thread.join()實現原理
- 15.PriorityQueue 的特性和原理
- 16.CyclicBarrier的實際使用場景
- 五.Java I/O NIO
- 1.I/O模型簡述
- 2.Java NIO之緩沖區
- 3.JAVA NIO之文件通道
- 4.Java NIO之套接字通道
- 5.Java NIO之選擇器
- 6.基于 Java NIO 實現簡單的 HTTP 服務器
- 7.BIO-NIO-AIO
- 8.netty(一)
- 9.NIO面試題
- 六.Java設計模式
- 1.單例模式
- 2.策略模式
- 3.模板方法
- 4.適配器模式
- 5.簡單工廠
- 6.門面模式
- 7.代理模式
- 七.數據結構和算法
- 1.什么是紅黑樹
- 2.二叉樹
- 2.1 二叉樹的前序、中序、后序遍歷
- 3.排序算法匯總
- 4.java實現鏈表及鏈表的重用操作
- 4.1算法題-鏈表反轉
- 5.圖的概述
- 6.常見的幾道字符串算法題
- 7.幾道常見的鏈表算法題
- 8.leetcode常見算法題1
- 9.LRU緩存策略
- 10.二進制及位運算
- 10.1.二進制和十進制轉換
- 10.2.位運算
- 11.常見鏈表算法題
- 12.算法好文推薦
- 13.跳表
- 八.Spring 全家桶
- 1.Spring IOC
- 2.Spring AOP
- 3.Spring 事務管理
- 4.SpringMVC 運行流程和手動實現
- 0.Spring 核心技術
- 5.spring如何解決循環依賴問題
- 6.springboot自動裝配原理
- 7.Spring中的循環依賴解決機制中,為什么要三級緩存,用二級緩存不夠嗎
- 8.beanFactory和factoryBean有什么區別
- 九.數據庫
- 1.mybatis
- 1.1 MyBatis-# 與 $ 區別以及 sql 預編譯
- Mybatis系列1-Configuration
- Mybatis系列2-SQL執行過程
- Mybatis系列3-之SqlSession
- Mybatis系列4-之Executor
- Mybatis系列5-StatementHandler
- Mybatis系列6-MappedStatement
- Mybatis系列7-參數設置揭秘(ParameterHandler)
- Mybatis系列8-緩存機制
- 2.淺談聚簇索引和非聚簇索引的區別
- 3.mysql 證明為什么用limit時,offset很大會影響性能
- 4.MySQL中的索引
- 5.數據庫索引2
- 6.面試題收集
- 7.MySQL行鎖、表鎖、間隙鎖詳解
- 8.數據庫MVCC詳解
- 9.一條SQL查詢語句是如何執行的
- 10.MySQL 的 crash-safe 原理解析
- 11.MySQL 性能優化神器 Explain 使用分析
- 12.mysql中,一條update語句執行的過程是怎么樣的?期間用到了mysql的哪些log,分別有什么作用
- 十.Redis
- 0.快速復習回顧Redis
- 1.通俗易懂的Redis數據結構基礎教程
- 2.分布式鎖(一)
- 3.分布式鎖(二)
- 4.延時隊列
- 5.位圖Bitmaps
- 6.Bitmaps(位圖)的使用
- 7.Scan
- 8.redis緩存雪崩、緩存擊穿、緩存穿透
- 9.Redis為什么是單線程、及高并發快的3大原因詳解
- 10.布隆過濾器你值得擁有的開發利器
- 11.Redis哨兵、復制、集群的設計原理與區別
- 12.redis的IO多路復用
- 13.相關redis面試題
- 14.redis集群
- 十一.中間件
- 1.RabbitMQ
- 1.1 RabbitMQ實戰,hello world
- 1.2 RabbitMQ 實戰,工作隊列
- 1.3 RabbitMQ 實戰, 發布訂閱
- 1.4 RabbitMQ 實戰,路由
- 1.5 RabbitMQ 實戰,主題
- 1.6 Spring AMQP 的 AMQP 抽象
- 1.7 Spring AMQP 實戰 – 整合 RabbitMQ 發送郵件
- 1.8 RabbitMQ 的消息持久化與 Spring AMQP 的實現剖析
- 1.9 RabbitMQ必備核心知識
- 2.RocketMQ 的幾個簡單問題與答案
- 2.Kafka
- 2.1 kafka 基礎概念和術語
- 2.2 Kafka的重平衡(Rebalance)
- 2.3.kafka日志機制
- 2.4 kafka是pull還是push的方式傳遞消息的?
- 2.5 Kafka的數據處理流程
- 2.6 Kafka的腦裂預防和處理機制
- 2.7 Kafka中partition副本的Leader選舉機制
- 2.8 如果Leader掛了的時候,follower沒來得及同步,是否會出現數據不一致
- 2.9 kafka的partition副本是否會出現腦裂情況
- 十二.Zookeeper
- 0.什么是Zookeeper(漫畫)
- 1.使用docker安裝Zookeeper偽集群
- 3.ZooKeeper-Plus
- 4.zk實現分布式鎖
- 5.ZooKeeper之Watcher機制
- 6.Zookeeper之選舉及數據一致性
- 十三.計算機網絡
- 1.進制轉換:二進制、八進制、十六進制、十進制之間的轉換
- 2.位運算
- 3.計算機網絡面試題匯總1
- 十四.Docker
- 100.面試題收集合集
- 1.美團面試常見問題總結
- 2.b站部分面試題
- 3.比心面試題
- 4.騰訊面試題
- 5.哈羅部分面試
- 6.筆記
- 十五.Storm
- 1.Storm和流處理簡介
- 2.Storm 核心概念詳解
- 3.Storm 單機版本環境搭建
- 4.Storm 集群環境搭建
- 5.Storm 編程模型詳解
- 6.Storm 項目三種打包方式對比分析
- 7.Storm 集成 Redis 詳解
- 8.Storm 集成 HDFS 和 HBase
- 9.Storm 集成 Kafka
- 十六.Elasticsearch
- 1.初識ElasticSearch
- 2.文檔基本CRUD、集群健康檢查
- 3.shard&replica
- 4.document核心元數據解析及ES的并發控制
- 5.document的批量操作及數據路由原理
- 6.倒排索引
- 十七.分布式相關
- 1.分布式事務解決方案一網打盡
- 2.關于xxx怎么保證高可用的問題
- 3.一致性hash原理與實現
- 4.微服務注冊中心 Nacos 比 Eureka的優勢
- 5.Raft 協議算法
- 6.為什么微服務架構中需要網關
- 0.CAP與BASE理論
- 十八.Dubbo
- 1.快速掌握Dubbo常規應用
- 2.Dubbo應用進階
- 3.Dubbo調用模塊詳解
- 4.Dubbo調用模塊源碼分析
- 6.Dubbo協議模塊